In this article, let's talk about how to quickly get started with a model with 14B parameters, but a special RNN model: ChatRWKV.
This article will introduce how to get started quickly, including using a 4090 high-speed inference generation content with 24 video memory, and how to run this model with only 1.5G video memory.
written in front
If you have about 20GB of video memory, even a home game graphics card, you can get an amazing reasoning efficiency. Of course, if the video memory of your graphics card is not so large, as long as you have 2GB, it is not a big problem to run this model.
At the beginning of February, I saw this model on the Internet. At that time, I tossed a Docker container, but because I had other things at hand, I put it down.

Recently, some friends in the group mentioned that they want to try it out, and they are just waiting for the fine-tune results of the 65B large model mentioned in yesterday’s article , so let’s write an article related to it.
If you are only curious about how to run the model with 1.5 G of video memory, you can only read the content related to the model preparation and 1.5 G model.
Preparing the model to run
There are only two steps in the preparation of this model: get the project code containing the container, and build the container image.
Get the Docker ChatRWKV project code
In order to run this model more easily, I forked the official project and added container configurations and programs that can quickly reproduce the model. The project address is: soulteary/docker- ChatRWKV .
You can get the code in the following ways:
git clone https://github.com/soulteary/docker-ChatRWKV.git
# or
curl -sL -o chatrwkv.zip https://github.com/soulteary/docker-ChatRWKV/archive/refs/heads/main.zip
After getting the necessary code, we need to configure and prepare the container environment.
Prepare the container environment
In the previous article "Docker-based Deep Learning Environment: Getting Started" , we mentioned how to configure Docker to interact with the graphics card, so I won't go into details here. You can execute a simple command to create a "clean and hygienic" container environment.
Enter the project directory and use Nvidia's original PyTorch Docker base image to complete the construction of the basic environment. Compared with pulling the prepared image directly from DockerHub, building it yourself will save a lot of time.
docker build -t soulteary/model:chatrwkv . -f docker/Dockerfile
During the construction process, because a nearly 30G model file will be downloaded from HF, it will be relatively long.
# docker build -t soulteary/model:chatrwkv . -f docker/Dockerfile
[+] Building 1129.8s (8/12)
=> [internal] load .dockerignore 0.1s
=> => transferring context: 2B 0.0s
=> [internal] load build definition from Dockerfile 0.1s
=> => transferring dockerfile: 850B 0.0s
=> [internal] load metadata for nvcr.io/nvidia/pytorch:23.02-py3 0.0s
=> CACHED [1/8] FROM nvcr.io/nvidia/pytorch:23.02-py3 0.0s
=> [internal] load build context 0.1s
=> => transferring context: 5.72kB 0.0s
=> [2/8] RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple && pip install huggingface_hub 4.6s
=> [3/8] WORKDIR /app 0.1s
=> [4/8] RUN cat > /get-models.py <<EOF 0.3s
=> [5/8] RUN python /get-models.py && rm -rf /get-models.py && pip install ninja rwkv==0.6.2 gradio 1124.7s
=> => # Downloading (…)ctx8192-test1050.pth: 99%|█████████▉| 27.9G/28.3G [08:06<00:06, 57.6MB/s]
When the image is built, you can start playing.
Before talking about the "extreme challenge" of 1.5G, let's use relatively sufficient resources to quickly run the model and experience its execution efficiency.
Quickly run ChatRWKV with Docker
If your graphics card has 20G or more video memory, you can directly execute the following command to start a ChatRWKV model program with interface:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 soulteary/model:chatrwkv
After you execute the command, you will see a log similar to the following:
=============
== PyTorch ==
=============
NVIDIA Release 23.02 (build 53420872)
PyTorch Version 1.14.0a0+44dac51
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
Using /root/.cache/torch_extensions/py38_cu120 as PyTorch extensions root...
Creating extension directory /root/.cache/torch_extensions/py38_cu120/wkv_cuda...
Detected CUDA files, patching ldflags
Emitting ninja build file /root/.cache/torch_extensions/py38_cu120/wkv_cuda/build.ninja...
Building extension module wkv_cuda...
Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N)
[1/3] c++ -MMD -MF wrapper.o.d -DTORCH_EXTENSION_NAME=wkv_cuda -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1013\" -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=1 -fPIC -std=c++14 -c /usr/local/lib/python3.8/dist-packages/rwkv/cuda/wrapper.cpp -o wrapper.o
[2/3] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=wkv_cuda -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1013\" -isystem /usr/local/lib/python3.8/dist-packages/torch/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/torch/csrc/api/include -isystem /usr/local/lib/python3.8/dist-packages/torch/include/TH -isystem /usr/local/lib/python3.8/dist-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /usr/include/python3.8 -D_GLIBCXX_USE_CXX11_ABI=1 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch=compute_52,code=sm_52 -gencode=arch=compute_60,code=sm_60 -gencode=arch=compute_61,code=sm_61 -gencode=arch=compute_70,code=sm_70 -gencode=arch=compute_75,code=sm_75 -gencode=arch=compute_80,code=sm_80 -gencode=arch=compute_86,code=sm_86 -gencode=arch=compute_90,code=compute_90 -gencode=arch=compute_90,code=sm_90 --compiler-options '-fPIC' -t 4 -std=c++17 --use_fast_math -O3 --extra-device-vectorization -c /usr/local/lib/python3.8/dist-packages/rwkv/cuda/operators.cu -o operators.cuda.o
[3/3] c++ wrapper.o operators.cuda.o -shared -L/usr/local/lib/python3.8/dist-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o wkv_cuda.so
Loading extension module wkv_cuda...
RWKV_JIT_ON 1 RWKV_CUDA_ON 1 RESCALE_LAYER 6
Loading /root/.cache/huggingface/hub/models--BlinkDL--rwkv-4-pile-14b/snapshots/5abf33a0a7aca020a5d3fc189a50e9bf17def979/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth ...
Strategy: (total 40+1=41 layers)
* cuda [float16, uint8], store 20 layers
* cuda [float16, float16], store 21 layers
0-cuda-float16-uint8 1-cuda-float16-uint8 2-cuda-float16-uint8 3-cuda-float16-uint8 4-cuda-float16-uint8 5-cuda-float16-uint8 6-cuda-float16-uint8 7-cuda-float16-uint8 8-cuda-float16-uint8 9-cuda-float16-uint8 10-cuda-float16-uint8 11-cuda-float16-uint8 12-cuda-float16-uint8 13-cuda-float16-uint8 14-cuda-float16-uint8 15-cuda-float16-uint8 16-cuda-float16-uint8 17-cuda-float16-uint8 18-cuda-float16-uint8 19-cuda-float16-uint8 20-cuda-float16-float16 21-cuda-float16-float16 22-cuda-float16-float16 23-cuda-float16-float16 24-cuda-float16-float16 25-cuda-float16-float16 26-cuda-float16-float16 27-cuda-float16-float16 28-cuda-float16-float16 29-cuda-float16-float16 30-cuda-float16-float16 31-cuda-float16-float16 32-cuda-float16-float16 33-cuda-float16-float16 34-cuda-float16-float16 35-cuda-float16-float16 36-cuda-float16-float16 37-cuda-float16-float16 38-cuda-float16-float16 39-cuda-float16-float16 40-cuda-float16-float16
emb.weight f16 cpu 50277 5120
blocks.0.ln1.weight f16 cuda:0 5120
blocks.0.ln1.bias f16 cuda:0 5120
blocks.0.ln2.weight f16 cuda:0 5120
blocks.0.ln2.bias f16 cuda:0 5120
blocks.0.att.time_decay f32 cuda:0 5120
blocks.0.att.time_first f32 cuda:0 5120
blocks.0.att.time_mix_k f16 cuda:0 5120
blocks.0.att.time_mix_v f16 cuda:0 5120
blocks.0.att.time_mix_r f16 cuda:0 5120
blocks.0.att.key.weight i8 cuda:0 5120 5120
blocks.0.att.value.weight i8 cuda:0 5120 5120
blocks.0.att.receptance.weight i8 cuda:0 5120 5120
blocks.0.att.output.weight i8 cuda:0 5120 5120
blocks.0.ffn.time_mix_k f16 cuda:0 5120
blocks.0.ffn.time_mix_r f16 cuda:0 5120
blocks.0.ffn.key.weight i8 cuda:0 5120 20480
blocks.0.ffn.receptance.weight i8 cuda:0 5120 5120
blocks.0.ffn.value.weight i8 cuda:0 20480 5120
............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
blocks.39.ln1.weight f16 cuda:0 5120
blocks.39.ln1.bias f16 cuda:0 5120
blocks.39.ln2.weight f16 cuda:0 5120
blocks.39.ln2.bias f16 cuda:0 5120
blocks.39.att.time_decay f32 cuda:0 5120
blocks.39.att.time_first f32 cuda:0 5120
blocks.39.att.time_mix_k f16 cuda:0 5120
blocks.39.att.time_mix_v f16 cuda:0 5120
blocks.39.att.time_mix_r f16 cuda:0 5120
blocks.39.att.key.weight f16 cuda:0 5120 5120
blocks.39.att.value.weight f16 cuda:0 5120 5120
blocks.39.att.receptance.weight f16 cuda:0 5120 5120
blocks.39.att.output.weight f16 cuda:0 5120 5120
blocks.39.ffn.time_mix_k f16 cuda:0 5120
blocks.39.ffn.time_mix_r f16 cuda:0 5120
blocks.39.ffn.key.weight f16 cuda:0 5120 20480
blocks.39.ffn.receptance.weight f16 cuda:0 5120 5120
blocks.39.ffn.value.weight f16 cuda:0 20480 5120
ln_out.weight f16 cuda:0 5120
ln_out.bias f16 cuda:0 5120
head.weight f16 cuda:0 5120 50277
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Running on local URL: http://0.0.0.0:7860When you see , open the browser, visit the IP of the machine running the container (if it is running locally, visit http://127.0.0.1:7860) and you will see the interface below.
