Summary:
Targeted issues:
1. When the image quality is poor, a lot of pre-optimization processing is required for the fingerprint. This can introduce false ridge patterns, degrading system performance with ridge patterns
2. The biometric calculation time of the fingerprint matching algorithm is long, and the fingerprint matching on a large database may be inefficient
Therefore, HHACOFM is proposed: A Fingerprint Matching Algorithm Based on Hierarchical Heterogeneous Ant Colony Optimization
HHACOFM: Having ant agents at different levels of the hierarchy to find matches between input and stored ridge patterns
Evaluated on four datasets with parallelism and scalability
Personal identification is critical to protecting data from cyberattacks. As identity theft increases, fingerprint recognition systems are increasingly important in enhancing safe and secure identification. Although most fingerprint recognition systems use minutiae features for fingerprint matching, when the image quality is poor, a lot of pre-processing of fingerprints is required. This may introduce false ridge modes, degrading the performance of the system. In addition, the calculation time of the fingerprint matching algorithm is long, and the fingerprint matching efficiency on a large database is low. This requires a fast and reliable fingerprint recognition system. A computationally intelligent fingerprint recognition system that extracts ridges from fingerprints for matching is proposed. Hierarchical Heterogeneous Ant Colony Optimization-based Fingerprint Matching Algorithm (HHACOFM) uses different levels of ant bodies in the fingerprint matching algorithm to find the match between the input ridges and the stored ridges. The algorithm is evaluated on the synthetic database generated by SFinGe tool, internal database, SOCOFing database and FVC2004 database. Experimental results show that this method has a higher recognition rate compared with existing methods. Compared with existing methods, the EER of hacofm algorithm is lower. The results were verified by statistical tests. HHACOFM supports parallelism, which reduces response time. The scheme is scalable and suitable for real-time applications requiring fast fingerprint verification.
Keywords: fingerprint recognition; hierarchical heterogeneous ant colony optimization; ridge model; biometrics
1. Introduction (note the references used)
first paragraph:
First, explain the effectiveness of biometrics against attacks (name some biometrics, point out the uniqueness of fingerprints)
Second, the reliability and universality of fingerprints introduced through the literature
Finally, a little explanation of the possible reasons for the existence of low quality
Reliable personal identification has become a challenging problem in recent years due to the increase in cybercrime. The heavy usage of online banking and e-commerce applications has led to the use of biometric systems to protect them from cyber-attacks. Biometric systems use a person's physiological or behavioral characteristics as characteristics for reliable identification (Maltoni et al., 2009). Fingerprints, voice, iris, face, etc. are some of the physiological characteristics that biometric systems use for reliable identification. While there is no single feature that can be concluded as the best feature, fingerprints are favored for their uniqueness (Peralta et al., 2015). Fingerprinting systems have gained popularity for their reliability and are generally preferred to protect data from hackers intent to fraud (Maltoni et al., 2009; Peralta et al., 2015). Fingerprints consist of patterns of ridges and valleys formed by genetic and environmental factors (Patil & Ingle, 2021). The texture of each finger of each person is unique and cannot be changed in a lifetime. This characteristic facilitates its use as an identity marker. Trauma and burns can temporarily damage fingerprints
Second paragraph:
Introduces the content related to fingerprint recognition. Divided into the authentication of recognition. There are three methods: correlation, minutiae-based and ridge-based
Fingerprint recognition systems deal with two issues, verification and identification. Fingerprint verification involves matching two fingerprints to determine if they correspond to the same finger. In fingerprinting, an input fingerprint is matched against all fingerprints in a database (Peralta et al., 2017). When two fingerprints represent the same finger, they are called "genuine," and when they represent different fingers, they are called "imposters." Fingerprint recognition systems learn patterns from a training set and are able to classify fingerprints as genuine or counterfeit. Fingerprint comparison is an important part of fingerprint verification and identification. Fingerprint matching methods are broadly classified into correlation-based, minutiae-based, and ridge-based methods (Maltoni et al., 2009). In correlation-based matching, the similarity between the input fingerprint and the stored template is discovered by matching global patterns of ridges and grooves to see if the ridges align. However, this method cannot be used when the fingerprint image is transformed. Furthermore, correlation-based methods suffer from nonlinear distortions, skin conditions, and finger pressure (Maltoni et al., 2009).
Third paragraph:
Introduce minutiae-based recognition methods. Divided into global and local, the global effect is not good, and the local effect is good, but when the local detail recognition encounters low image quality, it is not suitable.
NK Sreeja Intelligent Systems with Applications 17 (2023) 200180 Minutia-based methods compare two sets of minutiae from two fingerprints by initially aligning the minutiae and then counting the number of matching minutiae. Details can be matched globally or locally. The global minutiae matching algorithm handles the alignment process by treating all minutiae as a set. Although global detail matching algorithms achieve a high degree of uniqueness, they are computationally expensive (Peralta et al., 2015). The local minutiae matching algorithm compares two fingerprints based on the local structure of the minutiae. The local detail matching algorithm is simple, distortion tolerant and computationally cheap. Detail matching methods are not reliable when the image quality is poor. They require extensive preprocessing and image enhancement techniques to remove spurious details.
Fourth paragraph:
Introducing ridge-based methods. Not critical for time in large-scale environments, but in real-time environments where reduced response time is required
Ridge-based methods extract useful features from fingerprint images and classify them as real or impostor. Ridge-based methods are preferred when the image quality is too low to extract reliable details. They show better performance than minutiae-based algorithms when the sensor area used to capture the fingerprint is small (Castillo-Rosado and Hern´andez-Palancar, 2015; Maltoni et al., 2009). Ridge-based methods are often combined with detail-based methods for better performance. This further increases the computational complexity. Some ridge-based methods extract the edges of the ridges to form edge profiles and use them as features for fingerprint matching. Most fingerprint matching algorithms in large-scale environments focus on accuracy rather than the time required for matching. In real-time environments, high response times equate to system failures (Peralta et al., 2014). This requires designing a robust and scalable fingerprint matching algorithm with reduced response time.
Fifth paragraph:
The algorithm in this paper is proposed, which compares the similarity between the input ridge and the stored ridge by bitwise XOR operation. In large non-distributed databases, it can be executed in parallel, thereby improving time performance.
Question 1:
The introduction part introduces the three methods of fingerprint identification, and then writes the algorithm of this article in the fifth paragraph. How can it be modified in this intermediate connection?
A fingerprint matching algorithm based on hierarchical heterogeneous ant colony optimization is proposed. The proposed method extracts the edges of ridges and converts them into ridge patterns. Ridges are characteristic of fingerprints. Since ridges are unique to a fingerprint, the extracted ridge pattern is also unique. The similarity between the input ridge pattern and the stored ridge pattern is computed by performing a bitwise XOR operation on them. If the similarity is less than a selected threshold, the ant agent identifies the input fingerprint as an imposter. In large non-distributed databases, the hierarchical heterogeneous ant system ensures the parallel execution of calculations, thus improving the time performance. Experiments were carried out on four databases: (1) a fingerprint database based on the SFinGe (Synthetic Fingerprint Generator) tool (Cappelli et al., 2002; Cappelli et al., 2004), simulating different real-world scenarios with different fingerprint qualities, (2) an internal database, (3) FVC2004 database and (4) SOCOFing database. Experiments show that the proposal shows good performance on these databases. The performance of the proposal with state-of-the-art fingerprint matchers (such as Bozorth3, VeriFinger, Minutiae Cylindrical Code, FingerCode, etc.) on the FVC2004 database reveals the robustness of the proposal.
Contribution writing:
Question 2:
Generally, the first contribution is to write a brief description of the proposed method. Can 3, 4, and 5 be put together? Or can we highlight the key points of 4 and 5?
1. A Hierarchical Heterogeneous Ant Colony Optimization-based Fingerprint Matching (HHACOFM) algorithm is proposed for fingerprint recognition. The HHACOFM algorithm extracts ridges from input and stored fingerprints and calculates the similarity between them by performing a bitwise XOR operation.
2. HHACOFM intelligently distributes calculations to achieve parallelism, which reduces response time and makes it suitable for real-time applications. (I feel this is the main innovation point)
3. The HHACOFM algorithm is tested on four databases, namely SFinGe, SOCOFing, internal database and FVC2004 database. Experimental results show that the HHACOFM algorithm has good performance compared with other fingerprint matching methods.
4. Compared with the state-of-the-art fingerprint matching methods, the EER of the HHACOFM algorithm is very low.
5. The HHACOFM algorithm is scalable and very suitable for applications that require fast fingerprint verification.
2. Related work
First paragraph: (correlation method)
Because the article is trying to improve low-quality images, all the challenges encountered when first explaining fingerprint matching (causing low-quality reasons). Introduce the correlation-based methods and the subsequent challenges of these methods, one by one.
Fingerprint matching is a challenging problem as it is affected by factors such as deformation, pressure, skin condition, displacement and rotation. Fingerprint matching algorithms are classified into correlation-based, minutiae-based, and ridge-based methods (Maltoni et al., 2009). Correlation-based methods overlay input and stored fingerprints and compute correlations between corresponding pixels of various alignments. However, correlation-based methods fail when the input fingerprint is shifted or rotated. Furthermore, these methods do not account for nonlinear distortion, pressure, and skin conditions (Maltoni et al., 2009). To overcome this problem, methods based on alignment of symmetric points before correlation (Nilsson & Bigun, 2003) and complex correlation filters (Venkataramani & Kumar, 2004) were proposed. Correlation-based methods incur high computational costs. To reduce computational complexity, algorithms using space-invariant transformations were proposed (Sujan & Mulqueen, 2002). However, these methods require preprocessing of fingerprints. Phase Only Correlation (POC) matcher (Ito et al., 2004) is a correlation-based fingerprint matching algorithm that is highly discriminative and invariant to displacement and brightness. However, the POC matcher is very slow, which greatly limits its applicability in real-life scenarios (Pober, 2010).
