This article originated from the public account [Exploration of High-Performance Architecture]. This public account is dedicated to sharing dry goods, hard goods and bug analysis at work. Welcome to pay attention. Reply [pdf] Free access to classic computer books
Hello, I'm Yule!
Recently, I have talked about Memory Orderrelevant knowledge in the group. It just so happens that my understanding of this area is vague and disorderly, so with the help of this article, I will reorganize the relevant knowledge.
written in front
Before really understanding the role of the Memory Model, it was a misunderstanding to simply equate the Memory Order with mutex and atomic for inter-thread data synchronization, or to limit the execution order between threads. It wasn't until after careful study of Memory Order that it was discovered that Memory Order was not the same thing as them in terms of function or principle. In fact, Memory Order is used to constrain the ordering of memory access in the same thread, although the rearrangement of the code order in the same thread will not affect the execution results of this thread (if the results are not consistent, then the rearrangement will It doesn't make sense), but in a multi-threaded environment, the data access order changes caused by rearrangement will affect the access results of other threads.
It is for the above reasons that the memory model is introduced. The problem solved by the C++ memory model is how to reasonably limit the code execution order in a single thread, so that the computing power of the CPU can be maximized without using locks, and logic will not appear in a multi-threaded environment. mistake.
command out of order
Today's CPUs use multi-core and multi-thread technology to improve computing power; methods such as out-of-order execution, pipeline, branch prediction, and multi-level cache are used to improve program performance. While multi-core technology improves program performance, it also brings out-of-order execution sequence and out-of-order memory sequence access. At the same time, the compiler will also optimize the code based on its own rules, and these optimization actions will also cause the order of some code to be rearranged.
First, let's look at a piece of code, as follows:
int A = 0;
int B = 0;
void fun() {
A = B + 1; // L5
B = 1; // L6
}
int main() {
fun();
return 0;
}
If used g++ test.cc, the generated assembly instructions are as follows:
movl B(%rip), %eax
addl $1, %eax
movl %eax, A(%rip)
movl $1, B(%rip)
Through the above instructions, we can see that first put B into eax, then put eax+1 into A, and finally execute B + 1.
And if we use g++ -O2 test.cc, the generated assembly instructions are as follows:
movl B(%rip), %eax
movl $1, B(%rip)
addl $1, %eax
movl %eax, A(%rip)
It can be seen that first put B in eax, then execute B = 1, then execute eax + 1, and finally assign eax to A. It can be seen from the above instructions that the B assignment statement (statement L6) is executed before the A assignment statement (statement L5).
We call the above-mentioned instruction method that is not executed in code order 指令乱序.
For instruction out-of-order, it should be noted that the compiler only needs to ensure that the execution results are eventually consistent in a single-threaded environment . Therefore, instruction out-of-order is completely allowed in a single-threaded environment. For the compiler, it only knows: in the current thread, the reading and writing of data and the dependencies between data. However, the compiler doesn't know which data is shared between threads and may be modified . And these need to be guaranteed by developers.
So, does instruction reordering allow developers to control it, rather than letting the compiler optimize it at will?
You can use compilation options to stop such optimizations, or use precompiled instructions to separate code that you don't want to be rearranged, such as available under gcc asm volatile, as follows:
void fun() {
A = B + 1;
asm volatile("" ::: "memory");
B = 0;
}
Similarly, the processor will also provide instructions for developers to use to avoid out-of-order control. For example, the instructions on x86 and x86-64 are as follows:
lfence (asm), void _mm_lfence(void)
sfence (asm), void _mm_sfence(void)
mfence (asm), void _mm_mfence(void)
Why do you need a memory model
The multi-threading technology is to squeeze the cpu to the maximum extent and improve the computing power. In the single-core era, the concept of multithreading is that 宏观上并行,微观上串行multiple threads can access the same CPU cache and the same set of registers. But in the multi-core era, multiple threads may execute on different cores, each CPU has its own cache and registers, and threads executing on one CPU cannot access the cache and registers of another CPU. The CPU reorders the memory interactions of machine instructions according to certain rules, specifically allowing each processor to delay stores and load data from different locations. At the same time, the compiler will also optimize the code based on its own rules, and these optimization actions will also cause the order of some code to be rearranged. Although this kind of instruction rearrangement does not affect the execution result of a single thread, it will aggravate the problem of data race (Data Race) when multiple threads access shared data.