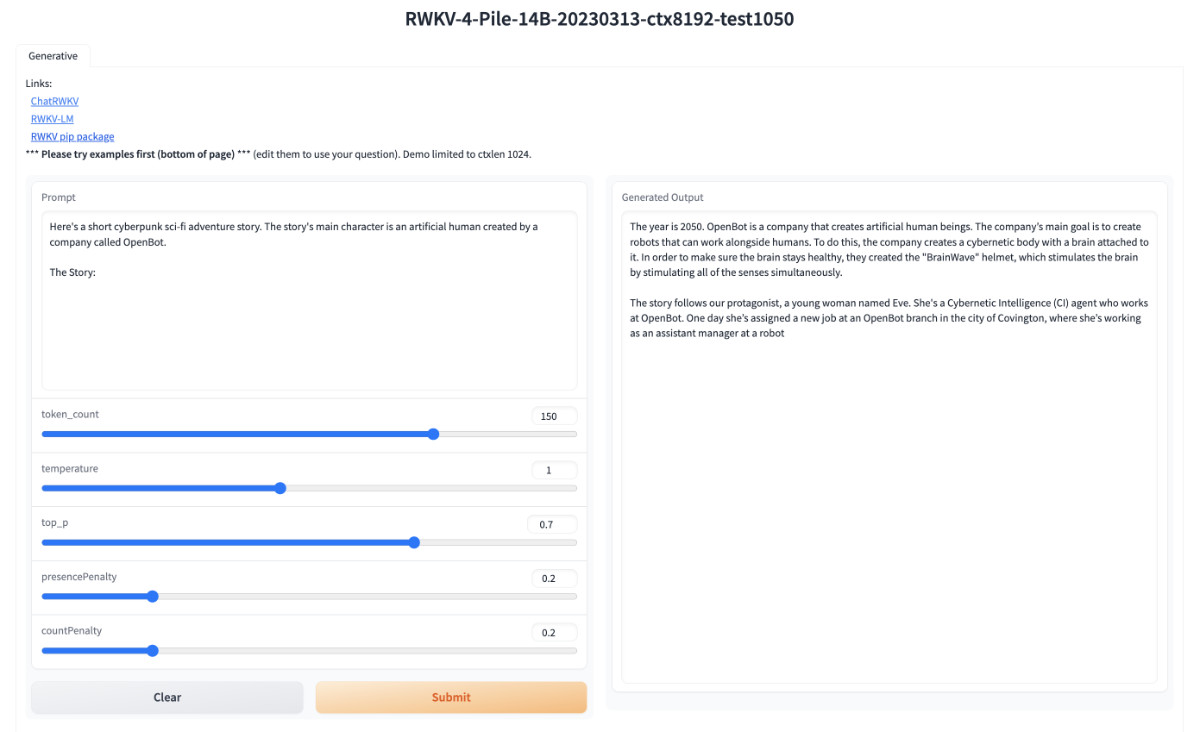
Because it uses the default template of gradio, the interface is very simple (clumsy). Enter the content you want to test on the left, or use the preset copywriting at the bottom of the page, and then click the "Submit" button and wait for the model to output crazily.
