CNN mainly processes image information and is mainly used in the field of computer vision.
RNN (recurrent neural network) mainly processes sequence data (natural language processing, speech recognition, video classification, text sentiment analysis, translation), and its core is that it can maintain past memory . However, RNN has the problem of gradient disappearance, and experts then improved it to LSTM and GRU structures. The following will introduce each in plain language in detail.
For children's shoes who are not familiar with machine learning or deep learning, you can read these articles first:
"No Nonsense Machine Learning Notes"
"One article to quickly understand deep learning"
"One article summarizes the classic convolutional neural network CNN model"
Table of contents
RNN(Recurrent Neural Network)
The processing unit in the RNN, the green in the middle is the result of the past processing, the first picture on the left is a normal DNN, the past results will not be saved, the picture on the right has a characteristic, the output result (blue) not only depends on the current The input of , also depends on the past input! Different units can endow RNN with different capabilities, such as many-to-one, which can classify a string of texts and output discrete values, such as judging whether you are happy today or not based on your words.
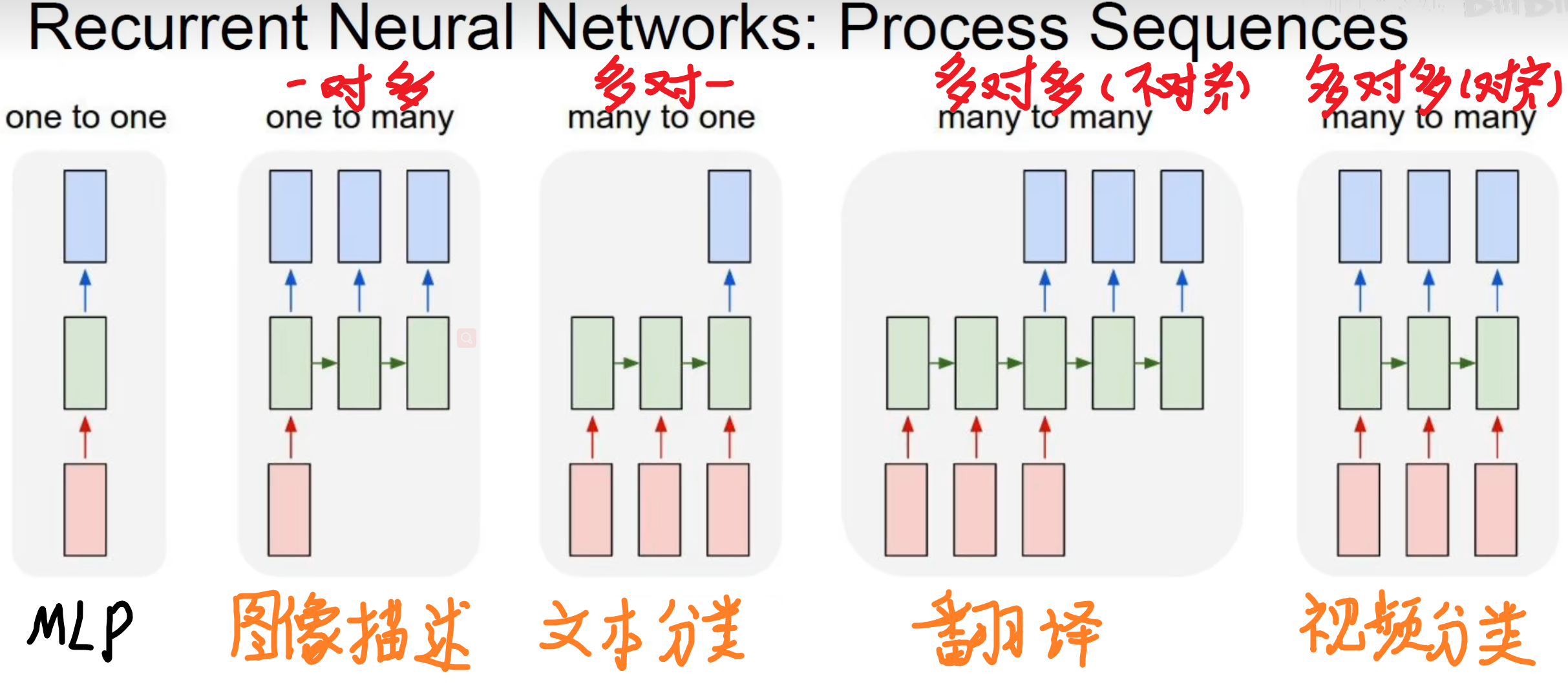
The past information is kept in the RNN, and the output depends on the present and the past . If you have learned counting electricity, this is a state machine! This thing is very similar to a trigger.
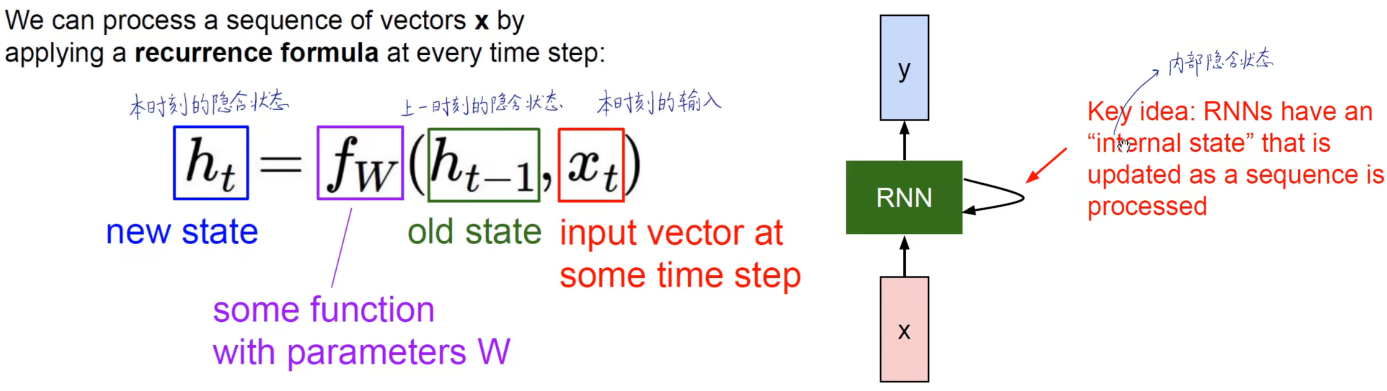
There is a very important point:
this weight fw is consistent along the time dimension, and the weights are shared. Just like a convolution kernel in CNN has the same parameters during the convolution process. So CNN shares weights along the spatial dimension; RNN shares weights along the time dimension.

Specifically, there are three weights, one for the past and one for the present, and one more when added together. They all share weights along the time dimension. Otherwise, the weight will be different at each time, and the amount of parameters will be terrifying.

The overall calculation graph (many-to-many):
each output y can be used to construct a loss function with the label value, which is the same as the previous DNN training model idea, training 3 sets of weights to make the loss function continuously decrease to a satisfactory level.