The two variables A and B in the example in the above section are taken as an example. After the compiler shuffles them, although it is no problem for the current thread. However, in a multi-threaded environment, if other threads depend on A and B, 竞争the problem of multi-thread access to shared data will be exacerbated, and unexpected results may be obtained.
It is precisely because of the out-of-order instructions and the uncertainty of data competition in a multi-threaded environment that we often use semaphores or locks to achieve synchronization requirements during development, thereby solving the uncertainty caused by data competition. However, locking or semaphores are relatively close to the underlying primitives of the operating system. Each locking or unlocking may cause the user state and kernel state to switch between each other, which leads to data access overhead. If the lock is used improperly, it may It will cause serious performance problems, so a language-level mechanism is needed, which does not have the large overhead of locks and can meet the requirements of data access consistency. In 2004, Java 5.0 began to introduce a memory model suitable for multi-threaded environments, while C++ did not start to introduce it until C++11.
** Herb Sutter ** evaluates the memory model introduced by C++11 in his article:
The memory model means that C++ code now has a standardized library to call regardless of who made the compiler and on what platform it’s running. There’s a standard way to control how different threads talk to the processor’s memory.
“When you are talking about splitting [code] across different cores that’s in the standard, we are talking about the memory model. We are going to optimize it without breaking the following assumptions people are going to make in the code,” Sutter said
It can be seen from the content that the significance of the introduction of the Memory model in C++11 is that there is a standard library at the language level that is independent of the operating platform and compiler, allowing developers to control the memory access sequence more conveniently and efficiently.
In a word, there are several reasons for introducing the memory model:
- Compiler optimization: In some cases, even simple statements are not guaranteed to be atomic
- CPU out-of-order: CPU may adjust the execution order of instructions for performance
- CPU Cache Inconsistency: Under the influence of CPU Cache, instructions executed under a certain CPU will not be seen by other CPUs immediately
relational term
In order to better understand the following content, we need to understand several relational terms.
sequenced-before
sequenced-before is a relationship on a single thread, which is an asymmetric, transitive pairwise relationship.
Before understanding sequenced-before, we need to look at a concept evaluation(求值).
Evaluation of an expression (evaluation), consists of the following two parts:
- value computations: calculation of the value that is returned by the expression. This may involve determination of the identity of the object (glvalue evaluation, e.g. if the expression returns a reference to some object) or reading the value previously assigned to an object (prvalue evaluation, e.g. if the expression returns a number, or some other value)
- Initiation of side effects: access (read or write) to an object designated by a volatile glvalue, modification (writing) to an object, calling a library I/O function, or calling a function that does any of those operations.
The simple understanding of the above content is that value computation is to calculate the value of an expression, and side effect is to read and write objects.
For C++, the language itself does not specify the order of evaluation of expressions, so for expressions like f1() + f2() + f3(), the compiler can decide which function to execute first, and then follow the addition operation The rules are added from left to right, so the compiler may optimize to become (f1() + f2()) + f(3), but both f1() + f2() and f3() can be executed first.
You can often see code like this:
i = i++ + i;
It is precisely because the language itself does not specify the evaluation order of expressions, so the order of the two subexpressions (i++ and i) in the above code cannot be determined, so the behavior of this statement is undefined.
sequenced-before is 同一个线程内a description of the evaluation sequence relationship:
- If A sequenced-before B, it means that the evaluation of A will be completed before the evaluation of B
- If A is not sequenced-before B, but B sequenced-before A, it means that B is evaluated first, and then A is evaluated
- If A is not sequenced-before B, and B is not sequenced-before A, both A and B may be executed first, or even at the same time
happens-before
happens-before is an extension of sequenced-before, because it also includes the relationship between different threads. When A operates happens-before B operation, operation A is executed before operation B, and the result of operation A is visible to B.
