Based on Wu Enda's video and symbol regulations, this article introduces the structure and formula of RNN/GRU/LSTM, focusing on explaining the forward and back propagation process of RNN, especially the back propagation of RNN. I think it is relatively easy to understand . A little bit of personal experience, this part is difficult to understand in general, you can follow a teacher or a post that speaks clearly, and read it carefully.
[1] A brief introduction to RNN
First of all, why is this new structure of RNN needed?
The biggest difference between it and the previous multi-layer perceptron and convolutional neural network is that it is a sequence model, the nodes between the hidden layers are no longer connected but connected, and the input of the hidden layer includes not only the input The output of the layer also includes the output of the hidden layer at the previous moment.
For MLP or CNN, give some training data, these data are independent and unrelated to each other, but in reality some are related to time, such as the prediction of the next moment of the video, the prediction of the content of the front and back of the document, etc. These The performance of the algorithm is not satisfactory, and the serial network structure of RNN is very suitable for time series data, which can maintain the dependencies in the data.
What is the general structure of RNN?
The figure below shows the general structure of RNN. The right side is expanded according to time. Through the connection on the hidden layer, the network state at the previous moment can be transmitted to the current moment, and the state at the current moment can also be passed to the next moment.
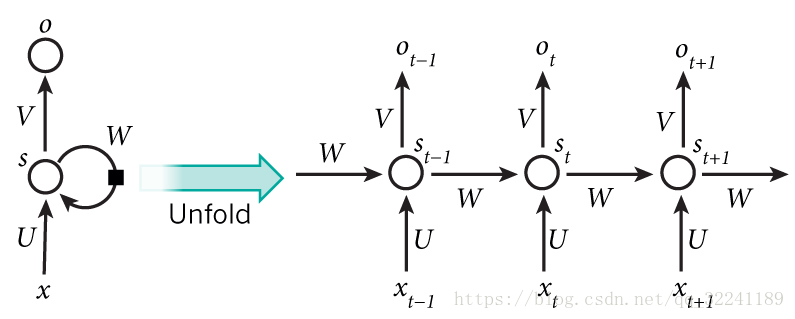
[2] Forward propagation of RNN
The network structure of RNN Here, I will use the symbol system in Wu Enda's course. I personally think that Li Hongyi can make people understand what RNN is used for from an overall perspective, and intuitively understand some of its ideas. Wu Enda The details are more detailed, and will be explained in depth from the structure and derivation. Li Mu prefers to give a brief introduction, but the advantage is that he can talk about code and answer questions.
Start with the simple case, assuming there is only one hidden layer, and the input sequence length is equal to the output sequence.