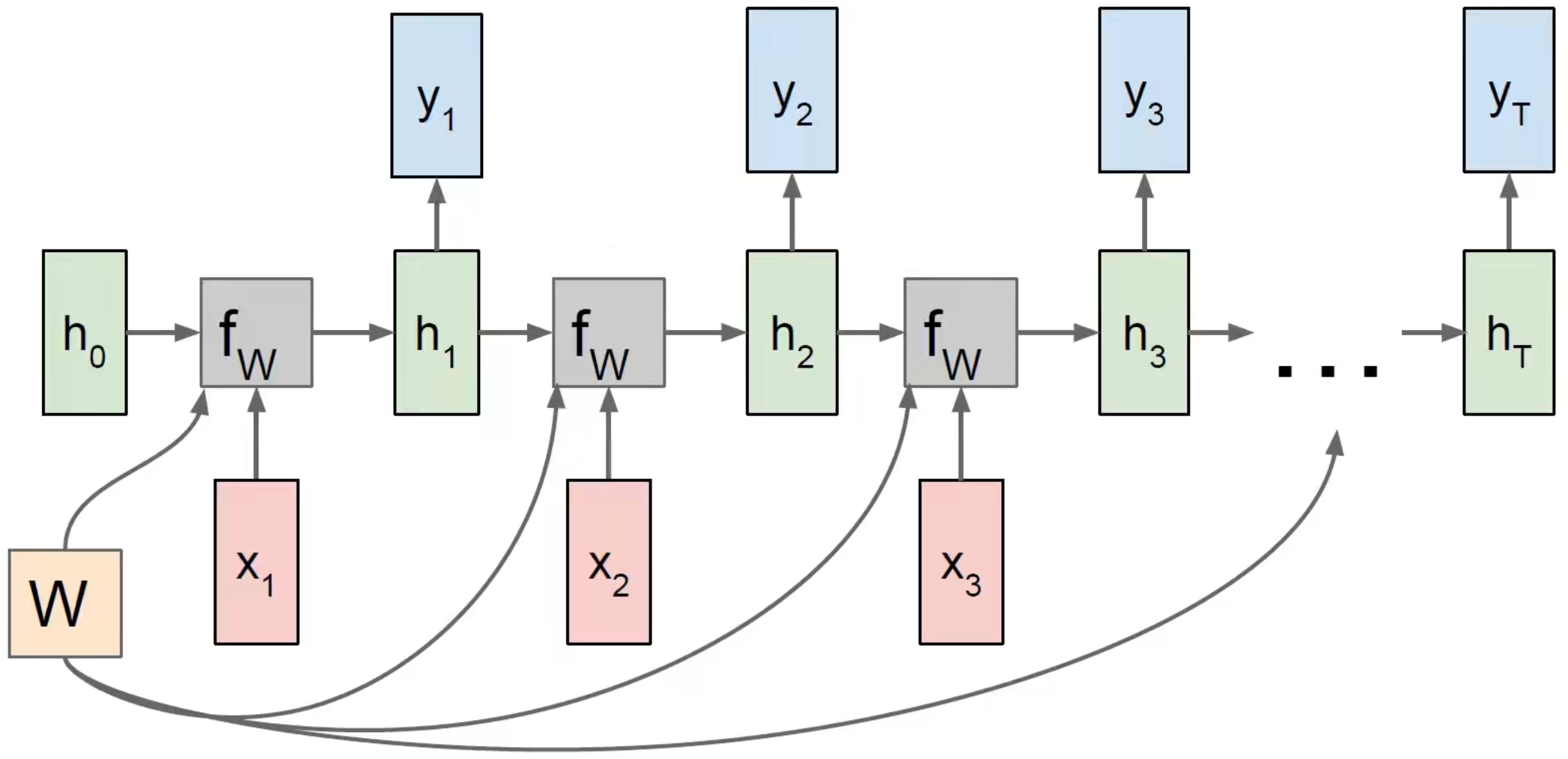
Backpropagation must be passed back along time (backpropagation through time, BPTT)
Forward through entire sequence to compute loss, then backward through entire sequence to compute gradient.

There will be problems in this way, that is, to get all the sequences in to find the gradient at once, and the amount of calculation is very large . In fact, we will divide the large sequence into small sequences of equal length and process them separately:
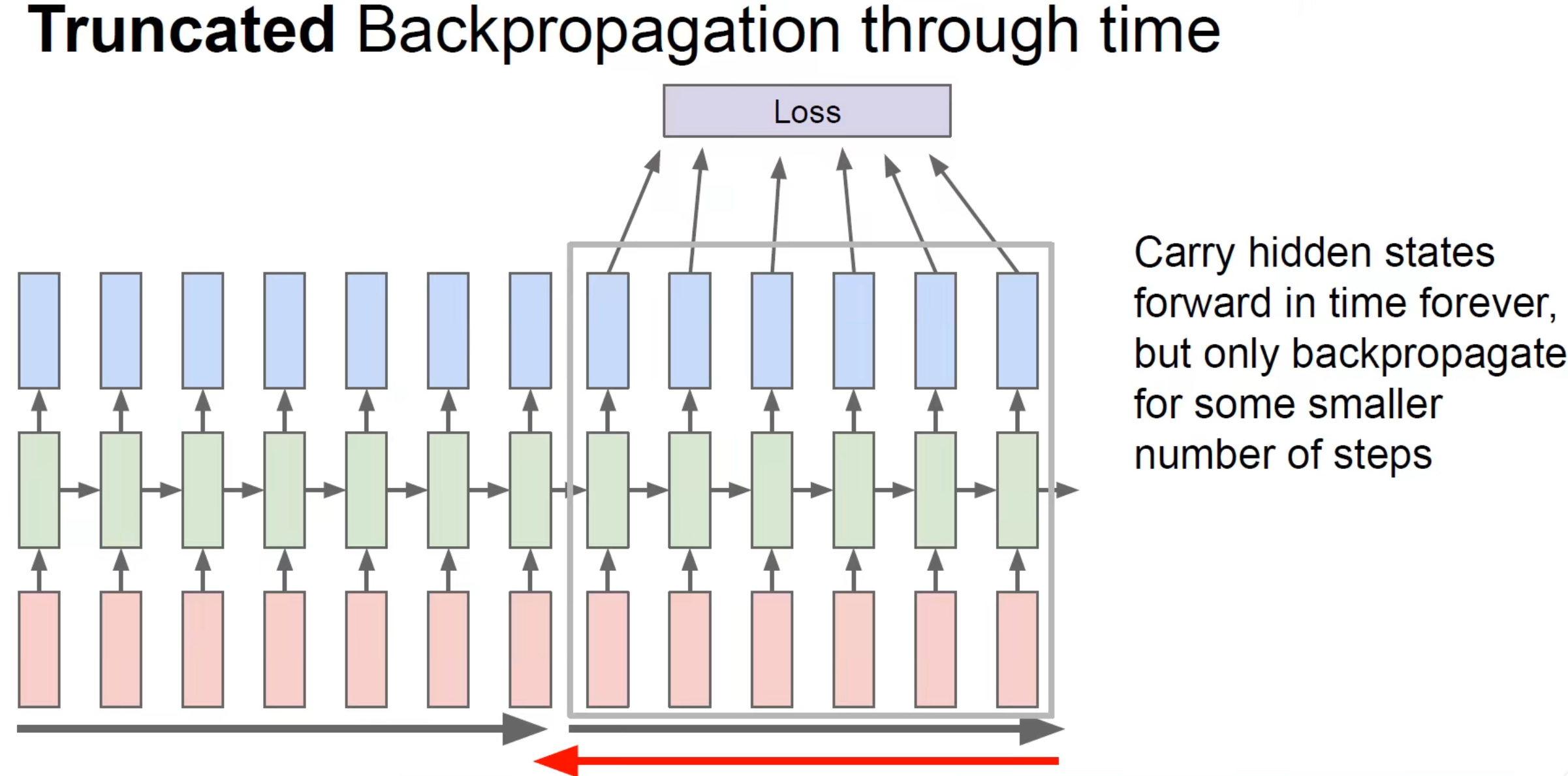
Different values in different hidden layers are responsible for different features in the corpus, so the more hidden states, the better the model can capture the underlying features of the text.