Look cppreferenceat the definition of the happens-before relationship, as follows:
Regardless of threads, evaluation A happens-before evaluation B if any of the following is true:
\1) A is sequenced-before B
\2) A inter-thread happens before B
As can be seen from the above definition, happens-before includes two situations, one is the happens-before relationship in the same thread (equivalent to sequenced-before), and the other is the happens-before relationship of different threads.
For happens-before in the same thread, it is equivalent to sequenced-before, so ignore it here and focus on it 线程间的happens-before关系.
Suppose there is a variable x, which is initialized to 0, as follows:
int x = 0;
At this time, there are two threads running at the same time, thread A performs ++x operation, and thread B prints the value of x. Because the two threads do not have happens-beforea relationship, that is 没有保证++x操作对于打印x的操作是可见的, the printed value may be 0 or 1.
For this kind of scenario, the language itself must provide appropriate means to enable developers to achieve the happens-before relationship in multi-threaded scenarios, and then get correct running results. This is the second point A inter-thread happens before B mentioned above .
C++ defines five scenarios where cross-thread happens-before can be established, as follows:
- A synchronizes-with B
- A is dependency-ordered before B
- A synchronizes-with some evaluation X, and X is sequenced-before B
- A is sequenced-before some evaluation X, and X inter-thread happens-before B
- A inter-thread happens-before some evaluation X, and X inter-thread happens-before B
synchronizes-with
Synchronized-with describes the synchronization relationship between different threads. When thread A is synchronized-with thread B, it means that thread A's operation on a certain variable or memory is visible to thread B. In other words, synchronized-with就是跨线程版本的happens-before.
Suppose in a multi-threaded environment, thread A x = 1writes to variable x, and thread B reads the value of x. Without any synchronization, even if thread A executes first and thread B executes later, the value of x read by thread B is not necessarily the latest value. This is because in order to make the program more efficient, the compiler or CPU has 指令乱序optimized it, and it is also possible that the modified value of A 寄存器thread is included or stored in CPU cache中,还没来得及写入内存. It is precisely because of various operations that in a multi-threaded environment, if there are read and write operations at the same time, it is necessary to perform synchronization operations on the variable or memory.
Therefore, synchronizes-with is such a relationship that it can ensure that the write operation result of thread A is visible in thread B.
On page 12 of the 2014 C++ official standard document (Standard for Programming Language C++) N4296, it is suggested that the synchronization operation provided by C++ is to use atomic or mutex:
The library defines a number of atomic operations and operations on mutexes that are specially identified as synchronization operations. These operations play a special role in making assignments in one thread visible to another.
memory_orde
C++11 introduces six memory constraints to solve the memory consistency problem under multi-threading (in the header file), which are defined as follows:
typedef enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
} memory_order;
These six memory constraints can be divided into the following three types from the perspective of reading/writing:
- Read operation (memory_order_acquire memory_order_consume)
- Write operation (memory_order_release)
- Read-modify-write operation (memory_order_acq_rel memory_order_seq_cst)
ps: Because memory_order_relaxed does not define synchronization and ordering constraints, it does not fit this category.
For example, since store is a write operation, it makes sense storeto specify memory_order_relaxedeither when calling. And specifying is meaningless.memory_order_releasememory_order_seq_cstmemory_order_acquire
From the perspective of access control, it can be divided into the following three types:
- Sequential consistency模型(memory_order_seq_cst)
- Relax model (memory_order_relaxed)
- Acquire-Release模型(memory_order_consume memory_order_acquire memory_order_release memory_order_acq_rel)
In terms of the strength of access control, the Sequential consistency model is the strongest, followed by the Acquire-Release model, and the Relax model is the weakest.