Second paragraph: (based on detail matching method)
Introduce the minutiae-based fingerprint matching method, specifically introduce the global and local methods, and highlight the extensibility of the theme in the part
Minutia-based methods are the most common fingerprint matching methods (Nachar et al., 2020). Minutia-based methods rely on the alignment of the minutiae of two fingerprints. The global minutiae matching algorithm handles the alignment process by considering the entire minutiae set. Since global minutiae matching algorithms use the full information of fingerprints, they are highly unique (Peralta et al., 2017). However, global detail matching methods are computationally expensive and sensitive to distortions (Peralta et al., 2017). To solve this problem, minutiae matching can be performed locally. Local minutiae matching techniques extract and compare the local structure of minutiae from input and stored fingerprints. They are tolerant to global transformations like translation and rotation and are less sensitive to distortions (Peralta et al., 2017). Yin et al. Minutia cylindrical codes are extended for resource-constrained IoT devices, and eMCC is proposed for IoT environments (Yin et al., 2022). Deshpandae et al. (Deshpandae et al., 2022) proposed the scaling and rotation invariant fingerprint matching (CLMP) algorithm based on latent minutiae similarity (LMS) and clustering minutiae for fingerprint matching. The proposal achieves good accuracy on the FVC database. Bakheet et al. A fingerprint matching algorithm based on improved SIFT features is proposed (Bakheet et al., 2022). However, the scalability of this method was not explored. (I want to learn from it in my thesis)
Third paragraph: (Three kinds of fingerprint matchers)
Three fingerprint matchers are introduced, which face low-performance results when targeting low-quality images. Point out the need to address the low quality of the theme
Minutiae Cylindrical Code (MCC) (Cappelli et al., 2010), Bozorth3 (Watson et al., 2010), and VeriFinger (Neurotechnology 2010) are some well-known minutiae-based fingerprint matchers. MCC is an effective fingerprint matcher with high-quality representation of local detail structures. MCC features consider the relative relationship between minutiae and its neighbors, and thus are robust to translation, rotation and invariance. Bozorth3 is a standard algorithm developed by the National Institute of Standards and Technology (NIST). The algorithm uses the "mindtct" algorithm to detect minutiae from input fingerprints and stored templates and calculate a similarity score between them. Bozorth3 is invariant to translation and rotation. VeriFinger is another commercial minutiae based fingerprint matcher which is NKSreeja Intelligent Systems with Applications 17 (2023) 200180 Tolerant of translation, rotation and deformation (Pober, 2010). Detail-based methods perform poorly when there are only few details available. Moreover, traditional minutiae matching algorithms may lead to wrong matching results, as minutiae from different regions of different fingers may not be well matched (Cao et al., 2012). Furthermore, minutiae-based methods cannot be used when the fingerprint quality is low. In this case, spurious detail may be obtained due to unwanted spikes, holes, etc. Therefore, extensive preprocessing and image enhancement techniques are required before usable details can be extracted. (Learn from your own thesis)
Fourth paragraph: (ridge-based fingerprint matching method)
The first sentence connects the two with the low-quality challenge presented above. (interlocking logic, imitation)
Enumerate the literature on ridge-based matching methods, continuing the topic of scalability.
Ridge-based fingerprint matching algorithms are a good choice when the quality of details is poor. FingerCode (Jain et al., 1999) is a ridge-based fingerprint matcher that exploits both local and global features of fingerprints. It extracts feature vectors from input and stored fingerprints and calculates the similarity between feature vectors by finding the Euclidean distance between them. Some ridge-based methods extract edge profiles of ridges for fingerprint matching (Islam et al., 2010; Mohan et al., 2019; Ratiporn et al., 2015). However, the scalability of these methods has not been explored. Xu and so on. (Xu et al., 2019) proposed a high-resolution fingerprinting system using pores and edges. However, the system fails when the fingerprint quality is poor. Chen (Chen, 2012) proposed a fingerprint recognition system based on Ant Colony Optimization (ACO), where ACO is used for image segmentation and fingerprints are matched based on minimum gradient. The method achieved 90% accuracy on 20 samples. Nachar et al. (Nachar et al., 2020) use ridge minutiae and corners to detect feature points in fingerprints.
Fifth paragraph:
Describes the fingerprint matching algorithm performed by deep learning methods in recent years.
Some methods are listed, but at the same time, it takes a long time to train and check the network stability ( you can learn from the robustness of your own papers, and correspondingly say that the robustness of these articles is poor )
In recent years, researchers have focused on fingerprint matching algorithms using deep learning methods. Wang et al. (Wang et al., 2014) proposed a fingerprint recognition system based on deep neural network. The method uses an orientation field as an input feature and uses a stacked sparse autoencoder to classify fingerprints. Patil and Suralkar (Patil Waghjale & Suralkar, 2013) detected the edges of ridges, extracted features from them and used artificial neural networks for fingerprint matching. The method achieves impressive accuracy on small datasets. Kim et al. (Kim et al., 2016) proposed a deep belief network (DBN) to determine the liveness of fingerprints. Nogueira et al. (Nogueira et al., 2016) Liveness detection using Convolutional Neural Networks (CNN). Zhang et al. (Jang et al., 2017) proposed a method for detecting fake fingerprints using contrast enhancement and CNN. Although some of these methods achieve good accuracy, the training time of these methods is very long (Hammad & Wang, 2018). Ulyan et al. (Uliyan et al., 2020) proposed a fingerprint recognition system using a depth-restricted Boltzmann machine (DRBM). Almajmaie et al. (Almajmaie et al., 2019) proposed an associative memory-based fingerprint recognition system (MMCA-AM). Although DRBM and MMCA-AM achieve good accuracy, the image processing time is very long. Stephane and Claude (Stephane & Claude., 2016) use Backpropagation Network (BPN) for fingerprint matching. Dinka et al. (Dinca et al., 2022) proposed a CNN-based fingerprint recognition system to deal with low-quality fingerprints. However, the stability of the network is poor. Saponara et al. (Saponara et al., 2021) reconstruct a fingerprint image and classify it using a CNN autoencoder. Although the fingerprint matching algorithm based on deep learning achieves reasonable accuracy, the training and recognition time of this method is very long.
Sixth paragraph:
Questions! ! ( imitation )
First explain that the literature listed in the related work lacks scalability and requires high response time (scalability can be imitated)
Most fingerprint matching methods in the literature are not suitable for fingerprinting of large databases because they lack scalability and may result in very high response time. Therefore, it is necessary to design a computationally intelligent fingerprint matching algorithm that reduces processing time without compromising accuracy. In this paper, we propose a fingerprint matching algorithm based on hierarchical heterogeneous ant colony optimization, which can intelligently distribute calculations, achieve parallelism, and thus reduce response time.
3. Fingerprint matching based on hierarchical heterogeneous ant colony algorithm
This part introduces the topic
Question 3:
Should this part of the writing be as high-level as the article? Need to be more specific?
This section presents a hierarchical heterogeneous ant colony optimization algorithm for fingerprint matching. The algorithm has multiple ant agents operating at different levels of the hierarchy to compute the similarity between the input fingerprint and the stored fingerprint template. Stored fingerprints with a similarity greater than a fixed threshold are considered matching fingerprints.
3.1. Hierarchical heterogeneous ant colony optimization
Introduced the ant colony optimization algorithm and ant colony algorithm, and introduced the concept of heterogeneity in the ant colony algorithm
Ant colony optimization (Dorigo & Stutzle, 2005) is a metaheuristic algorithm that mimics the behavior of ants. In ant colony optimization, a group of ants represents a set of computationally concurrent agents moving through problem states representing a partial solution to the problem. They move by applying a stochastic local decision strategy based on paths and attractions (Maniezzo et al., 2004). Each ant gradually builds a solution as it moves. When an ant finds a solution, it evaluates the solution and modifies the values of the components used to find the solution. In the future, other ants use this information to find a solution.
AOC Algorithm: Ant Colony Algorithm (not described in the previous article, suddenly appeared)
In addition, the ACO algorithm uses two other factors, namely pheromone evaporation and optional daemon operation. Pheromone evaporation facilitates the exploration of new paths, and daemon actions are used to achieve actions that individual ant agents cannot perform (Maniezzo et al., 2004). ACO has been found to successfully solve many combinatorial problems. JW introduced the concept of heterogeneity in ant agents. Lee and JJ. Lee (Lee & Lee, 2010). Each group of ants has a different purpose and their pheromone rules vary. These heterogeneous groups work together to find the best solution. In Hierarchical Heterogeneous Ant Colony Optimization (Rusin & Zaitseva, 2012), a set of ant agents work at different levels of the hierarchy. Ant agents at each level are constrained by constraints, and they search in their own search space. Ant managers sit at the top of the hierarchy and monitor ant agents at other levels of the hierarchy.
Note: The concept of hierarchical heterogeneous ant colony optimization was not first proposed by the author. It should be the first to be applied to fingerprint recognition. How to carry out comparative design in the subsequent comparison experiments (pay attention to learning and imitation)
3.2. Extraction of fingerprint ridges
Feature extraction (denoising) using Canny edge detection operator
Ridge edges were extracted and converted to ridge patterns using the Canny edge detection operator (Canny, 1986). Figure 1(a) and (b) show the sample fingerprints and the corresponding output generated by the canny operator, respectively. The ridge of an M × N fingerprint is a Boolean matrix with M rows and N columns. A value of "1" in the pattern indicates the presence of ridges, a value of "0" indicates the absence of ridges. Figure 2(a) and (b) show sample fingerprints and corresponding ridges of size 40×40 selected from the SOCOFing database, respectively.
Canny edge detection factor: (Pay attention to the description method in this part of the full text, you can learn to imitate)
1. Denoising. Noise will affect the accuracy of edge detection, so the noise should be filtered out first.
2. Calculate the magnitude and direction of the gradient.
3. Non-maximum suppression. It is appropriate to 'thin' the edges.
4. Determine the edge. The final edge information is determined using a double threshold method.

Figure 1 shows: (a) a fingerprint sample (b) the edges of the fingerprint ridges in Figure 1(a).

Figure 2 shows: (a) a fingerprint sample from the SOCOFing database (b) the fingerprint ridge map in Figure 2(a).
3.3. Fingerprint matching based on hierarchical heterogeneous ant colony optimization
Describe in detail and give the system architecture (this part is described in detail, it is the short board of my thesis, learn to imitate, and firmly believe that what I do can!!!)
假设有 m 个存储的指纹,分别用 SF1、SF2、...、SFm 表示,I 是输入指纹。存储的和输入的指纹大小为 p*n。如第 3.2 节所述,获得存储指纹的脊线图案。设存储指纹SF1、SF2、…、SFm的脊纹分别为E(SF1)、E(SF2)、…、E(SFm)。脊图案的大小为 p*n。 HHACOFM 算法为输入指纹 I 找到匹配的存储指纹。HHACOFM 算法选择一组异构的蚂蚁代理。这些蚂蚁代理被放置在层次结构中的三个级别。第 3 级在层次结构中位于顶部,包含一个蚂蚁管理器。蚂蚁管理者监督每一级蚂蚁代理的整体功能并获得解决方案。第 2 级和第 1 级蚂蚁代理的数量由蚂蚁管理器确定,如等式 1 所示。 图 3 显示了所提出的指纹识别系统的模型。
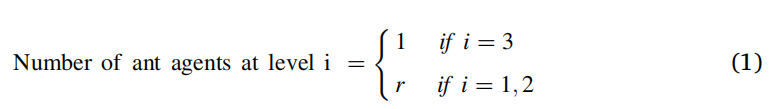
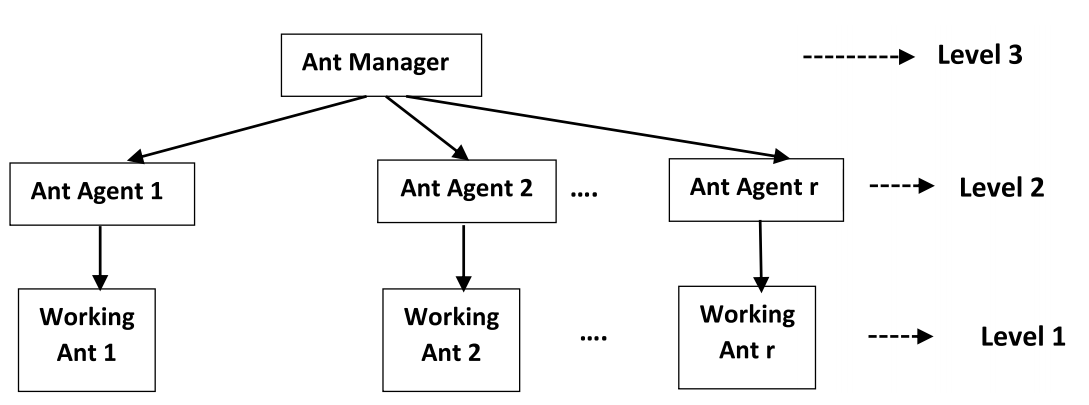
图3所示:指纹识别系统模型。
存储指纹的脊线图案作为输入提供给蚂蚁管理器。蚂蚁管理器将脊线模式存储在其表格列表中。如果存储的脊线模式数量大于 100,蚂蚁管理器会在 [40, 70] 范围内随机选择一个数字“r”。否则,r 的值为 2。'r' 表示第 2 级和第 1 级的蚂蚁代理数量,如等式(2)所示。
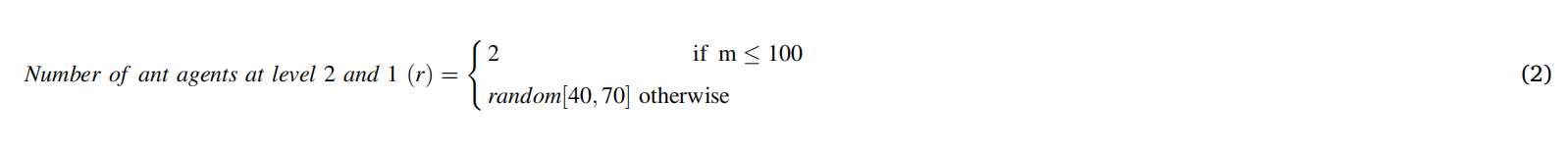
tabulist:
禁忌(Tabu Search)算法是一种元启发式(meta-heuristic)随机搜索算法,它从一个初始可行解出发,选择一系列的特定搜索方向(移动)作为试探,选择实现让特定的目标函数值变化最多的移动。
蚁群管理器的tabulist包含全局值和全局集。全局值初始化为0,全局集为空,如式(3)所示。
蚂蚁管理器将存储指纹的脊线模式划分为 r 个互斥子集 S1、S2、…Sr,并将每个子集 Si 分配给第 2 级的蚂蚁代理 Ai,如图 4 所示。
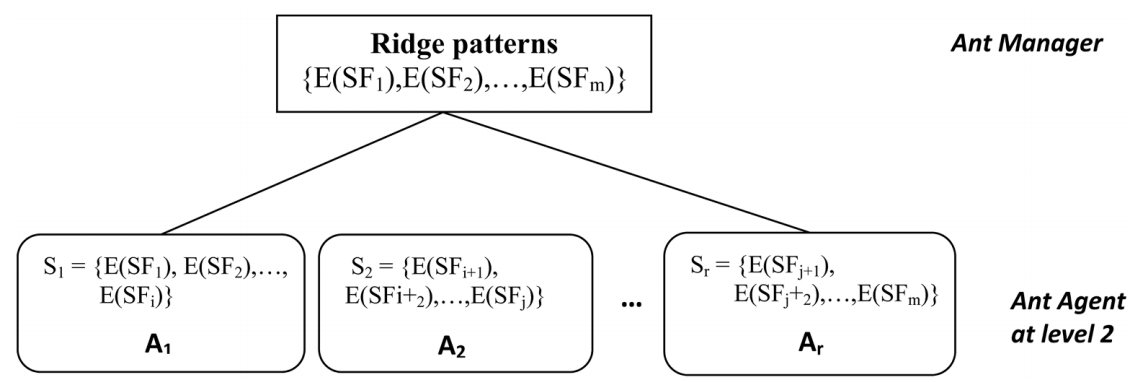
图4所示:由蚂蚁管理者分配脊型。
第 2 层的每个蚂蚁智能体 Ai 都有一个表示记忆的表格列表。表格包含两个变量“count_fingerprint”和“max_similarity”。 max_similarity 的初始值为 0。count_fingerprint 的初始值比等式 Si 中的子集 Si 中的脊图案数量大 1。如公式(4)

