Table of contents
1. Papers & Code Sources
"MULTI-VIEW GAIT RECOGNITION USING 3D CONVOLUTIONAL NEURAL NETWORKS"
paper address: https://mediatum.ub.tum.de/doc/1304824/document.pdf
Code download address: The author did not provide
2. Highlights of the paper
The authors of this paper propose a deep convolutional network using 3D convolutions for multi-view gait recognition to capture spatio-temporal features.
The input data of the model consists of grayscale images and optical flow to enhance color invariance ("color invariance" should be the word, the original text is wrong... )
3. Model structure
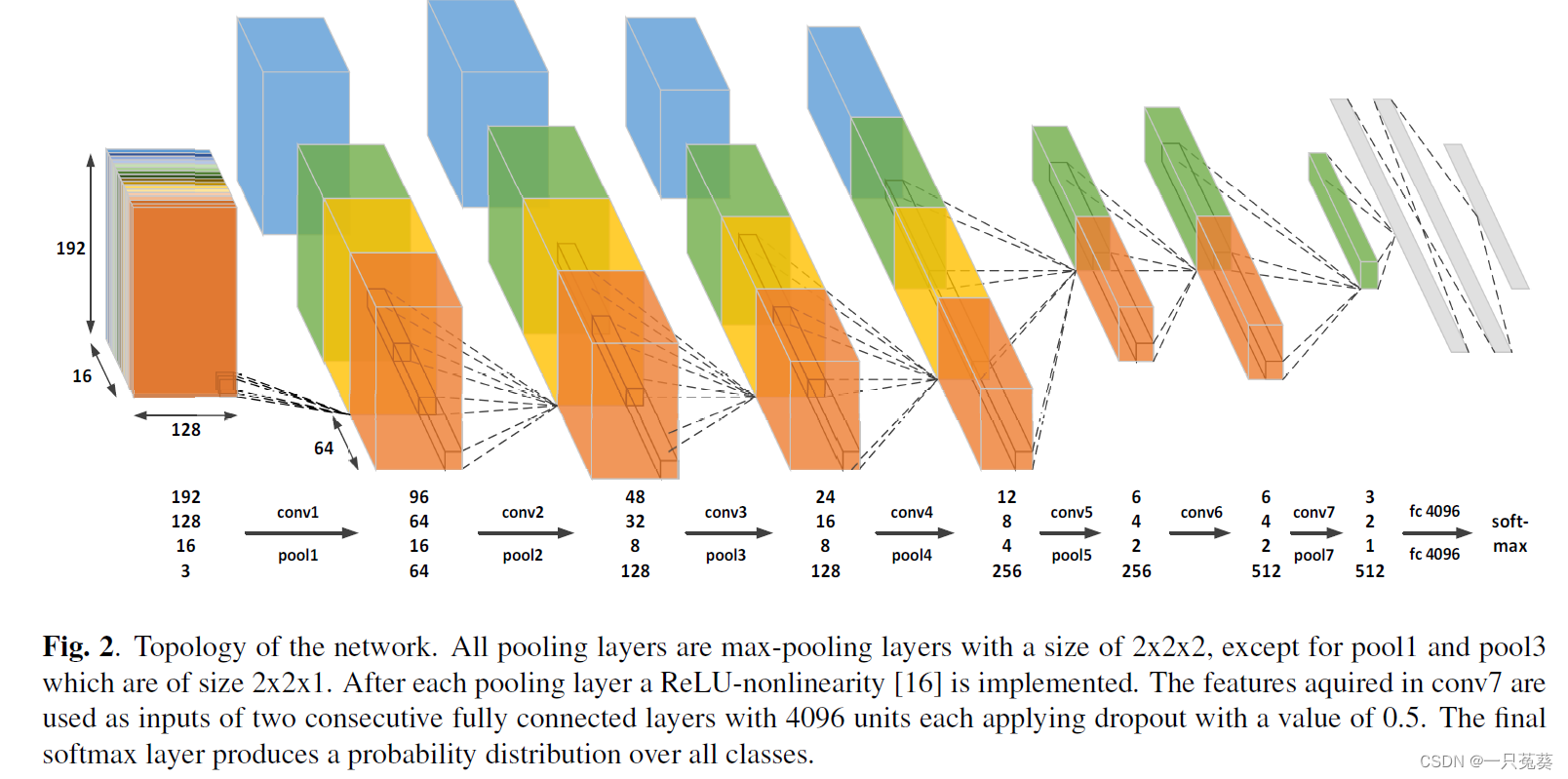
3.1 Technical route
The model structure is shown in the figure above, set the frame length to 16 161 6 , to balance capturing enough time information and computational complexity; the pooling layer size is2 × 2 × 2 2 \times 2 \times 22×2×2,1st11、 3 3 3 layers do not perform pooling operations to avoid premature folding of time information; all convolutional layers are3 × 3 × 3 × N 3 \times 3 \times 3 \times N3×3×3×N , the number of channelsN = [ 3 , 64 , 128 , 128 , 256 , 256 , 512 ] N=[3, 64, 128, 128, 256, 256, 512]N=[3,64,128,128,256,256,5 1 2 ] , the output of the last convolutional layer is the input of two consecutive fully connected layers, each fully connected layer has4096 40964 0 9 6 neurons, the dropout value of each neuron is0.5 0.50.5 ; the last layer uses the softmax function to generate the probability distribution of the classification .