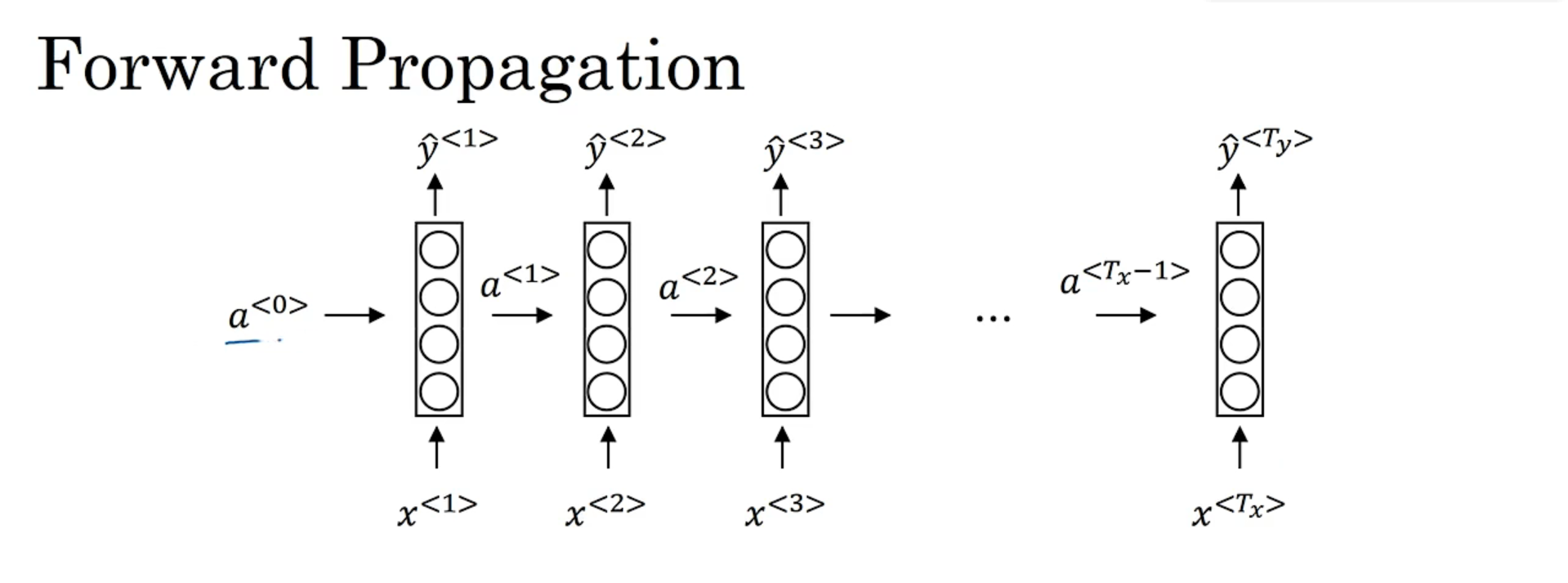
x < 1 > , . . . , x < 9 > x^{<1>},...,x^{<9>} x<1>,...,x< 9 > is the input sequence,x < i > x^{<i>}x< i > is a vector, superscriptiii representativeiii time steps,a < t > a^{<t>}a< t > indicates the output of the hidden layer, and the circles in the box represent the hidden layer. (It can also be seen that there are connections between nodes on the same layer, which is different from ordinary fully connected networks, which only have connections between layers)
When performing forward propagation, first by x < 1 > x^{<1>}x<1> 计算 a < 1 > a^{<1>} a<1> ,计算式为: a < 1 > = g ( W a a a < 0 > + W a x x < 1 > + b a ) a^{<1>}=g(W_{aa}a^{<0>}+W_{ax}x^{<1>}+b_a) a<1>=g(Waaa<0>+Waxx<1>+ba) According to this formula, it can be seen that the calculation of theiia < i > a^{<i>} for i time stepsa< i > used theiiInput x < i > x^{<i>} for i time stepsx< i > and the memory a of the previous time step< i − 1 > a^{<i-1>}a< i − 1 > , here is the first time step,a < 0 > a^{<0>}a<0> Where does it come from? Generally, a vector of all 0s is used instead. If there is no W aaa < i > W_{aa}a^{<i>}in the formulaWaaaThe < i > part is the same as the structure of the multi-layer perceptron. The activation function here generally uses tanh or relu.
由 a < 1 > a^{<1>} a<1> 计算 y ^ < 1 > \hat{y}^{<1>} y^The expression of < 1 > is as follows:y ^ < 1 > = g ( W yaa < 1 > + by ) \hat{y}^{<1>}=g(W_{ya}a^{<1>}+ b_y)y^<1>=g(Wy aa<1>+by) The activation function here should be determined according to the specific task. If it is a binary classification, sigmoid is generally used. If it is multi-classification, softmax is generally used.
Similarly, then start to calculate a < 2 > a^{<2>}a<2> 和 y ^ < 2 > \hat{y}^{<2>} y^< 2 > , for the more general case, i.e., computinga < t > a^{<t>}a<t> 和 y ^ < t > \hat{y}^{<t>} y^<t> 的表达式为: a < t > = g ( W a a a < t − 1 > + W a x x < t > + b a ) a^{<t>}=g(W_{aa}a^{<t-1>}+W_{ax}x^{<t>}+b_a) a<t>=g(Waaa<t−1>+Waxx<t>+ba) y ^ < t > = g ( W y a a < t > + b y ) \hat{y}^{<t>}=g(W_{ya}a^{<t>}+b_y) y^<t>=g(Wy aa<t>+by) For each calculation step,W aa W_{aa}WaaThe city is the same, W ya , ba , by W_{ya}, b_a, b_yWy a,ba,byAlso, is a shared parameter for all time steps.