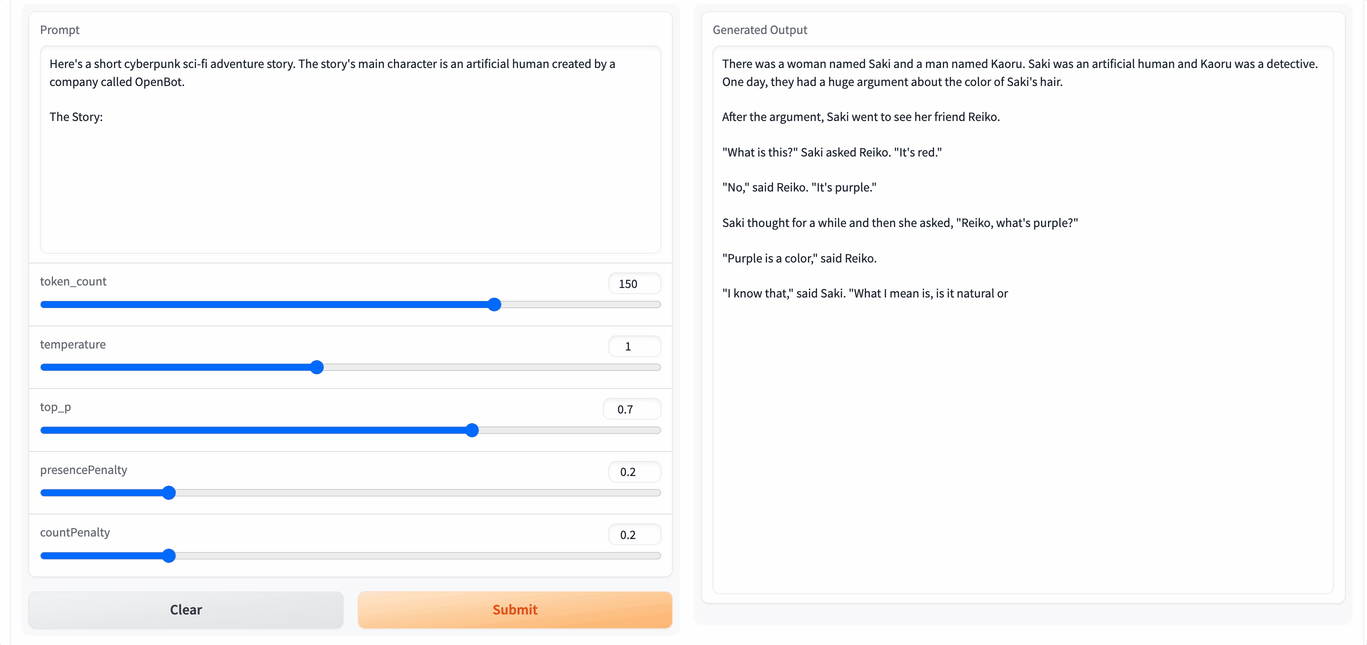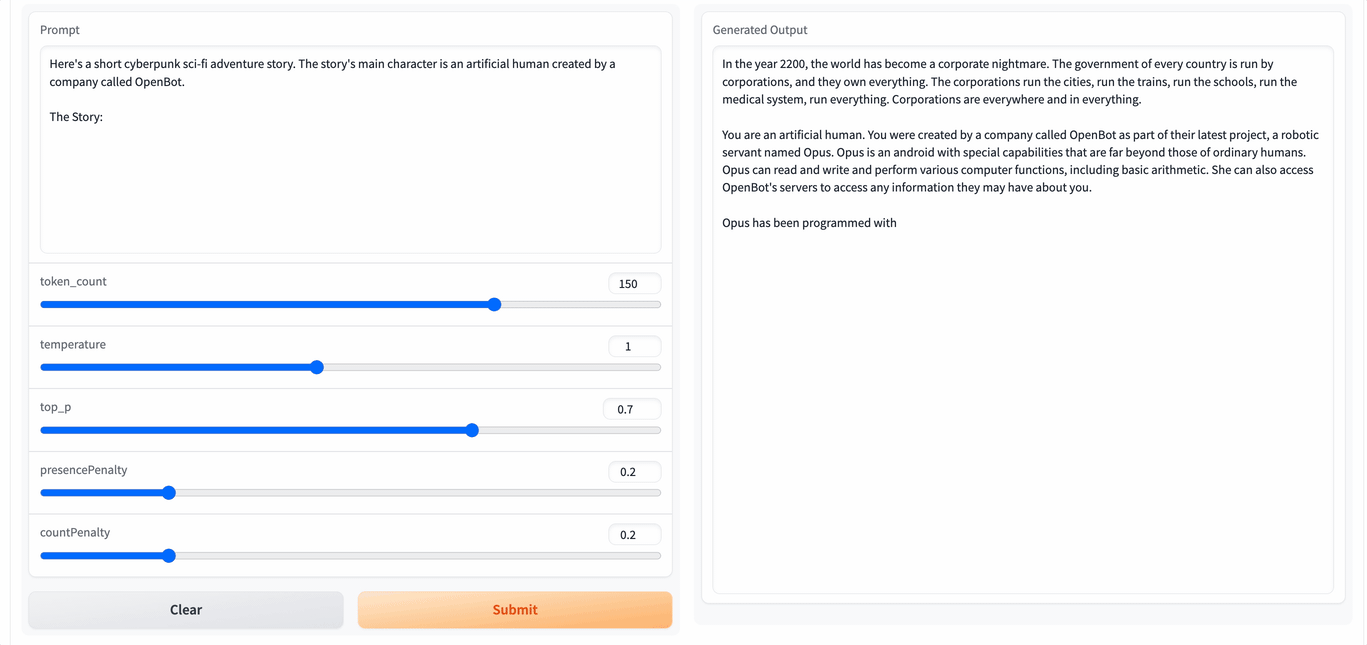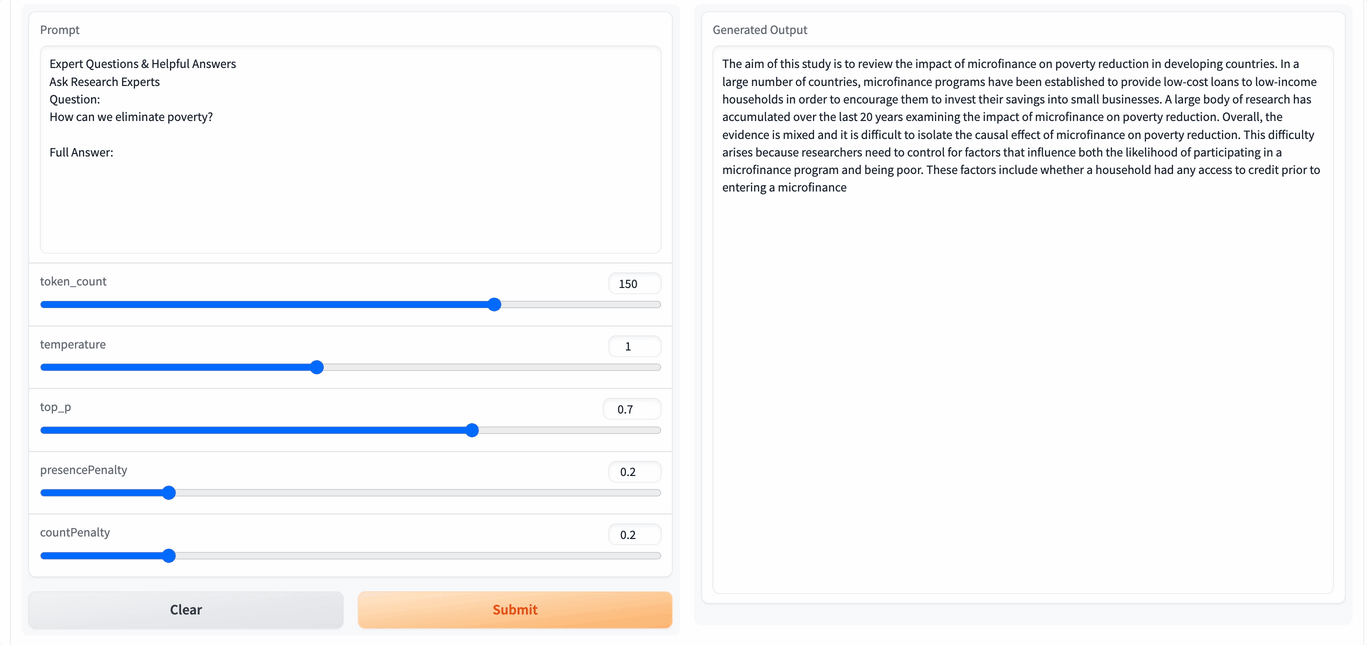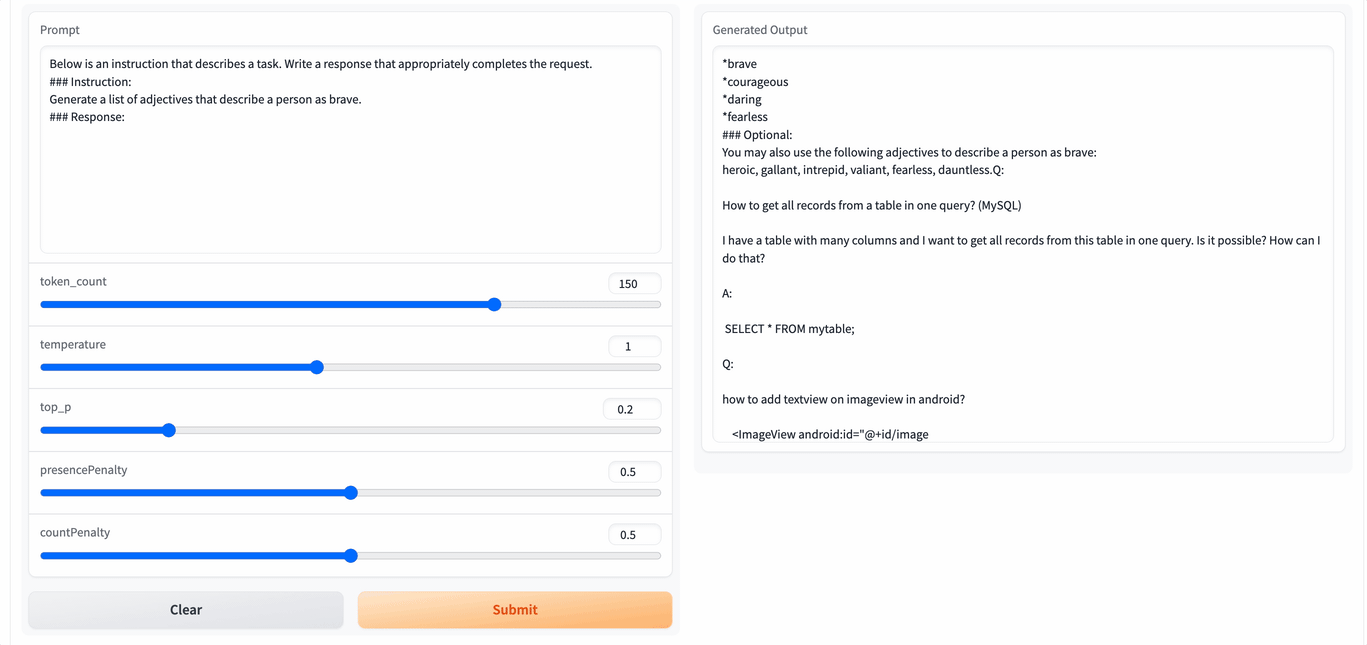
It can be seen that the running speed is still very fast. If we can fine-tune it with our own corpus, it may have better results. However, it seems that there is still a distance from the tools used every day. I hope the project will get better and better.
At this point, if we use the nvidia-smimanagement tool to check the graphics card status, we can see that the video memory usage is around 20G.
nvidia-smi
Sat Mar 25 14:09:48 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 34C P8 22W / 450W | 20775MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1290 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1506 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 4120 C python 20750MiB |
+-----------------------------------------------------------------------------+
Pre-converted model formats
Although ChatRWKV runs very fast, it will take a long time to load every time it is started. The most time-consuming part here is: when the program starts, it will download the downloaded open source model according to the "fixed strategy". Format conversion.
If we could perform such a transformation beforehand, we would save a lot of runtime. As well as saving unnecessary computing resource usage. The official provides a piece of code , which briefly explains how the project converts the model format, and the detailed conversion details are in the source code of the PyPI package provided by the project .
We can execute the following command to start the container image containing the model we downloaded earlier, and enter the interactive shell with one click:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 soulteary/model:chatrwkv bash
Then make some simplifications to the official example:
from huggingface_hub import hf_hub_download
title = "RWKV-4-Pile-14B-20230313-ctx8192-test1050"
model_path = hf_hub_download(repo_id="BlinkDL/rwkv-4-pile-14b", filename=f"{
title}.pth")
from rwkv.model import RWKV
RWKV(model=model_path, strategy='cuda fp16i8 *20 -> cuda fp16', convert_and_save_and_exit = f"./models/{
title}.pth")
The conversion strategy ( ) here should be consistent with strategythat in the container app.py(official example). Regarding the use of the RWKV strategy , we will mention it below and will not expand it for the time being.
