Article directory
foreword
On November 30, 2022, OpenAI launched the artificial intelligence chat model ChatGPT ( ChatGPT: Optimizing Language Models for Dialogue ), which soon attracted millions of users to register and use, the official account and hot searches continued, quickly became popular, and even attracted major companies. The arms race on chatbots.
1. The past and present of GPT
1.1 OpenAI and GPT series
OpenAI (Open Artificial Intelligence) is an artificial intelligence research laboratory in the United States. It was established at the end of 2015. It is composed of the profit-making organization OpenAI LP and the parent company's non-profit organization OpenAI Inc. The purpose is to promote and develop friendly artificial intelligence to benefit mankind as a whole .
OpenAI is represented as the GPT series of natural language processing models. Since 2018, OpenAI has released the generative pre-trained language model GPT (Generative Pre-trained Transformer), followed by GPT-2 in February 2019 and GPT-3 in May 2020. GPT model parameters have exploded, and its effect is getting better and better. The effect of GPT-3 is not inferior to BERT, which was dominant at the time, but because it is not open source and open, the popularity is not so high. On November 30, 2022, OpenAI released ChatGPT. During the research preview period, users can use it for free after registration and login. unavailable).

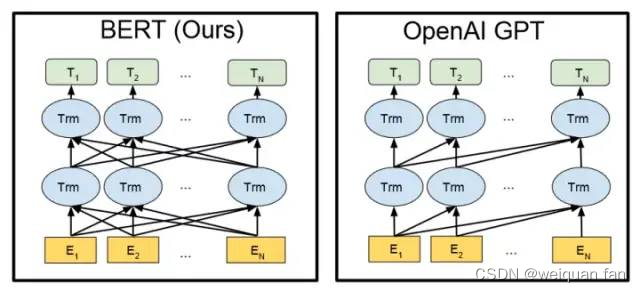
Among them, the schematic diagrams of BERT and GPT are as follows. They are both based on the Transformer model, the former is bidirectional and the latter is unidirectional.
1.2 ChatGPT and the comparison model of the same period
It is reported that ChatGPT is developed based on the GPT-3.5 architecture and is a brother model of InstructGPT. Based on the large amount of dialogue data collected during the open source period, GPT-4 may be further launched later.
Currently, ChatGPT has the following characteristics:
1) You can take the initiative to admit your mistakes. If the user points out their mistake, the model listens and refines the answer.
2) ChatGPT can challenge incorrect questions. For example, when asked the question "Columbus came to the United States in 2015", the robot will explain that Columbus does not belong to this era and adjust the output.
3) ChatGPT can admit its own ignorance and ignorance of professional technology.
4) Support continuous multiple rounds of dialogue.
According to the repeated tests of the majority of netizens, ChatGPT can now conduct a large degree of open dialogue, you can ask travel strategies, you can ask philosophical questions, you can ask how to do math problems, and even let it type code. But it is a generative model after all, not a retrieval model. It can only answer based on the data set so far, but cannot ask it what the weather will be like tomorrow. During the opening period, a large amount of test data was continuously collected, but it was also shielded by algorithms to filter out harmful input samples.