In the following content, these 6 constraints will be combined to further analyze the memory model.
memory model
Sequential consistency model
The Sequential consistency model, also known as the sequential consistency model, is the memory model with the strictest control granularity. It can be traced back to the paper " How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs " published by Leslie Lamport in September 1979 , in which the definition was proposed for the first time :Sequential consistency
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program
According to this definition, under the sequential consistency model, the execution order of the program is strictly consistent with the code order, that is, in the sequential consistency model, there is no order disorder.
The constraint symbol corresponding to the sequential consistency model is memory_order_seq_cst. This model has the strongest consistency control for memory access sequence. It is similar to the easy-to-understand mutex lock mode, and the first to get the lock is the first to access.
Suppose there are two threads, namely thread A and thread B, then there are three execution situations of these two threads: the first one is that thread A executes first, and then executes thread B; the second situation is that thread B executes first, Then execute thread A; the third case is that thread A and thread B are executed concurrently, that is, the code sequence of thread A and the code sequence of thread B are executed alternately. Although there may be a third case of alternate code execution, purely from the perspective of thread A or thread B, the code execution of each thread should be executed in code order, which is the sequential consistency model. To sum it up:
- The execution order of each thread is strictly consistent with the code order
- The order of execution of threads may alternate, but from the perspective of a single thread, execution is still sequential
In order to facilitate the understanding of the above content, an example is as follows:
x = y = 0;
thread1:
x = 1;
r1 = y;
thread2:
y = 1;
r2 = x;
Because the execution sequence of multi-threads may be interleaved, the execution sequence of the above example may be:
- x = 1; r1 = y; y = 1; r2 = x
- y = 1; r2 = x; x = 1; r1 = y
- x = 1; y = 1; r1 = y; r2 = x
- x = 1; r2 = x; y = 1; r1 = y
- y = 1; x = 1; r1 = y; r2 = x
- y = 1; x = 1; r2 = x; r1 = y
That is to say, although in a multi-threaded environment, the execution order is chaotic, but from the perspective of thread 1, the execution order is x = 1; r1 = y; from the perspective of thread 2, the execution order is y = 1; r2 = x.
std::atomic operations all use memory_order_seq_cst as the default value. If you are not sure which memory access model to use, use memory_order_seq_cst to ensure that there is no error.
All operations of sequential consistency are performed in the order specified by the code, which is in line with the developer's thinking logic, but this strict ordering also limits the ability of modern CPUs to use hardware for parallel processing, which will seriously hinder the performance of the system.
Relax model
The Relax model corresponds to the one in memory_order memory_order_relaxed. It can be seen from its literal meaning that it has the least restriction on memory order, that is to say, this method can only ensure that the current data access is an atomic operation (not interrupted by operations of other threads) , but the order of memory access There are no constraints, which means that reads and writes to different data may be reordered.
In order to facilitate the understanding of the Relax model, let us give a simple example, the code is as follows:
#include <atomic>
#include <thread>
#include <iostream>
std::atomic<bool> x{false};
int a = 0;
void fun1() { // 线程1
a = 1; // L9
x.store(true, std::memory_order_relaxed); // L10
}
void func2() { // 线程2
while(!x.load(std::memory_order_relaxed)); // L13
if(a) { // L14
std::cout << "a = 1" << std::endl;
}
}
int main() {
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}
In the above code, thread 1 has two code statements. Statement L9 is a simple assignment operation, and statement L10 is an memory_order_relaxedatomic write operation with a mark. Based on the reorder principle, the order of these two sentences is not determined, so it cannot be guaranteed which one is in Which is the front and which is the back. As for thread 2, there are also two code sentences, which are respectively the labeled memory_order_relaxedatomic read operation L13 and the simple judgment output statement L14. It should be noted that the order of statement L13 and statement L14 is determined, that is, statement L13 happens-before statement L14, which is determined by while循环代码语义保证的. In other words, the while statement is executed prior to the following statements, which is the rearrangement rule of the compiler or CPU.
