1 R&D background
1.1 What problem do we want to solve?
The three types of operational demands that we expect the platform to cover are as follows:
(1) Response to emergencies: including but not limited to external force majeure, hotspot events on the Internet, liquidation and other emergencies, in personalized traffic scenarios such as search & recommendation, relying solely on the learning of algorithm models to adapt, Time is not accepted by the business side.
(2) Lack of data for new products/newcomers: In terms of supporting new products and retaining newcomers, it is difficult to recall new products, low personalization scores lead to low rankings and cannot be exposed, and the lack of portraits of newcomers will also affect the recommendation effect. Therefore, when frequent adjustments are required for the weighting of new products and targeted delivery of newcomers, manual changes are often required.
(3) Experimental/exploratory projects on the platform: such as category price band distribution control, some exploratory and tentative experiments, it is necessary to push designated products with small traffic for experiments, and after obtaining certain results and experience, optimize and promote them, etc. . It needs to be analyzed from multiple angles such as circled products, circled people, AB experiments, and data market; frequent adjustments to strategy play also require iterative upgrades on the technical side.
1.2 Why make a platform?
Without building a platform, we also quickly implement business side appeals such as high UE product weighting and price force product support. The method is generally by marking the products in the recall engine, and identifying a targeted delivery of a request for composite services in the upstream system In the rule, the marked items are weighted. At the same time, the buried point data is counted, and the diff between the product experiment group and the benchmark control group is evaluated to ensure that the support meets business expectations. The reason why platformization invests a lot of R&D costs in the initial stage is mainly for the following two points:
(1) R&D & time cost: The addition of each strategy needs to be iterated from product marking to engine, online link to the identification of specified traffic, algorithm weighting, real-time data feedback, offline data report, etc., which requires BI, Engine dump, recall layer, forecasting algorithm, real-time data warehouse and other teams invest a total of at least 10-12 man-days of R&D resources, and at the same time, PMO, team leaders and PMs, project joint debugging, test resources, online change CR, etc. Indirect inputs also add up.
(2) Multi-scenario problem: Repeated construction in different scenarios will also bring about an increase in cost. I won’t go into details here. What’s more, the same users have their own distribution rules in different scenarios. How to conduct AB experiments and statistical analysis of data in a unified way also exists There are certain problems. Part of the product weighting will inevitably crowd out the natural exposure traffic of other products, and this part of the crowded traffic is our operating cost. How to evaluate the ROI of each scene, and how to stop investing in a single scene when the effect is not satisfactory, and how to resume the resource investment of the scene are also issues we need to face.
1.3 How do we do it?
The above three types of problems can actually be unified and abstracted as follows: users can choose a product set at any time, and carry out certain support (weighting, maintenance, etc.) volume, exposure percentage, scaling up, etc.). We generally divide the system that realizes this capability into five modules, as shown in the following figure:
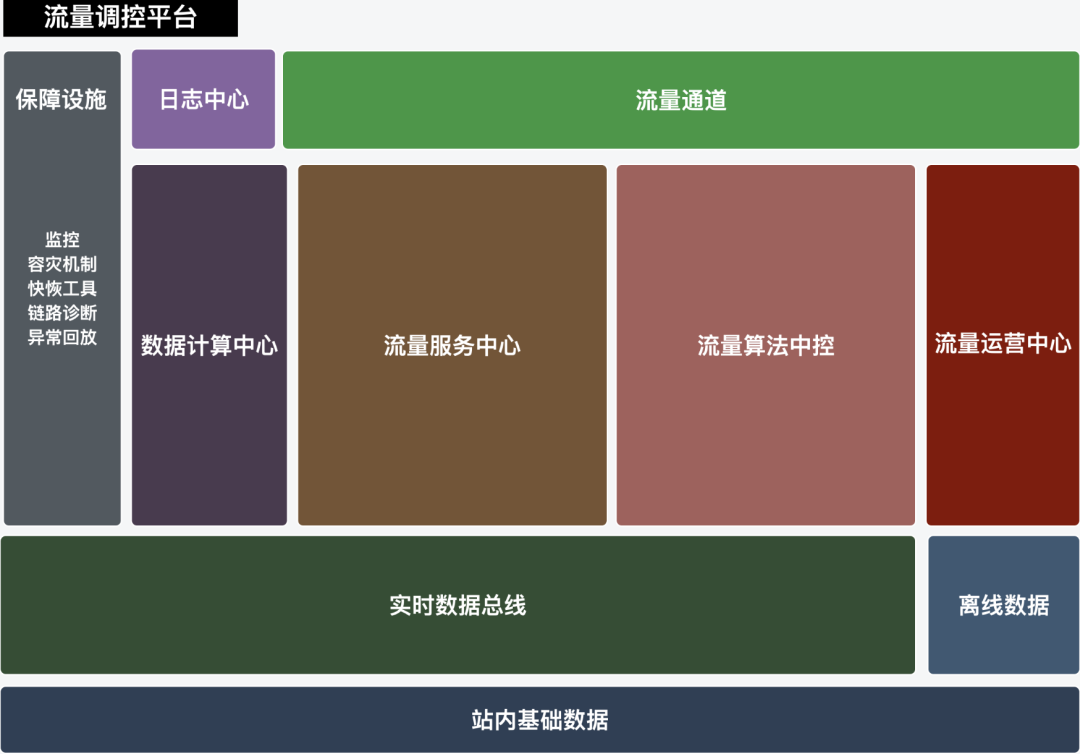
1) Traffic operation center: Support operation students to freely configure strategies, change product sets, adjust delivery conditions, complete approval process, check reports and other operational operations; new additions and changes to strategies no longer require scheduling and R&D cycles Long wait.
(2) Traffic service center: It is used to match the traffic rules configured by the operation with online requests, and is also responsible for the central control of the series algorithm, the regulation of product recall, the report of buried points, the disaster recovery and current limit, etc., and is the hub of link regulation.
(3) Data Computing Center: It is mainly responsible for two parts. One is to update the offline data such as the product collection configured by operation, the basic data in the station, and the completion of product increment targets to the search engine. The other part is the minute-level statistical real-time data of the online link, the real-time accumulated data of the sub-experiment, sub-strategy, and sub-scenario of the product are synchronized to the algorithm central control to make decisions, and the basis for the search engine to update the recall filter conditions in real time.
(4) Central control of traffic algorithm: The products recalled by the control link need to be adjusted in real time by the central control according to the product characteristics, user portraits, estimated scores, target achievement progress and growth rate and other factors. Responsibilities such as smooth control and excessive fusing are the brains of the entire regulatory system.
(5) Support facilities: infrastructure built around the perspectives of stability, problem location efficiency, etc., will not be described in detail.
The technical links are expanded below.