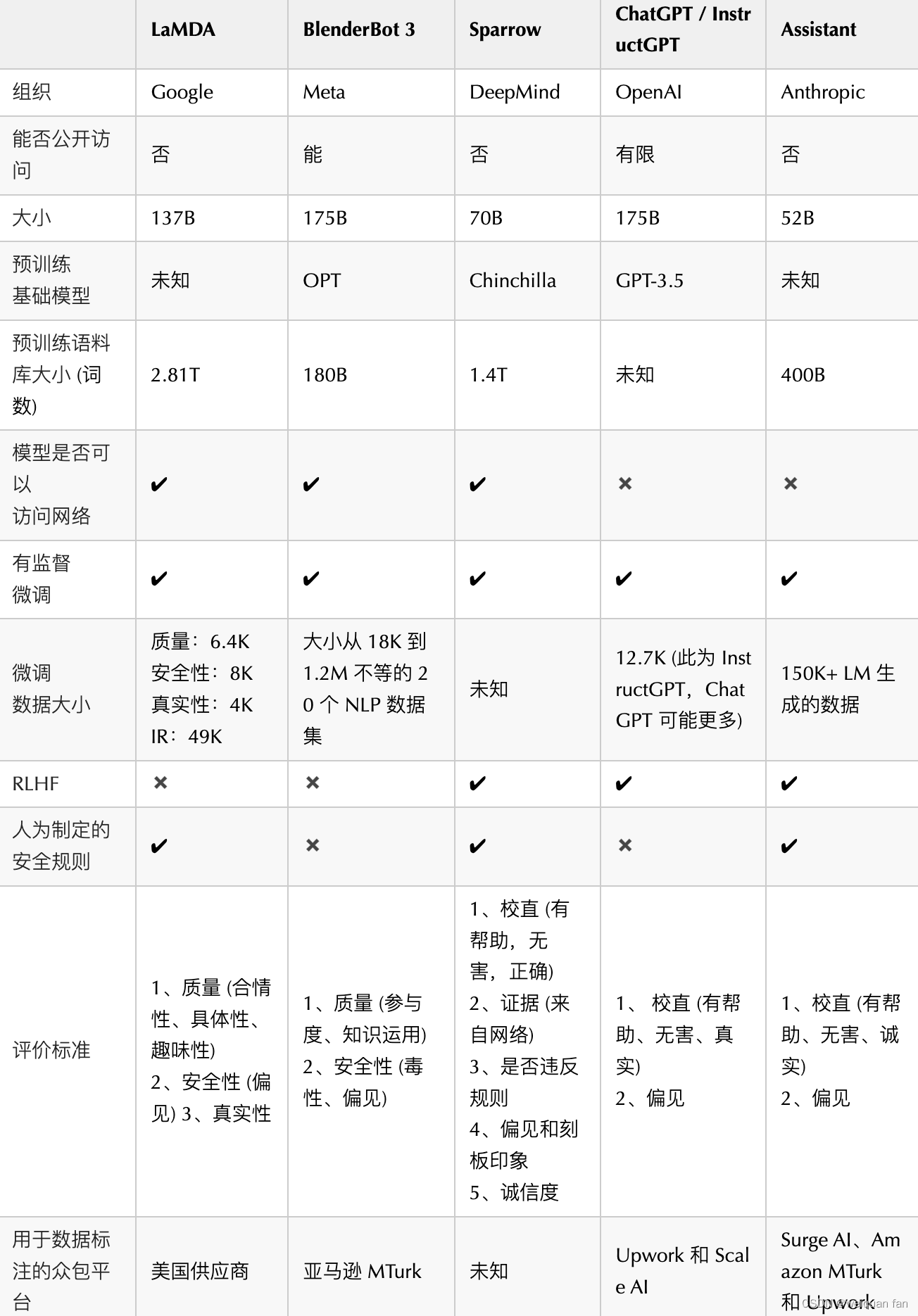
At the same time as ChatGPT, major Internet companies have their own corresponding chatbots. The following is a comparison table.