For the above example, our first impression would output a = 1this sentence. But in reality, there may be no output. This is because in thread 1, due to the out-of-order rearrangement of instructions, it may cause L10 to be executed first, and then statement L9 to be executed. If combined with thread 2 to analyze, the execution order of these 4 code sentences may be #L10–>L13–>L14–>L9, so we cannot get the result we want.
So now memory_order_relaxed不能保证执行顺序, what are their usage scenarios? This requires the use of its feature that only guarantees that the current data access is an atomic operation , which is usually used in some statistical counting requirements scenarios, the code is as follows:
#include <cassert>
#include <vector>
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<int> cnt = {0};
void fun1() {
for (int n = 0; n < 100; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
void fun2() {
for (int n = 0; n < 900; ++n) {
cnt.fetch_add(1, std::memory_order_relaxed);
}
}
int main() {
std::thread t1(fun1);
std::thread t2(fun2);
t1.join();
t2.join();
return 0;
}
After the above code is executed, cnt == 1000.
In general, relaxed memory orders have the least synchronization overhead compared to other memory orders. However, because the synchronization overhead is small, this leads to uncertainty, so we choose the appropriate memory order option according to our own usage scenarios during the development process.
Acquire-Release model
The control strength of the Acquire-Release model is between the Relax model and the Sequential consistency model. It is defined as follows:
- Acquire: If an operation X has acquire semantics, then all read and write instructions after operation X will not be reordered to before operation X
- Release: If an operation X has release semantics, all read and write instructions before operation X will not be reordered after operation X
Combined with the above definition, reinterpret the model: Suppose there is an atomic variable A, synchronize the write operation (Release) and read operation (Acquire) of A, and establish a sorting constraint relationship, that is, for the write operation (release) X, all read and write instructions before the write operation X cannot be placed after the write operation X; for the read operation (acquire) Y, all read and write instructions after the read operation Y cannot be placed before the read operation Y.
The Acquire-Release model corresponds to memory_order_consume, memory_order_acquire, memory_order_release, and memory_order_acq_rel among the six constraint relationships. Some of these constraint relationships can only be used for read operations (memory_order_consume, memory_order_acquire), some are suitable for write operations (memory_order_release), and some skills can be used for both read operations and write operations (memory_order_acq_rel). These constraints cooperate with each other to achieve relatively strict memory access sequence control.
memory_order_release
Suppose there is an atomic variable A, and the memory_order_release constraint is imposed when it is written to X, then in the current thread T1, any read and write operation instructions before the operation X cannot be placed after the operation X. When another thread T2 reads the atomic variable A, the memory_order_acquire constraint is imposed, and any read and write operations before the write operation in the current thread T1 are visible to the thread T2; when another thread T2 executes the atomic variable A During the read operation, if the memory_order_consume constraint is imposed, the 依赖read and write operations of all atomic variables A in the current thread T1 are visible to the T2 thread (the order of memory operations without dependencies cannot be guaranteed).
It should be noted that for a write operation with a memory_order_release constraint, all read and write instructions before the write will not be reordered. The prerequisite after the write operation is: memory_order_acquire 其他线程对这个原子变量执行了读操作,且施加了or memory_order_consume constraint.
memory_order_acquire
When a load operation on an atomic variable , use the memory_order_acquire constraint: In the current thread , neither read nor write operations after the load can be rearranged before the current instruction. Operations on this atomic variable are visible in the current thread if other threads use memory_order_releasethe constraint .store
Suppose there is an atomic variable A, if the read operation X of A is marked with memory_order_acquire, then in the current thread T1, all read and write instructions after operation X cannot be rearranged before operation X; when other threads perform A For the write operation Y with the memory_order_release constraint applied, all read and write instructions before this write operation Y are visible to the current thread T1 ( 这里的可见请结合 happens-before 原则理解,即那些内存读写操作会确保完成,不会被重新排序). That is to say, from the perspective of thread T2, all memory writes that occur before the atomic variable A write operation will have an effect in thread T1. That is, once the atomic read is complete, thread T1 is guaranteed to see everything that thread A wrote to memory.