3.2 Data preprocessing
Color and clothing changes are very important factors in gait recognition algorithms. Existing data sets provide few types of clothing changes. An ideal data set should include multiple sequences of the same subject with different clothing conditions, which limits The ability of the model to learn color invariance . In order to solve this problem, the author made the following transformations to the input image.
The first channel: Convert the RGB image to a grayscale image.
The second and third channels: use the method in [Secrets of optical flow estimation and their principles] to calculate xxx、yyOptical flow in the y direction, the purpose is to use optical flow to enhance the ability of the network to learn gait characteristics.
The training and testing process uses overlapping frame sequences, which are explained as follows:
a subject may appear in the first frame with a similar pose that does not match (with the subject), and the network will learn that the initial pose is the same as the subject. In order to avoid this situation, a sequence is divided into 16 frames, such as a 50 5050 frames of video are divided into( 1 − 16 ) , ( 2 − 17 ) , . . . , ( 35 − 50 ) (1-16), (2-17), ..., ( 35-50 )(1−16),(2−17),...,(35−5 0 ) of these fragments.
3.3 Training and Testing
In order to make the network learn "pure" gait features without being affected by changing factors such as walking speed and clothing, the author adjusted the training set and test set: because the training set and test set of the original data set are Under different conditions (recorded), the two are divided into 2 3 \frac 23 of the original data set32and 1 3 \frac 1331, then 2 3 \frac 2332Training set data and 2 3 \frac 2332The test set data are combined to form a new training set, and the remaining 1 3 \frac 1331Similarly, generate a new test set.
The network is trained using the stochastic gradient descent method, and the initial learning rate for the USF and CASIA-B data sets is 1 0 − 4 10^{-4}10− 4 , CMU is1 0 − 5 10^{-5}10− 5 , the momentum coefficient is0.9 0.90 . 9 , the attenuation coefficient is5 ∗ 1 0 − 4 5*10^{-4}5∗10− 4 , every 10 epochs, the learning rate decreases by 10 times.
4. Experimental results
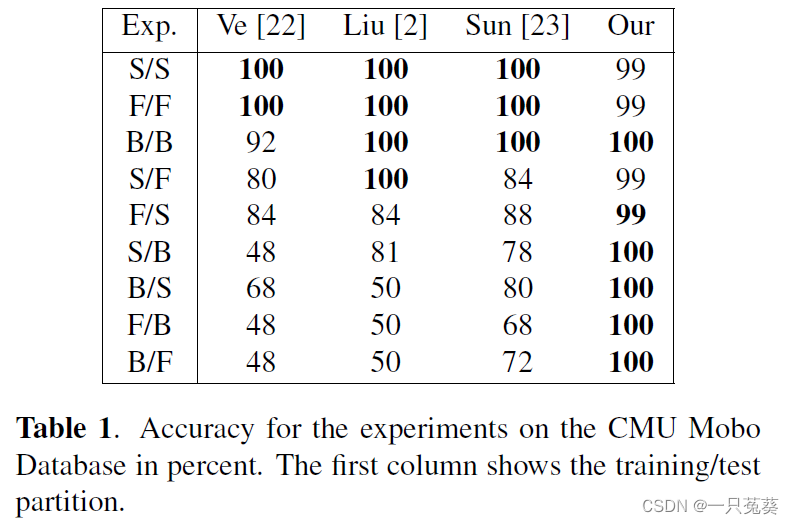
4.1 CMU
A total of 9 experiments were carried out, 3 of which used the same conditions for training and testing, and 6 of them used the split data of different condition data sets for training and testing.