蚂蚁管理员提供输入指纹 I。蚂蚁管理器提取 I 的脊线模式并将其分配给第 2 层的所有蚂蚁代理。令 IN 表示提取的脊线模式。第 2 级的每个蚂蚁智能体 Ai 通过将 count_fingerprint 减 1 来存储信息素,并从子集 Si 中选择一个脊图案。令 M 表示所选模式。蚂蚁代理 Ai 将选择的模式 M 和输入模式 IN 分配给级别 1 的工作蚂蚁代理。
第 1 级的每个工作蚂蚁代理都有一个表格列表,其中包含一个变量“similarity_score”,用于存储输入和所选脊线模式之间的相似性。 similarity_score 的初始值为 0。工作的蚂蚁代理存放信息素并对 IN 和 M 中的值执行按位异或运算。XOR 运算返回零的次数按等式计算,用公式(5 和 6)并将结果存储在 similarity_score 中。
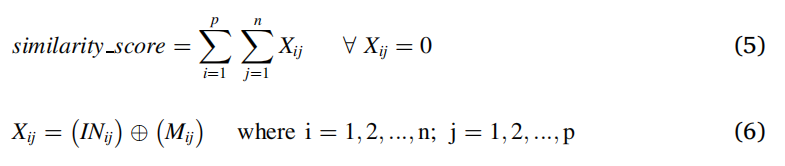
图5显示了在脊模式之间执行位异或操作的工蚁代理。

图5所示:工作蚂蚁代理执行按位异或操作。
工作的蚂蚁代理将其表列表中的 similarity_score 值发送给相应的第 2 级蚂蚁代理。第 2 级的蚂蚁代理将 similarity_score 的值与其 tabulist 中的 max_similarity 的值进行比较。如果 similarity_score 小于 max_similarity,则第 2 层的蚂蚁智能体移动到下一条路径。如果 similarity_score 大于 max_similarity,则第 2 层的蚂蚁智能体会找到等式中的相似度百分比,如公式 (7)。

如果相似度的百分比大于或等于0.96的阈值,第2级的蚂蚁代理用公式(8)中的similarity_score更新其tabulist中的' max_similarity '值。与similarity_score相对应的脊状图也会在其tabulist中更新。否则,max_similarity不会更新。选择阈值0.96来适应指纹的变形和失真。
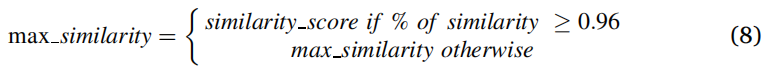
第 2 级的蚂蚁代理通过信息素蒸发移动到下一条路径。它再次通过将 count_fingerprint 减 1 来沉积信息素。它现在从子集 Si 中选择另一个脊线模式并将其分配给级别 1 的工作蚂蚁代理。第 1 级的工作蚂蚁代理发现输入脊线模式与从 Si 中选择的脊线模式之间的相似性。级别2的ant代理重复此过程,直到count_fingerprint的值为0。当count_fingerprint值为0时,第2级ant agent将max_similarity值发送给第3级的蚂蚁经理。
蚂蚁管理器将 max_similarity 值与其表列表中的全局值进行比较。如果 max_similarity 大于全局值,则使用 max_similarity 值更新全局值,并使用等式中相应的脊线模式更新全局集。 (9).否则,不更新全局值和全局集。在第2级的其他蚂蚁代理以同样的方式工作,最后,全局集包含与Eq.(10)中输入的ridge模式in最相似的ridge模式。在全局集中脊纹图案对应的指纹为匹配指纹。如果全局值为0,则表示给定输入指纹(I)没有匹配的存储指纹。HHACOFM算法伪代码如图6所示。