A simplification of the formula here is introduced in Wu Enda's video. Put a < t > = g ( W aaa < t − 1 > + W axx < t > + ba ) a^{<t>}=g(W_{aa}a^{<t-1>}+W_{ ax}x^{<t>}+b_a)a<t>=g(Waaa<t−1>+Waxx<t>+ba) 改写为 a < t > = g ( W a [ a < t − 1 > , x < t > ] + b a ) a^{<t>}=g(W_a[a^{<t-1>},x^{<t>}]+b_a) a<t>=g(Wa[a<t−1>,x<t>]+ba) W a W_a WaCommander W aa W_{aa}Waa和W ax W_{ax}WaxGlue left and right, give an example to understand:
Suppose x < t > x^{<t>}x< t > is a 1000-dimensional vector,a < t − 1 > a^{<t-1>}a< t − 1 > is a 100-dimensional vector, thenW aa W_{aa}Waais a 100×100 matrix, W ax W_{ax}Waxis a 100×1000 matrix.
Simplified a < t − 1 > a^{<t-1>}a<t−1>和 x < t > x^{<t>} x< t > put together to become a 1100-dimensional vector,W a W_aWaIt is a matrix of 100 × 1100, which is relatively simple to write, and is exactly the same as the original operation result.
Before introducing backpropagation, first define the loss function, using the cross-entropy loss function: L < t > ( y ^ < t > , y < t > ) = − y < t > logy ^ < t > − ( 1 − y < t > ) log ( 1 − y ^ < t > ) L^{<t>}(\hat{y}^{<t>},y^{<t>})=-y^{<t >}log\hat{y}^{<t>}-(1-y^{<t>})log(1-\hat{y}^{<t>})L<t>(y^<t>,y<t>)=−y<t>logy^<t>−(1−y<t>)log(1−y^< t > )This is the loss at the t-th time step, and the loss for the entire sequence is the sum of the t losses.
[3] Backpropagation BPTT of RNN
The backpropagation of RNN is called Backpropagation through time (BPTT), that is, backpropagation through time, that is, from the last time step to the previous time step one by one, and the chain rule is used repeatedly like ordinary neural networks. For convenience, the following derivations are superscripted < t > ^{<t>}<t> is written as subscriptt_tt
The first is the output layer parameter W ya W_{ya}Wy a,define β t = W yaat \beta_t=W_{ya}a_tbt=Wy aat, represents the state where the hidden layer multiplies the weight matrix to the output layer, but has not yet passed through the activation function (the bias item is ignored here, in fact, it is the same whether it is present or not, and the subsequent derivation will not affect it): ∂ L t ∂ W ya = ∂ L t ∂ y ^ t ∂ y ^ t ∂ W ya = ∂ L t ∂ y ^ t ∂ y ^ t ∂ β t ∂ β t ∂ W ya \dfrac{\partial{L_t}}{\partial{W_{ya }}}=\dfrac{\partial{L_t}}{\partial{\hat{y}_{t}}}\dfrac{\partial{\hat{y}_{t}}}{\partial{W_ {ya}}}=\dfrac{\partial{L_t}}{\partial{\hat{y}_{t}}}\dfrac{\partial{\hat{y}_{t}}}{\partial {\beta_t}}\dfrac{\partial{\beta_t}}{\partial{W_{ya}}}∂Wy a∂Lt=∂y^t∂Lt∂Wy a∂y^t=∂y^t∂Lt∂βt∂y^t∂Wy a∂βt