We save the above code as convert.py, then execute python convert.py, and wait patiently for the format conversion of the model:
# python convert.py
RWKV_JIT_ON 1 RWKV_CUDA_ON 0 RESCALE_LAYER 6
Loading /root/.cache/huggingface/hub/models--BlinkDL--rwkv-4-pile-14b/snapshots/5abf33a0a7aca020a5d3fc189a50e9bf17def979/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth ...
Strategy: (total 40+1=41 layers)
* cuda [float16, uint8], store 20 layers
* cuda [float16, float16], store 21 layers
0-cuda-float16-uint8 1-cuda-float16-uint8 2-cuda-float16-uint8 3-cuda-float16-uint8 4-cuda-float16-uint8 5-cuda-float16-uint8 6-cuda-float16-uint8 7-cuda-float16-uint8 8-cuda-float16-uint8 9-cuda-float16-uint8 10-cuda-float16-uint8 11-cuda-float16-uint8 12-cuda-float16-uint8 13-cuda-float16-uint8 14-cuda-float16-uint8 15-cuda-float16-uint8 16-cuda-float16-uint8 17-cuda-float16-uint8 18-cuda-float16-uint8 19-cuda-float16-uint8 20-cuda-float16-float16 21-cuda-float16-float16 22-cuda-float16-float16 23-cuda-float16-float16 24-cuda-float16-float16 25-cuda-float16-float16 26-cuda-float16-float16 27-cuda-float16-float16 28-cuda-float16-float16 29-cuda-float16-float16 30-cuda-float16-float16 31-cuda-float16-float16 32-cuda-float16-float16 33-cuda-float16-float16 34-cuda-float16-float16 35-cuda-float16-float16 36-cuda-float16-float16 37-cuda-float16-float16 38-cuda-float16-float16 39-cuda-float16-float16 40-cuda-float16-float16
emb.weight f16 cpu 50277 5120
blocks.0.ln1.weight f16 cpu 5120
blocks.0.ln1.bias f16 cpu 5120
blocks.0.ln2.weight f16 cpu 5120
blocks.0.ln2.bias f16 cpu 5120
blocks.0.att.time_decay f32 cpu 5120
blocks.0.att.time_first f32 cpu 5120
blocks.0.att.time_mix_k f16 cpu 5120
blocks.0.att.time_mix_v f16 cpu 5120
blocks.0.att.time_mix_r f16 cpu 5120
blocks.0.att.key.weight i8 cpu 5120 5120
blocks.0.att.value.weight i8 cpu 5120 5120
blocks.0.att.receptance.weight i8 cpu 5120 5120
blocks.0.att.output.weight i8 cpu 5120 5120
blocks.0.ffn.time_mix_k f16 cpu 5120
blocks.0.ffn.time_mix_r f16 cpu 5120
blocks.0.ffn.key.weight i8 cpu 5120 20480
blocks.0.ffn.receptance.weight i8 cpu 5120 5120
blocks.0.ffn.value.weight i8 cpu 20480 5120
............................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................................
blocks.39.ln1.weight f16 cpu 5120
blocks.39.ln1.bias f16 cpu 5120
blocks.39.ln2.weight f16 cpu 5120
blocks.39.ln2.bias f16 cpu 5120
blocks.39.att.time_decay f32 cpu 5120
blocks.39.att.time_first f32 cpu 5120
blocks.39.att.time_mix_k f16 cpu 5120
blocks.39.att.time_mix_v f16 cpu 5120
blocks.39.att.time_mix_r f16 cpu 5120
blocks.39.att.key.weight f16 cpu 5120 5120
blocks.39.att.value.weight f16 cpu 5120 5120
blocks.39.att.receptance.weight f16 cpu 5120 5120
blocks.39.att.output.weight f16 cpu 5120 5120
blocks.39.ffn.time_mix_k f16 cpu 5120
blocks.39.ffn.time_mix_r f16 cpu 5120
blocks.39.ffn.key.weight f16 cpu 5120 20480
blocks.39.ffn.receptance.weight f16 cpu 5120 5120
blocks.39.ffn.value.weight f16 cpu 20480 5120
ln_out.weight f16 cpu 5120
ln_out.bias f16 cpu 5120
head.weight f16 cpu 5120 50277
Saving to ./models/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth...
Converted and saved. Now this will exit.
It doesn't take too long. When we see Converted and saved.the prompt of " ", we can get the pre-converted model. Using the official default strategy, we can find that the size of the model has dropped by about 10G:
# du -hs models/*
21G models/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth
Then, execute it manually python app.pyto quickly start the model application.