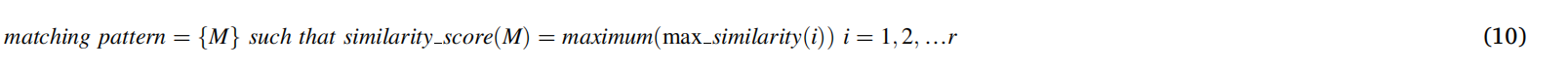

图6所示:HHACOFM算法伪代码。
4、案例研究
已经讨论了一个案例研究,用于将输入指纹与一组四个存储的指纹进行匹配。为了演示,假设所有指纹的大小都是 4 × 4。将存储的指纹表示为{SF1,SF2,SF3,SF4},对应的脊纹分别为E(SF1)、E(SF2)、E(SF3)和E(SF4)。第 3 层的蚂蚁管理员会看到存储指纹的脊线图案。由于呈现给蚂蚁管理器的模式数量少于 100,因此 r 的值为 2。因此,在第 2 层有 2 个蚂蚁代理,即 A1 和 A2。这些蚂蚁代理并行工作,为输入指纹找到匹配的存储指纹。每个蚂蚁代理 Ai 都有一个对应的工作蚂蚁代理,记为 Wi。由于 r = 2,蚂蚁管理器将存储指纹的脊线模式划分为两个互斥的子集,并将脊线模式 E(SF1) 和 E(SF2) 分配给 A1。类似地,E(SF3) 和 E(SF4) 被分配给 A2。令输入指纹为 I。为找到 I 的匹配存储指纹,HHACOFM 算法的工作原理如下。第 3 层的蚂蚁管理员被提供输入指纹 I。ant manager的tabulist中的global value和global set都是空的。蚂蚁管理器提取输入指纹 I 的脊线图案(IN),并将图案的副本发送给 A1 和 A2。
表 1 总结了蚂蚁代理 A1 和 A2 的工作。A1 的 tabulist 中 count_fingerprint 的初始值为 3,因为 A1 被分配了两个脊线模式 E(SF1) 和 E(SF2)。A1的tabulist中max_similarity的值为0。A1 通过将 count_fingerprint 减 1 来沉积信息素。它选择脊线模式 E(SF2) 进行比较。它将输入指纹的模式 IN 和存储指纹的模式 E(SF2) 发送给级别 1 的工作蚂蚁代理 W1。工作蚂蚁代理 W1 在 IN 和 E(SF2) 的值之间执行按位异或运算以查找相似性。表 2 显示了存储的带有 IN 的脊线模式的 similarity_score。从表 2 中可以注意到,由于 E(SF2) 和 IN 的所有位都相等,因此 E(SF2) 和 IN 的位异或结果 similarity_score 为 16。从表 1 可以看出,由于 E(SF2) 的 similarity_score 大于 max_similarity,A1通过将 max_similarity 除以脊图案的大小来找到相似性的百分比。可能会注意到 E(SF2) = 1 的相似性百分比。由于相似度百分比大于0.96,将A1表中的max_similarity更新为16,并将脊线图案E(SF2)存入A1表中。 A1的信息素蒸发了。 A1 移动到下一条路径,N.K. Sreeja Intelligent Systems with Applications 17 (2023) 200180 通过将 count_fingerprint 减 1 来沉积信息素。它现在选择下一个脊线模式 E(SF1) 并将其分配给级别 1 的工作蚂蚁代理 W1。W1 找到 IN 和 E(SF1) 之间的 similarity_score 并将 similarity_score 发送给 A1。从表 2 可以看出,E(SF1) 的 similarity_score 是 15。由于A1的tabulist中similarity_score小于max_similarity,所以max_similarity不更新。A1 重复这个过程,继续沉积信息素,直到 count_fingerprint 为 0。当 count_fingerprint 为 0 时,A1 将 max_similarity 值和对应的脊线模式 E(SF2) 发送给第 3 级的蚂蚁管理器。蚂蚁管理器将 max_similarity 与其表列表中的全局值进行比较。由于 max_similarity 大于全局值,全局值更新为 16,全局集更新为脊线模式 E(SF2)。
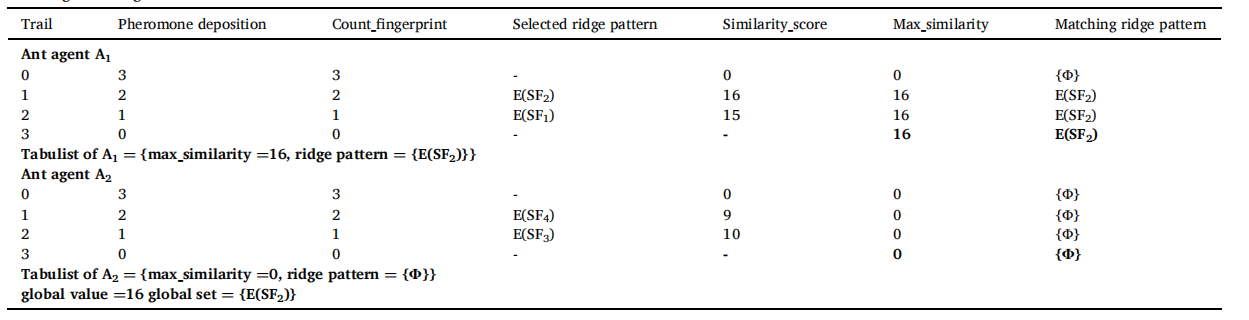
表1:蚂蚁agent在第2级的工作情况。
A2 的工作方式与 A1 相同。 A2的tabulist中max_similarity的值为0。它将脊线模式 E(SF3) 和 E(SF4) 分配给它的工作蚂蚁代理 W2。从表 2 中可以看出,E(SF4) 的 similarity_score 为 9。工作蚂蚁代理 W2 将 E(SF4) 的 similarity_score 发送给 A2。由于 E(SF4) 的 similarity_score 大于 max_similarity,A2 计算模式 E(SF4) 的相似度百分比。由于相似度百分比为0.56,小于阈值0.96,所以A2的tabulist中的max_similarity值没有更新,仍然为0。同样,将 E(SF3) 的相似度分数发送到 A2,由于 E(SF3) 的相似度百分比小于 0.96,因此不会更新 A2 的表格列表中的 max_similarity。A2 将 max_similarity 值发送给第 3 级的蚂蚁管理器。蚂蚁管理器将 max_similarity 值与全局值进行比较。由于 max_similarity 值小于全局值,因此不会更新全局值。最后,全局集包含脊线模式 E(SF2),全局值等于 16。因此,脊纹E(SF2)对应的存储指纹SF2是I的匹配指纹。
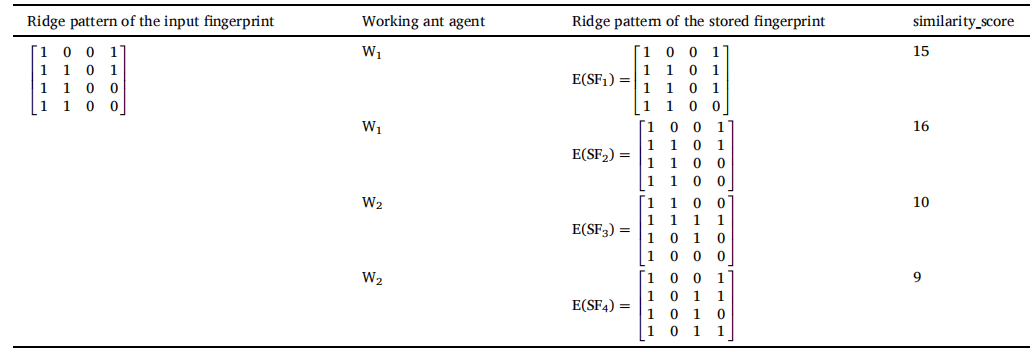
表2:脊型相似度评分。
5、 实验研究
本节简要介绍了为评估提案的性能而进行的实验的详细信息。首先,介绍了用于研究的数据库的描述,然后是用于评估 HHACOFM 算法的性能度量。HHACOFM 算法在 MATLAB 2016 中实现,系统配置为 Intel (R) Core (TM) i3-4130 [email protected] GHz 和 4 GB RAM。
5.1、数据库
四个数据库用于实验:SFinGe、SOCOFing、内部数据库和 FVC2004 数据库。NIST Special Database 4 (NIST-4)(Watson & Wilson,1992)被认为是文献中的基准数据库。由于该数据库没有适当的文档,因此无法再使用。因此,在其他数据库上进行了实验。
(a) SFinGe:SFinGe 是由 SFinGe 工具生成的合成数据库(Cappelli 等人,2002 年;Cappelli 等人,2004 年)。该数据库包括低质量指纹。用于生成指纹的参数如表 3 所示。使用该工具在不同压力和干燥度水平下生成了 50 个指纹,每个手指有两个印记。指纹受到不同距离的平移和不同程度的旋转。裁剪每个指纹以表示部分指纹。每个指纹经过四种不同的转换,最终数据库中有 50 * 6 = 300 个指纹。
图 7 (a) 显示了由 SFinGe 工具生成的高质量合成指纹。图 7(b)、(c)和(d)分别显示了相应的平移、旋转和部分指纹。图 8 (a) 显示了 SFinGe 工具生成的低质量合成指纹。图 8(b)、(c)和(d)分别显示了相应的平移、旋转和部分指纹。
图7所示:(a) SFinGe工具生成的高质量指纹。(b)图7 (a)对应的平移指纹。(c)图7 (a)对应的旋转指纹。(d)图7 (a)对应的部分指纹。

图8所示:(a) SFinGe工具生成的低质量指纹。(b)图8 (a)对应的平移指纹(c)图8 (a)对应的旋转指纹(d)图8 (a)对应的部分指纹。
(a) Sokoto Coventry Fingerprint Dataset (SOCOFing):SOCOFing(Shehu 等人,2018 年)是一个专为学术研究目的而设计的数据库。它拥有来自 600 个非洲受试者的 6,000 个真实指纹图像。每个真实的指纹都使用抹去、中心旋转和 z 切进行综合更改,这是混淆和扭曲的常见方法。因此,数据库中有6000枚真实指纹和17931枚合成变造指纹图像(69枚合成变造指纹不可用)。每幅图像的大小为 96 × 103 像素。图 9 (a) 显示了来自 SOCOFing 数据库的样本指纹。图 9(b)、(c)和(d)分别显示了擦除、中心旋转和 z 切割后获得的指纹。
(b) 内部数据库:使用 ZK6000 指纹扫描仪收集 263 人的左手和右手拇指印象,每个人有 5 个印象。每张图片的分辨率为 500 dpi。内部数据库中的指纹总数为 263 * 5 * 2 = 2630。图 10(a)显示了来自内部数据库的样本指纹。图 10 (b)、(c) 和 (d) 分别显示了相应的平移、旋转和部分指纹。

图9所示:(a)来自SOCOFing数据库的指纹。(b)在第9(a)条指纹擦除后获得的指纹。(c) 9(a)中指纹中心旋转后获得的指纹。(d)在9(a)指纹上进行z字形切割后获得的指纹。

图10所示:(a)内部数据库的指纹。(b)图10 (a)对应的平移指纹(c)图10 (a)对应的旋转指纹(d)图10 (a)对应的部分指纹。
(c) FVC 2004 数据库:FVC2004 ( http://bias.csr.unibo.it/fvc 2004) 数据库有四组(DB1、DB2、DB3 和 DB4)灰度图像,每组有 80 个指纹。每个手指产生八个印象。数据库中的指纹总数为 80 * 8 =640。FVC2004 数据库中指纹的描述如表 4 所示。DB1 到 DB3 包含真实指纹,而 DB4 包含合成指纹。
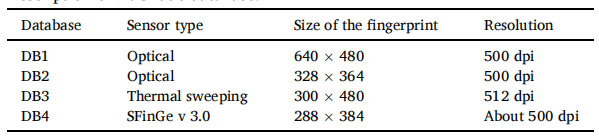
表4: FVC2004数据库描述。
5.2、性能的衡量
指纹识别系统的性能主要是根据其区分真假指纹的能力来衡量的。识别率(Accuracy)是衡量指纹识别系统整体性能的常用指标。定义为系统正确识别的指纹数与数据库中指纹总数的比值。错误不匹配率 (FNMR) 是指纹匹配系统无法匹配真实尝试的概率。另一个性能指标是错误匹配率 (FMR)。错误匹配率定义为指纹匹配系统接受冒名顶替者尝试并将其视为真正匹配的概率。FMR 和 FNMR 的比例相交的点称为等错误率 (EER)。EER 是一种独立于阈值的性能度量。低 EER 表示系统在此时的错误率降低时性能更好。
指纹识别系统的其他性能评估指标是错误拒绝率 (FRR) 和错误接受率 (FAR)。FRR 和 FAR 分别类似于 FNMR 和 FMR,只是它们是根据交易数量计算的。事务由一系列尝试组成。在进行的实验中,尝试次数限制为 1。因此,错误拒绝率 (FRR) 与 FNMR 相同,错误接受率 (FAR) 与FMR。实现非常低的 FAR 和 FRR 的指纹识别系统被认为是理想的。
6、实验结果
本节讨论在 SFinGe、SOCOFing、FVC2004 和内部数据库上进行的实验结果。将 HHACOFM 算法的性能与最先进的指纹匹配算法进行了比较,并进行了统计测试以验证结果。
6.1、HHACOFM在基准数据库上的性能
为了计算 FNMR,将生成的每个指纹与同一手指的其余样本进行匹配。这被称为真正的测试。因此,SFinGe、SOCOFing、internal和FVC2004数据库的正版测试总数分别为15*50=750、6*6000=36000、10*526=5260、28*80=2240。
为了找到 FMR,将每个手指的第一个样本与其余手指的所有样本进行匹配。这被称为冒名顶替者测试。因此,SFinGe 和 FVC2004 的冒名顶替者测试总数数据库分别为294*50=14700和632*80=50560。对于内部和 SOCOFing 数据库,从个体获得的每个样本都与从其余个体获得的其他样本相匹配。因此,内部和SOCOFing数据库的冒名顶替者测试数量分别为526 * 2620 = 1378120和6000 * 17901 = 107406000。
表 5 显示了 HHACOFM 算法在基准数据库上的性能。从表 5 可以看出,HHACOFM 算法能够识别 FVC2004、内部和 SFinGe 数据库的所有指纹。对于 SOCOFing 数据库,将 6000 个真实图像与 17931 个合成改变的样本进行了比较。HHACOFM算法从SOCOFing数据库的6000个指纹中识别出5976个指纹。从表 5 可以看出,SFinGe、FVC2004 和内部数据库的 HHACOFM 算法的 FMR 和 FNMR 为 0,表明其在区分冒名顶替者和真实用户方面的效率。HHACOFM 算法将 15 个冒名顶替者样本误识别为真实样本,HHACOFM 算法对 SOCOFing 数据库的 FMR 为 1.397e-07.同样,该算法将 24 个真实样本视为冒名顶替者。因此,SOCOFing数据库的HHACOFM算法的FNMR为6.667e-04