2Technical link
2.1 Business Architecture:
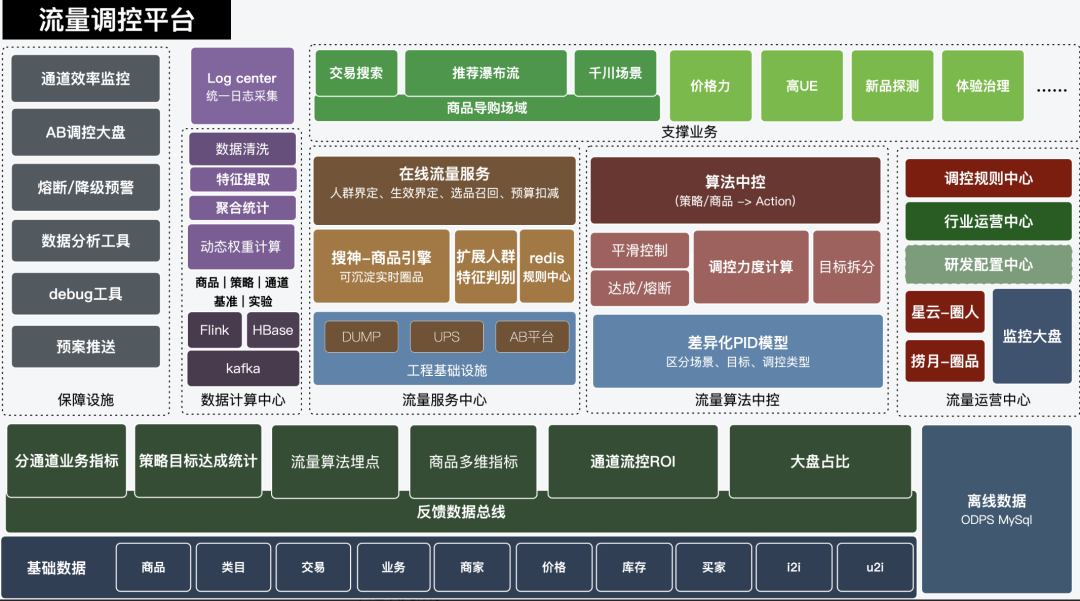
After the research and development work in the 2022 Q4 quarter, the current scenario has covered the transaction search and some recommendation scenarios. The online support business strategy includes: new product quantity maintenance, high UE product weighting, repeated exposure/lower exposure ratio of novelty-hunting products and other business demands. At the same time, in order to access more personalized traffic channels, the regulation has also completed the construction of general capabilities such as non-text personalized multi-channel recall. The basic construction of the general report, approval process, and change history comparison of the operation background has been basically completed.
2.2 Engineering link:
- The blue box is the new 2022 Q4 construction, and the white box is the completed function in Q3
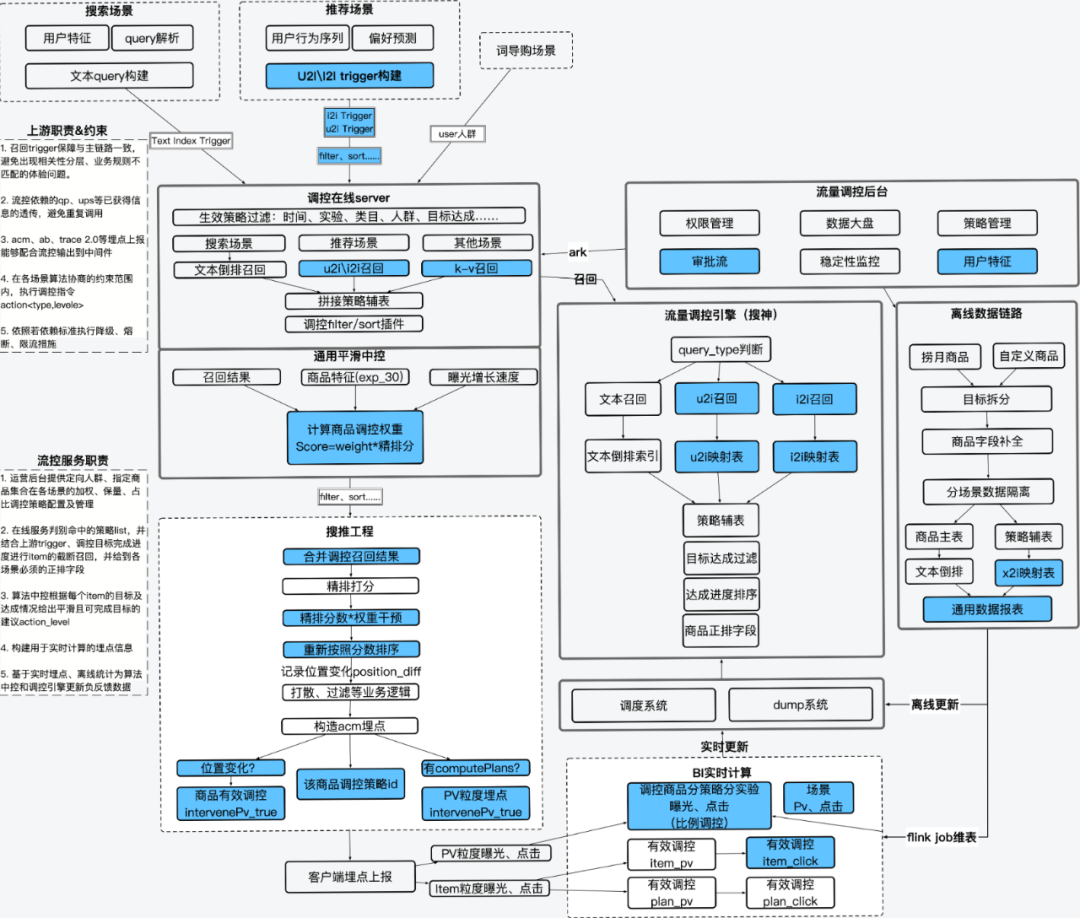
When the offline data is updated to the engine at the hourly level, the request of the entire system enters from the upper left scene, carrying the text query or user characteristic trigger to the control