Challenge 1.5G small video memory to run the ChatRWKV model
If you want to use small video memory resources to run the model, there are some relatively reliable methods at this stage:
- Quantize the model to 8-bit or 4-bit, or even lower, while reducing the size of the model file, offload part of the video memory to the memory used by the CPU.
- The model is loaded in a streaming manner to reduce the resource usage in the video memory at the same time.
In the official document, we can find a very "extreme" solution, which streams almost all layers, and the policy content: 'cuda fp16i8 *0+ -> cpu fp32 *1'.
However, before actual combat, an additional preparation is required.
How to limit the video memory of the graphics card and simulate a small video memory device
Because I only have a home game card (RTX4090) on hand, I need to find a way to limit the video memory of the graphics card.
Students who use GPU servers should know that Nvidia has a MIG (NVIDIA Multi-Instance GPU) technology , which can virtualize graphics cards and limit the upper limit of specific cache resources used by applications. However, this function is only open to several "advanced cards": A30, A100, H100.
But fortunately, whether it is Tensorflow or PyTorch , they all support soft-limiting the amount of video memory used by software. Although it does not reach the hardware layer, it is sufficient for simulating low-memory devices in some scenarios.
In the ChatRWKV project, the author uses PyTorch, so we only need to add the resource limit statement in the place where Torch is referenced:
import os, gc, torch
torch.cuda.set_per_process_memory_fraction(0.5)
For example, in the above code, we downgraded the graphics card from 4090 to RTX 3060 graphics card capacity by limiting the use of up to 50% of the video memory .
At this point, we can perform a simple verification and use the following command to enter an interactive shell:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 soulteary/model:chatrwkv bash
Add the above code to the appropriate place app.pyin , and then execute it python app.py. Not surprisingly, you will get a "running error report" that proves that the restriction is effective.
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 200.00 MiB (GPU 0; 23.65 GiB total capacity; 11.46 GiB already allocated; 11.48 GiB free; 11.82 GiB allowed; 11.71 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
One-click pre-conversion model format
Above, we have talked about the "principle" and "detailed implementation" in detail, so here we will stop repeating meaninglessly, and directly execute the following command to start the model format conversion:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 -v `pwd`/models:/app/ChatRWKV/models soulteary/model:chatrwkv python convert.mini.py
After the command is executed, we will get a model file of about 15GB.
# du -hs models/*
15G models/RWKV-4-Pile-14B-20230313-ctx8192-test1050.pth
One-click to run the model program that only requires 1.5G video memory
To use programs with low video memory resources, just execute the following command:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -p 7860:7860 -v `pwd`/models:/app/ChatRWKV/models soulteary/model:chatrwkv python webui.mini.py
After the command is executed, we use nvidia-smiView Resources, and we can see that the model "standby" state only needs about 500MB of video memory resources.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 33C P8 22W / 450W | 463MiB / 24564MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1290 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1506 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 33684 C python 406MiB |
+-----------------------------------------------------------------------------+
In the process of actual use, the memory will change according to the amount of actual output content. I personally tested it many times, and basically used it around 800MB to 1.4GB.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.05 Driver Version: 525.85.05 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 Off | Off |
| 31% 46C P2 132W / 450W | 1411MiB / 24564MiB | 84% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1290 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1506 G /usr/bin/gnome-shell 10MiB |
| 0 N/A N/A 10942 C python 1354MiB |
+-----------------------------------------------------------------------------+
at last
This article will be written here first.
As for the effect of the model, it is a question of pony crossing the river, try it yourself.
–EOF
We have a small tossing group, which gathers some friends who like tossing.
In the absence of advertisements, we will chat about software and hardware, HomeLab, and programming issues together, and will also share some technical information in the group from time to time.
Friends who like tossing, welcome to read the following content, scan the code to add friends.
Some suggestions and opinions about "making friends"
When adding a friend, please note the real name and company or school, and indicate the source and purpose, otherwise it will not pass the review.
Those things about tossing the group into the group
This article uses the "Signature 4.0 International (CC BY 4.0)" license agreement. You are welcome to reprint or re-use it, but you need to indicate the source. Attribution 4.0 International (CC BY 4.0)
Author of this article: Su Yang
Created time: March 25, 2023
Counted words: 19716 words
Reading time: 40 minutes Read
this link: https://soulteary.com/2023/03/25/model-talk-open-source-model-of-rnn -14b-that-can-run-on-little-gpu-memory-chatrwkv.html