表5: HHACOFM算法的精度。
HHACOFM算法对SFinGe、FVC2004和内部数据库的识别率为100%。HHACOFM 算法对于像 SOCOFing 这样的大型数据库具有 99.6 ± 0.339(标准偏差)的高精度,证明了 HHACOFM 算法的可扩展性。HHACOFM 算法在所有数据库中的平均识别率为 99.9%。使用 SFinGe 工具生成的指纹经过几何变换。生成的每个指纹都被裁剪为代表部分指纹。从表 5 可以看出,HHACOFM 算法对 SFinGe 数据库的 FMR 和 FNMR 为 0,识别率为 100%,表明 HHACOFM 算法具有识别部分指纹的能力。HHACOFM 算法对 SOCOFing 数据库的识别率达到 99.6 ± 0.339 %,该数据库包含合成改变的指纹以表示失真和混淆。这证明了HHACOFM算法识别失真指纹的稳定性。
图 11 显示了来自 SOCOFing 数据库的少量指纹,这些指纹未被 HHACOFM 算法识别,并获得了相应的脊线。从图 11 可以看出,指纹的质量很差。由于只提取了很少的脊,HHACOFM 算法无法识别它们。
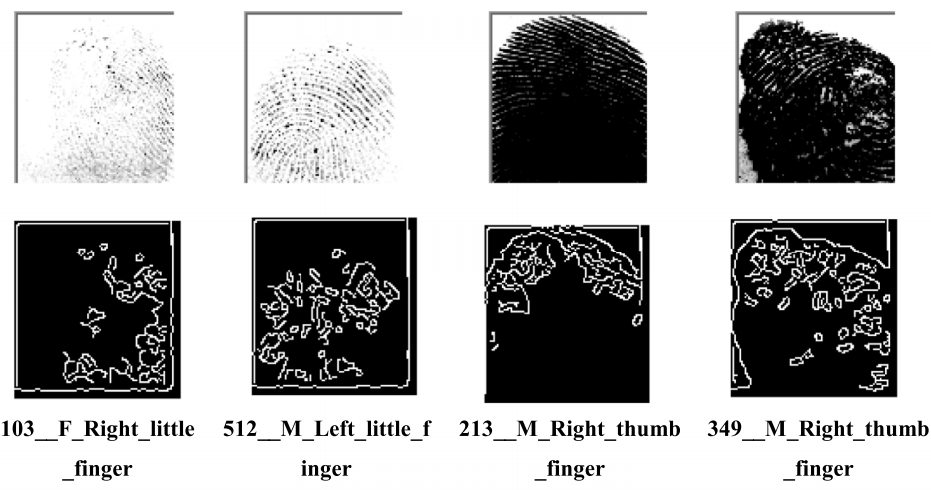
图11所示:SOCOFing数据库中无法识别的指纹。
表 6 和表 7 显示了不同阈值的数据库的 FMR 和 FNMR。SOCOFing 和 FVC2004 数据库的 FMR 和 FNMR 已经根据不同的阈值绘制,以判断指纹匹配系统的性能。图 12 显示了在阈值为0.93,0.94,0.95,0.96,0.97和0.98时,HHACOFM算法在SOCOFing数据库上的性能。从图12中可以看出,FMR和FNMR的图相交于1.089e−06,表明HHACOFM算法在SOCOFing数据库中的EER为0.000109%。

表6:不同阈值下的FMR。

表7:不同阈值的FNMR。

图12所示:不同阈值的SOCOFing数据库的FNMR和FMR。
图 13 显示了 HHACOFM 算法在 FVC2004 数据库上针对各种阈值的性能。从图 13 可以看出,两条曲线在 0 处相交,表明 HHACOFM 算法对 FVC2004 数据库的 EER 为 0。对于 SFinGe 和内部数据库,对于阈值 0.93、0.94、0.95、0.96、0.97 和 0.98,FNMR 和 FMR 为 0。因此,没有为这些数据库绘制 FMR 和 FNMR 的性能。表 8 显示了 FVC2004、SFinGe、SOCOFing 和内部数据库的 HHACOFM 算法的 EER。

图13所示:FNMR和FMR用于FVC2004数据库的不同阈值。
从表 8 可以看出,HHACOFM 算法对数据库 FVC2004、SFinGe 和内部数据库的 EER 为 0,表明 HHACOFM 算法的性能卓越。对于SOCOFing数据库,HHACOFM算法的EER为0.000109%。HHACOFM 算法的平均 EER 为 0.00002725%,表明 HHACOFM 算法在区分冒名顶替者和真实尝试方面的显着性能。

表8: HHACOFM算法的EER。
6.2、HHACOFM 与最先进方法的比较
将 HHACOFM 的识别率与流行的指纹识别方法(如 MMCA-AM、堆叠稀疏编码器和其他深度学习方法)进行了比较。此外,将 FVC2004 数据库的 HHACOFM 的 EER 与 POC 匹配器、MCC、VeriFinger、Bozorth3 和 Fingercode 等最先进的指纹匹配器进行了比较。
6.2.1、识别率
HHACOFM 算法的识别率已经与一些表现出良好准确性的指纹识别系统进行了比较,如 MMCA-AM(Almajmaie 等人,2019 年)、堆叠稀疏编码器(SSE)(Wang 等人,2014 年)、深度信念网络(DBN)(Kim et al., 2016)、卷积神经网络(CNN)(Nogueira et al., 2016)、对比度增强+CNN(Jang et al., 2017)、人工神经网络(ANN)( Patil Waghjale & Suralkar, 2013) 和反向传播网络 (Stephane & Claude., 2016) 使用 (Almajmaie et al., 2019; Hammad & Wang, 2018) 中报告的结果。HHACOFM 算法将 FVC2004 数据库中的所有 640 个样本识别为 MMCA-AM。
然而,MMCA-AM 无法识别内部数据库中 2500 个模式中的 13 个模式,MMCA-AM 对内部数据库的识别率为 99.48%。MMCA-AM同样不能识别NIST数据库中2000种模式中的16种,识别率为99.2%。但是,HHACOFM 算法对大多数数据库的识别率为 100%。值得一提的是,HHACOFM算法在SOCOFing数据库的6000个模式中只能识别出24个模式,HHACOFM算法对SOCOFing数据库的识别率为99.6%。表9显示了HHACOFM、MMCA-AM、SSE、DRBM+DBM、DBN、CNN、对比度增强+CNN、ANN和BPN得到的平均结果。从表 9 可以看出,HHACOFM 算法的平均识别率高于其他方法。图 14 显示了流行的指纹匹配算法的平均识别率。从图 14 可以明显看出,HHACOFM 算法实现了最好的平均识别率,而 ANN (Patil Waghjale & Suralkar, 2013) 实现了最低的识别率。

表9: HHACOFM算法平均结果比较。

图14所示:平均识别率的比较。
HHACOFM 算法在 FVC2004 数据库上的准确性已经与 Dinca 等人等最近的一些方法进行了比较。 (Dinca 等人,2022 年)、saponara 等人。 (Saponara 等人,2021 年)、未受保护的指纹细节、哈希指纹、修改后的哈希指纹细节(Ajish 和 AnilKumar,2020)、RNA-FINNT(Kaur,2015;Kaur 和 Ganesan,2012)、ANN(Patil Waghjale 和 Suralkar, 2013 年)、LMS(Deshpandae 等人,2022 年)、CLMP(Deshpandae 等人,2022 年)和 MMCA-AM(Almajmaie 等人,2019 年)使用(Ajish 和 AnilKumar,2020 年;Almajmaie 等人)中报告的结果。 ,2019 年;Dinca 等人,2022 年;Deshpandae 等人,2022 年;Saponara 等人,2021 年)。表 10 显示了方法在 FVC2004 数据库上的准确性。从表 10 可以明显看出,HHACOFM、CLMP 和 MMCA-AM 在其他方法中实现了 FVC2004 数据库的最高准确度。