After that W aa W_{aa}Waa和W ax W_{ax}Wax, these two need to consider the gradient at the current moment (the gradient passed down from the loss function at the current moment t) and the gradient at the next moment (the gradient passed down from the time t+1) when updating the gradient. For convenience, then Define two variables: zt = W axxt + W aaat − 1 z_t=W_{ax}x_t+W_{aa}a_{t-1}zt=Waxxt+Waaat−1, is the hidden layer node of the tth time step (accepting the input xt x_t at time txtand at − 1 a_{t-1} at time t-1at−1) but has not yet passed through the activation function. Let δ t \delta_tdtIndicates the moment t zt z_tzt 接受到的梯度。 δ t = ∂ L t ∂ y t ^ ∂ y t ^ ∂ a t ∂ a t ∂ z t + δ t + 1 ∂ z t + 1 ∂ a t ∂ a t ∂ z t \delta_t=\dfrac{\partial{L_t}}{\partial{\hat{y_t}}}\dfrac{\partial{\hat{y_t}}}{\partial{a_t}}\dfrac{\partial{a_t}}{\partial{z_t}}+\delta_{t+1}\dfrac{\partial{z_{t+1}}}{\partial{a_t}}\dfrac{\partial{a_t}}{\partial{z_t}} dt=∂yt^∂Lt∂at∂yt^∂zt∂at+dt+1∂at∂zt+1∂zt∂atFind δ t \delta_tdtAfter that, it is easy to find L t L_tLtVS aa W_{aa}Waa和W ax W_{ax}Wax 的导数: δ t a t − 1 T , δ t x t T \delta_ta^{T}_{t-1},\delta_tx^T_{t} dtat−1T, dtxtT
Give a specific small example to see how to calculate it. Assuming that there are only three time steps in total, the forward propagation process of the data is as follows (here z , β z, \betaz , β has a bias term, but it does not affect):

W ya W_{ya}Wy aThe gradient of is not counted because it is relatively simple. First look at the third time step, look at L 3 L_3L3VS aa W_{aa}Waa 的影响: ∂ L 3 ∂ W a a = ∂ L 3 ∂ y 3 ^ ∂ y 3 ^ ∂ β 3 ∂ β 3 ∂ a 3 ∂ a 3 ∂ z 3 ∂ z 3 ∂ W a a \dfrac{\partial{L_3}}{\partial{W_{aa}}}=\dfrac{\partial{L_3}}{\partial{\hat{y_3}}}\dfrac{\partial{\hat{y_3}}}{\partial{\beta_3}}\dfrac{\partial{\beta_3}}{\partial{a_3}}\dfrac{\partial{a_3}}{\partial{z_3}}\dfrac{\partial{z_3}}{\partial{W_{aa}}} ∂Waa∂L3=∂y3^∂L3∂β3∂y3^∂a3∂β3∂z3∂a3∂Waa∂z3Remove the last item on the right side of the equal sign ∂ z 3 ∂ W aa \dfrac{\partial{z_3}}{\partial{W_{aa}}}∂Waa∂z3It is the δ 3 \delta_3 we stipulated aboved3, the reason why this is specified is for the convenience of calculation and description, because the missing item will be expanded later.
