Metric loss:



Contrastive Loss

- Core meaning: samples of the same type are closer, and samples of different types are farther away
- Don’t worry about the positive samples, just separate the negative samples. Minimizing the loss function is to maximize the distance between the decision boundary and the negative samples
Triplet Loss
Triplet Loss is a loss function used to train Siamese networks or triplet networks in deep learning. Its goal is to make the distance between samples of the same class as small as possible and the distance between different classes as large as possible.
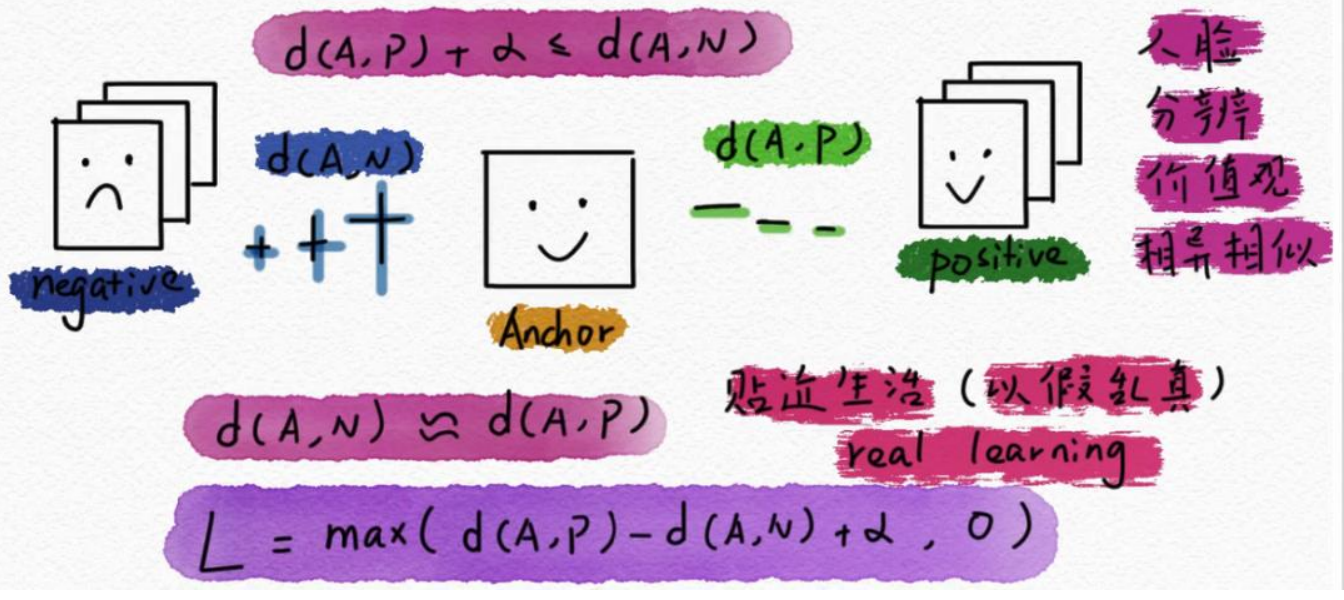
- There is an intermediate marker to calculate the distance
Specifically, for a triplet (anchor, positive, negative), where anchor is a sample, positive is a sample of the same category, and negative is a sample of a different category.
- The calculation method of Triplet Loss is: L = max(d(a, p) - d(a, n) + margin, 0)
Among them, d(a, p) represents the distance between anchor and positive, d(a, n) represents the distance between anchor and negative, and margin is a preset constant used to control the distance between different categories .
The goal of Triplet Loss is to make the distance between samples of the same category as small as possible and the distance between different categories as large as possible.
- If the distance between anchor and positive is less than the distance between anchor and negative plus margin, then the triplet is valid and the value of the loss function is 0.
- If the distance between anchor and positive is greater than the distance between anchor and negative plus margin, then this triplet is invalid, and the value of the loss function is d(a, p) - d(a, n) + margin.
During the training process, we need to select a large number of triples from the sample set, and then update the model parameters by minimizing the loss function of all valid triples, so that the model can learn better feature representation.

- The sensitivity is low, and a single sample cannot be limited, that is, there must be sample misclassification
- Constructing binary/triple is expensive
Center Loss
Center Loss is a supervised learning method used in tasks such as face recognition and target detection.
- Its principle is to enhance the discriminative ability of features by constraining the center of each category during the training process of deep neural network.
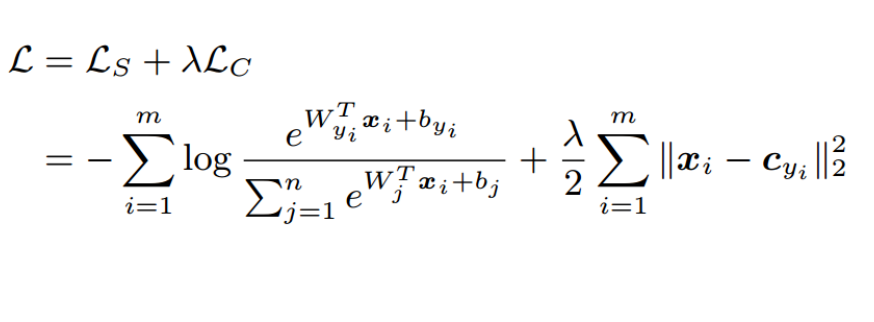
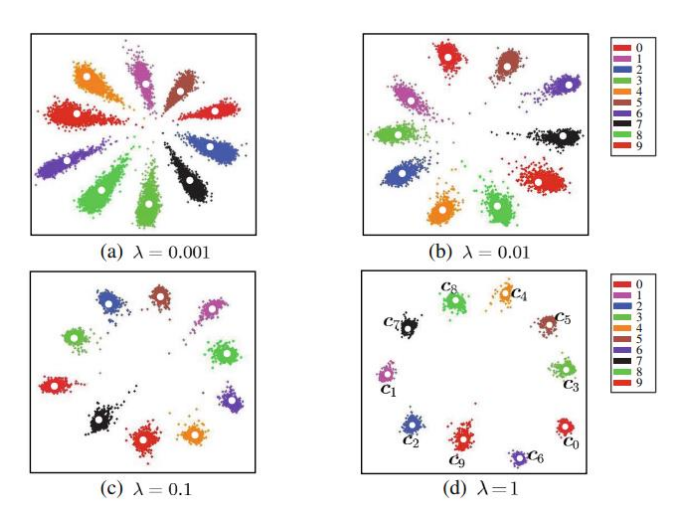
Specifically, Center Loss maintains a center vector for each category, which has the same dimension as the feature vector. During the training process, for each sample, its feature vector will be sent to the network for forward propagation, and a feature vector will be obtained in the last layer. This feature vector is then used to update the center vector of the class to which the sample belongs.
- The goal of Center Loss is to minimize the Euclidean distance between the feature vector of each sample and the center vector of its category.
This distance can be regarded as the "distance" between the sample and its category. The optimization goal of Center Loss is to make the feature vectors of samples of the same category closer to their center vectors, and the feature vectors of samples of different categories are farther away from each other's center vectors. .
In this way, Center Loss can make the feature vectors better distinguish different categories, thereby improving the accuracy of classification. At the same time, since the center vector is dynamically updated during the training process, Center Loss also has certain adaptability and can cope with changes in data distribution.