表11:基于FVC2004数据库的EER。
6.2.2、FVC2004数据库中最先进指纹匹配器的EER
FVC2004 数据库的 HHACOFM 算法的 EER 已与 MCC、Bozorth3、VeriFinger、FingerCode 和 POC 匹配器等最先进的指纹匹配器进行了比较。表 11 使用(Nachar 等人,2020 年;Pober,2010 年;Yin 等人,2022 年)报告的结果显示了 HHACOFM 和 FVC2004 数据库上流行的指纹匹配器的 EER。由于 DB1-DB3 包含真实指纹,DB4 包含合成指纹,因此 DB1-DB3 的结果已在表 11 中进行了比较。从表 11 中可以看出,HHACOFM 对于所有三个数据库都实现了 0 的 EER,并且优于其他最先进的基于细节、脊和相关性的匹配器。

表11:基于FVC2004数据库的EER。
6.2.3、统计分析
配对 Z 检验是一种统计检验,用于确定两个配对组在感兴趣的变量上是否彼此显着不同。为了确定算法的结果之间是否存在显着差异,进行了配对 Z 检验。表 12 显示了 HHACOFM 算法与其他指纹匹配算法之间多次成对比较的平均识别率的配对 Z 检验结果。从表 12 可以看出,除了 Contrast enhancement + CNN [49] 之外的所有算法的 z 值都小于 -2.58(a=0.01)因此,MMCA-AM、SSE、DBN、CNN、ANN 和 BPN 具有统计显着性.从表 12 中还可以看出,MMCA-AM 达到了最高等级,它是与 HHACOFM 进行成对比较的最佳算法。该测试报告 HHACOFM 与 MMCA-AM 的 p 值为 1.4 e-05 低于 0.01。因此,HHACOFM 算法优于 MMCA-AM 和其他指纹匹配算法,成对比较的置信度大于 99%。
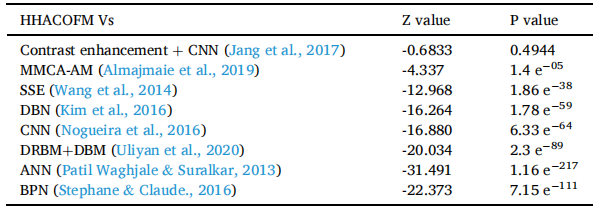
表12:指纹匹配算法平均识别率的配对z检验。
6.2.4、时间性能
实时环境中的指纹识别系统需要高精度和更少的匹配时间。大多数实时环境中的指纹匹配系统都获得了很好的准确性,但是匹配时间很长。HHACOFM 算法分布计算和指纹并行匹配。这减少了系统的匹配时间而不影响准确性。
将 HHACOFM 算法将输入指纹与存储的模板进行匹配所花费的时间与其他流行的指纹匹配算法的处理时间进行了比较。表 13 显示了 HHACOFM 算法匹配输入脊线 N.K. 所花费的时间。Sreeja Intelligent Systems with Applications 17 (2023) 200180 模式与存储的脊线模式。由于存储指纹的脊线模式在第 2 级的“r”个蚂蚁代理之间划分,因此许多模式是并行匹配的。由于 HHACOFM 算法在 [40, 70] 范围内选择 r,表 13 中的最小和最大时间分别表示当 r 等于 70 和 40 时蚂蚁代理所花费的时间。从表 13 中可以明显看出,HHACOFM 算法针对 17931 个存储模板找到输入指纹匹配所花费的最长时间仅为 4.4 秒,证明了 HHACOFM 算法的可扩展性。DRBM-DBM (Uliyan et al., 2020) 对输入指纹的处理时间约为 45 秒(系统配置:Intel (R) Xeon (R) CPU E5-2690 v2(3.00 GHz 处理器)和 20 GB RAM和 NVIDIA GPU)。虽然 MMCA-AM (Almajmaie et al., 2019) 获得了很好的精度,但 MMCA-AM 的处理时间为 32 秒 (Almajmaie et al., 2019)。DBN(系统配置:3.40 GHz 8 核 CPU 和 32 GB 内存)和 CNN 在 GPU 上的训练时间分别为 1 天和 5 小时(Kim 等人,2016 年;Nogueira 等人,2016 年)。虽然HHACOFM算法是在配置较低的系统上实现的,但即使在大型数据库中也能在不到五秒的时间内完成指纹匹配,适用于需要快速指纹验证的应用。图 15 显示了 HHACOFM 算法对 SFinGe、SOCOFing、内部和 FVC2004 数据库的匹配时间比较。从图 15 可以看出,HHACOFM 算法对所有数据库所花费的最大时间小于顺序匹配指纹所需的时间,使其适用于实时环境。
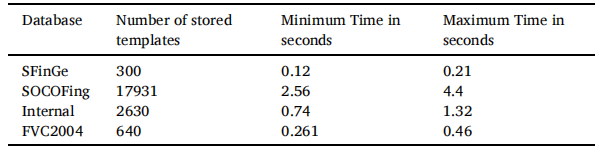
表13 :HHACOFM算法的匹配时间。
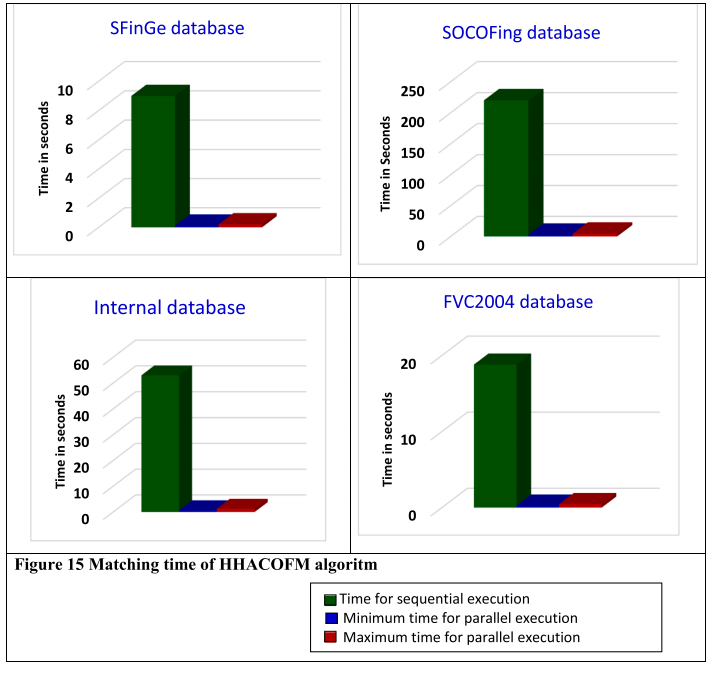
图15所示:HHACOFM算法的匹配时间。
7、结论
本文提出了一种基于层次异构蚁群优化的指纹识别系统。提取脊线的边缘并将其转换为用于指纹匹配的脊线图案。所提出的 HHACOFM 算法使用层次结构中不同级别的多个蚂蚁代理来查找输入和存储的脊线模式之间的匹配。在大型非分布式数据库中,层次异构的蚂蚁系统保证了计算的并行执行,从而提高了时间性能。与现有的指纹匹配算法相比,HHACOFM 算法表现出良好的性能。大多数数据库的 HHACOFM 算法的错误匹配率和错误不匹配率均为 0,表明其能够区分冒名顶替者和真实用户。该提案比 FVC2004 数据库的最先进的指纹匹配器实现了更低的 EER。该提案的平均 EER 为 0.00002725%。 HHACOFM 算法在识别失真和部分指纹方面是有效的。所提出的指纹识别系统实现了 99.9% 的平均识别率,将输入指纹与 17931 个存储模板匹配所需的最长时间为 4.4 秒。进行了统计测试以验证算法的性能。HHACOFM 算法具有可扩展性,非常适合需要快速指纹验证的应用。