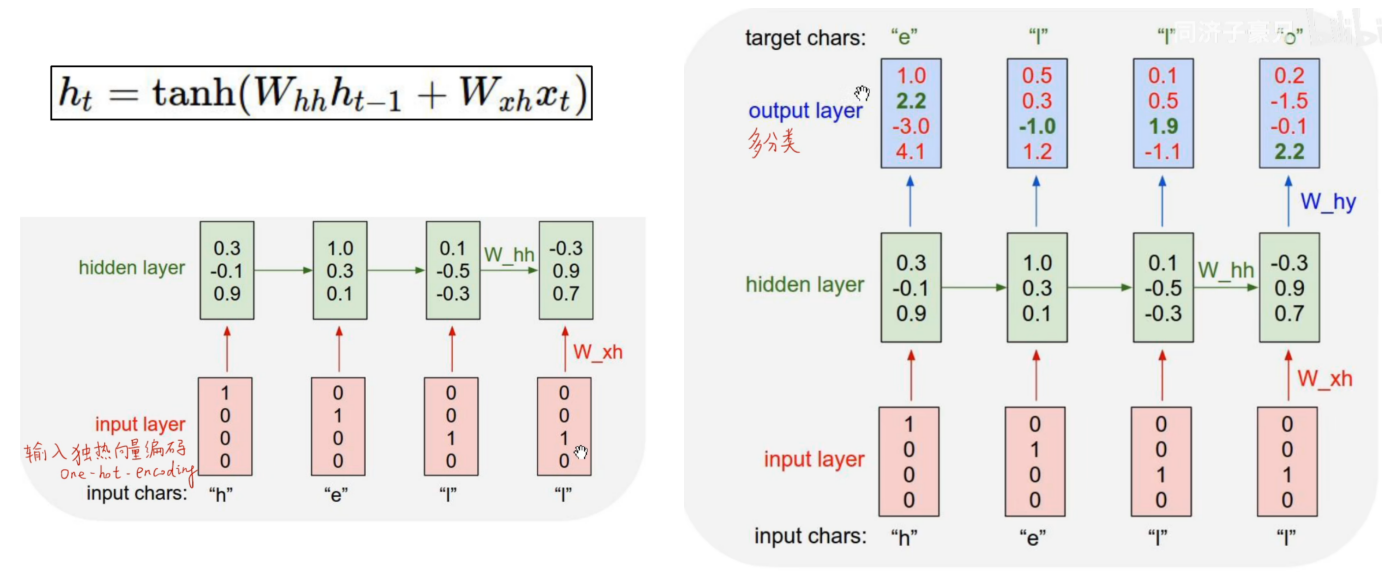
Let's look at an example: character-level language model (predicted by the above):
I want to input hell, and then the model predicts that I will output o; or I input h, the model outputs e, I input e again, and the model outputs l...
First Perform one-hot encoding on h, e, l, o, and then build a model for training.

Input Shakespeare's script, let the model generate the script by itself, the training process:

Enter the latex text and let the model generate the content by itself. The formula is well written, so I don’t know if it’s right:

Of course, enter the code, and the model will also output the code. So the essence of the hot Chatgpt now is RNN.
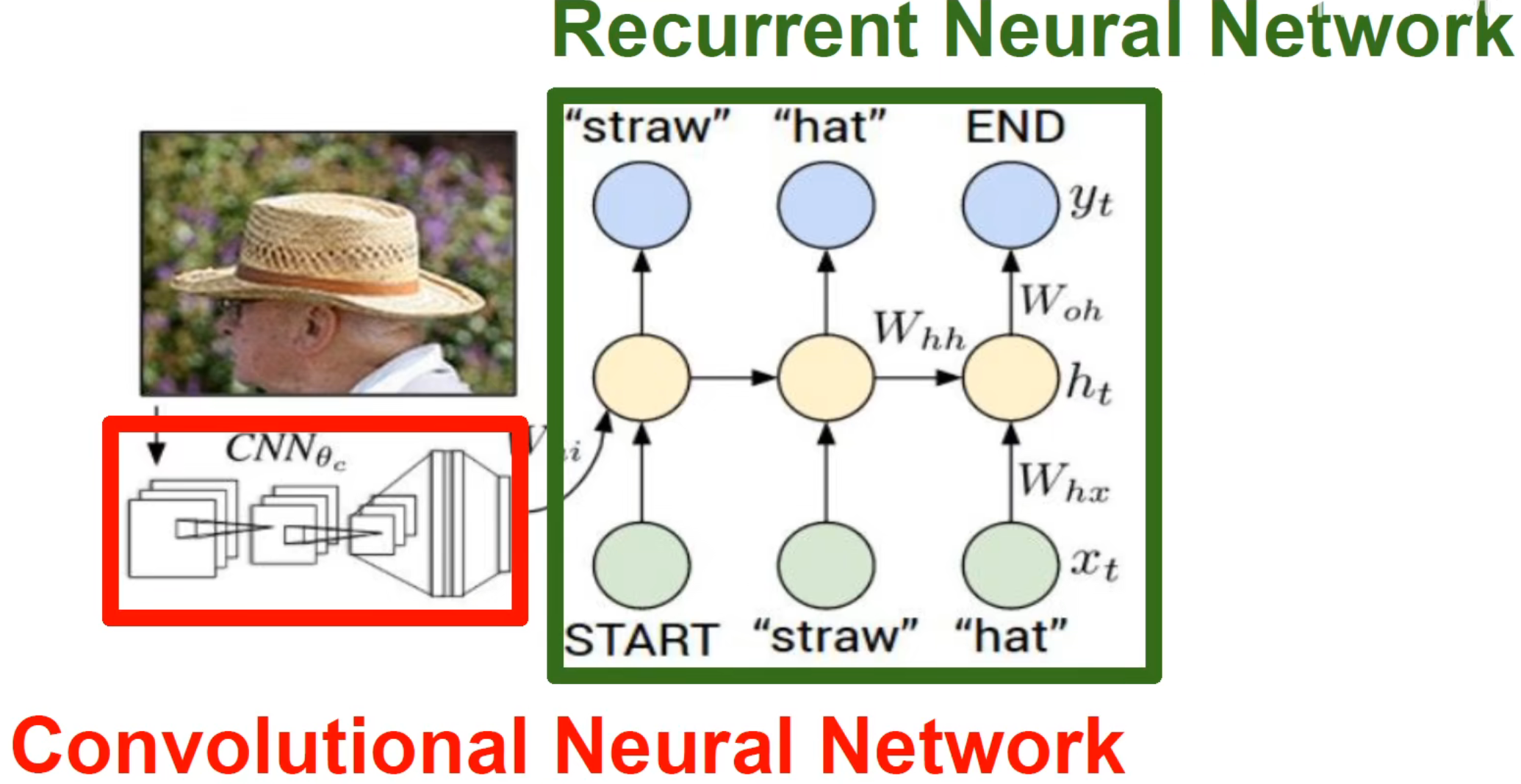
For image description, experts will first use CNN to extract features from the image (encoder), and then input the features into RNN for image description (decoder) .

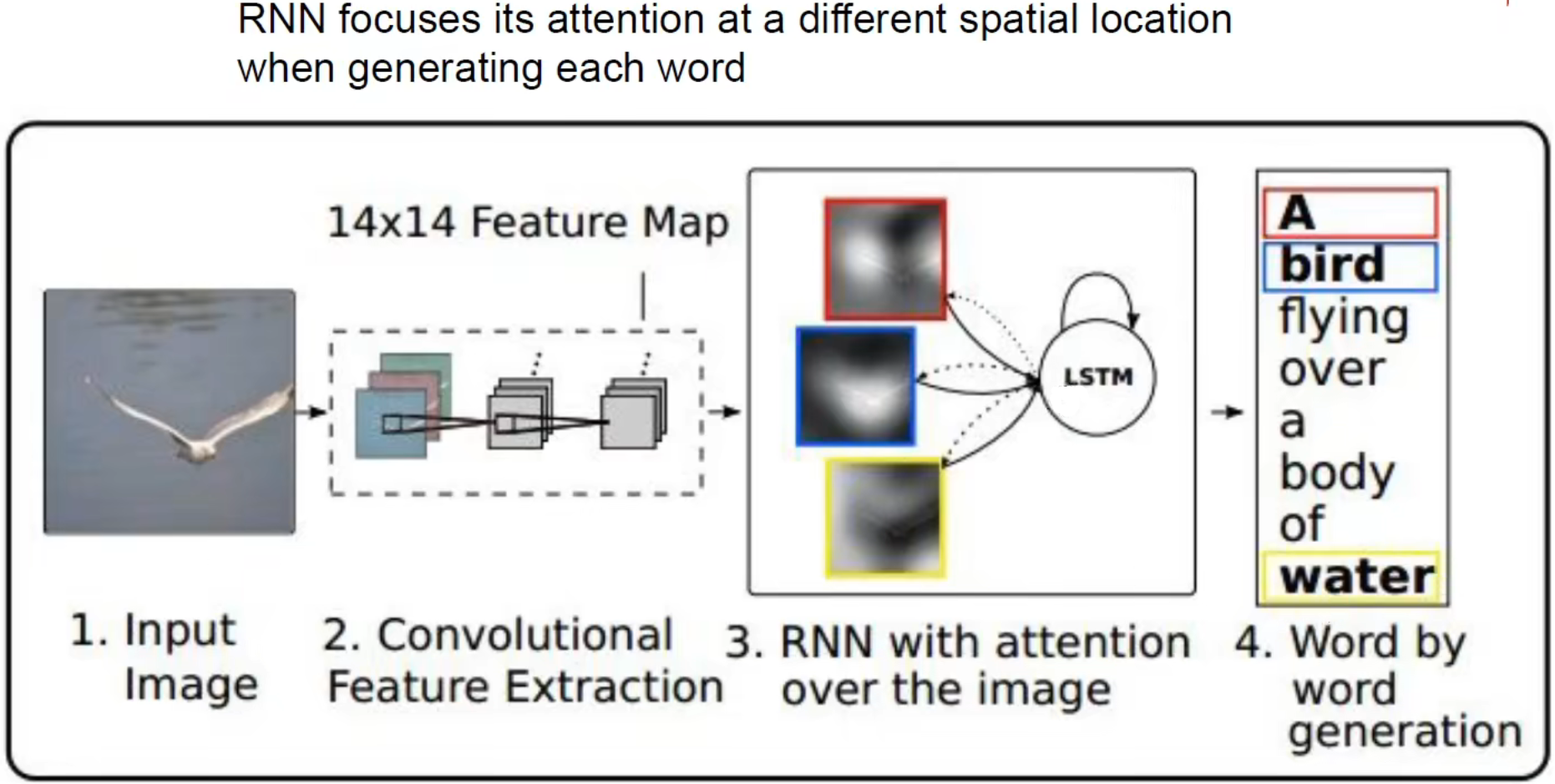
You can also combine the attention mechanism (Image captioning with attention):
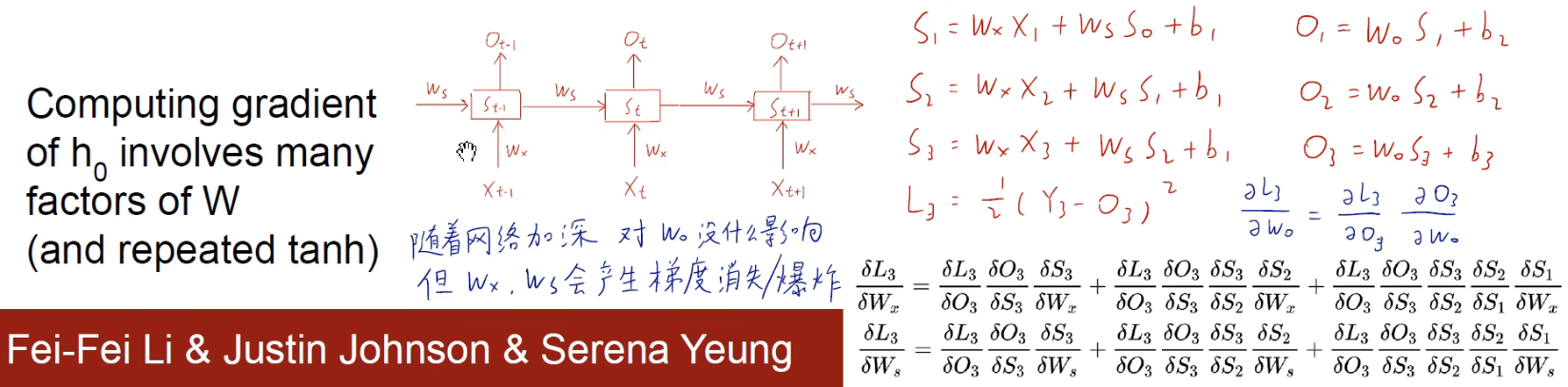
Once the hidden layers of ordinary stacked RNN become more and more deep, the gradient disappears/explodes easily during backpropagation .
Brother Zihao summed it up very well. From the perspective of the simplest three-layer network, the loss function L3 can be listed for the output O3, and the partial derivative of L3 can be calculated for the output weight w0, the input weight wx, and the past weight ws respectively. Seek guidance. We find that taking the partial derivative with respect to w0 is easy. However, partial derivatives of input weights wx and past weights ws can be painful due to the chain rule. In the expression, for the chain derivation of the earlier layer, the more product terms, so it is easy for the gradient to disappear/explode , and the gradient disappears in the majority.
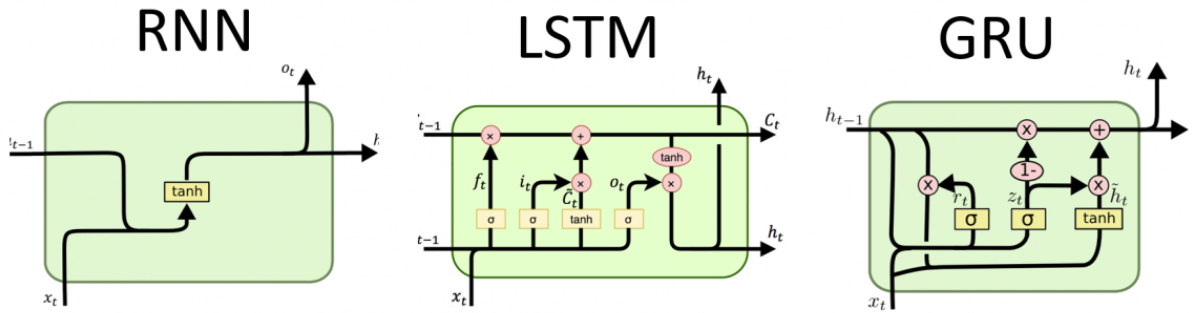
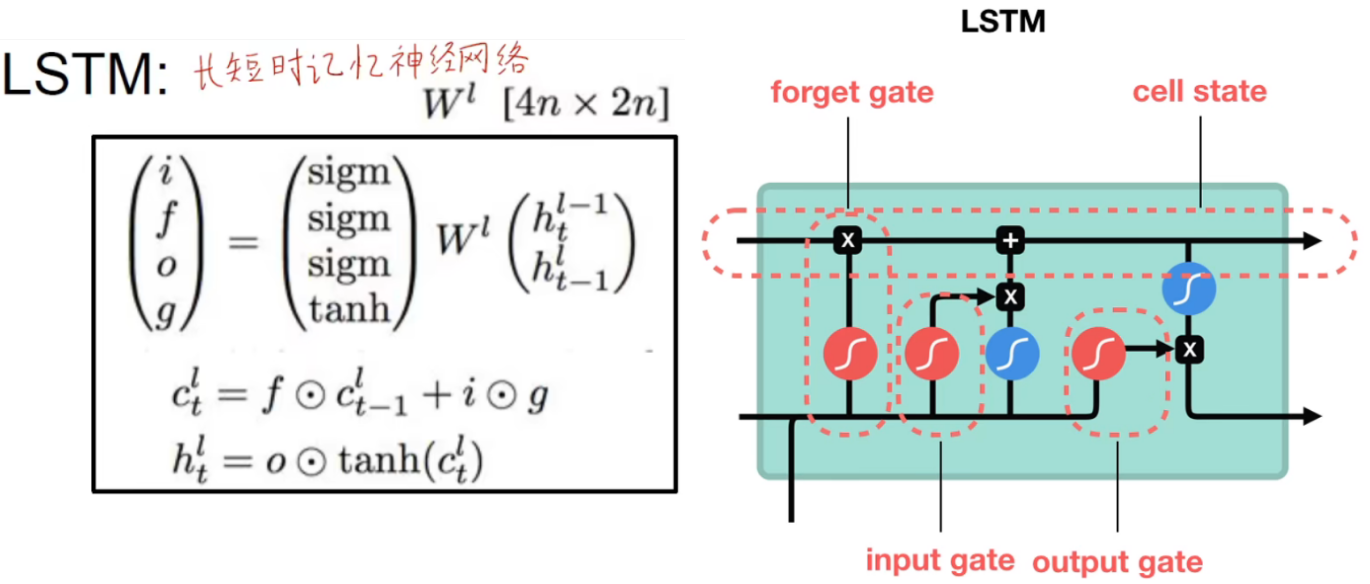
LSTM(Long Short-Term Memory)
Long short-term memory neural network (LSTM) came into being!