The gradient is passed back to the second time step, not only must be considered by L 2 L_2L2The calculated gradient and the gradient from time t=3. First consider L 2 L_2L2 的: ∂ L 2 ∂ W a a = ∂ L 2 ∂ y 2 ^ ∂ y 2 ^ ∂ β 2 ∂ β 2 ∂ a 2 ∂ a 2 ∂ z 2 ∂ z 2 ∂ W a a \dfrac{\partial{L_2}}{\partial{W_{aa}}}=\dfrac{\partial{L_2}}{\partial{\hat{y_2}}}\dfrac{\partial{\hat{y_2}}}{\partial{\beta_2}}\dfrac{\partial{\beta_2}}{\partial{a_2}}\dfrac{\partial{a_2}}{\partial{z_2}}\dfrac{\partial{z_2}}{\partial{W_{aa}}} ∂Waa∂L2=∂y2^∂L2∂β2∂y2^∂a2∂β2∂z2∂a2∂Waa∂z2Then L 3 L_3L3经a3 a_3a3pass to a 2 a_2a2Here, it is actually the above ∂ L 3 ∂ W aa \dfrac{\partial{L_3}}{\partial{W_{aa}}}∂Waa∂L3 继续往下链式求导: ∂ L 3 ∂ y 3 ^ ∂ y 3 ^ ∂ β 3 ∂ β 3 ∂ a 3 ∂ a 3 ∂ z 3 ∂ z 3 ∂ a 2 ∂ a 2 ∂ z 2 ∂ z 2 W a a = δ 3 ∂ z 3 ∂ a 2 ∂ a 2 ∂ z 2 ∂ z 2 W a a \dfrac{\partial{L_3}}{\partial{\hat{y_3}}}\dfrac{\partial{\hat{y_3}}}{\partial{\beta_3}}\dfrac{\partial{\beta_3}}{\partial{a_3}}\dfrac{\partial{a_3}}{\partial{z_3}}\dfrac{\partial{z_3}}{\partial{a_2}}\dfrac{\partial{a_2}}{\partial{z_2}}\dfrac{\partial{z_2}}{W_{aa}}=\delta_3\dfrac{\partial{z_3}}{\partial{a_2}}\dfrac{\partial{a_2}}{\partial{z_2}}\dfrac{\partial{z_2}}{W_{aa}} ∂y3^∂L3∂β3∂y3^∂a3∂β3∂z3∂a3∂a2∂z3∂z2∂a2Waa∂z2=d3∂a2∂z3∂z2∂a2Waa∂z2So the total gradient accepted at the second time step is the sum of the two.
Come to the first time step, although it is not drawn on the picture, there is actually a 0 a_0a0. Last W aa W_{aa}WaaThe update is L 3 L_3L3Incoming gradient + L 2 L_2L2Incoming gradient + L 1 L_1L1incoming gradient.
vsW ax W_{ax}WaxThe same is true for the calculation of , so I won't say more about it. In essence, it is still a chain derivation that has been passed down. Or to put it this way, take L t L_tLtAs a parameter to be updated such as W aa W_{aa}WaaThe multi-layer nested composite function, using the chain rule to derive to the innermost layer of our parameters to be updated, the feeling of peeling off layer by layer.
[4] Gradient disappearance and gradient explosion of RNN
Gradient disappearance means that the result of many derivative multiplications will be very close to 0. The gradient disappearance makes RNN not good at capturing long-distance dependencies. For example, for a very deep network, forward propagation of the network from left to right and then backpropagation, from the output y ^ \hat{y}y^The obtained gradient is difficult to propagate back, it is difficult to affect the weight of the previous layer, and it is difficult to affect the calculation of the previous layer. An output is mainly related to the nearby input, and it is basically difficult to be affected by the input at the front of the sequence. This is because no matter what the output is, whether it is right or wrong, it is difficult for this area to backpropagate to the sequence. In the front part, it is also difficult for the network to adjust the calculations in front of the sequence. This is a shortcoming of the basic RNN algorithm.
Gradient disappearance is the primary problem when training RNN. Although gradient explosion will also occur, gradient explosion is obvious, because exponentially large gradients will make your parameters extremely large, so that your network parameters collapse. So the gradient explosion is easy to spot, because the parameters will be so large that they will collapse, and you will see a lot of NaN, or not a number, which means that your network calculations have numerical overflow. If you find problems with exploding gradients, one solution is to use gradient pruning. Gradient pruning means to observe your gradient vector, if it is larger than a certain threshold, scale the gradient vector to ensure that it is not too large, this is the method of pruning by some maximum value (that is, when the gradient you calculate exceeds the threshold c Or when it is less than the threshold -c, the gradient at this time is set to c or -c).