2. Technical principle
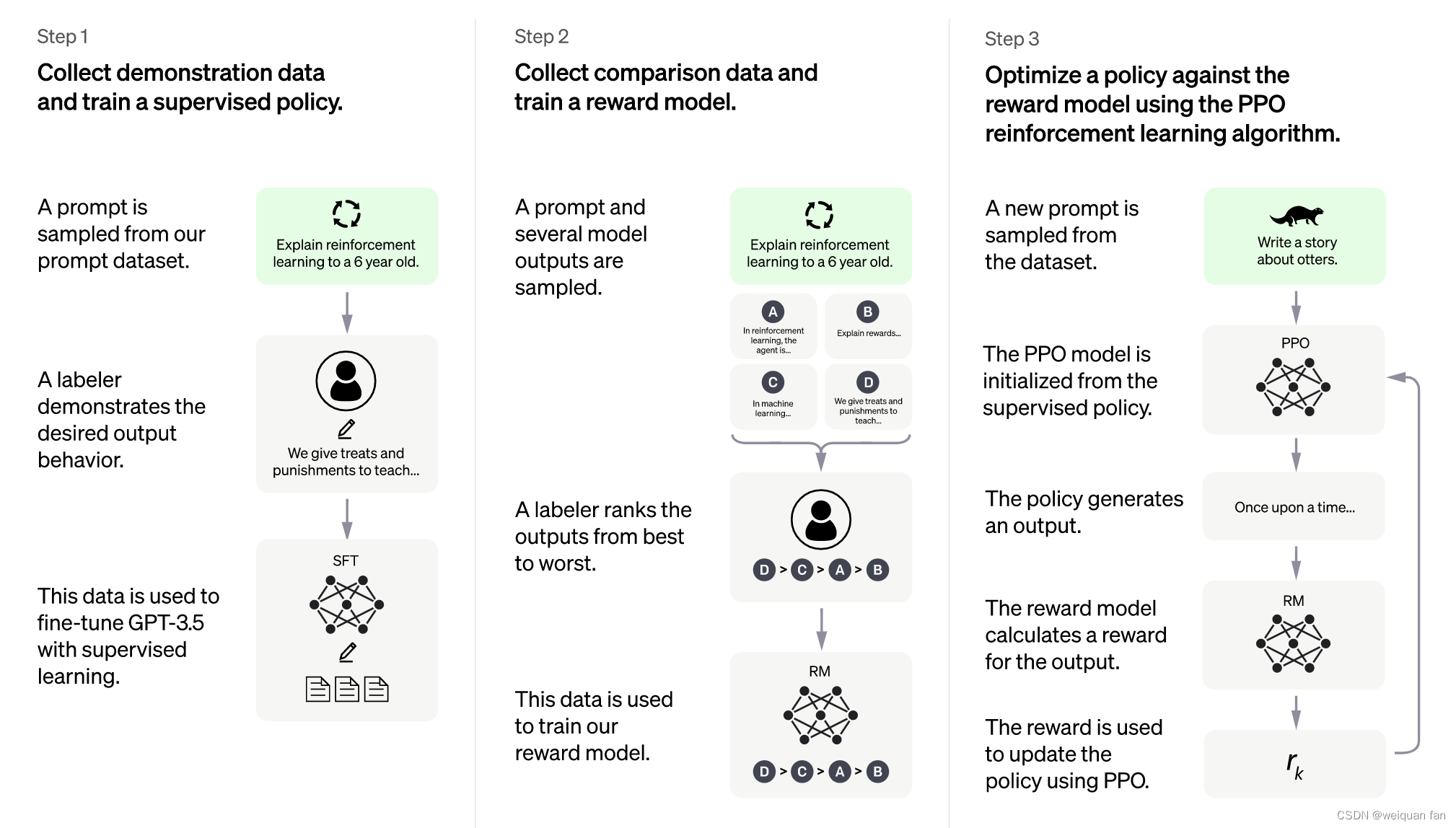
Since the details of ChatGPT have not yet been announced, according to InstructGPT, the main difference between it and GPT-3 is the use of RLHF (Reinforcement Learning from Human Feedback, human feedback reinforcement learning), that is, to optimize the language model based on human feedback by means of reinforcement learning, through The introduction of human knowledge trains a more reasonable dialogue model.
Among them, RLHF is a complex concept involving multiple models and different training stages, which can be broken down into three steps:
- Pre-train a language model (LM);
- Aggregate question and answer data and train a reward model (Reward Model, RM);
- Fine-tuning LMs with reinforcement learning (RL).