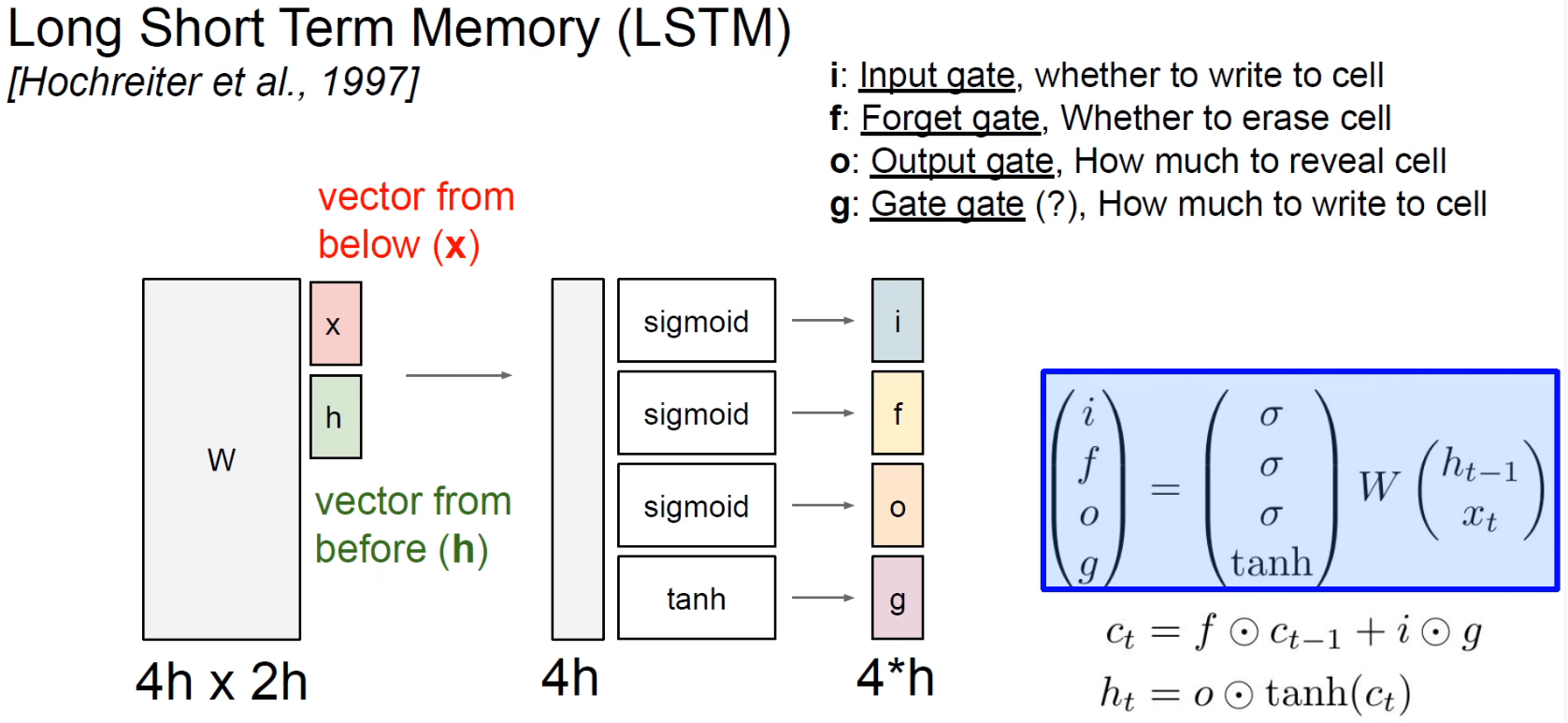
LSTM has both long-term memory and short-term memory, including forget gate, input gate, output gate, and long-term memory unit. The red function on the right is sigmoid, and the blue function is tanh.
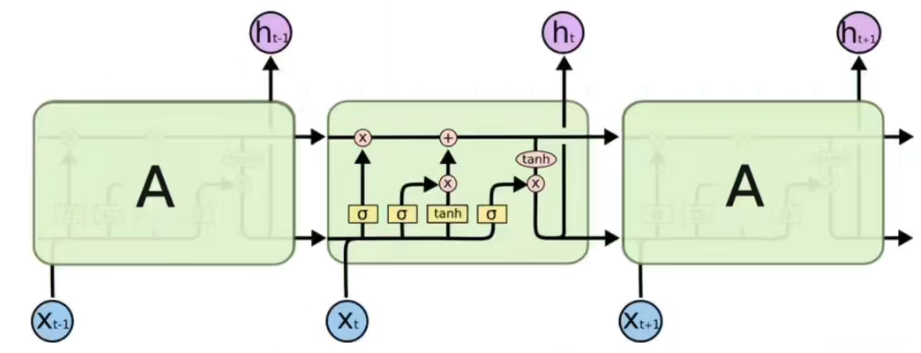
C is long-term memory and h is short-term memory.
So the current output ht is produced by short-term memory.

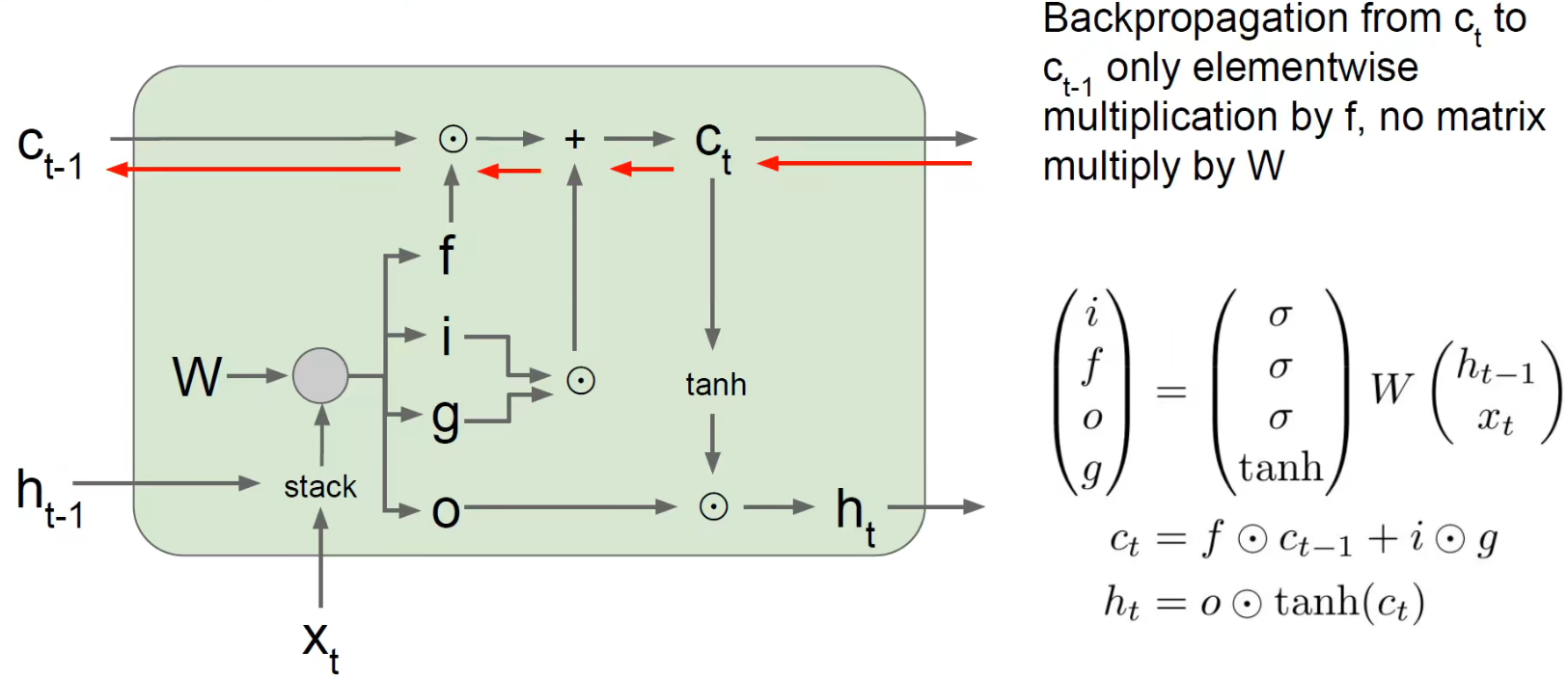
We see that the line of long-term memory is connected, and there are only multiplication and addition operations.