server, and the control server will push the plan according to the requestInfo and the flow control operation background (for some Request to regulate and abstract a product set into a plan) list for matching. Construct a query based on the effective policy ID to recall the regulation engine. The recall results are combined with the algorithm's central control output <action, weight> (control method, strength), and are sent to the upstream to reorder the fine sorting results. At the same time, the information that needs upstream assistance to bury points is also placed on the disk simultaneously. After the real-time data warehouse collects buried points, it calculates according to the corresponding rules, and feeds back to the central control and real-time update control engine.
The internal responsibilities of the control server are as follows:
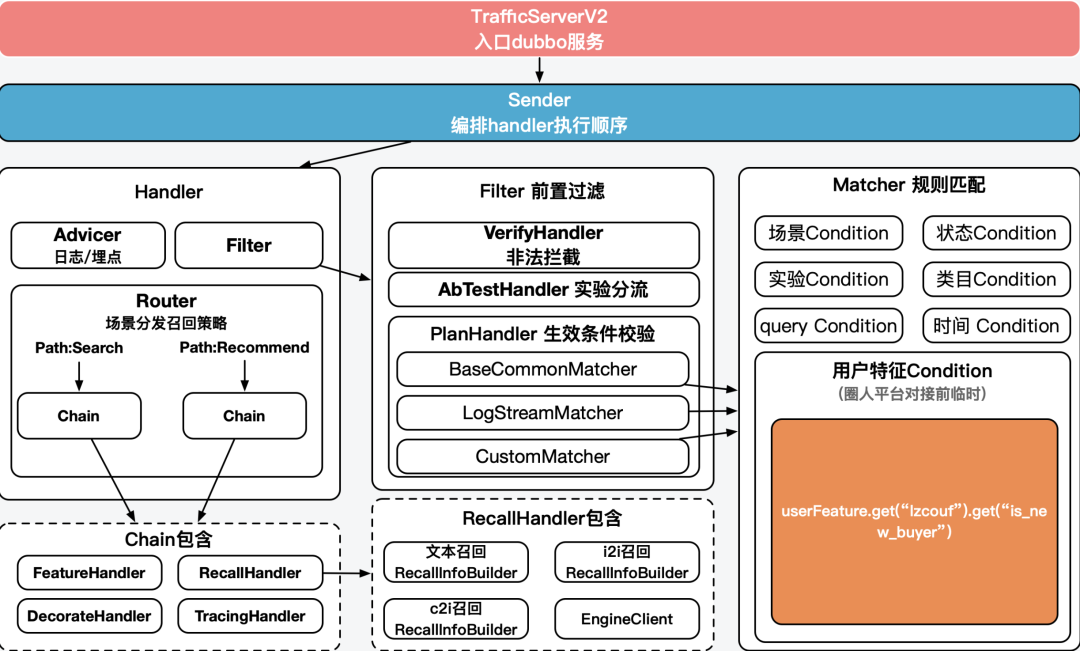
Each handler is responsible for effective policy identification, recall policy distribution, exit mechanism, AB bucketing, real-time calculation of buried point structure, call algorithm central control, etc. The detailed implementation will not be expanded.