[5] Gated recurrent unit GRU
GRU changes the hidden layer of RNN so that it can better capture deep connections and improve the problem of gradient disappearance. This is the GRU formula given in the video, and then I will explain it in detail:

(1) First, the original a < t > a^{<t>}a< t > use c here< t > c^{<t>}c< t > to indicate, refers to thettThe output value of the hidden layer at t time steps, naturally,W a W_aWaAlso changed to W c W_cWc . c c c means cell, which is understood as "memory cell", that is, it has memory ability and can maintain the value of the previous cell, thereby alleviating the problem of gradient disappearance/long-distance dependence.
(2) except c < t > c^{<t>}c< t > , also addedc ~ < t > \tilde{c}^{<t>}c~<t> as a candidate value. As you can see later, the original calculationa < t > a^{<t>}aThe formula of < t > gets the candidate valuec ~ < t > \tilde{c}^{<t>}c~< t > , after some processing will finally getc < t > c^{<t>}c<t> 。
(3) There are two "gates", and the "gate" uses Γ \GammaΓ means,Γ \GammaΓ is covered with sigmoid, its value is between 0 and 1, and the probability is relatively close to 0 or 1, so as to achieve control. The two doors are:
- Γ r \Gamma_rCr: correlation gate, controlling c ~ < t > \tilde{c}^{<t>}c~<t> 和 c < t − 1 > c^{<t-1>} cThe magnitude of the correlation between < t − 1 > , r means relevant
- Γ u \Gamma_uCu: Update gate, which controls whether the value of the memory cell is updated, that is, whether to use c ~ < t > \tilde{c}^{<t>}c~<t> 更新 c < t > c^{<t>} c<t> ,u 表示 update
Now, to think through the whole process, c < t − 1 > c^{<t-1>}c< t − 1 > is the hidden layer output of the last time step, first byc < t − 1 > c^{<t-1>}c<t−1> 和 x < t > x^{<t>} x< t > Calculate the candidate valuec ~ < t > \tilde{c}^{<t>}c~<t>: c ~ < t > = t a n h ( W c [ Γ r ∗ c < t − 1 > , x < t > ] + b c ) \tilde{c}^{<t>}=tanh(W_c[\Gamma_r *c^{<t-1>},x^{<t>}]+b_c) c~<t>=t a n h ( Wc[ Cr∗c<t−1>,x<t>]+bc) This calculated value should have beena < t > a^{<t>}a< t > (orc < t > c^{<t>}c< t > ), but now it is just a candidate value, and some operations are required to determine the finalc < t > c^{<t>}c<t> . _ _ Note that herec < t − 1 > c^{<t-1>}c< t − 1 > is also multiplied by aΓ r \Gamma_rCr, if Γ r \Gamma_rCrClose to 0, it means that the correlation with the hidden layer output of the previous time step is very small, otherwise it is very large. Γ r \Gamma_rCrThe value of is equivalent to "the degree of door opening", controlling c < t − 1 > c^{<t-1>}c< t − 1 > Influence on the next time step.
Then calculate c < t > c^{<t>}c<t>: c < t > = Γ u ∗ c ~ < t > + ( 1 − Γ u ) ∗ c < t − 1 > c^{<t>}=\Gamma_u*\tilde{c}^{<t>}+(1-\Gamma_u)*c^{<t-1>} c<t>=Cu∗c~<t>+(1−Cu)∗c< t − 1 >如果Γ u \Gamma_uCuClose to 1, then c < t > c^{<t>}c< t > is approximately equal to the candidate value, ifΓ u \Gamma_uCuClose to 0, then c < t > c^{<t>}c< t > is equal to the output of the previous time step, which is equivalent to no update, and the previous value is maintained, which is similar to "memory".
It is not difficult to see that RNN is Γ r = 1 , Γ u = 1 \Gamma_r=1,\Gamma_u=1Cr=1,Cu=1 when the special case of the GRU. But I also think, onlyΓ u \Gamma_uCuOk? It is updated when it is equal to 1, and it is not updated when it is equal to 0. Why there is Γ r \Gamma_rCr? This is because over the years researchers have tried many, many different possible ways to design these units, to try to make the neural network have deeper connections, to try to produce a wider range of influence, and to solve the problem of gradient disappearance, GRU It is one of the most commonly used versions by researchers, and it has also been found to be very robust and practical on many different problems. (Probably because, doing so is good in the experiment?