For ease of understanding, cppreferencethe examples in use are as follows:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire))); // L17
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
In the above example, the write operation (L12) of the atomic variable ptr is marked with memory_order_release, which means that in the thread producer, L10 and L11 will not be rearranged after L12; in the consumer thread, the atomic The memory_order_acquire flag is applied to the read operation L17 of the variable ptr, which means that L8 and L19 will not be rearranged before L17, which means that when the ptr read by L17 is not null, the operations of L10 and L11 in the producer thread It is visible to the consumer thread, so the assert in the consumer thread is true.
memory_order_consume
A load operation uses the memory_order_consume constraint: in the current thread , read and write operations that depend on this atomic variable after the load operation cannot be reordered before the current instruction. If other threads use memory_order_releasethe memory model to operate on this atomic variable store, it is visible in the current thread.
Before understanding the meaning of the memory_order_consume constraint, let's first understand the dependency relationship, for example:
std::atomic<std::string*> ptr;
int data;
std::string* p =newstd::string("Hello");
data =42;
ptr.store(p,std::memory_order_release);
In this example, the atomic variable ptr depends on p, but not on data, and p and data do not depend on each other
Now combine the dependencies to understand the meaning of the memory_order_consume mark: there is an atomic variable A, and the memory_order_release mark is applied to the write operation of the atomic variable in thread T1, and the read operation of the atomic variable A by thread T2 is marked as memory_order_consume, then From the perspective of thread T1, 在原子变量写之前发生的所有读写操作,只有与该变量有依赖关系的内存读写才会保证不会重排到这个写操作之后, that is to say, when thread T2 uses a read operation marked with memory_order_consume, only read and write operations that are dependent on this atomic variable in thread T1 will not be reordered to write operations after. If the memory_order_acquire flag is applied to the read operation, all read and write operations before the write operation in thread T1 will not be rearranged after the write (note here, 一个是有依赖关系的不重排,一个是全部不重排).
Similarly, use the example in cppreference as follows:
#include <thread>
#include <atomic>
#include <cassert>
#include <string>
std::atomic<std::string*> ptr;
int data;
void producer() {
std::string* p = new std::string("Hello"); // L10
data = 42; // L11
ptr.store(p, std::memory_order_release); // L12
}
void consumer() {
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_consume))); // L17
assert(*p2 == "Hello"); // L18
assert(data == 42); // L19
}
int main() {
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}
Compared with the example in the memory_order_acquire section, producer() has not changed, and the tag of the load operation in the consumer() function has changed from memory_order_acquire to memory_order_consume. And this change will cause the following changes: in producer(), ptr has a dependency relationship with p, then p will not be rearranged after store() operation L12, and data may be rearranged after L12 because it has no dependency with ptr , so it may cause L19's assert() to fail.
So far, the impact of the combination of memory_order_acquire&memory_order_acquire and memory_order_release&memory_order_consume on rearrangement has been analyzed: when the memory_order_acquire flag is used for read operations, for write operations, all reads and writes before the write operation cannot be rearranged after the write operation. For read operations, all reads and writes after the read operation cannot be rearranged to before the read operation; when the read operation uses the memory_order_consume flag, for write operations, 依赖关系all After the write operation, for the read operation, any read and write operations that are dependent on the read operation in the current thread will not be rearranged before the current read operation.
When the memory_order_acquire flag is applied to a read operation of an atomic variable, for those writing threads that use the memory_order_release flag, all memory operations in these threads before the write cannot be reordered after the write operation, which will severely limit The ability of the CPU and compiler to optimize code execution. Therefore, when you determine that you only need to restrict the access order of a certain variable, you should try to use memory_order_consume to reduce the restrictions on code rearrangement and improve program performance.