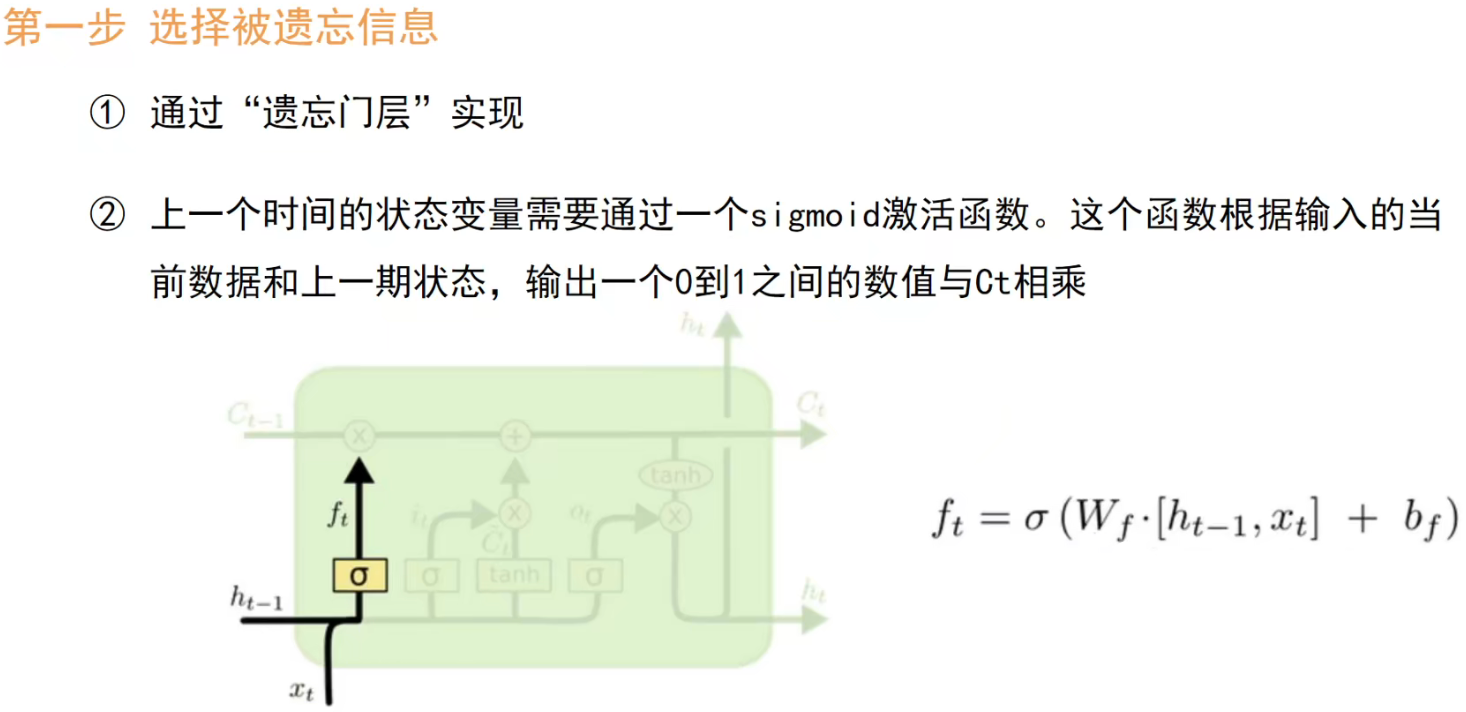
Detailed explanation of LSTM algorithm:
The following pictures perfectly explain:
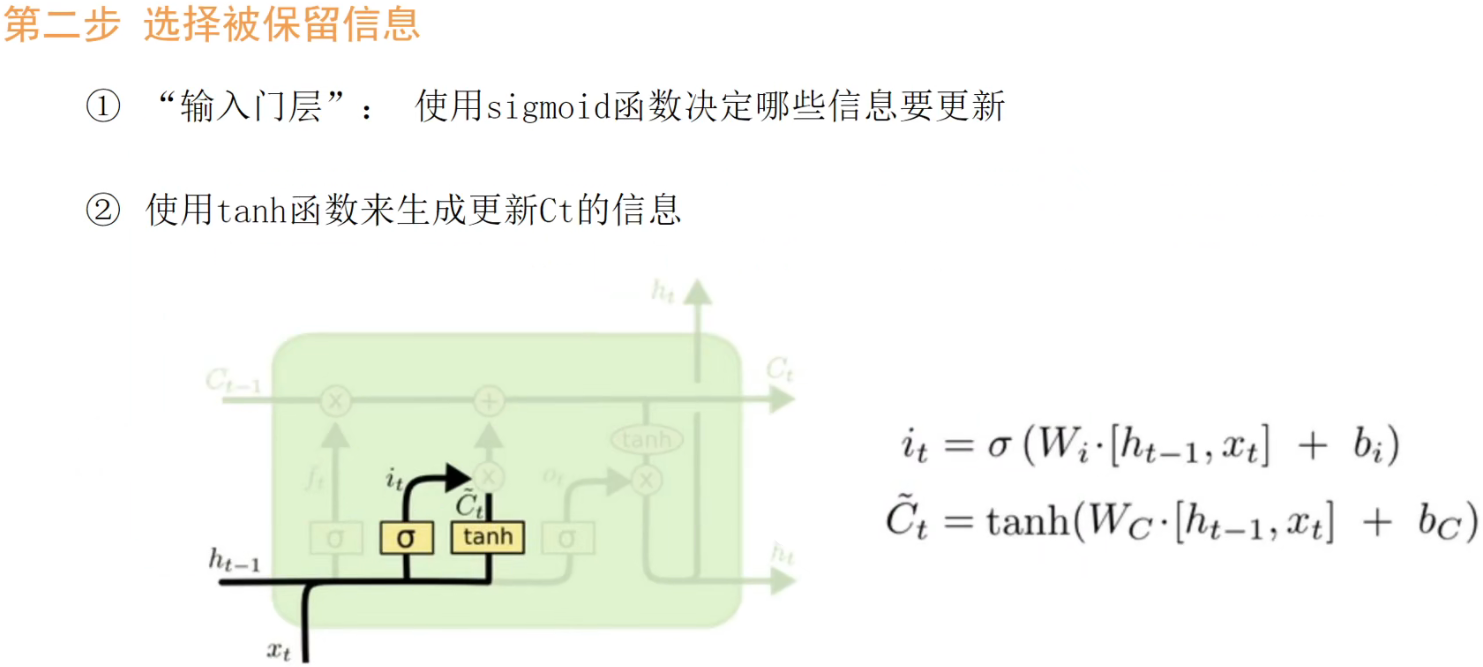
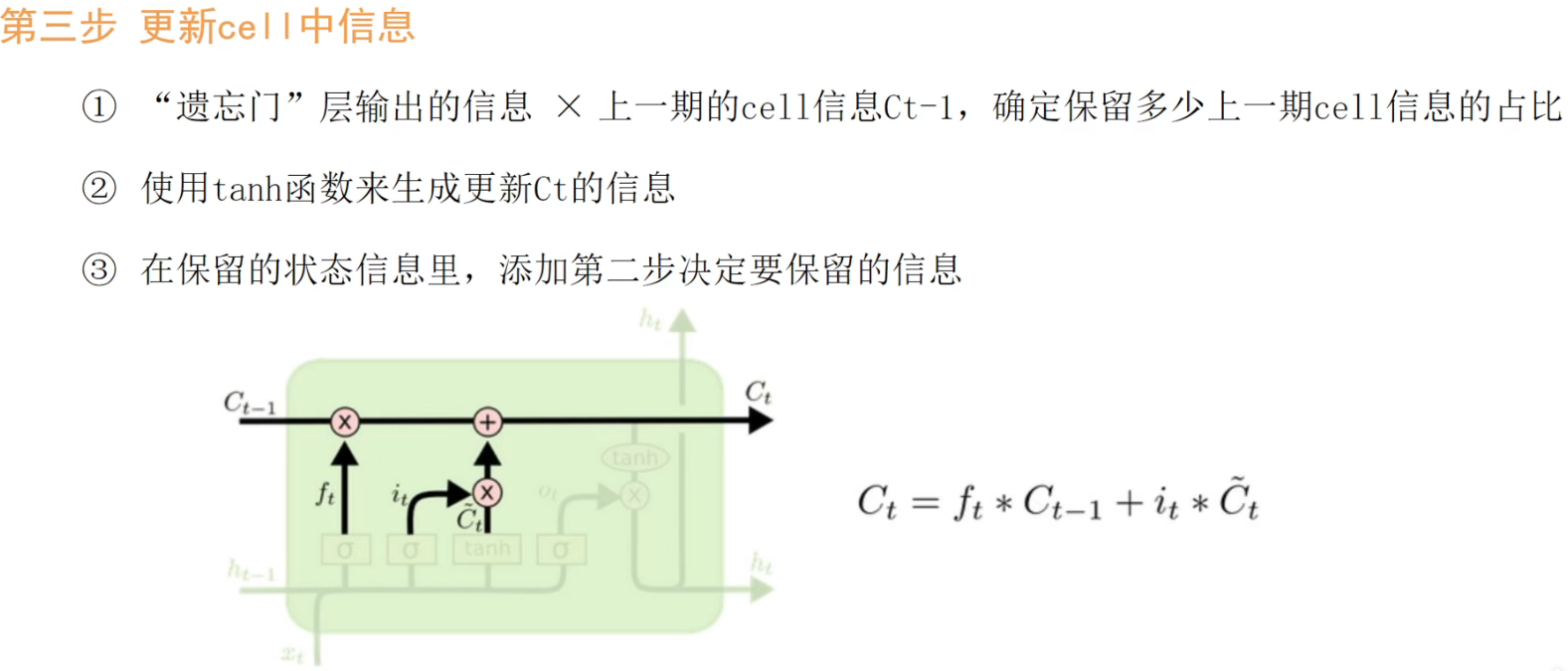
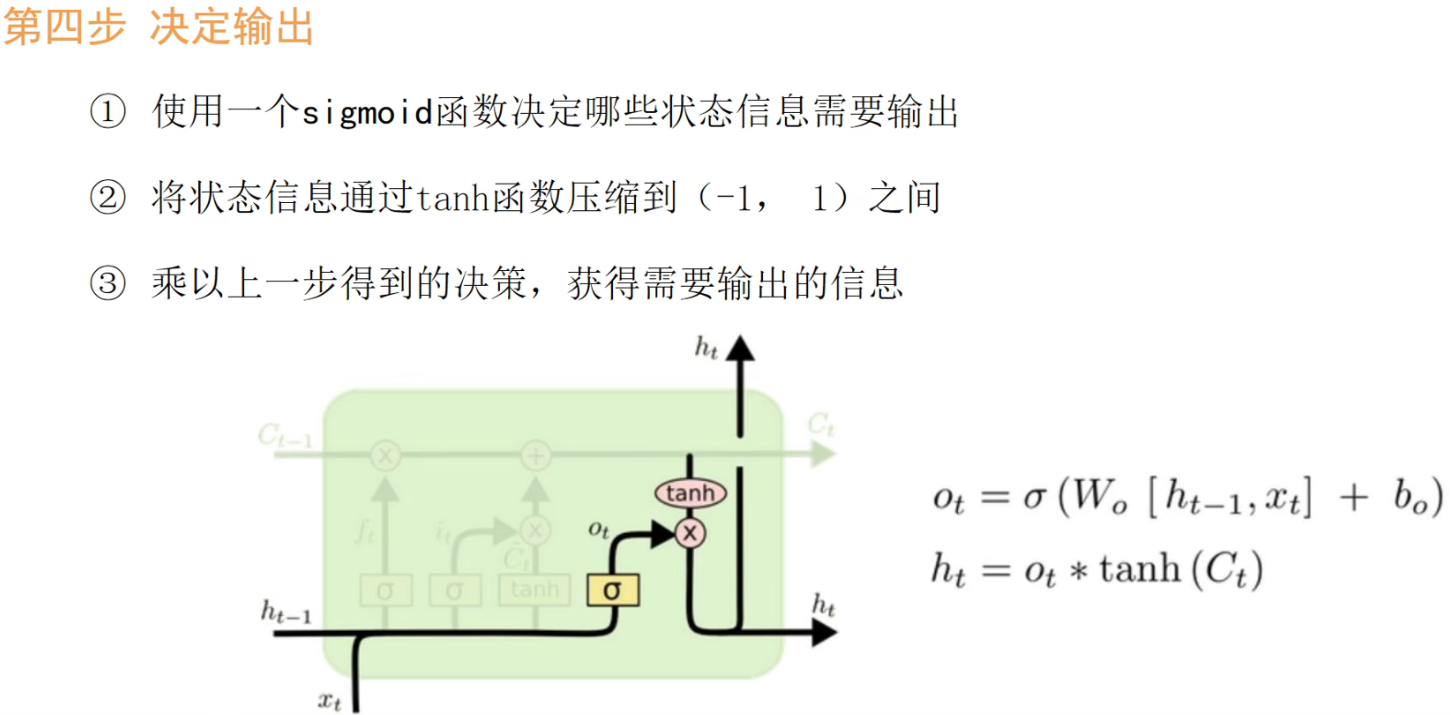
So there are four weights in total: Wf, Wi, Wc, Wo , and of course their corresponding bias terms.
The overall process can be summarized as: forgetting, updating, and outputting. (Updating includes choosing to keep the information before updating the latest memory.)