[6] Long short-term memory neural network LSTM

LSTM is a more general and powerful form of GRU. Now let's talk about the structure of LSTM. First is the memory cell c, use c ~ < t > = tanh ( W c [ a < t − 1 > , x < t > ] + bc ) \tilde{c}^{<t>}=tanh(W_c[a ^{<t-1>}, x^{<t>}]+b_c)c~<t>=t a n h ( Wc[a<t−1>,x<t>]+bc) to update its candidate value. Note that in LSTM we no longer havea < t > = c < t > a^{<t>}=c^{<t>}a<t>=c< t > case, now we specifically usea < t > a^{<t>}a<t> 或者 a < t − 1 > a^{<t-1>} a< t − 1 > , and do not useΓ r \Gamma_rCr, that is, the relevant gate.
Like GRU there is an update gate Γ u \Gamma_uCuand the parameter W u W_u representing the updateWu, but not only one update gate controls, Γ u \Gamma_u in ④Cu和1 − Γ u 1-\Gamma_u1−CuRepresented by different terms to allow for a more flexible structure. Therefore, let Γ f \Gamma_fCfDetermine1 − Γ u 1-\Gamma_u1−Cu , Γ f \Gamma_f CfRepresents the forget gate, controlling how much to forget c < t − 1 > c^{<t-1>}c< t − 1 > . So this gives the memory cell the option to maintain the old valuec < t − 1 > c^{<t-1>}c< t − 1 > or just add a new valuec ~ < t > \tilde{c}^{<t>}c~< t > , so a separate update gateΓ u \Gamma_uCuand forget gate Γ f \Gamma_fCf .
Then there is a new output gate Γ o \Gamma_oCo ,将 a < t > = c < t > a^{<t>}=c^{<t>} a<t>=c<t> 变成 a < t > = Γ o ∗ c < t > a^{<t>}=\Gamma_o*c^{<t>} a<t>=Co∗c<t>
We use graphs for a more intuitive understanding:

由 a < t − 1 > a^{<t-1>} a<t−1> 和 x < t > x^{<t>} x< t > DefinitionsΓf , Γ u , Γ o \Gamma_f,\Gamma_u,\Gamma_oCf,Cu,CoThe value at time t, and c ~ < t > \tilde{c}^{<t>}c~<t>,然后 c < t − 1 > ∗ Γ f c^{<t-1>}*\Gamma_f c<t−1>∗Cf, c ~ < t > ∗ Γ u \tilde{c}^{<t>}*\Gamma_u c~<t>∗Cu, the two are added to get c < t > c^{<t>}c<t>, c < t > c^{<t>} c< t > multiplied by Γ o \Gamma_oafter tanhCoGet hidden layer output a < t > a^{<t>}a<t>.
[7] Comparing GRU and LSTM
When should we use GRU? When to use LSTM? There is no uniform guideline here. In fact, in the history of deep learning, LSTM appeared earlier, and GRU was invented only recently. It may have originated from the simplification made by Pavia in the more complex LSTM model.
The advantage of GRU is that this is a simpler model , so it is easier to create a larger network, and it only has two gates, and it runs faster computationally, and then it can expand the size of the model, and the effect is also good.
But LSTM is more powerful and flexible because it has three gates instead of two. If you want to pick one to use, I think LSTM has historically been a more preferred choice, so if you have to pick one, I feel that most people today will still try LSTM as the default choice.
[8] Summary
RNN is a sequence model that is often used for tasks such as named entity recognition, machine translation, and text generation. Its typical feature is that the output of the hidden layer at a certain moment is not only related to the input data at that moment , but also related to the output of the hidden layer at the previous moment , but RNN has the problems of gradient disappearance and long-term dependence . GRU adds two gates on the basis of RNN: correlation gate and update gate. GRU can form memory and decide whether to update at each moment. RNN can be regarded as a special case of GRU. And LSTM is a more powerful and general version.