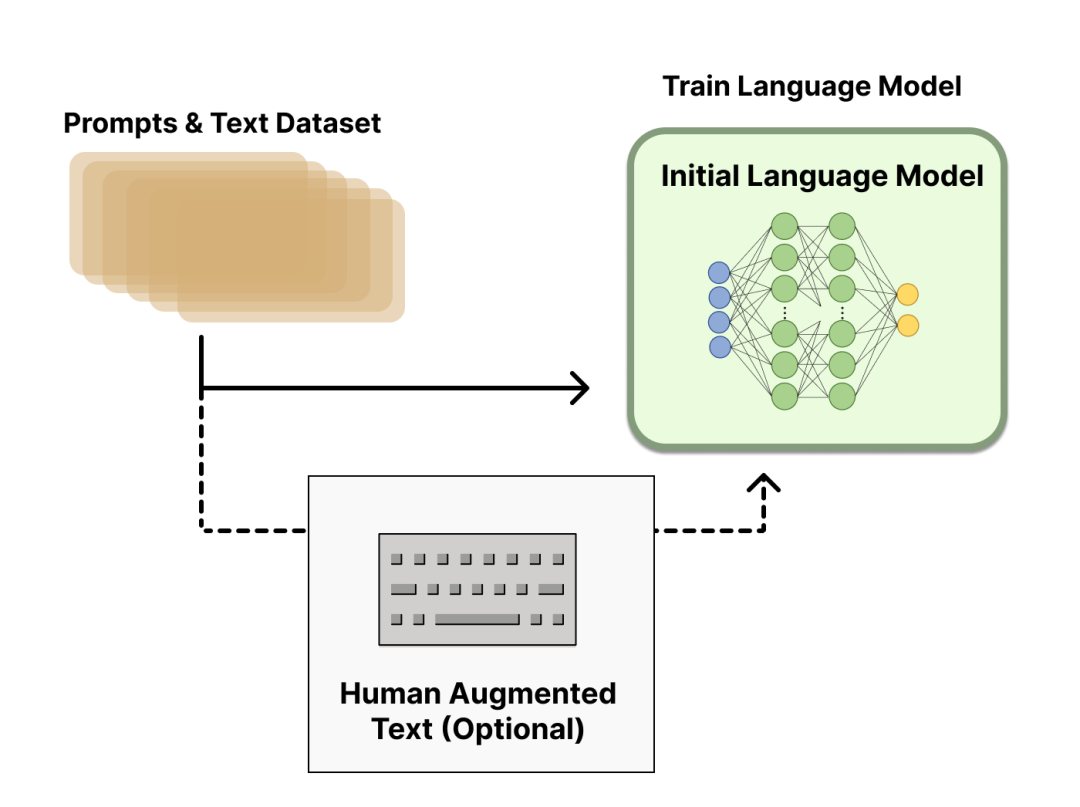
2.1 Pre-trained language model
This step can obtain the SFT (Supervised Fine-Tuning) model. ChatGPT is based on the LM of GPT-3.5 and fine-tuned by additional text or conditions (this is optional). OpenAI fine-tuned the "preferable" human-generated text, where the "preferable" evaluation criteria include:
- Authenticity: False or Misleading?
- Harmless: Does it cause physical or mental harm to people or the environment?
- Usefulness: Does it solve the user's task?
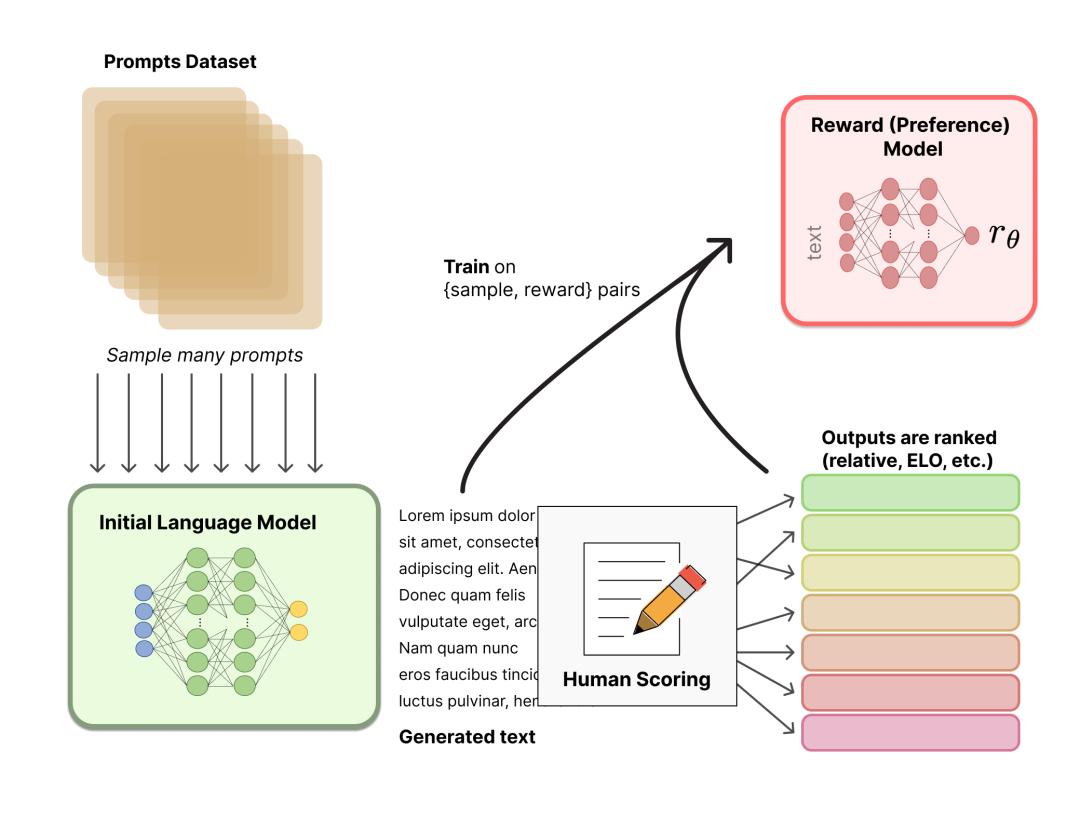
2.2 Training Reward Model
In this step, an RM (Reward Model) model can be obtained.
Regarding model selection, the RM can be another fine-tuned LM, or an LM trained from scratch on preference data.
Regarding the training text, the RM's hint-generation pairs are sampled from a predefined dataset, and the initial LM is used to generate text for these hints.
Regarding the value of the training rewards, it is necessary to manually rank the responses generated by the LM. At first, the author thought that RM should be trained directly on text annotation scores, but these scores were not calibrated and full of noise due to the different values of the annotators, and the output of multiple models can be compared and a better normative data set can be constructed through ranking.
For specific ranking methods, a successful approach is to compare the output of different LMs given the same prompt, and then use the Elo system to build a complete ranking. These different ranking results will be normalized to a scalar reward value for training.
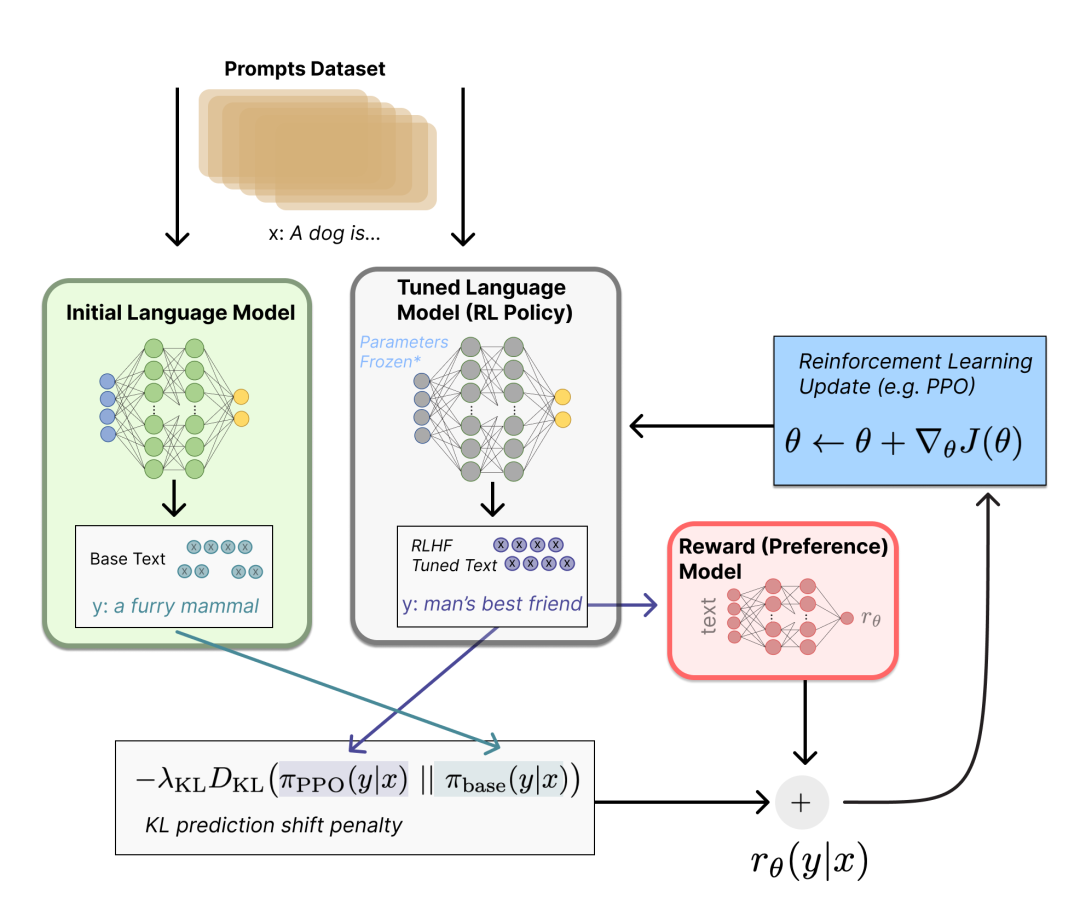
2.3 Fine-tuning with reinforcement learning