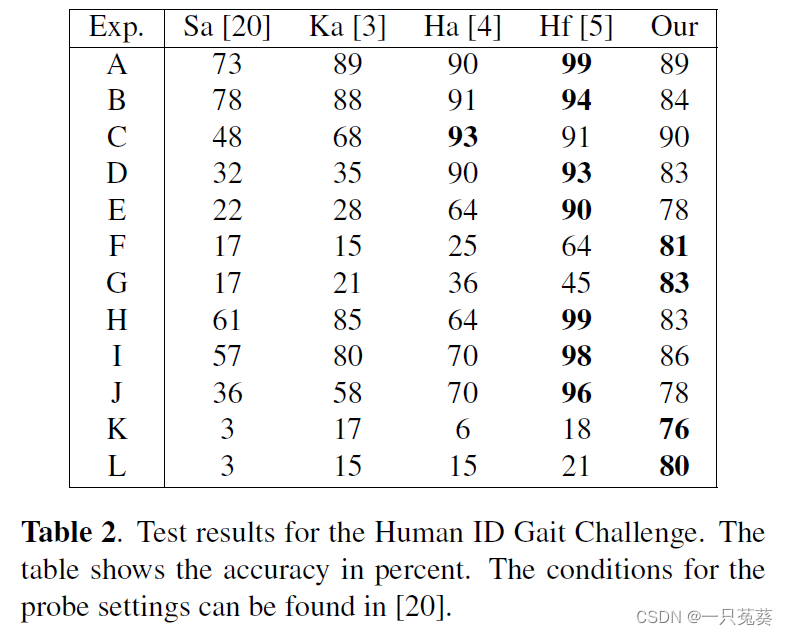
4.2 USF
A total of 12 experiments were carried out, in which 1 training set and 12 test sets were defined. The specific conditions were the same as [The humanid gait challenge problem: Data sets, performance, and analysis] paper. All experiments were performed using "training/ test" dataset.
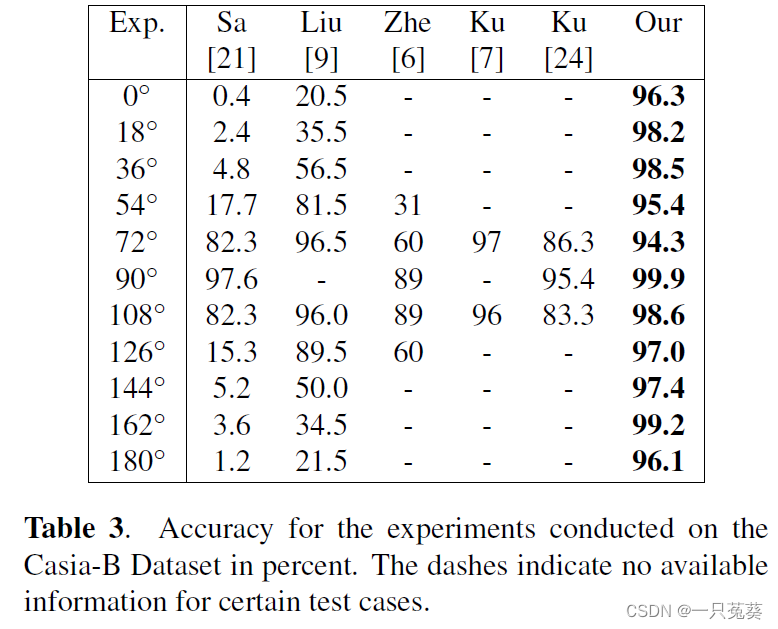
4.3 CAISA-B
Training experiment using 90° 90°6 gait sequences under 90 ° viewing angle; the test experiment uses 6 gait sequences under each viewing angle .
5. Summary
The authors propose a model based on convolutional neural network techniques to extract spatiotemporal features for classification. In experiments on different datasets, the accuracy of this representation is high, pointing to the great potential of CNN for gait recognition.
Also, overfitting is a potential problem due to the small amount of variation and the small size of the database. In addition to better hardware and larger network structures that can improve performance, the authors look forward to the emergence of a larger dataset with more cases. Using a dataset that includes thousands of subjects that vary widely in walking behavior and appearance further improves performance and reduces overfitting.
0. Knowledge Supplement
0.1 Optical flow method
Optical flow (Optical flow or optic flow) is a concept in object motion detection in the field of view. Used to describe the motion of an observed object, surface, or edge caused by motion relative to the observer. Optical flow is very useful in pattern recognition, computer vision, and other image processing fields. It can be used for motion detection, object cutting, calculation of collision time and object expansion, motion compensation coding, or three-dimensional measurement through object surfaces and edges, etc. wait.
The optical flow method is actually a method of inferring the moving speed and direction of an object by detecting the change of the intensity of the pixel points of the image over time.
Optical flow defines two other interesting terms:
1. Optical flow is the visual movement you can feel
2. Optical flow is the instantaneous speed of the pixel movement of the space moving object on the observation imaging plane (this seems more appropriate)
The concept of optical flow was first proposed by Gibson in 1950.
The reason why it is called "optical flow": When the human eye observes a moving object, the object forms a series of continuously changing images on the retina of the human eye, and this series of continuously changing information continuously "flows" through the retina (that is, the image Plane), like a "flow" of light, so it is called optical flow.
Optical flow expresses the change of the image, and because it contains the information of the target's motion, it can be used by the observer to determine the motion of the target.
Reference blog: