Article directory
- 1. How to learn deep learning model design and optimization
-
- 1.1 Model design for deep learning
-
- 1.1.1 Model depth - the key to performance improvement
- 1.1.2 Channel Dimension Transformation—Basic Design Unit
- 1.1.3 Model Width—Model Expressability and Compression Key
- 1.1.4 Residual network - key technology for deep model training
- 1.1.5 Packet network - the core technology of model compression
- 1.1.6 Multi-scale and abnormal convolution - the core technology for improving the performance of complex task models
- 1.1.7 Dynamic Reasoning and Attention Mechanism Network—Core Technology for Model Optimization
- 1.1.8 Generative Adversarial Networks - A New Generation of Deep Learning Basic Technology
- 2. Model optimization for deep learning
- 3. How to design a CNN structure with stronger performance
- 4. How to obtain a more efficient CNN model structure
Note:
Record some of the knowledge in the video lessons .
1. How to learn deep learning model design and optimization
1.1 Model design for deep learning
1.1.1 Model depth - the key to performance improvement

1.1.2 Channel Dimension Transformation—Basic Design Unit

1.1.3 Model Width—Model Expressability and Compression Key
Increase the width of the model:
(1) Increase the number of channels
(2) Increase the branch, such as: from one channel to multiple channels

1.1.4 Residual network - key technology for deep model training

1.1.5 Packet network - the core technology of model compression

1.1.6 Multi-scale and abnormal convolution - the core technology for improving the performance of complex task models

1.1.7 Dynamic Reasoning and Attention Mechanism Network—Core Technology for Model Optimization

1.1.8 Generative Adversarial Networks - A New Generation of Deep Learning Basic Technology
2. Model optimization for deep learning
2.1 Requirements for industrial-grade networks

2.2 Technical points of model simplification and optimization

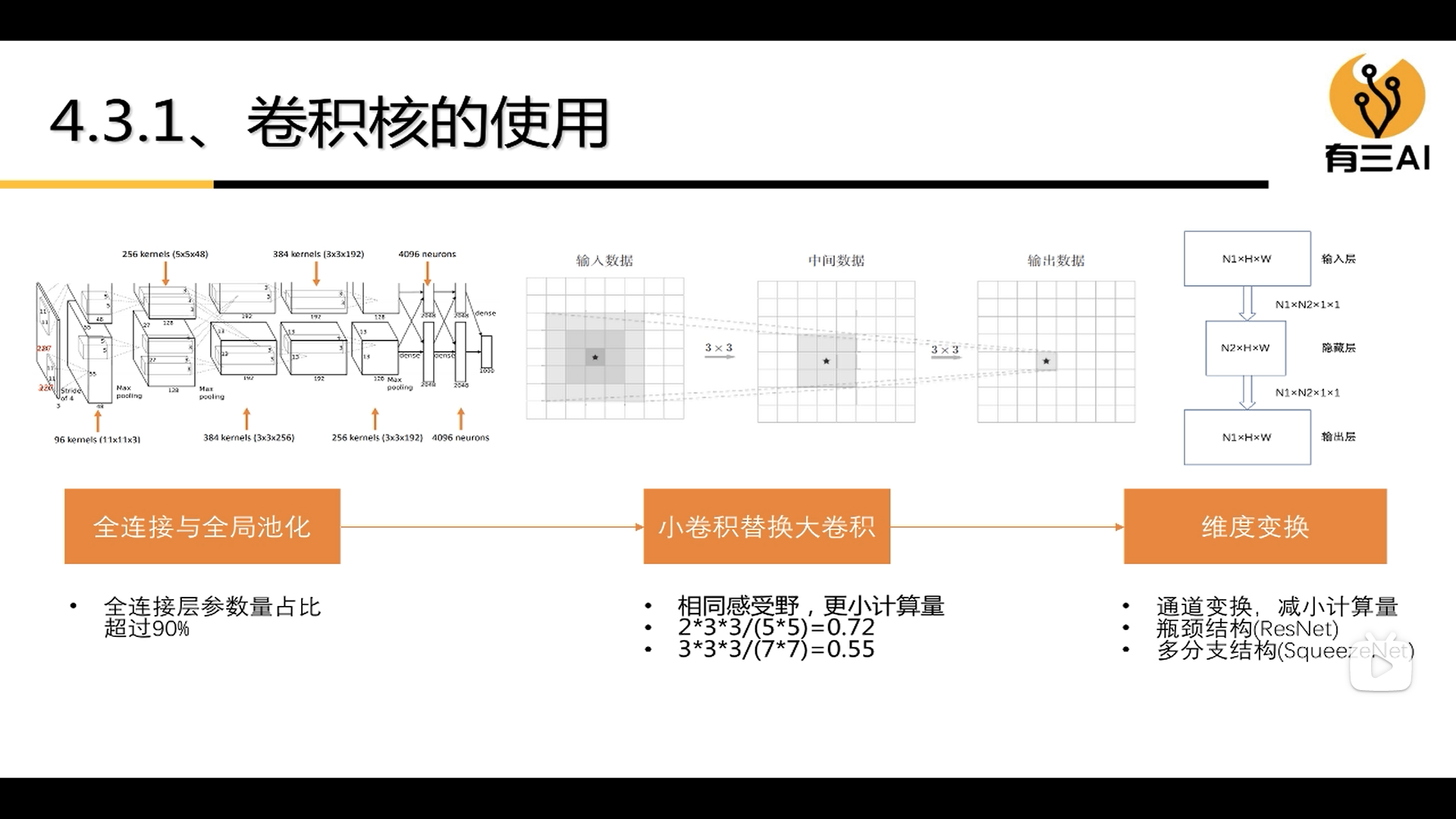
2.2.1 The use of convolution kernel
(1) Full connection and global pooling
(2) Small convolution replaces large convolution
(3) Dimensional transformation
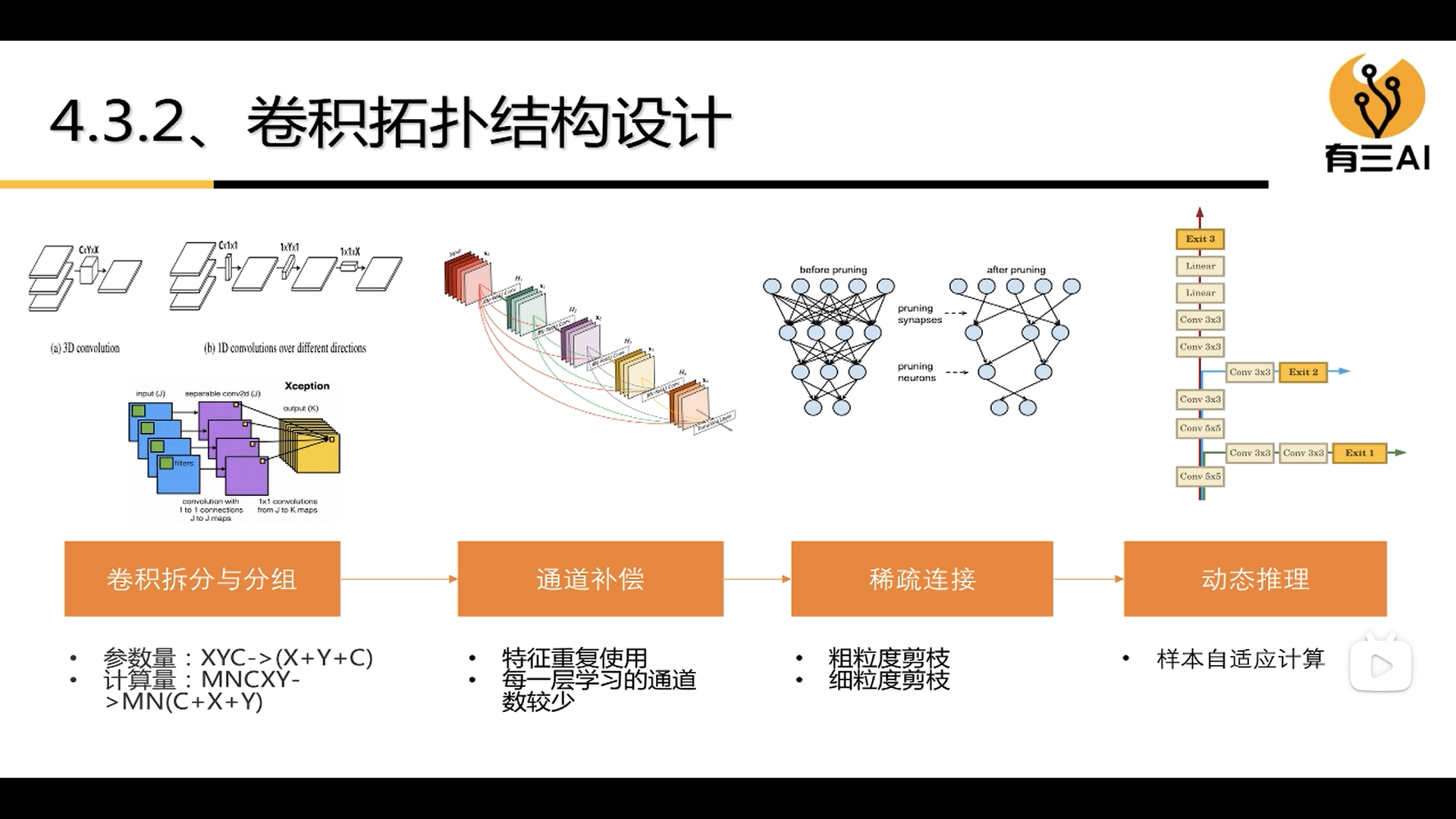
2.2.2 Convolution topology design
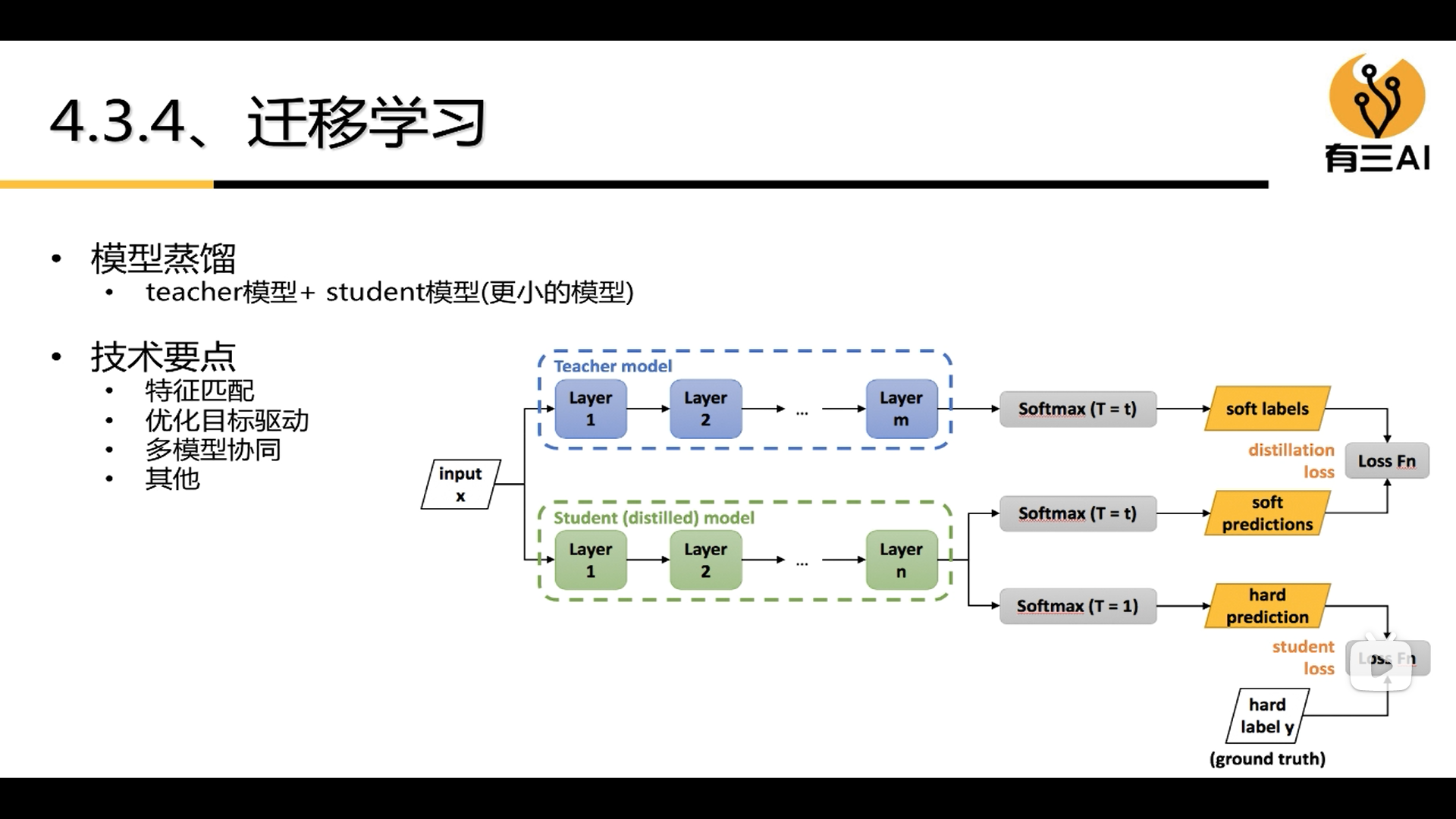
2.2.3 Transfer Learning
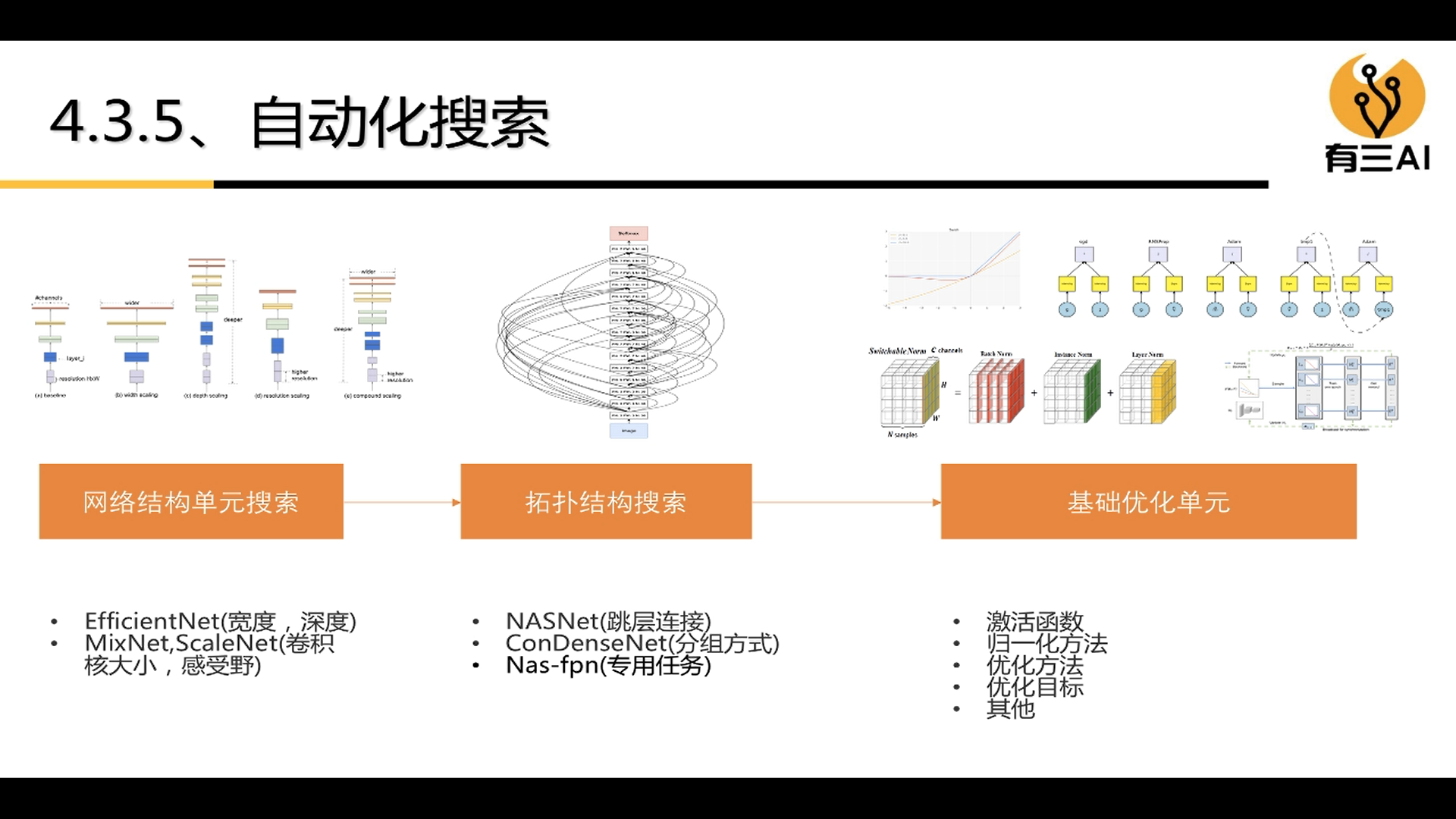
2.2.4 Automated Search
3. How to design a CNN structure with stronger performance
3.1 Design of Network Depth
3.1.1 Why deepening can improve performance
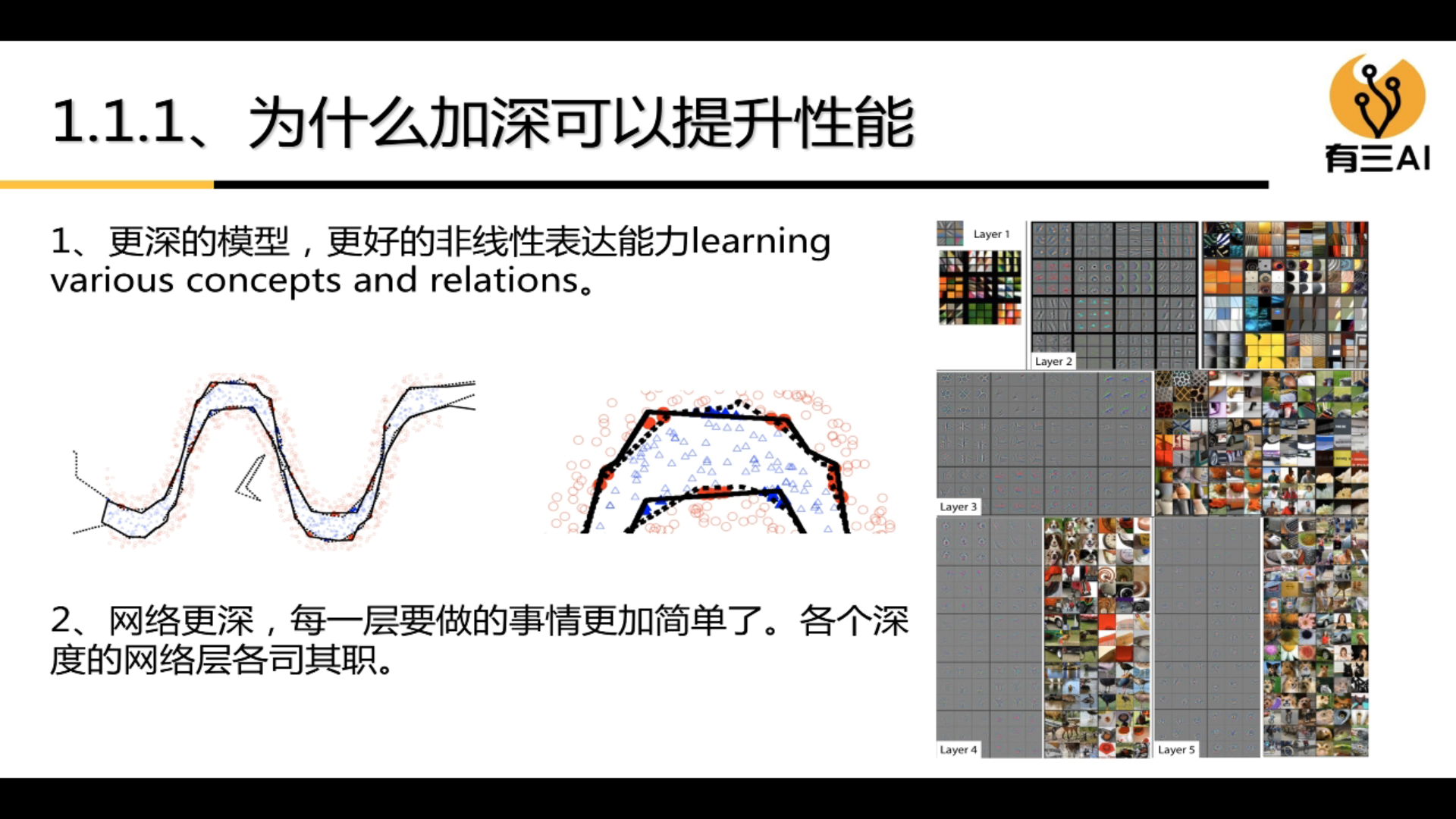
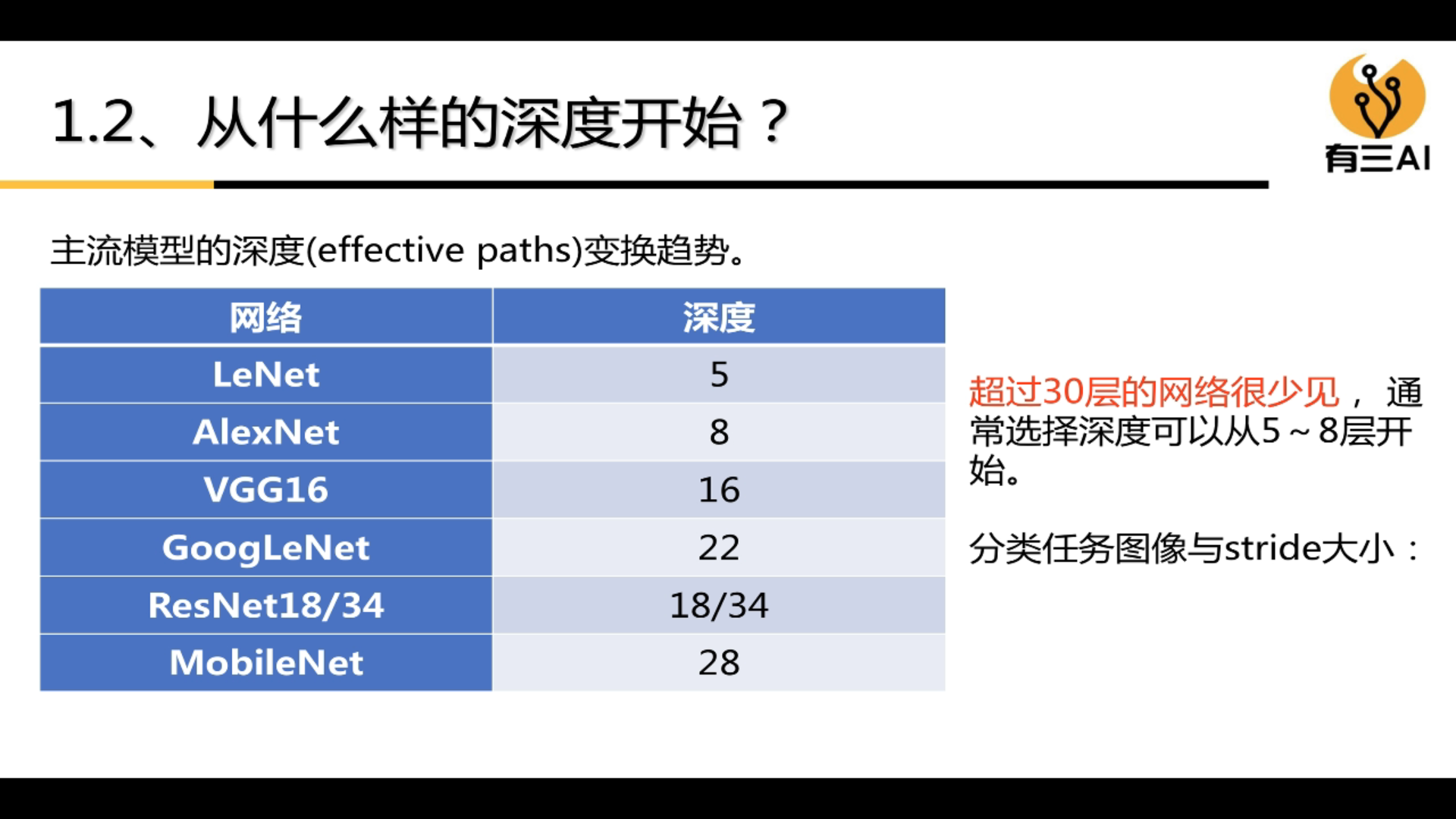
3.1.2 What depth to start with
(1) Networks with more than 30 layers are rare
(2) Usually, the depth of selection can start from 5 to 8 layers
3.1.3 Problems prone to occur in network deepening

3.2 Design of Network Width
3.2.1 Why do we need enough width - more width can learn richer features

The left part of the figure shows the visualization of the 96 channels of the first convolutional layer of AlexNet. It can be seen that
some channels are the shape features of the extracted pictures, and some are color information.
So if there are not enough channels, not so many features can be extracted.
3.2.2 Characteristics of network width
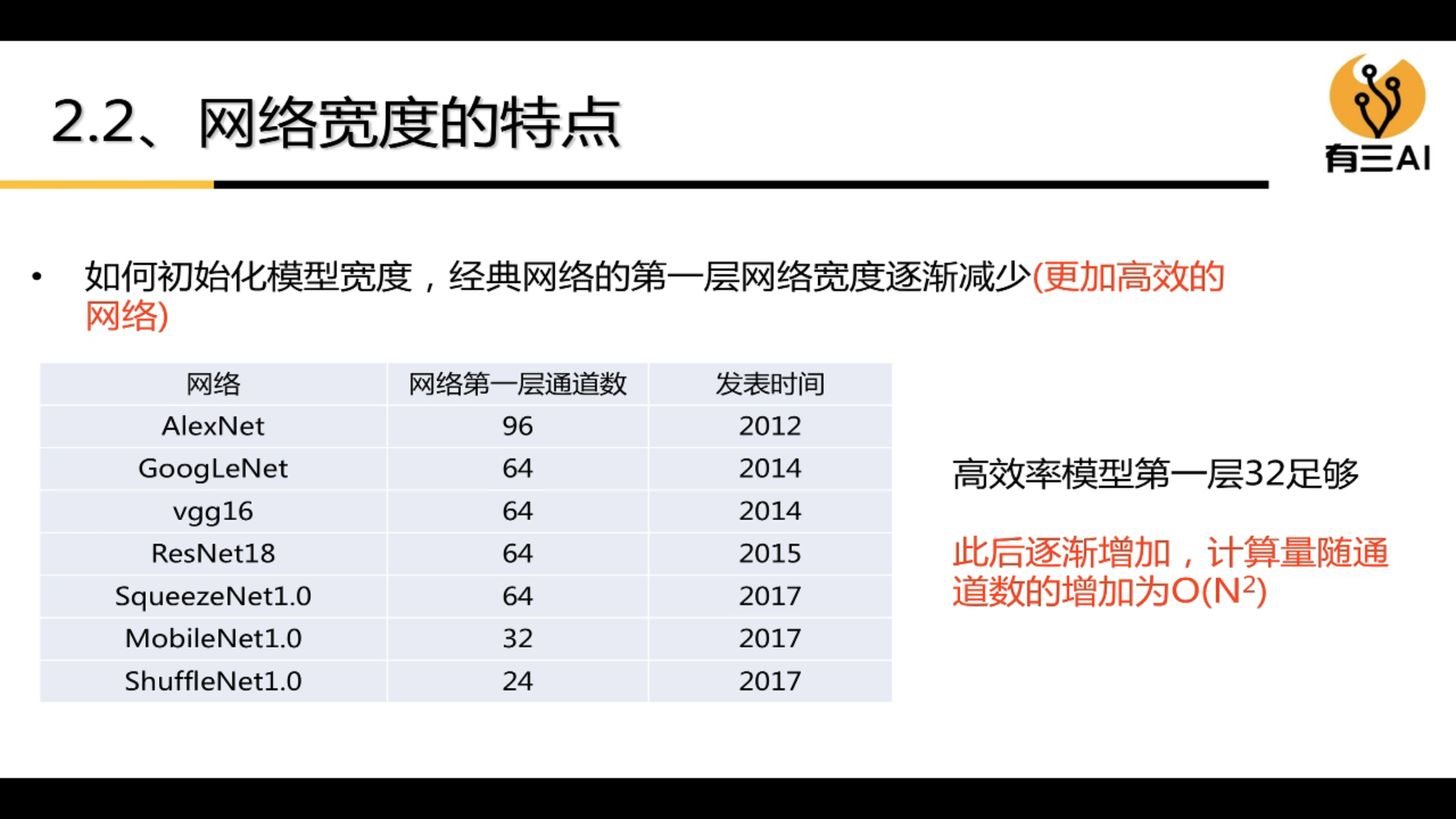
(1) As the width of the model increases, the calculation amount will also increase exponentially.
(2) Increasing the network width can improve the model performance, but it will be saturated after reaching a certain critical point.
3.2.3 Width Design Principles

3.3 Dropout and BN layer design
3.3.1 Benefits of Dropout
(1) Increase the generalization ability
(2) Alleviate the dead issue of ReLU
(3) Reduce the complex co-adaption between neurons. Figure a
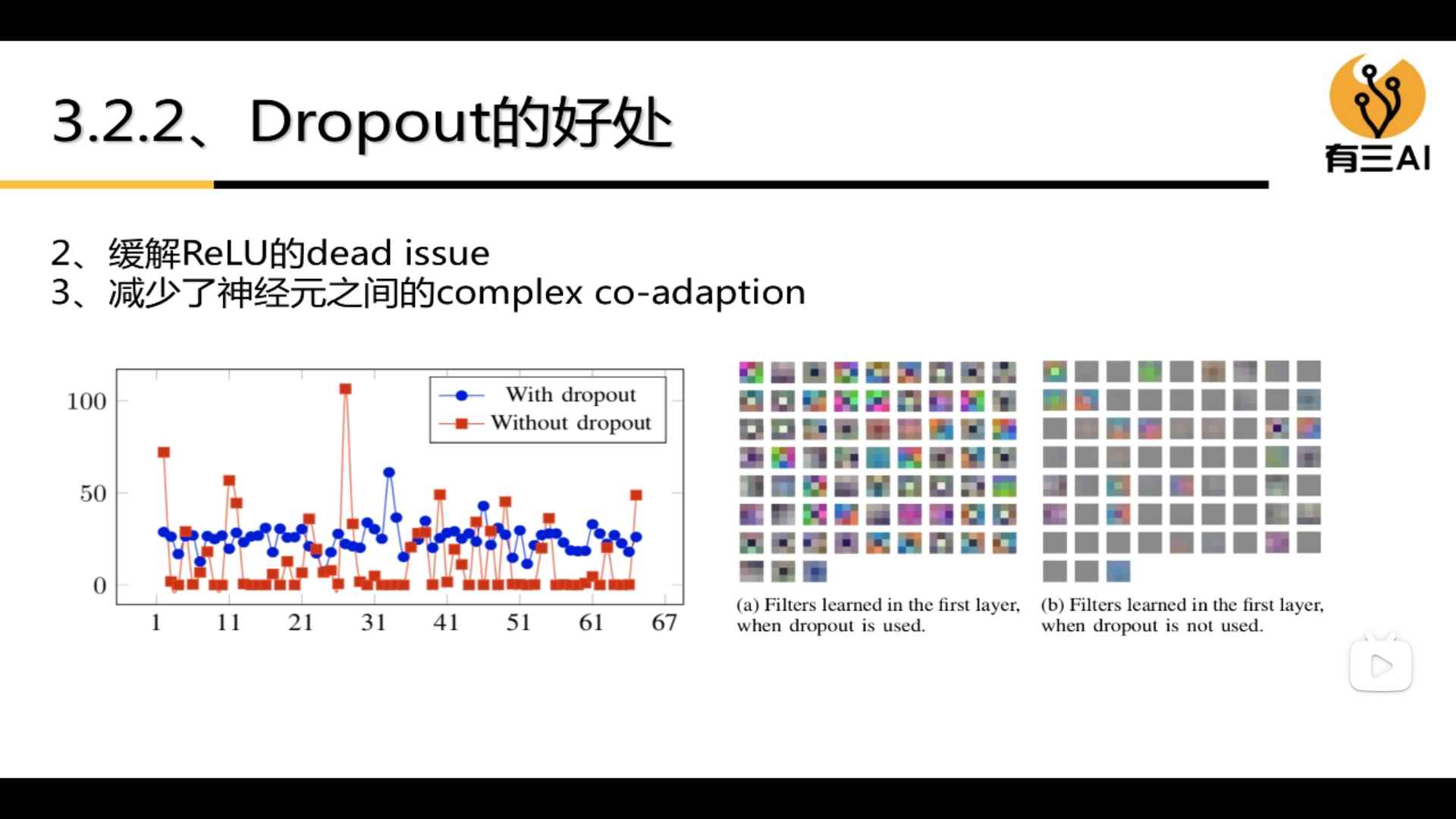
indicates that there is dropout, and its neuron performance is more abundant. Figure b indicates that there is no dropout, and its Neurons represent very little.
3.3.2 Problems using Dropout
Dropout is equivalent to adding noise and causing gradient loss, so it is necessary to use a larger learning rate and momentum item, and the training will take longer to converge.
3.3.3 Why BN is good

3.3.4 Precautions for using BN

3.4 Design of convolution kernel size, step size and pooling
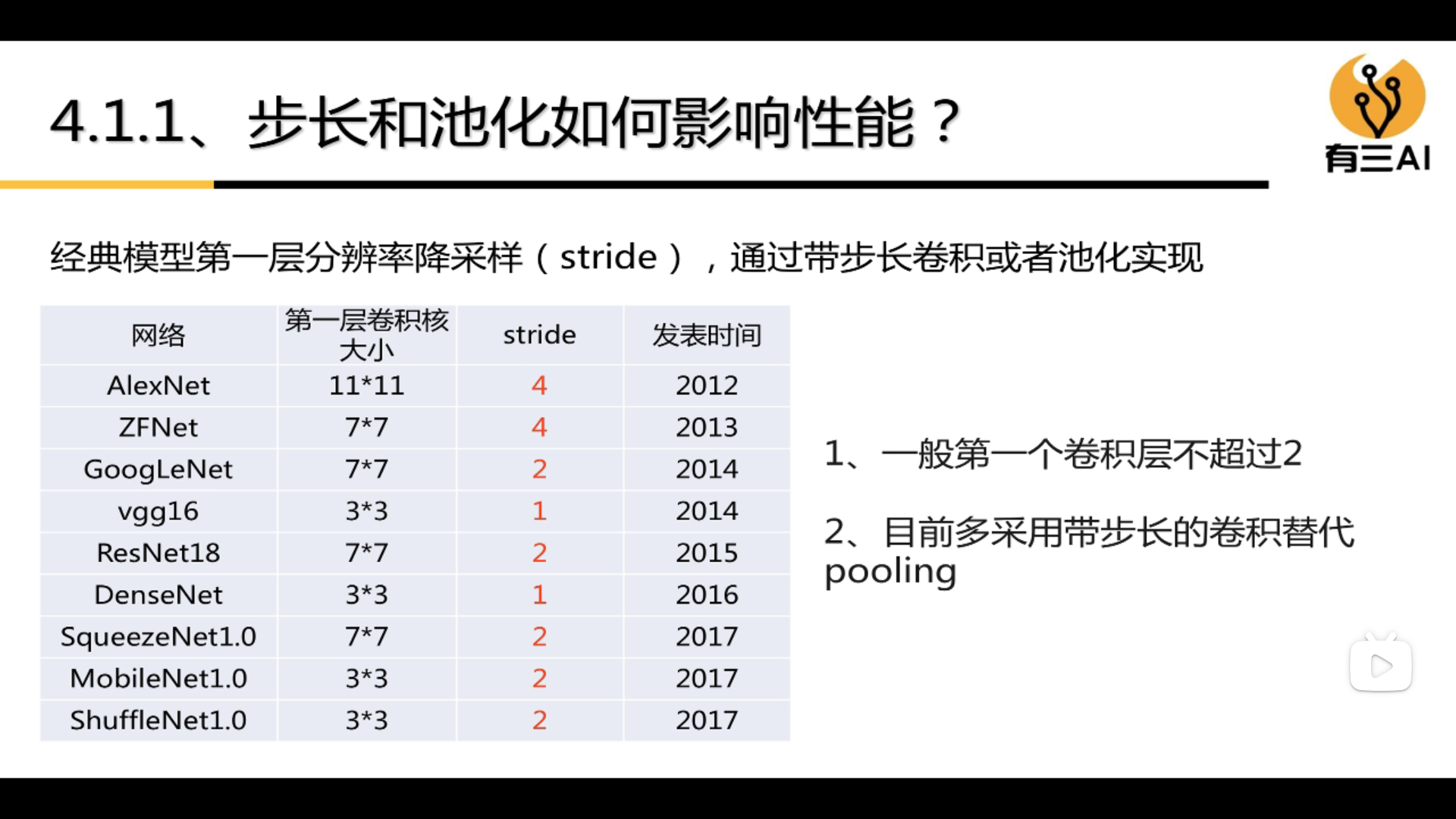
3.4.1 How stride and pooling affect performance
(1) Generally, the first convolutional layer does not exceed 2
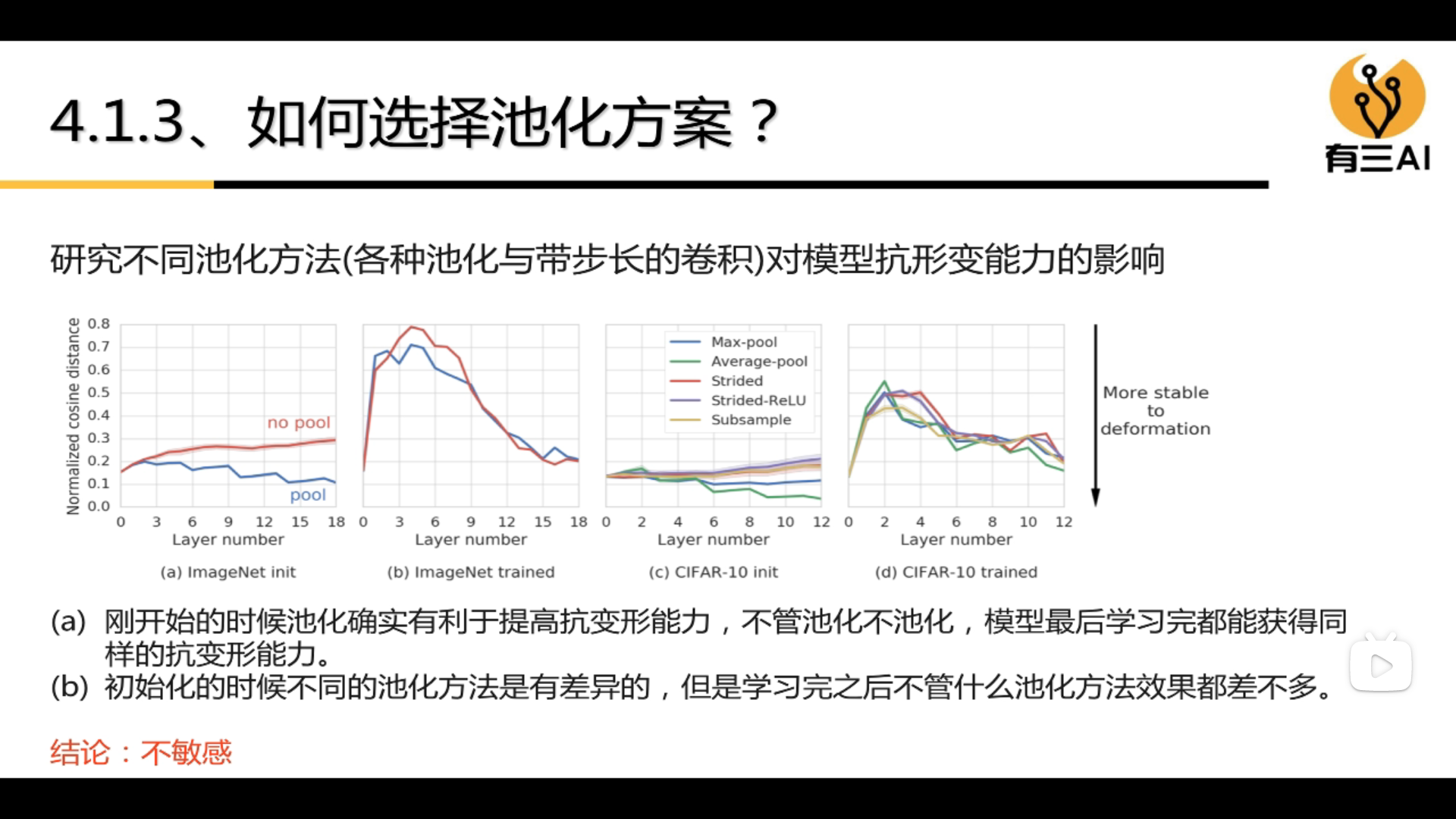
3.4.2 How to choose a pooling scheme
3.4.3 How to design the step size

3.4.4 How the size of the convolution kernel affects model performance
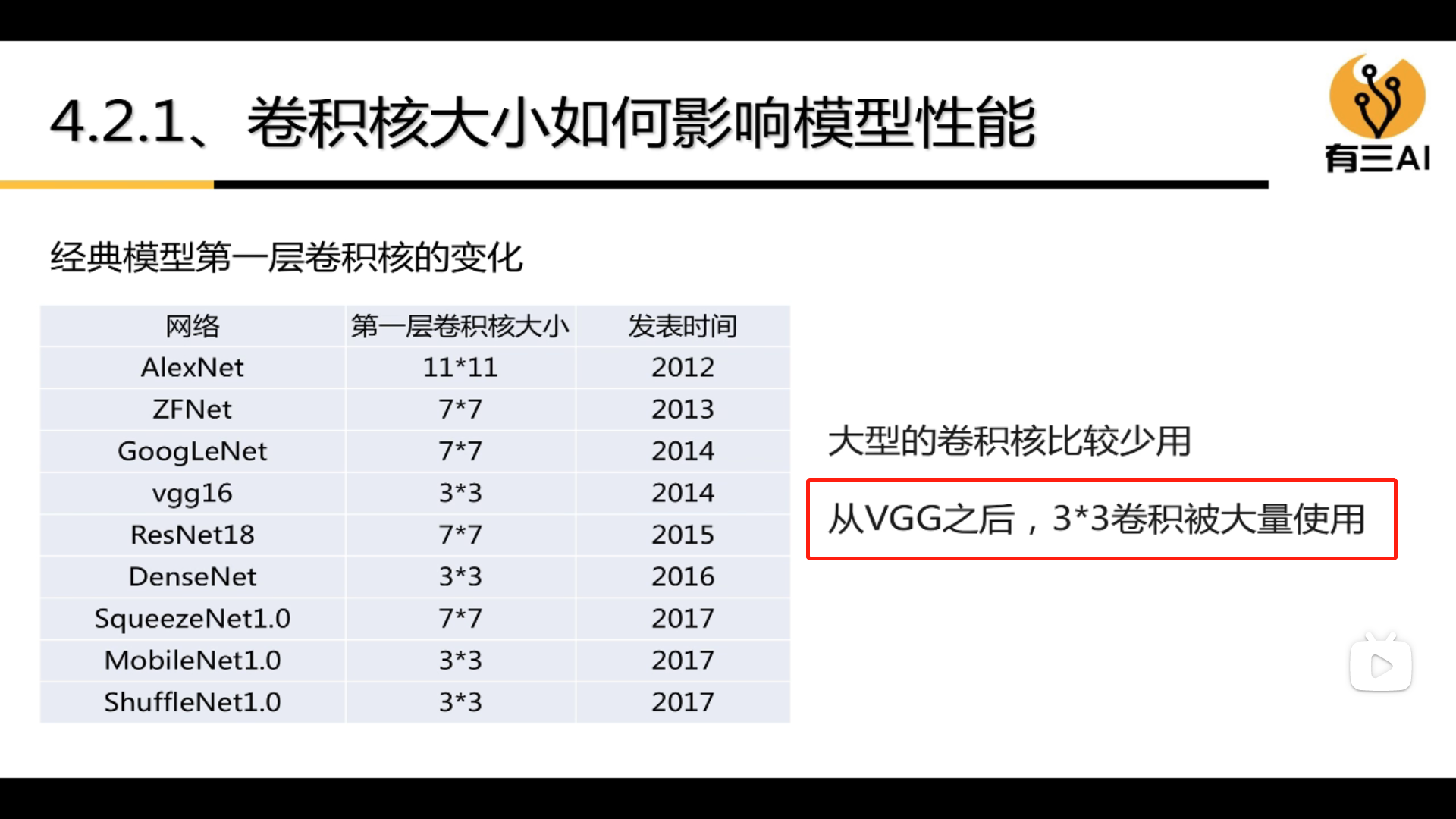

3.4.5 How to design the convolution kernel size

3.5 Understanding and Design of Residual Structure
3.5.1 Why the residual structure is effective

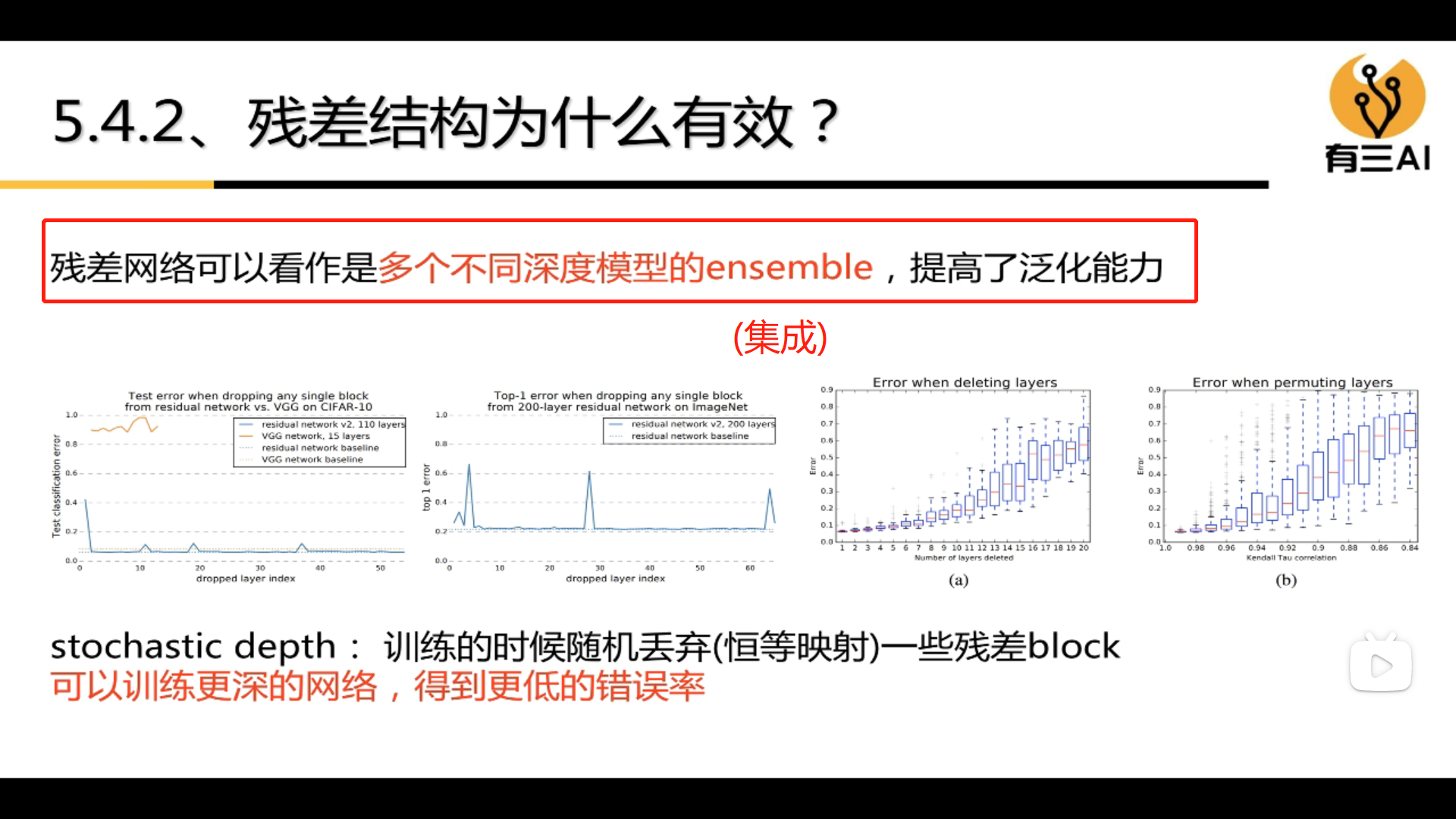
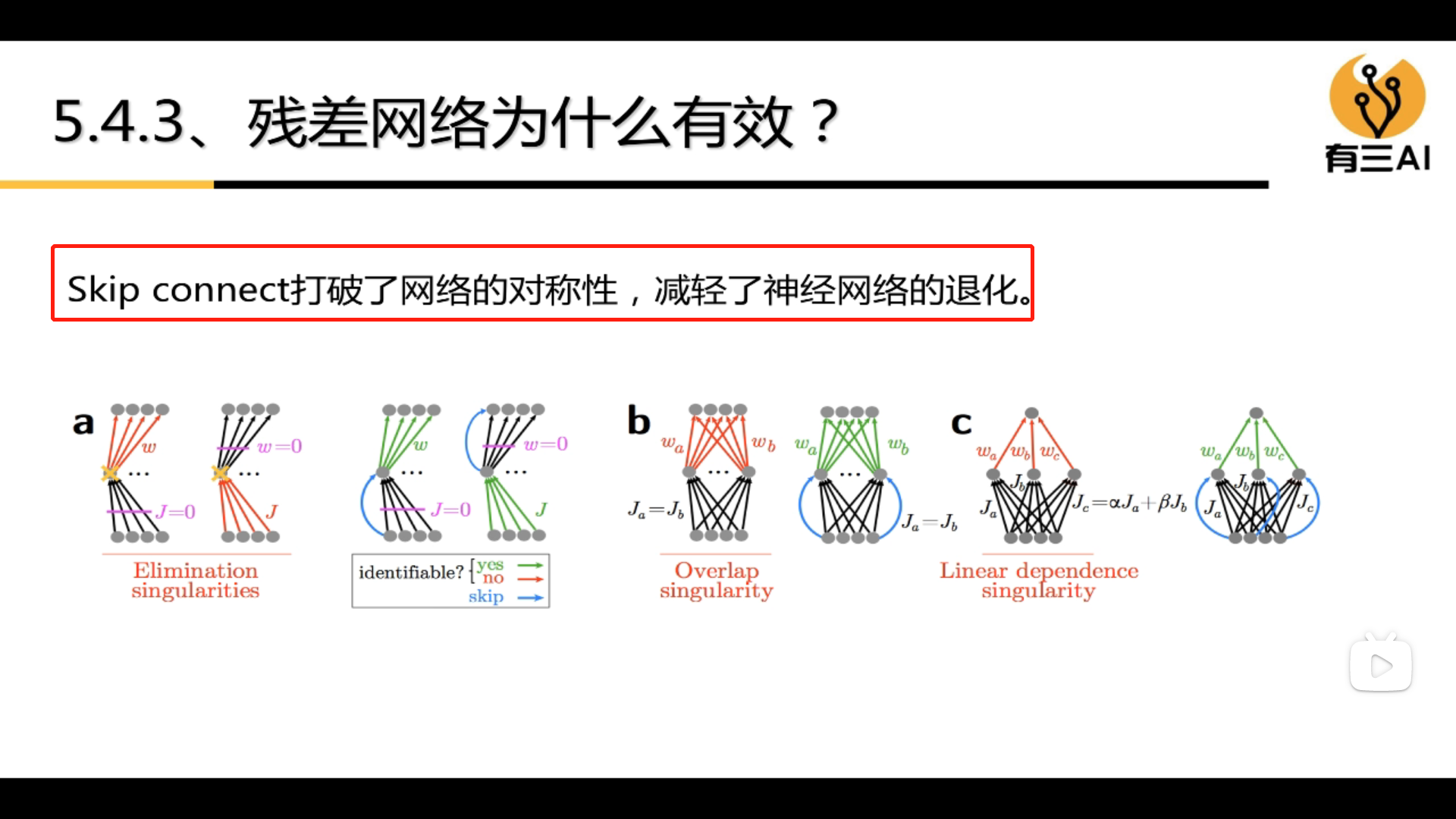
3.5.2 How to design a residual network

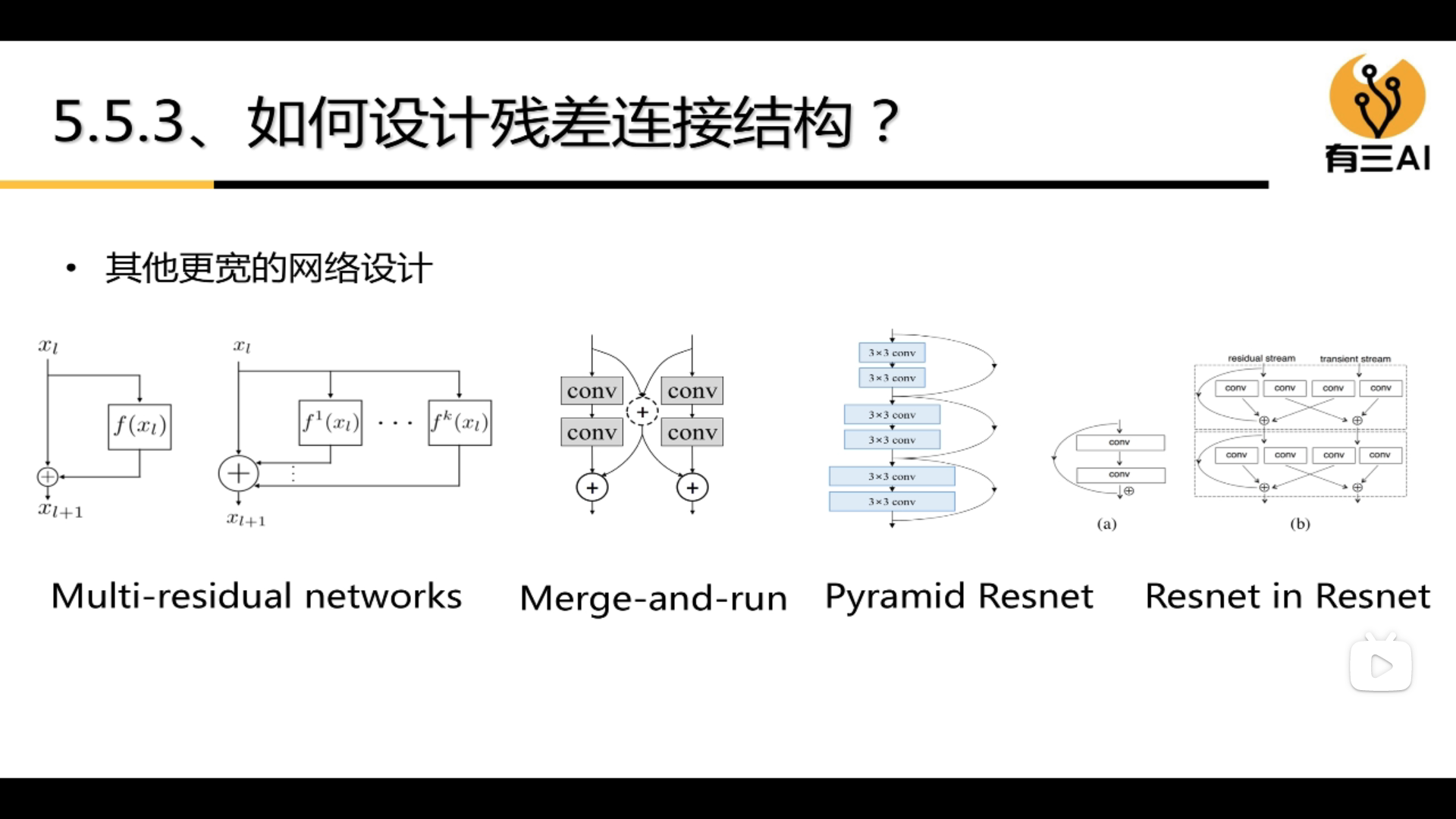
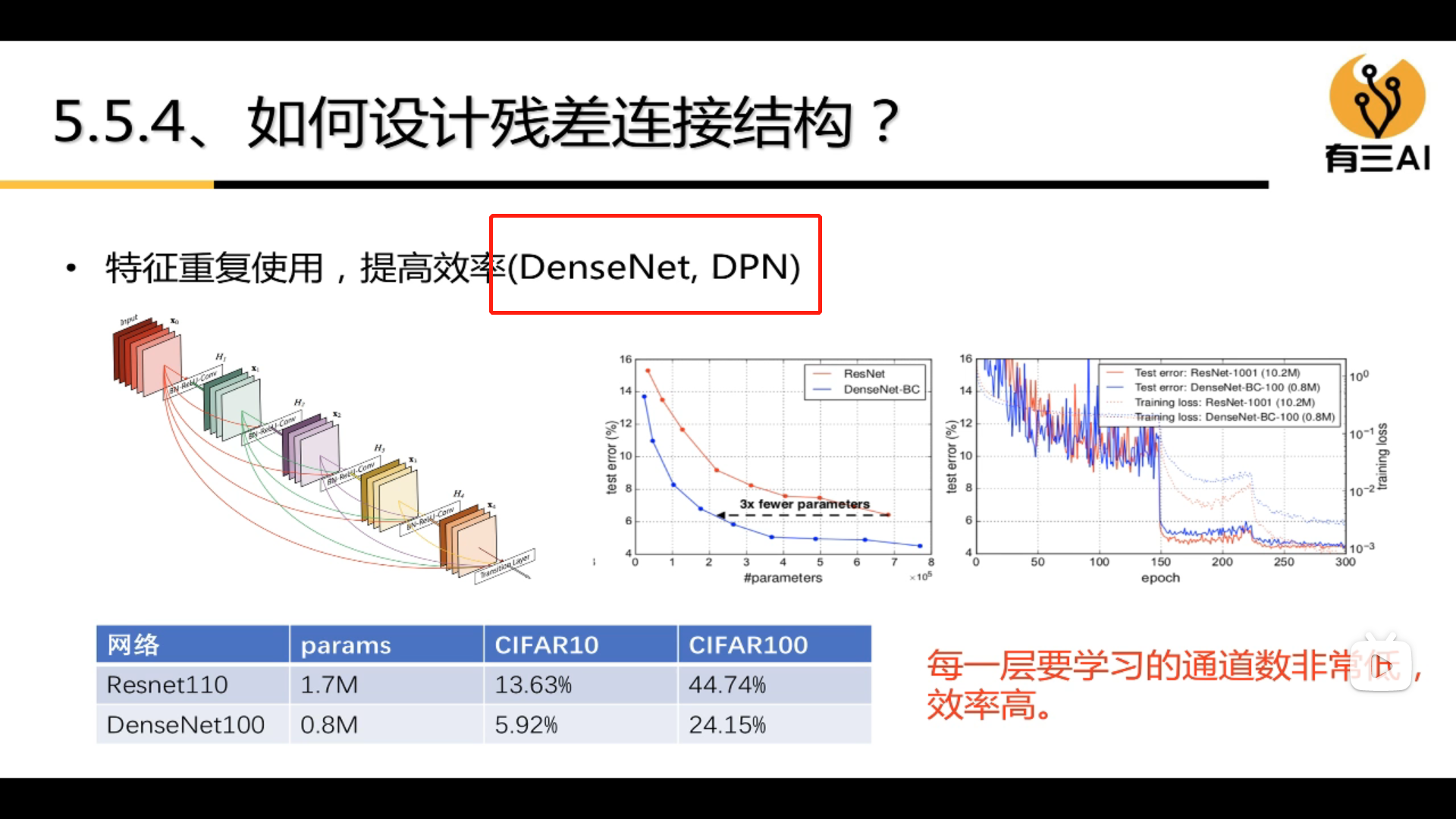
3.6 Multi-scale and information fusion
3.6.1 How to design a multi-scale network

3.7 Others
3.7.1 Attention

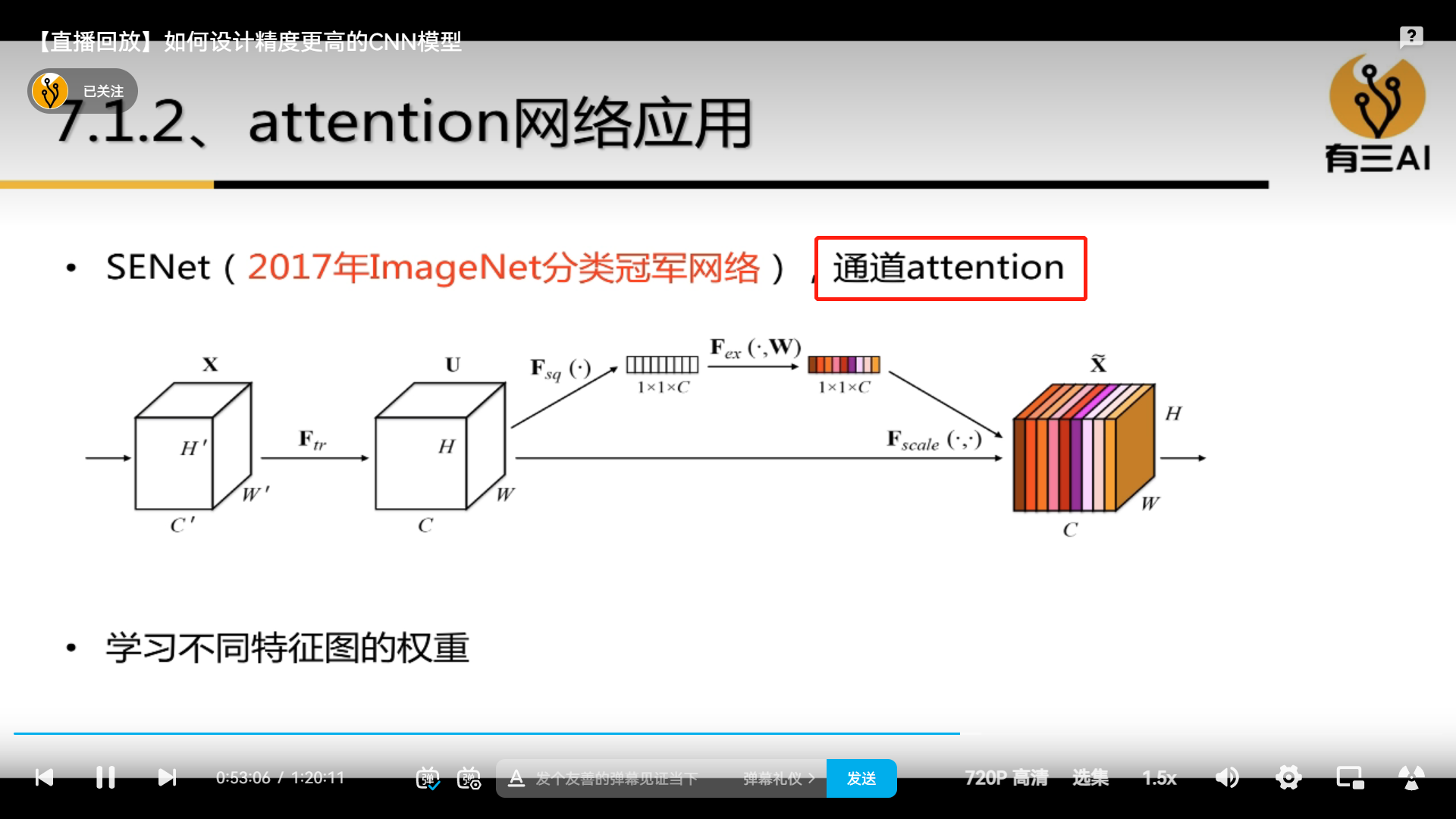
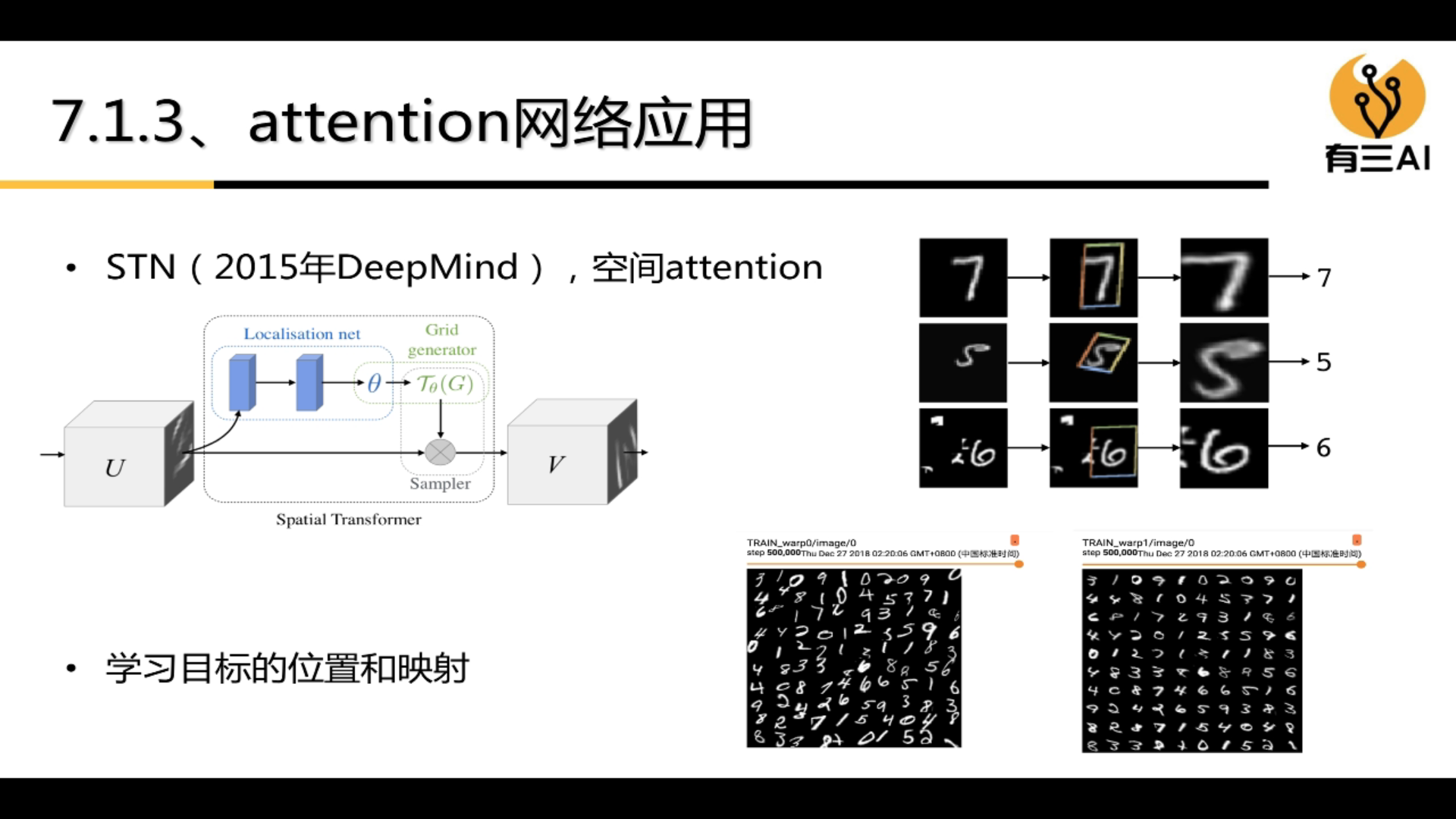
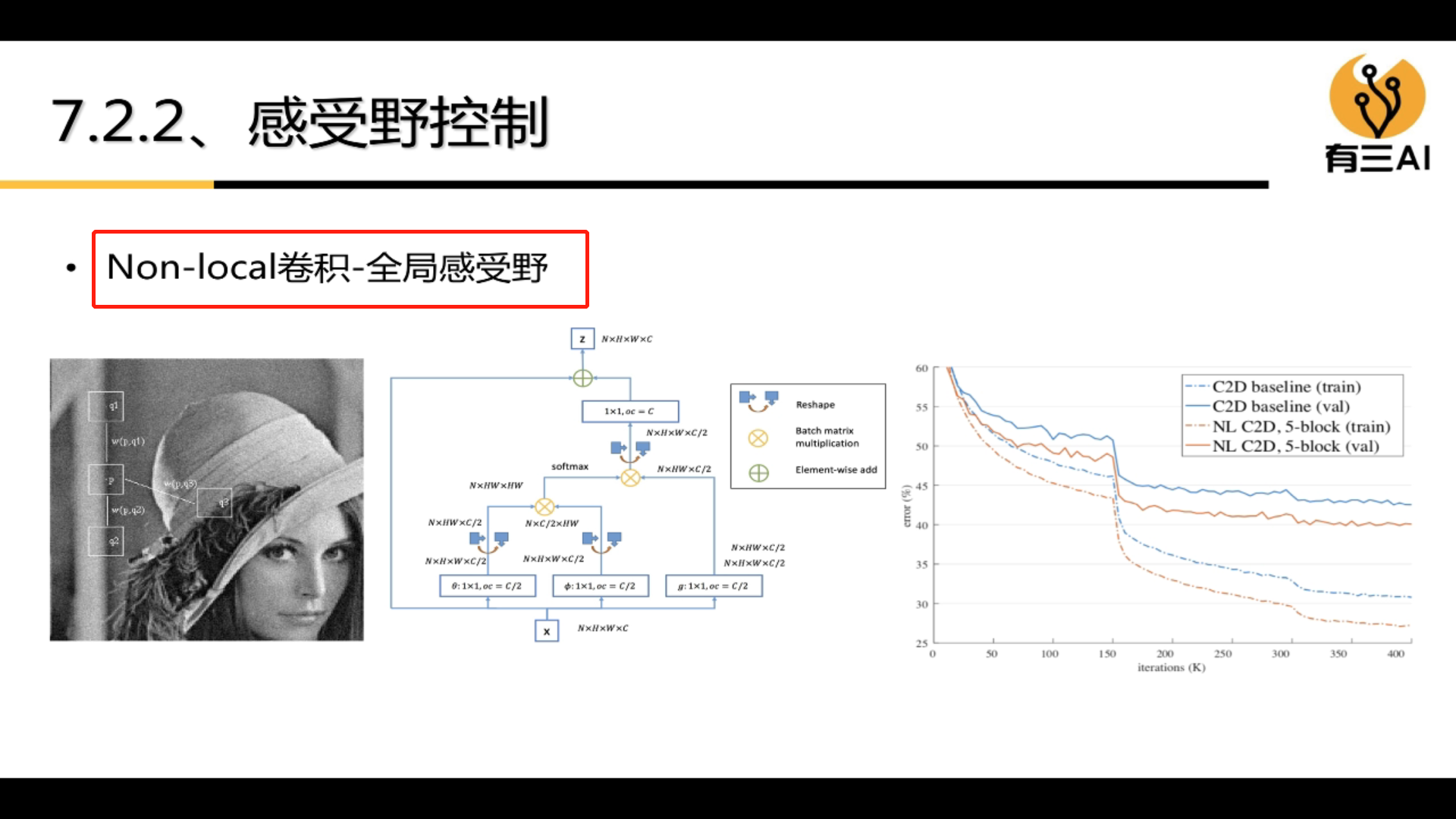
3.7.2 Receptive field control


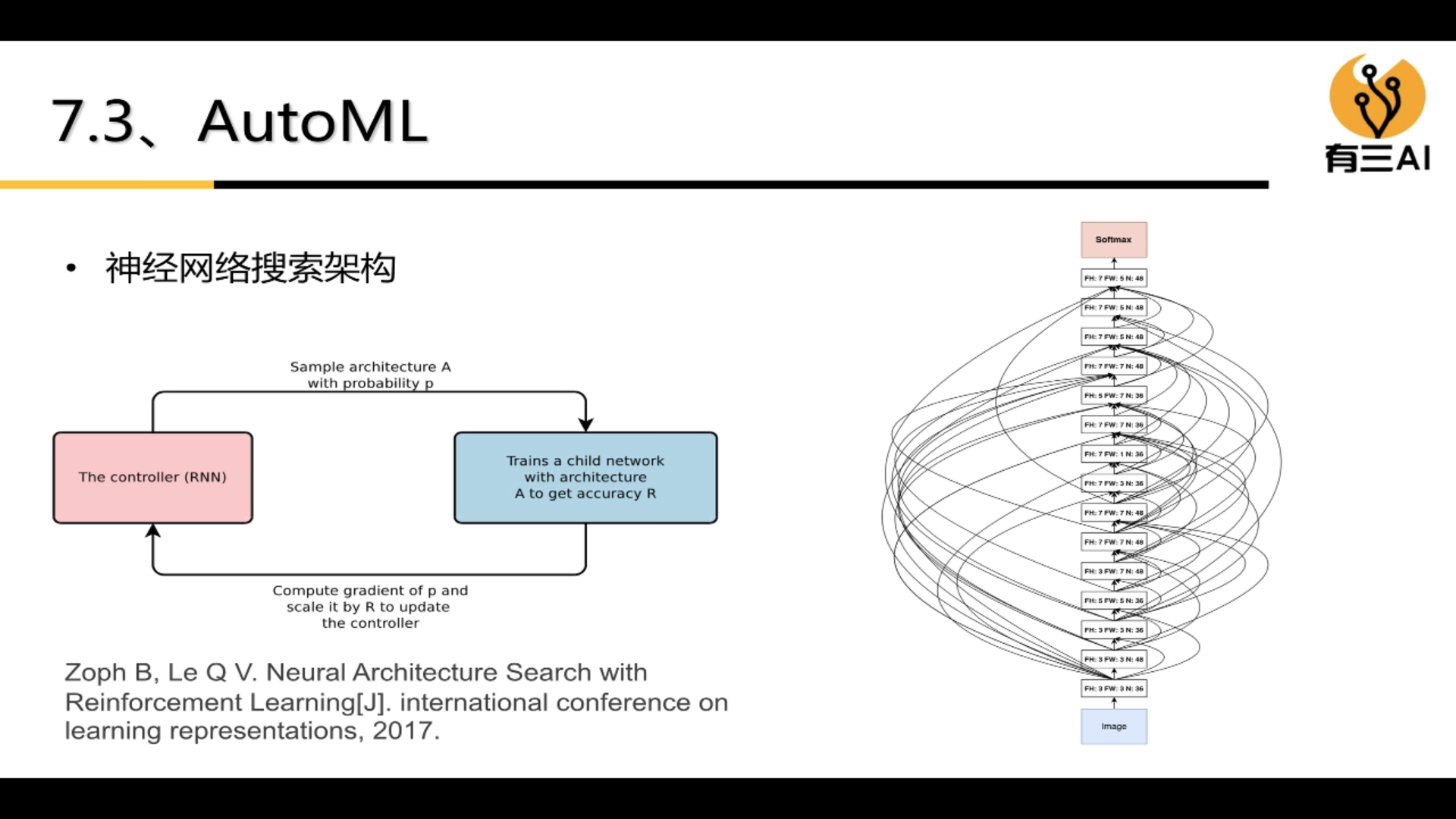
3.7.3 AutoML
3.8 GAN network
4. How to obtain a more efficient CNN model structure
4.1 What is a more efficient CNN network

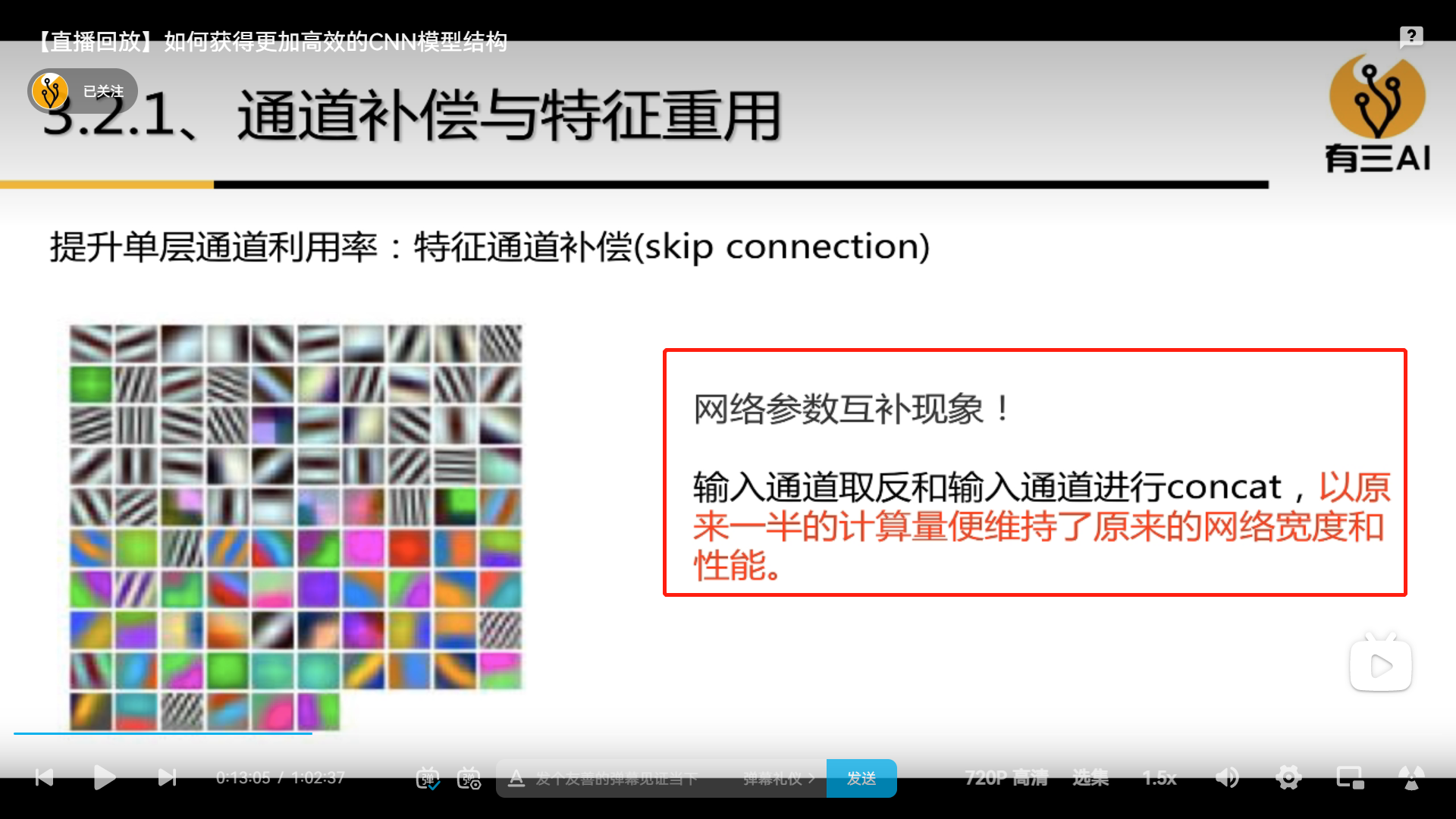
4.2 Channel Compensation and Channel Reuse
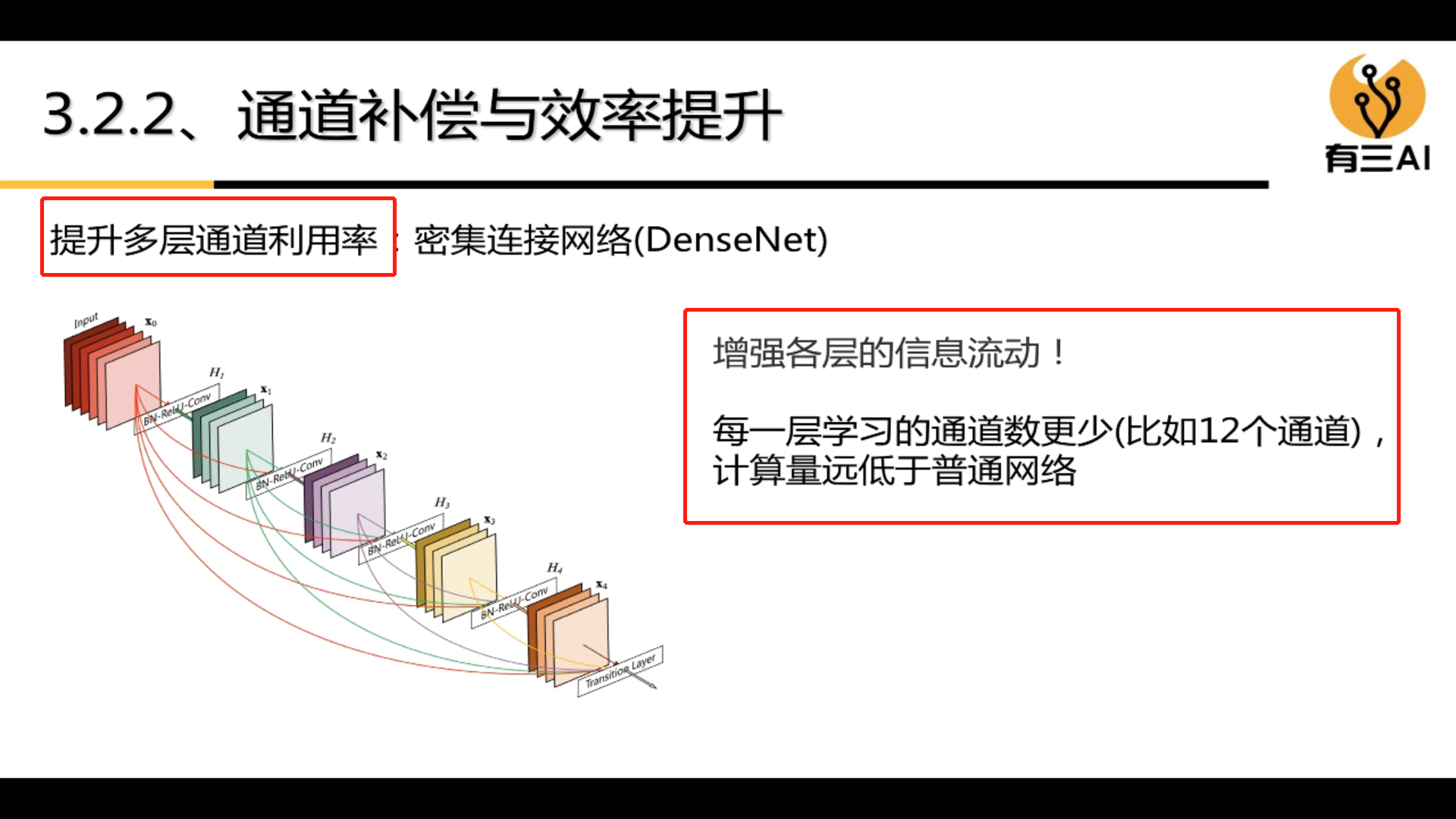
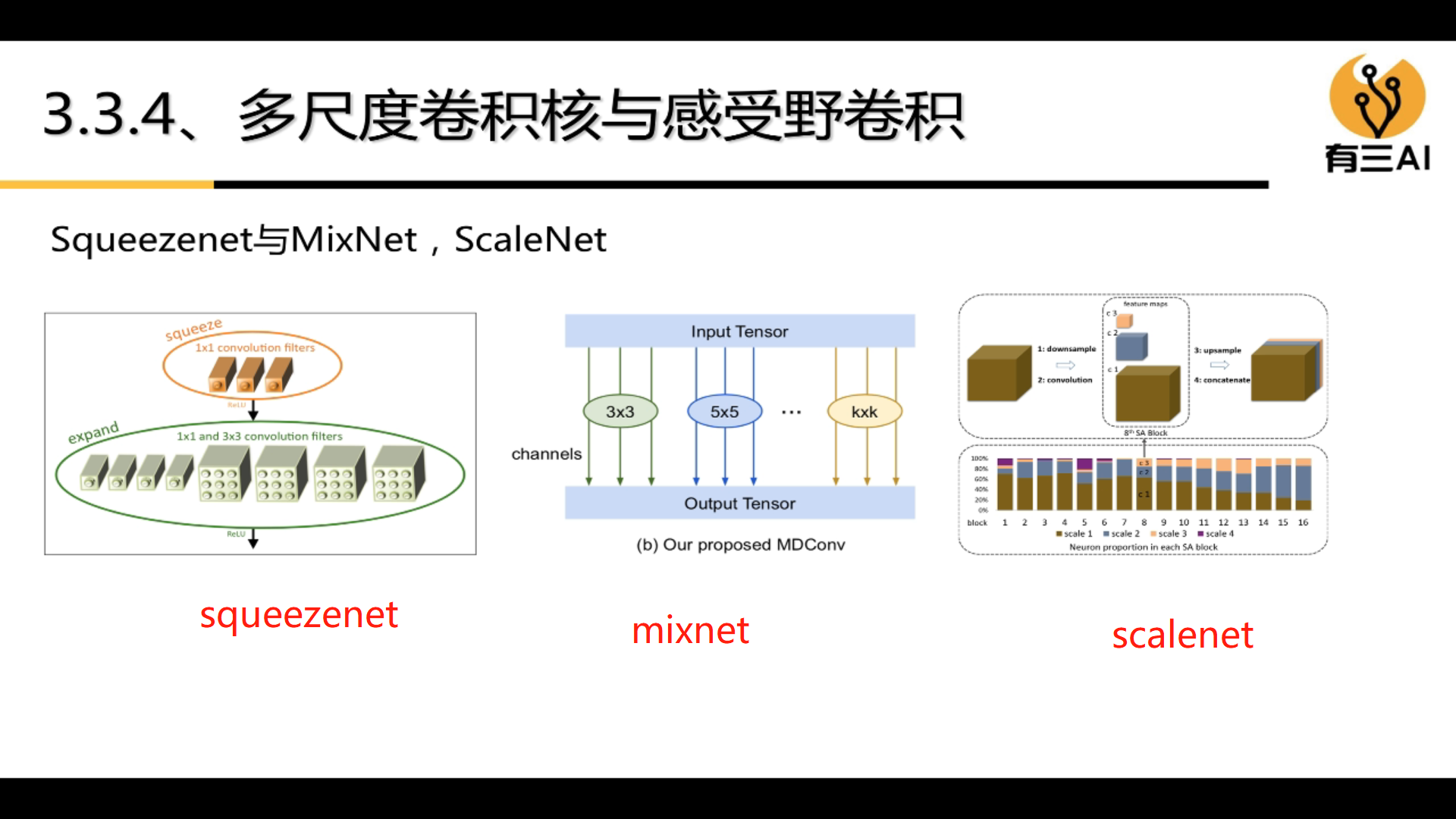
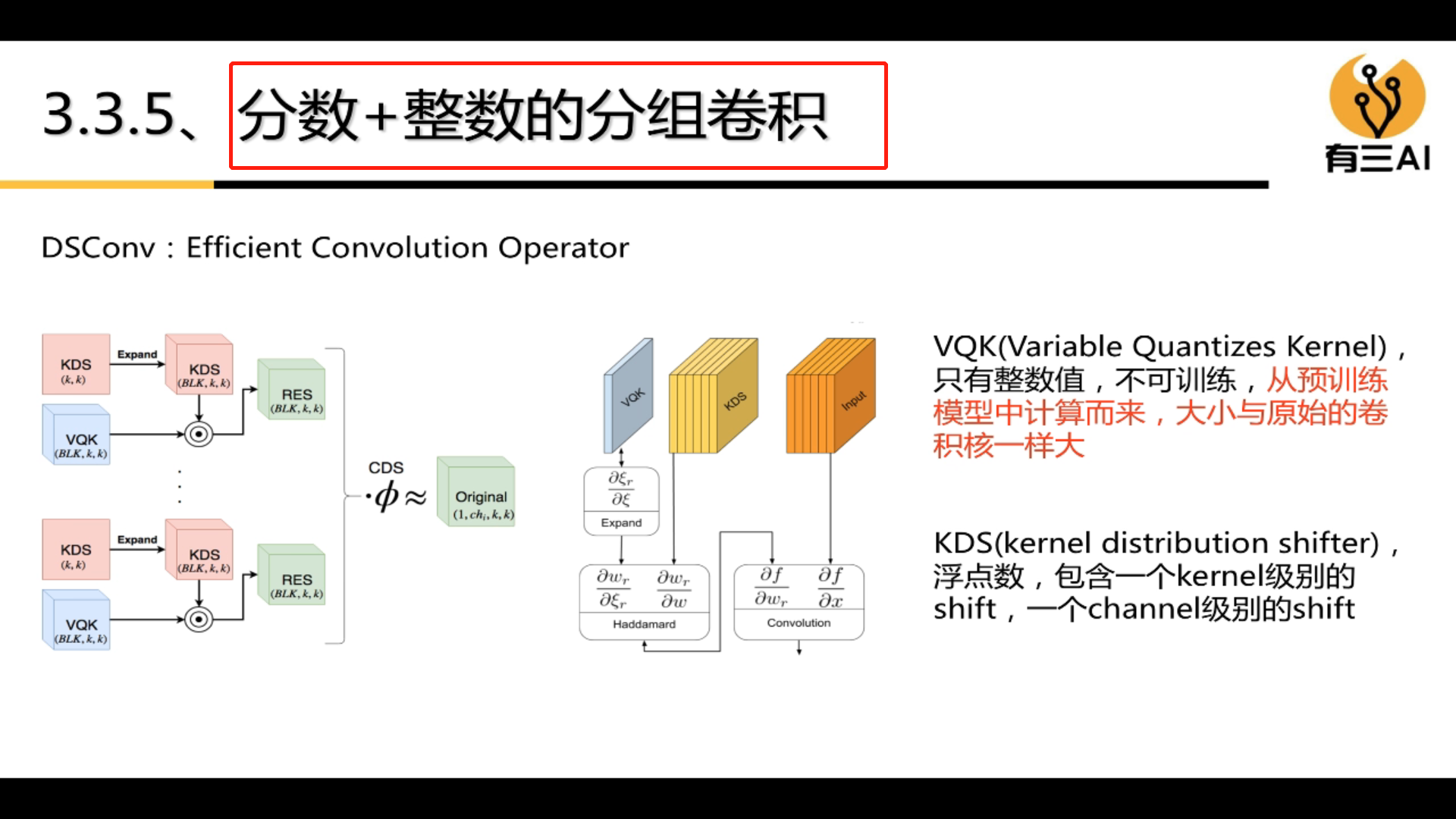
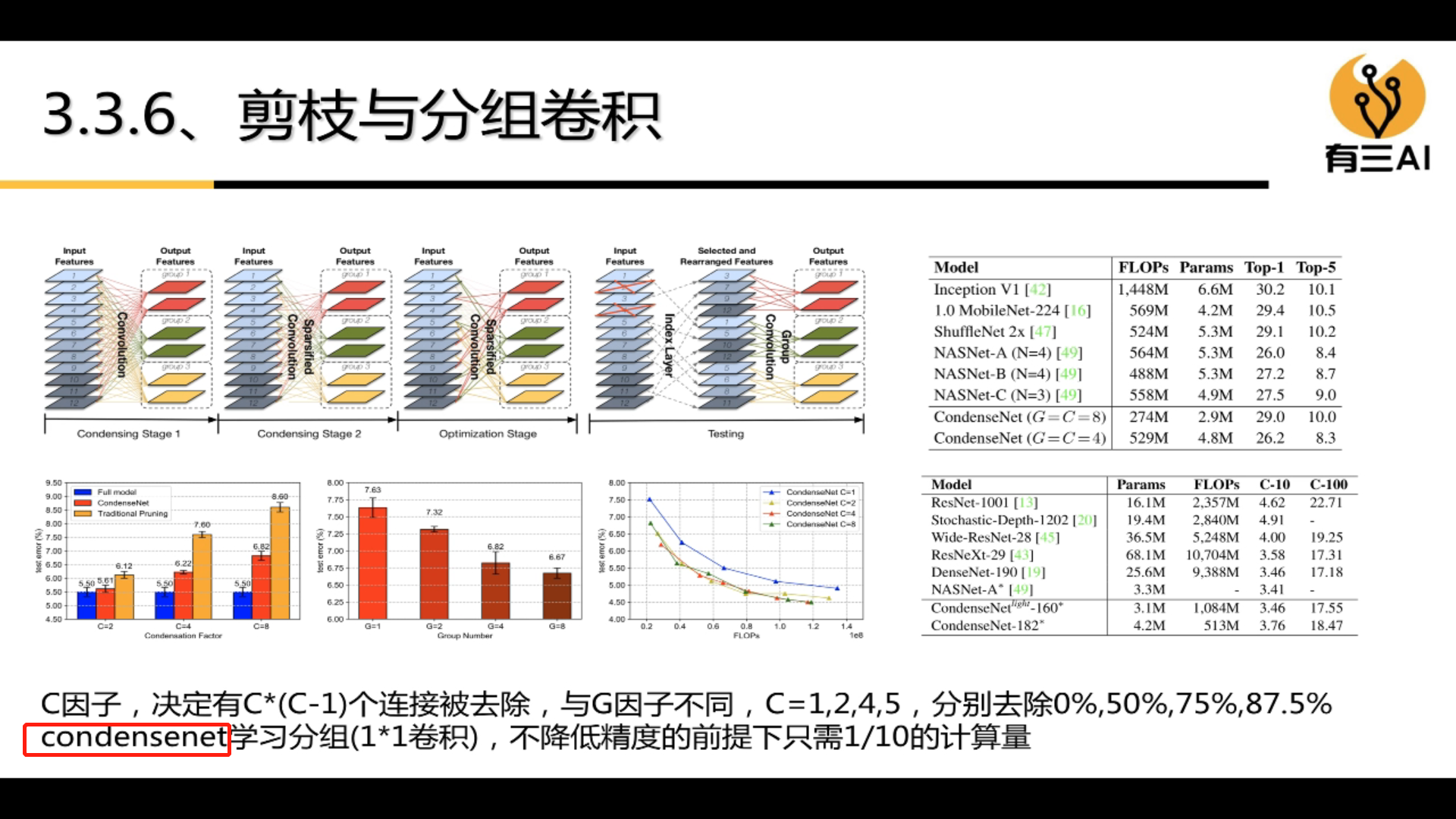
4.3 Group convolution
Grouped convolution can greatly reduce the amount of computation.
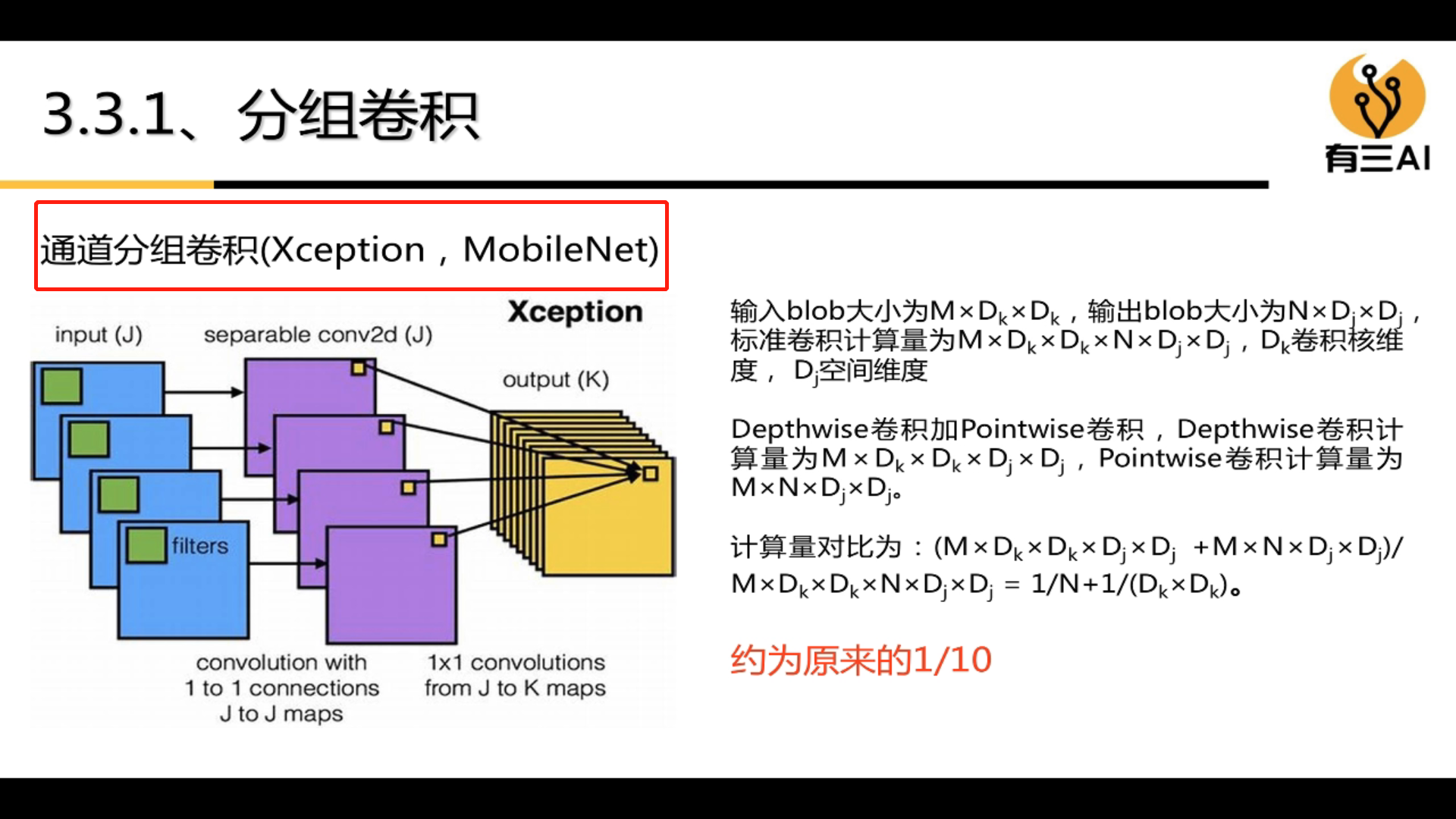
The types of group convolution are:
(1)
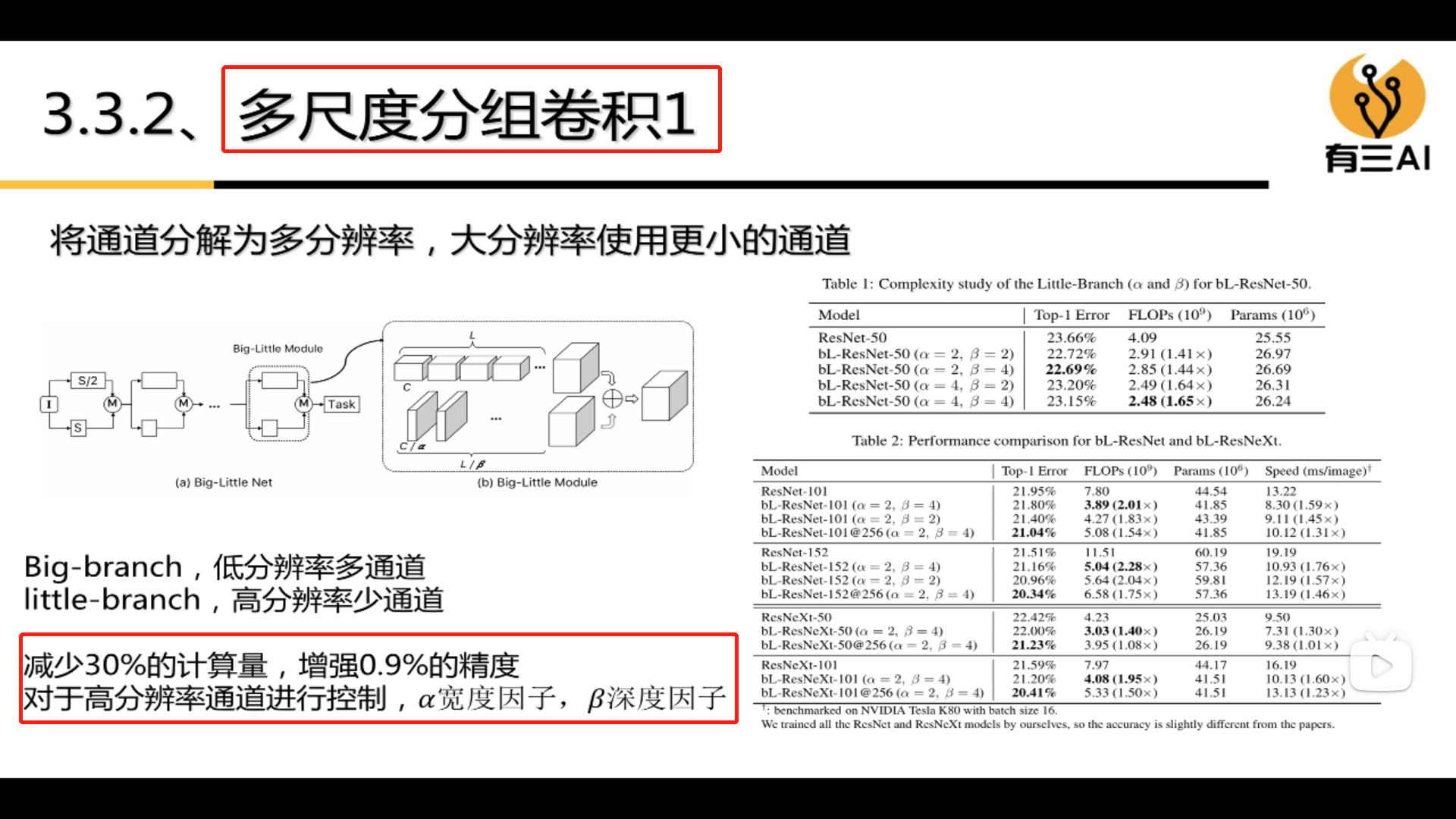
(2)
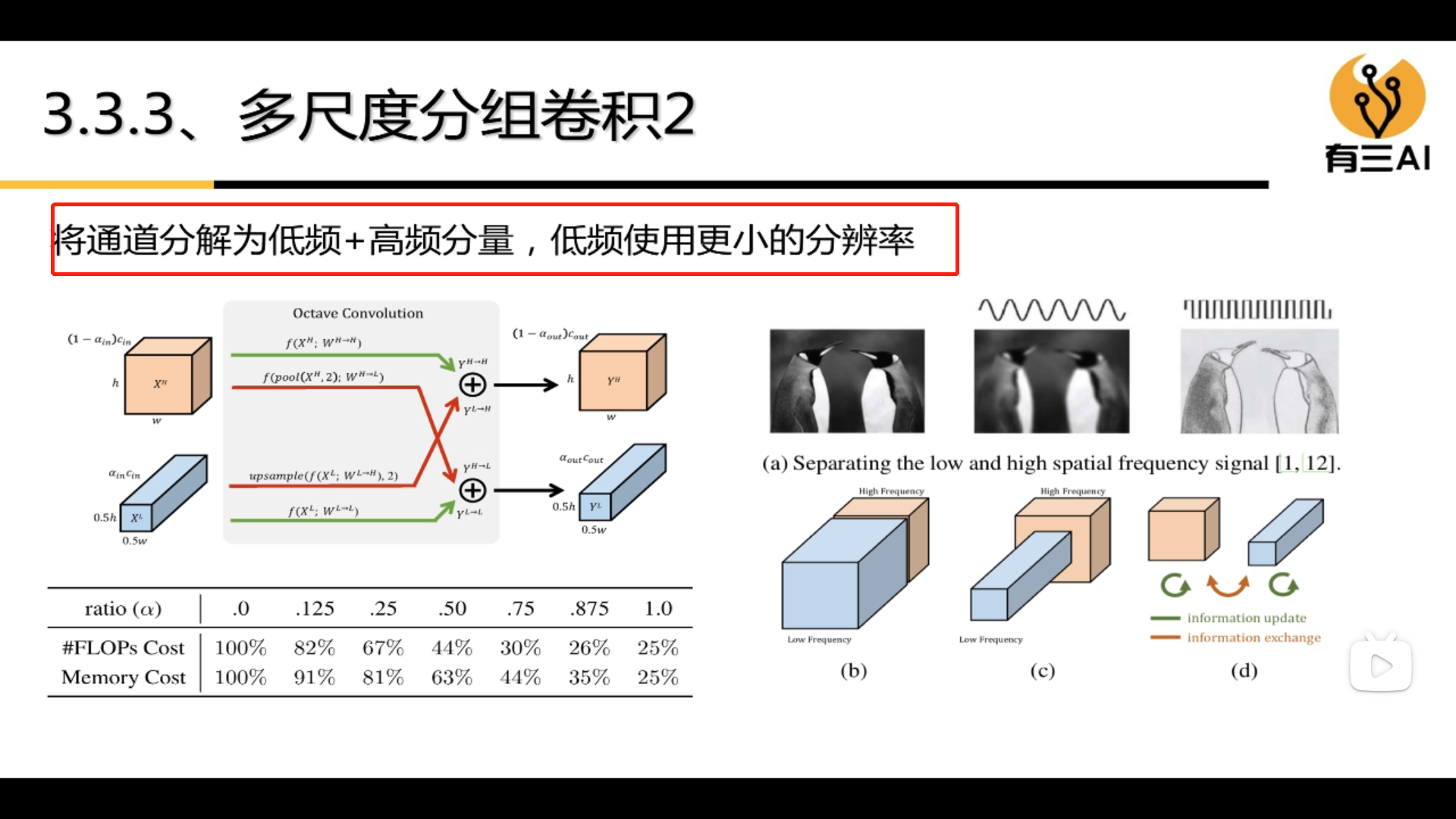
(3)
(4)
(5)
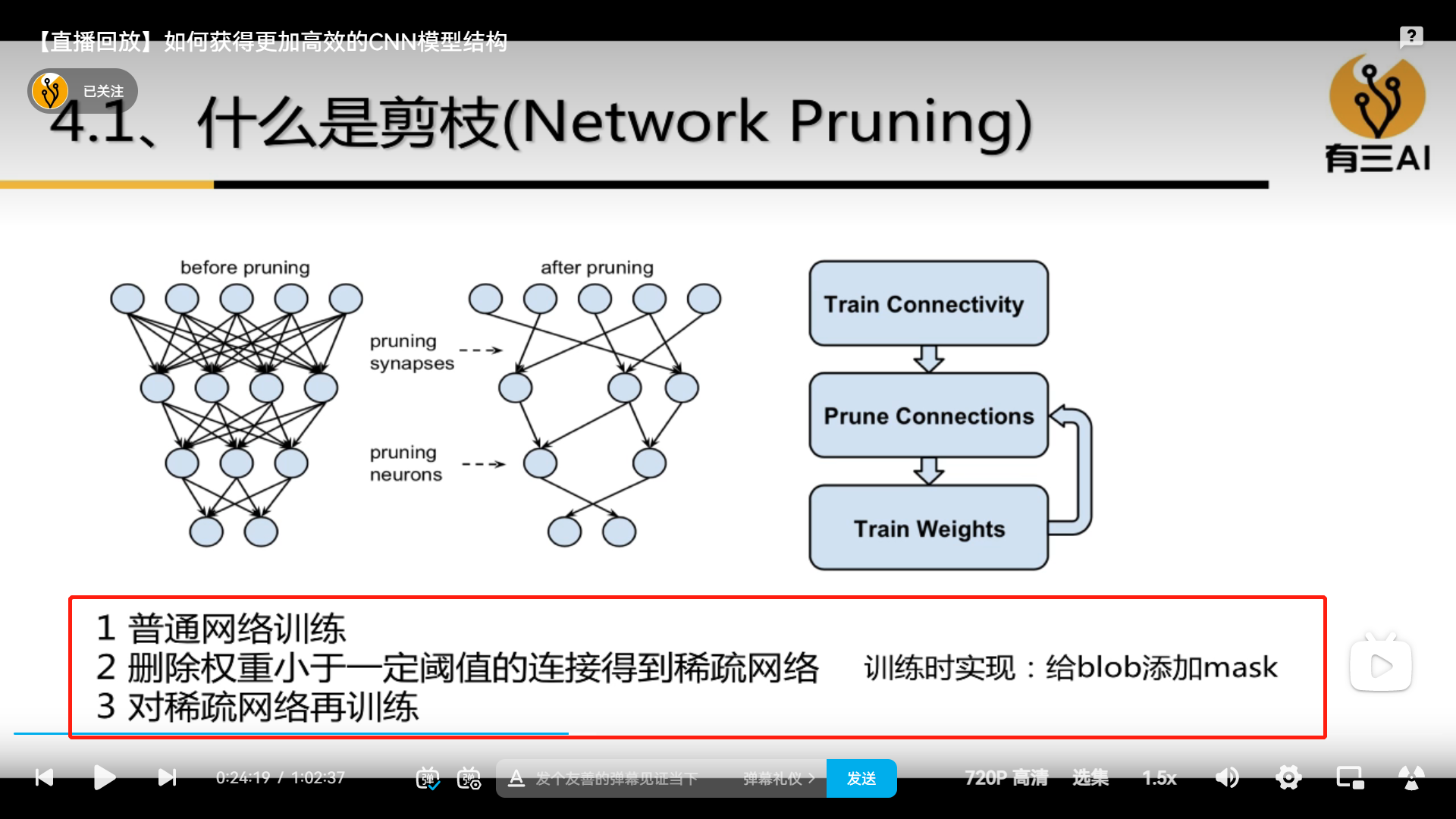
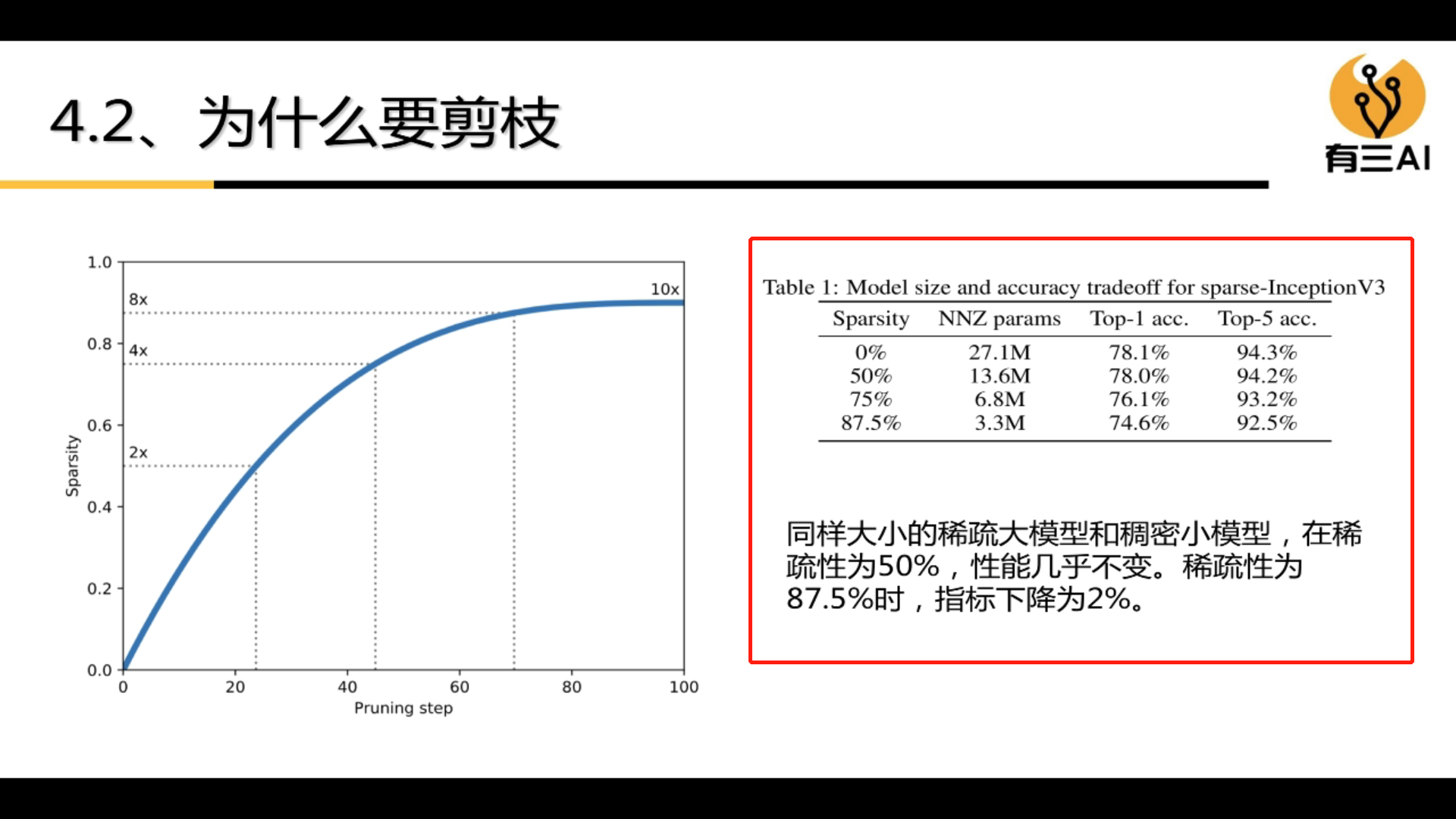
4.4 Pruning

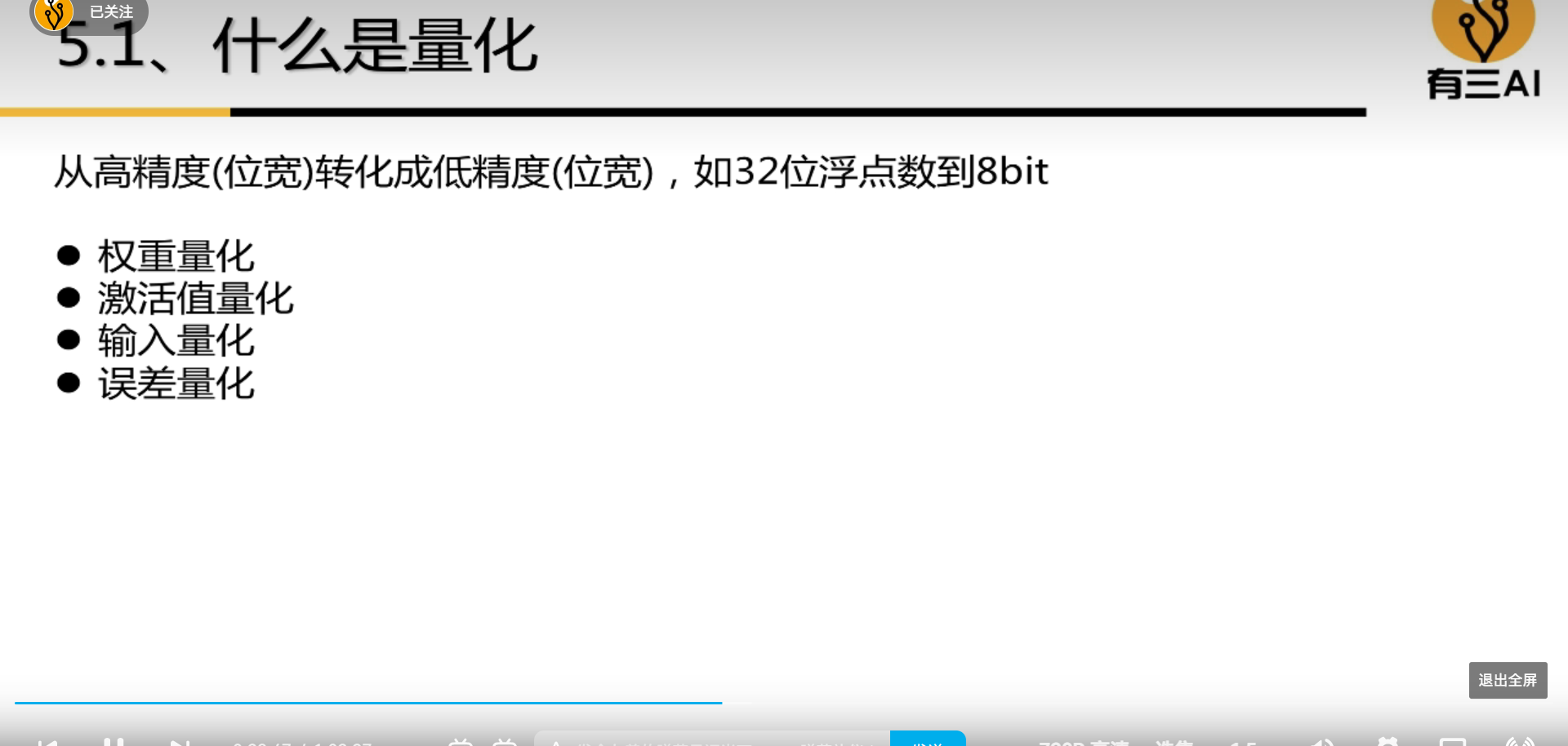
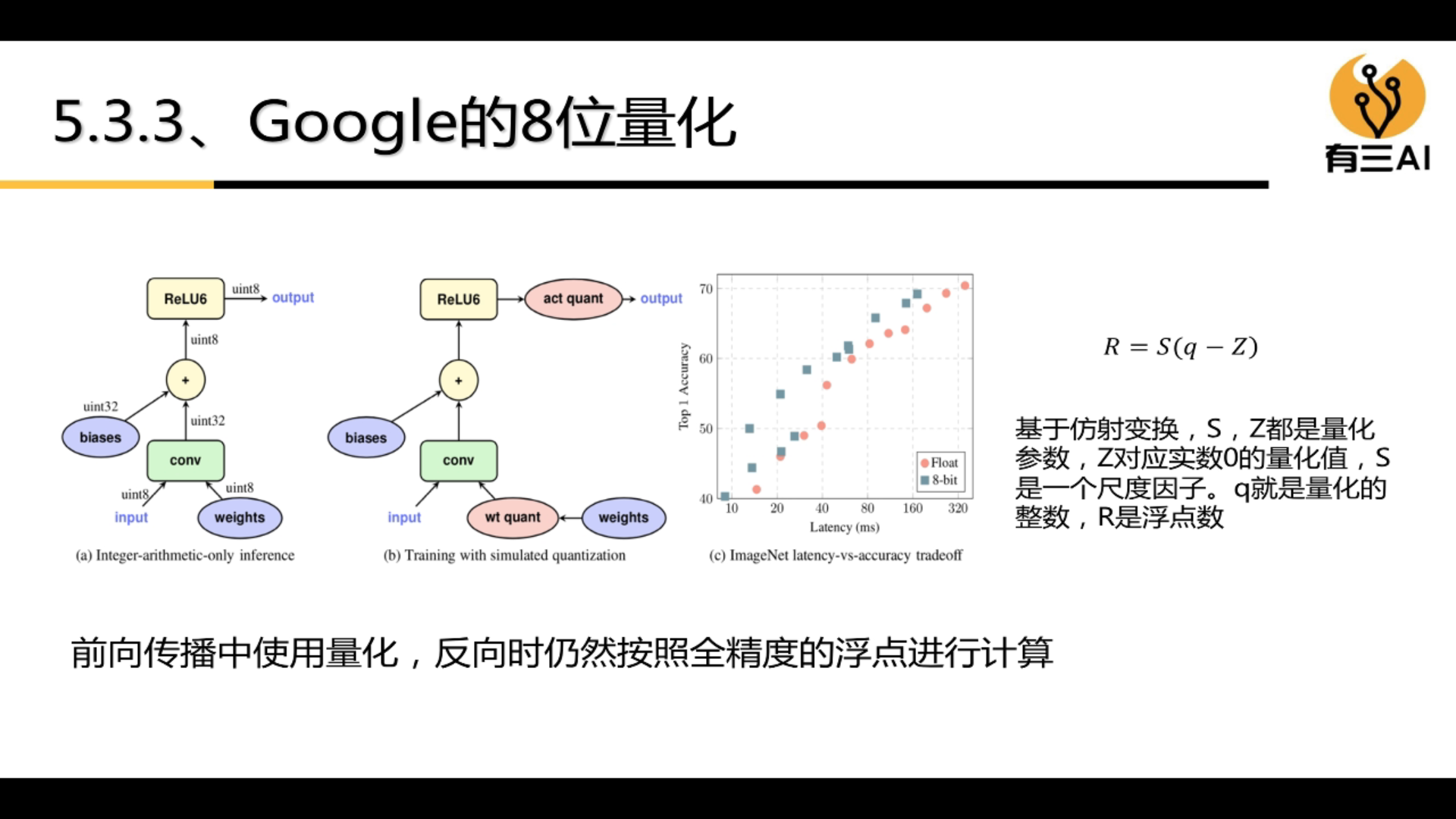
4.5 Quantization



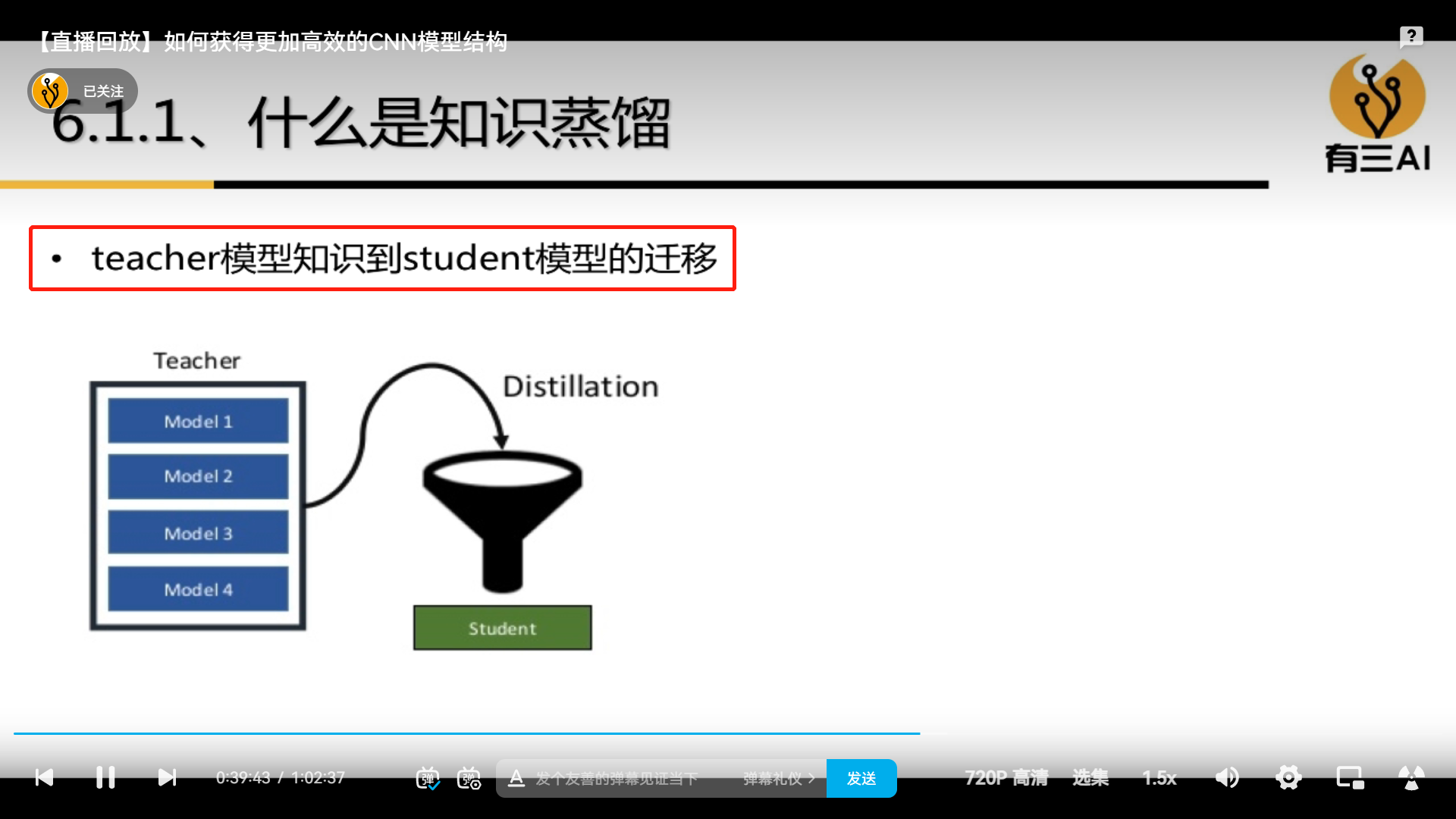
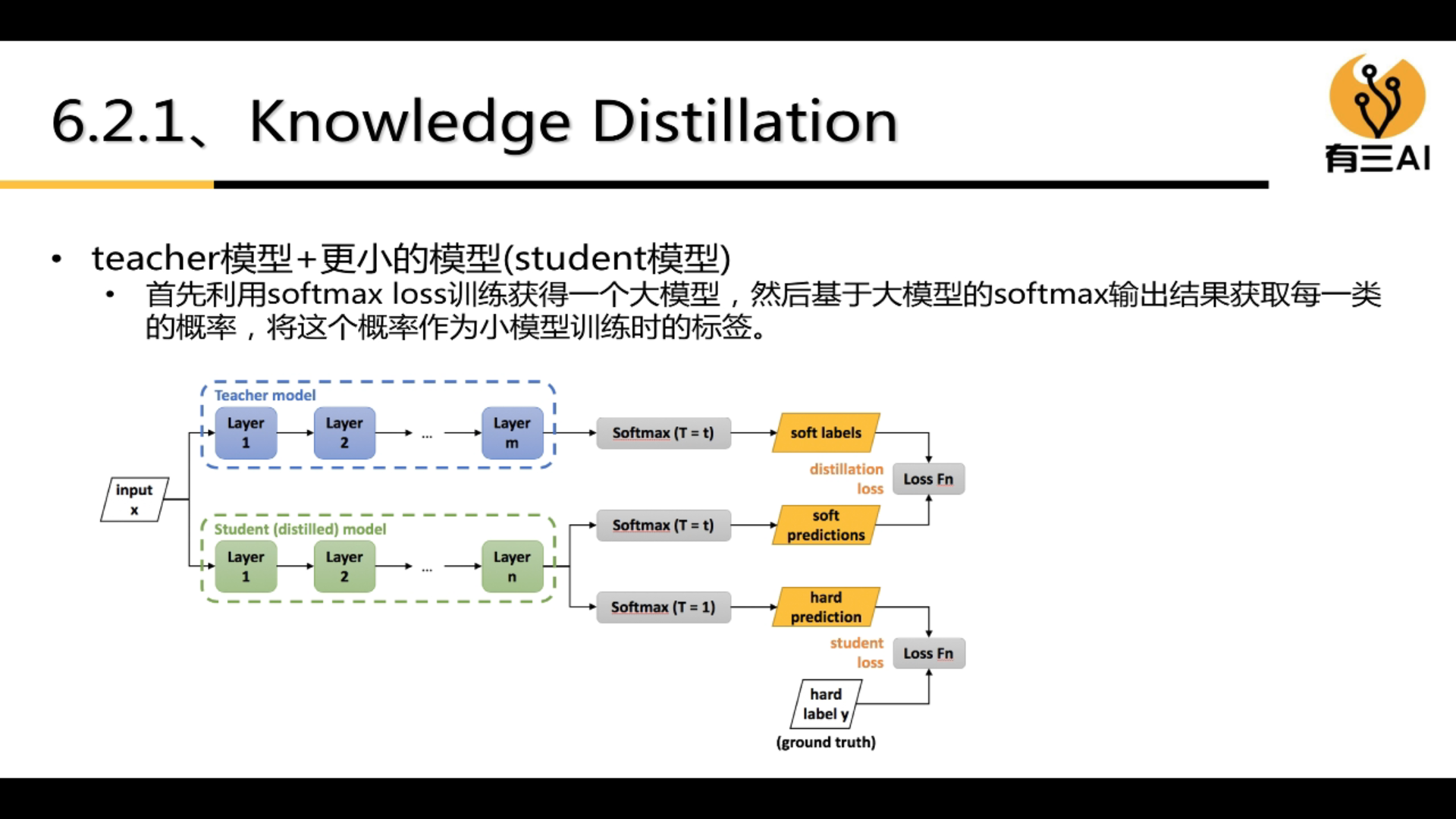
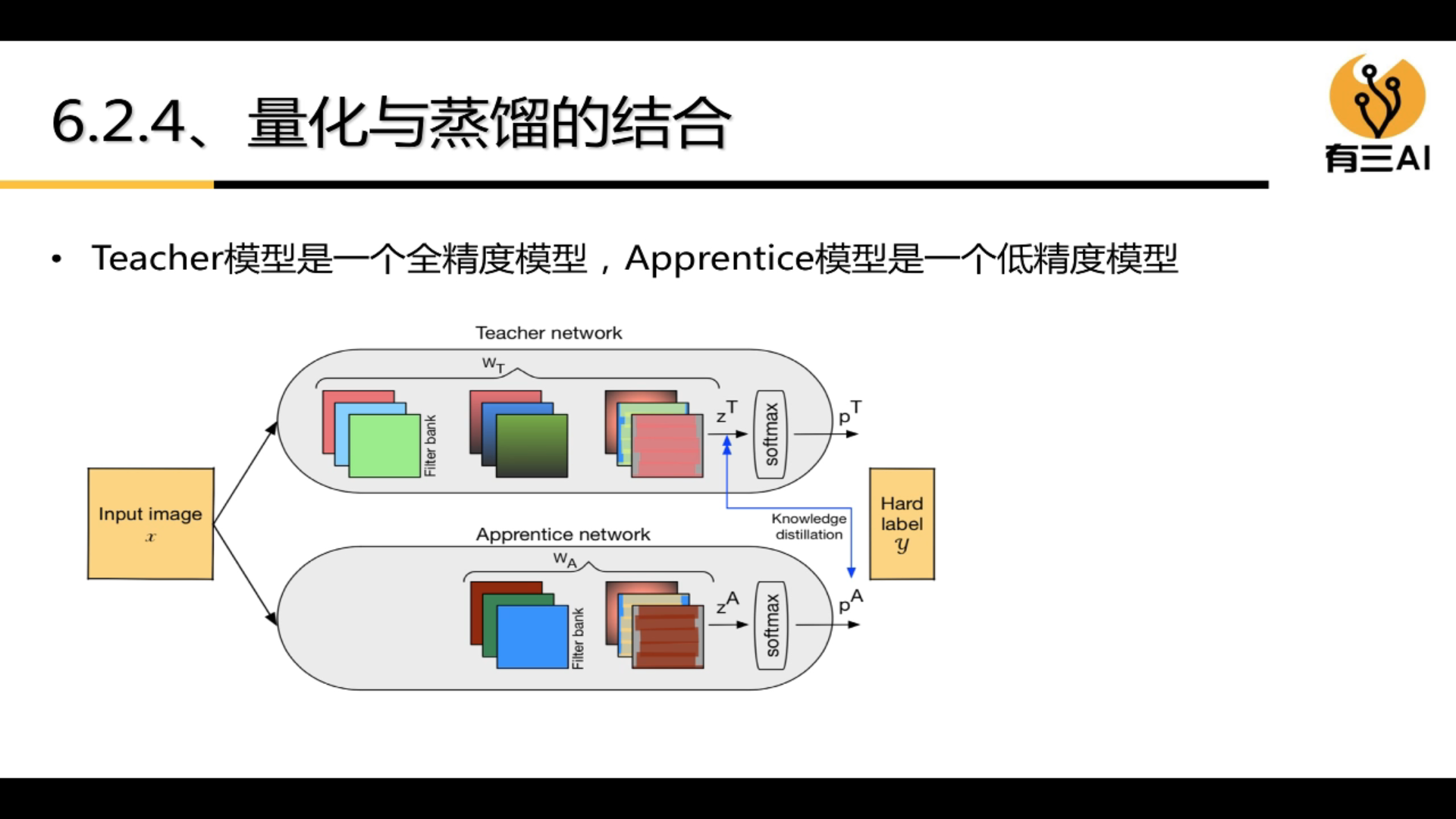
4.6 Knowledge Distillation