We first formulate the fine-tuning task as a reinforcement learning problem. First, a policy is an LM that takes a hint and returns a sequence of texts (or a probability distribution of texts). The action space of this strategy is all the tokens corresponding to the LM vocabulary (generally on the order of 50k), and the observation space is the possible input token sequence, which is also relatively large (vocabulary ^ input token quantity) . The reward function is a combination of preference models and policy transition constraints.
Fine-tune some or all parameters of the initial LM through Proximal Policy Optimization (PPO). For an input text, according to the initial LM of the first step and the current fine-tuned LM, the output text y1, y2 can be obtained respectively, and these two outputs are constrained by Kullback–Leibler (KL) divergence. Combined with the output of the current fine-tuning LM through the reward value obtained by the RM of the second step, it is optimized through PPO.
3. Current deficiencies
Although ChatGPT has demonstrated excellent contextual dialogue ability and even programming ability, it has completed the change of the public's impression of the human-machine dialogue robot (ChatBot) from "artificial mental retardation" to "interesting", we must also see that ChatGPT technology still has some limitations , is still making progress.
1) ChatGPT lacks "human common sense" and extension ability in areas where it has not been trained with a large amount of corpus, and it will even be serious "nonsense". ChatGPT can "create answers" in many fields, but when users seek correct answers, ChatGPT may also give misleading answers. For example, let ChatGPT do a primary school application problem. Although it can write a long list of calculation processes, the final answer is wrong.