The memory_order_consume constraint is an optimization of acquire&release semantics. This optimization is limited to variable operations that have a dependency relationship with atomic variables, so it is more tolerant than memory_order_acquire in terms of reordering restrictions. It should be noted that because of the complexity of memory_order_consume implementation, since June 2016, in all compiler implementations, the functions of memory_order_consume and memory_order_acquire are exactly the same, see "P0371R1: Temporarily discouraged memory_order_consume" for details
memory_order_acq_rel
The other three constraints in the Acquire-Release model are either used to constrain reading or to constrain writing. So how do you enforce constraints on two actions in one atomic operation? This requires memory_order_acq_rel, which can constrain both reading and writing.
For the atomic operation using the memory_order_acq_rel constraint, the impact on the current thread is: the memory read and write before or after this operation in the current thread T1 cannot be reordered (assuming that the operation before this operation is operation A, and this operation is operation B , the operation after this operation is B, then the execution order is always ABC, which can be understood as the relationship within the same thread sequenced-before); the impact on other threads T2 is that if the T2 thread uses the write operation of the memory_order_release constraint, then T2 All operations before the write operation in the thread are visible to the T1 thread; if the T2 thread uses the read operation of the memory_order_acquire constraint, the write operation of the T1 thread is visible to the T2 thread.
It may be confusing to understand. This mark is equivalent to using the memory_order_acquire constraint for read operations and the memory_order_release constraint for write operations. Memory reads and writes before this operation in the current thread cannot be rearranged after this operation, and memory reads and writes after this operation cannot be rearranged before this operation.
cppreferenceAn example of 3 threads is used to explain the memory_order_acq_rel constraint, the code is as follows:
#include <thread>
#include <atomic>
#include <cassert>
#include <vector>
std::vector<int> data;
std::atomic<int> flag = {0};
void thread_1() {
data.push_back(42); // L10
flag.store(1, std::memory_order_release); // L11
}
void thread_2() {
int expected=1; // L15
// memory_order_relaxed is okay because this is an RMW,
// and RMWs (with any ordering) following a release form a release sequence
while (!flag.compare_exchange_strong(expected, 2, std::memory_order_relaxed)) { // L18
expected = 1;
}
}
void thread_3() {
while (flag.load(std::memory_order_acquire) < 2); // L24
// if we read the value 2 from the atomic flag, we see 42 in the vecto
assert(data.at(0) == 42); // L26
}
int main() {
std::thread a(thread_1);
std::thread b(thread_2);
std::thread c(thread_3);
a.join();
b.join();
c.join();
return 0;
}
In thread thread_2, the compare_exchange operation on the atomic variable flag uses the memory_order_acq_rel constraint, which means that L15 cannot be rearranged after L18, that is to say, when the compare_exchange operation occurs, it can ensure that the value of expected is 1, making this compare_exchange_strong The operation can complete the action of replacing the flag with 2; the thread_1 thread uses the store with the memory_order_release constraint for the flag, which means that when the value of the flag is fetched in the thread_2 thread, L10 has been completed (it will not be rearranged after L11) ). When the compare_exchange operation of the thread_2 thread writes 2 to the flag, the load operation with the memory_order_acquire flag in the thread_3 thread can see the memory writes before L18, which naturally includes the memory writes of L10, so the assertion of L26 is always true.
In the above example, the memory_order_acq_rel constraint is used in scenarios where both reading and writing exist at the same time. At this time, it is equivalent to using the memory_order_acquire&memory_order_acquire combination. In fact, it can also be used for reading or writing alone, examples are as follows:
// Thread-1:
a = y.load(memory_order_acq_rel); // A
x.store(a, memory_order_acq_rel); // B
// Thread-2:
b = x.load(memory_order_acq_rel); // C
y.store(1, memory_order_acq_rel); // D
Let's look at another example:
// Thread-1:
a = y.load(memory_order_acquire); // A
x.store(a, memory_order_release); // B
// Thread-2:
b = x.load(memory_order_acquire); // C
y.store(1, memory_order_release); // D
The above two examples have exactly the same effect, and both can guarantee that A is executed before B, and C is executed before D.
Summarize
Among the six memory access constraints provided by C++11:
-
memory_order_release: In the current thread T1, any read and write operation instructions before this operation X cannot be placed after operation X. If other threads use the memory_order_acquire or memory_order_consume constraint on the same variable, any read and write operations before the current thread's write operation will be visible to other threads (note that the dependency is visible for consume)
-
memory_order_acquire: In the current thread, the read and write operations that depend on this atomic variable after the load operation cannot be rearranged before the current instruction. If other threads use the memory_order_release memory model to store this atomic variable, it will be visible in the current thread.
-
memory_order_relaxed: No synchronization or order constraints, only atomicity is required for this operation
-
memory_order_consume: In the current thread, the read and write operations that depend on this atomic variable after the load operation cannot be rearranged before the current instruction. If other threads use the memory_order_release memory model to store this atomic variable, it will be visible in the current thread.
-
memory_order_acq_rel: Equivalent to using both memory_order_release and memory_order_acquire constraints on atomic variables
-
memory_order_seq_cst: From a macro point of view, the execution order of threads is strictly consistent with the code order
The C++ memory model is implemented by relying on the above six memory constraints:
- Relax model: corresponding to memory_order_relaxed in memory_order. It can be seen from its literal meaning that it has the least restriction on memory order, that is to say, this method can only ensure that the current data access is an atomic operation (not interrupted by other thread operations), but the order of memory access There are no constraints, which means that reads and writes to different data may be reordered
- Acquire-Release model: corresponding memory_order_consume memory_order_acquire memory_order_release memory_order_acq_rel constraints (need to be used in conjunction with each other); for an atomic variable A, synchronize the write operation (Release) and read operation (Acquire) of A, and establish a sorting constraint relationship , that is, for write operation (release) X, all read and write instructions before write operation X cannot be placed after write operation X; for read operation (acquire) Y, all read and write instructions after read operation Y cannot be placed Before the read operation Y.
- Sequential consistency model: the corresponding memory_order_seq_cst constraint; the execution order of the program is strictly consistent with the code order, that is to say, in the sequential consistency model, there is no order disorder.
The following picture roughly sorts out the core concepts of the memory model, which can help us quickly review.
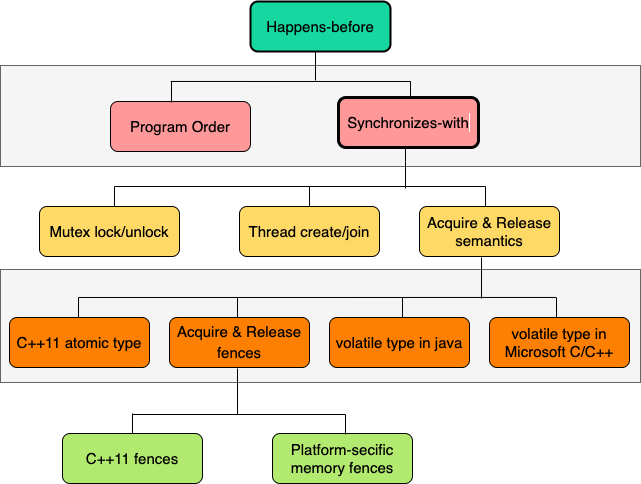
postscript
This article was written intermittently for more than a month, and I wanted to give up many times in the middle. However, fortunately, he gritted his teeth and persisted. I checked a lot of information, but because of insufficient knowledge reserves, many places are not well understood, so there may be misunderstandings in the article, I hope friendly exchanges and common progress.
In the process of writing the article, I deeply realized the complexity and depth of the memory model. In order to provide sufficient flexibility and high performance, the C++ memory model exposes various constraints to developers, giving experts enough room to play , It also makes the novice look at a loss.
Well, that's all for today's article, see you next time!