The graph in the original paper is also very vivid:
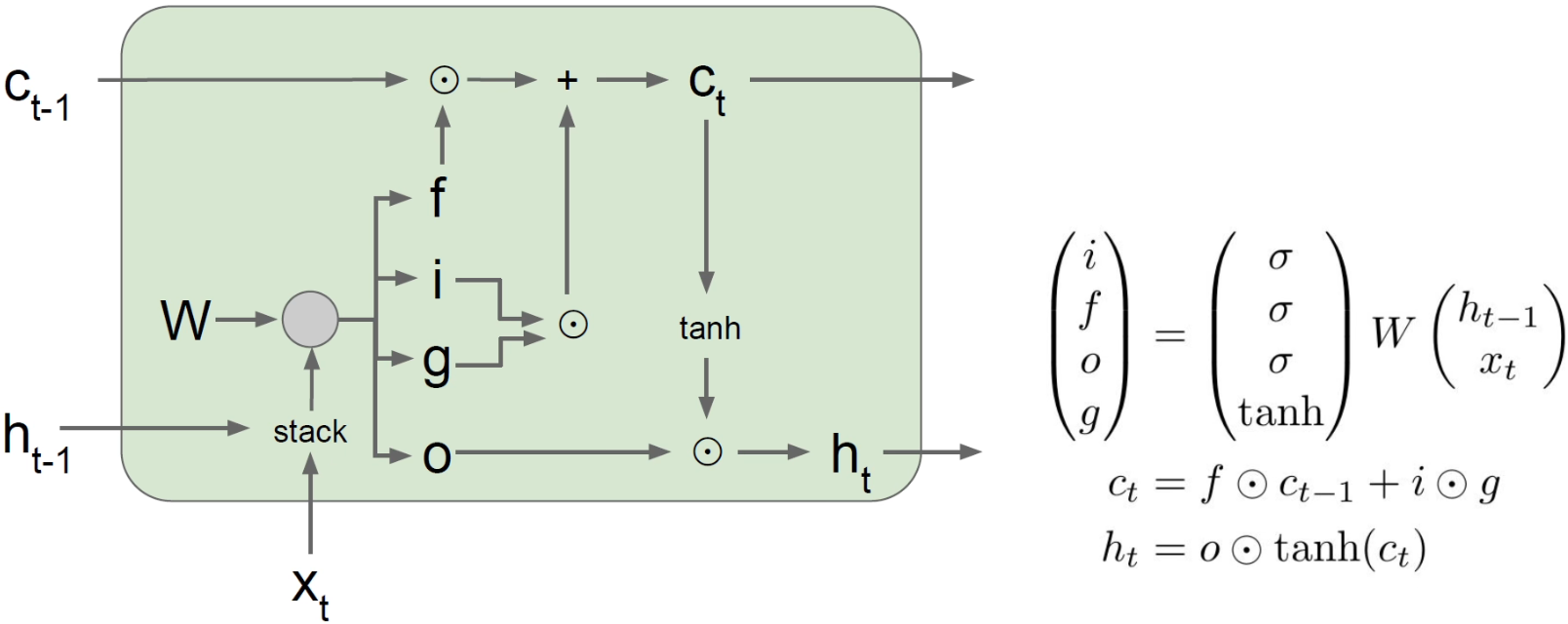
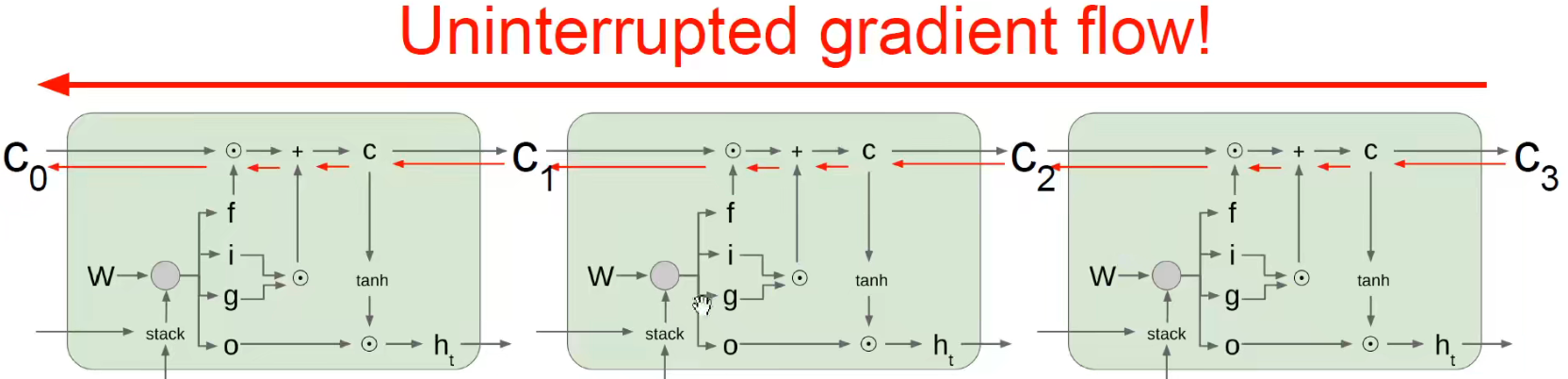
Now it is comfortable to backpropagate and find partial derivatives

GRU(Gated Recurrent Unit)
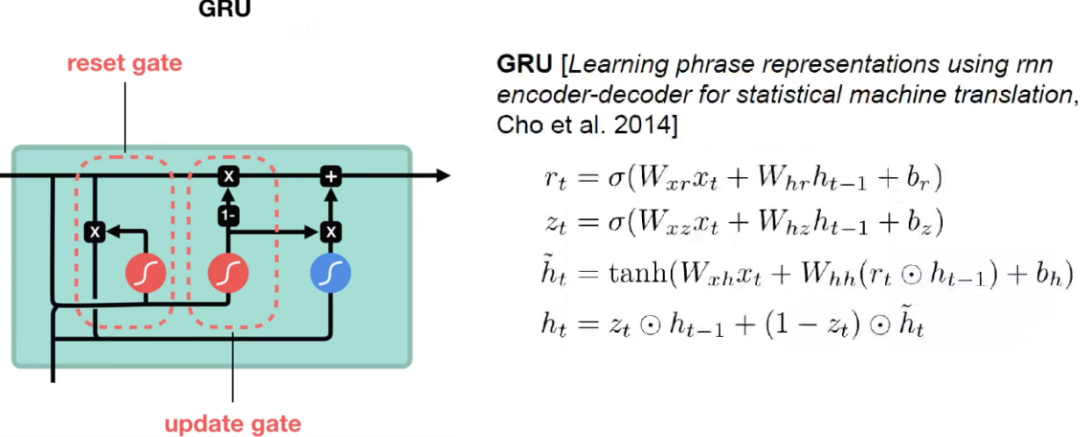
GRU can also solve the problem of gradient disappearance very well. The structure is simpler, mainly reset gate and update gate .

GRU vs. LSTM:
- Number of parameters: The number of parameters of GRU is less than that of LSTM, because it combines the input gate, forget gate and output gate in LSTM into one gating unit, thereby reducing the number of model parameters.
There are three gating units in LSTM : input gate, forget gate and output gate. Each gated unit has its own weight matrix and bias vector. These gating units are responsible for controlling the inflow and outflow of historical information.
There are only two gating units in the GRU : the update gate and the reset gate. They share a weight matrix and a bias vector. The update gate controls the influence of the current input and the output of the previous moment on the output of the current moment, while the reset gate controls the influence of the output of the previous moment on the current moment. - Calculation speed: Due to the smaller number of parameters, the calculation speed of GRU is faster than that of LSTM.
- Long sequence modeling: LSTM is better when dealing with long sequence data. Due to the introduction of a long-term memory unit (Cell State) in LSTM, it can better deal with the gradient disappearance and gradient explosion problems in long sequences.
GRU is suitable for:
processing simple sequence data, such as language models and text generation tasks.
Tasks that require fast training and inference when processing sequence data, such as real-time speech recognition, speech synthesis, etc.
For scenarios with limited computing resources, such as embedded devices, mobile devices, etc.
LSTM is suitable for:
processing complex sequence data, such as long text classification, machine translation, speech recognition and other tasks.
Process sequence data that requires long-term dependencies, such as long text, long speech, etc.
Scenarios that require high accuracy, such as stock forecasting, medical diagnosis, etc.