2) ChatGPT cannot handle complex, lengthy or particularly professional language structures. For questions from very specialized domains such as finance, natural sciences, or medicine, ChatGPT may not be able to generate appropriate responses without sufficient corpus "feeding".
3) ChatGPT requires a very large amount of computing power (chips) to support its training and deployment. Regardless of the need for a large amount of corpus data to train the model, at present, ChatGPT still needs server support with large computing power when it is applied, and the cost of these servers is unaffordable for ordinary users. Even a model with billions of parameters requires amazing amount of computing resources to run and train. , if facing hundreds of millions of user requests of real search engines, such as adopting the current free strategy, it is difficult for any enterprise to bear this cost. Therefore, for the general public, they still need to wait for a lighter model or a more cost-effective computing power platform.
4) ChatGPT has not been able to incorporate new knowledge online, and it is unrealistic to re-train the GPT model when some new knowledge emerges. Whether it is training time or training cost, it is difficult for ordinary trainers to accept. If the online training mode is adopted for new knowledge, it seems feasible and the corpus cost is relatively low, but it is easy to cause catastrophic forgetting of the original knowledge due to the introduction of new data.
5) ChatGPT is still a black-box model. At present, the internal algorithm logic of ChatGPT has not been decomposed, so there is no guarantee that ChatGPT will not produce statements that attack or even harm users.