Based on the flow control recall logic of Soshen's self-developed engine:
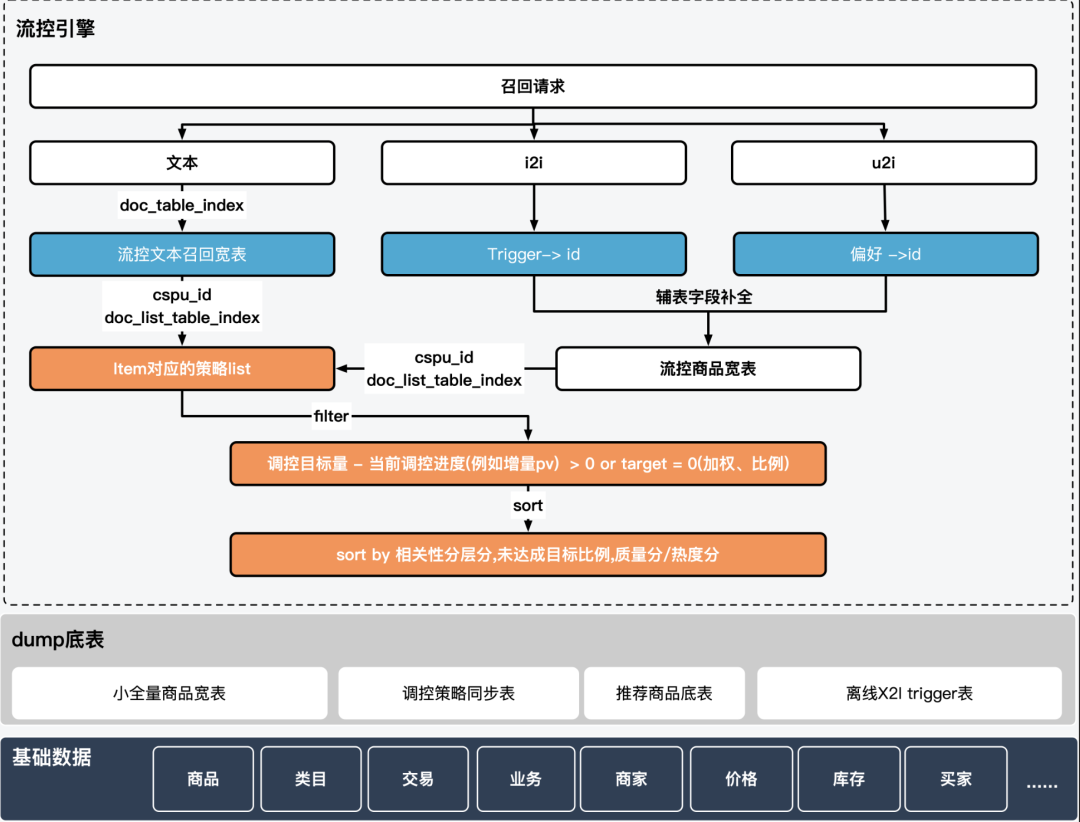
The flow control engine currently supports text recall for search scenarios and X2i recall for recommendation. The mapping relationship between trigger -> product and the underlying data are consistent with natural recall. The candidate set is also a proper subset of the recall candidate set for search and push scenarios. Ensure that correlation stratification, true and false exposure filtering and other logics are aligned with each scene; category prediction, product number identification multiplex QP results, recommended triggers and user behavior sequences are also multiplexed upstream results, so separate regulation and recall links do not Can cause experience problems.
In addition, for the control of new products of the type of quantity preservation, we have customized the goal-achievement filter filter and the sort plug-in with a priority lower than relevance with the help of the expansion capability of the Sogos self-developed engine, which has alleviated the rare problem of new product recalls to a certain extent.
2.3 Other modules:
2.3.1 Real-time data:
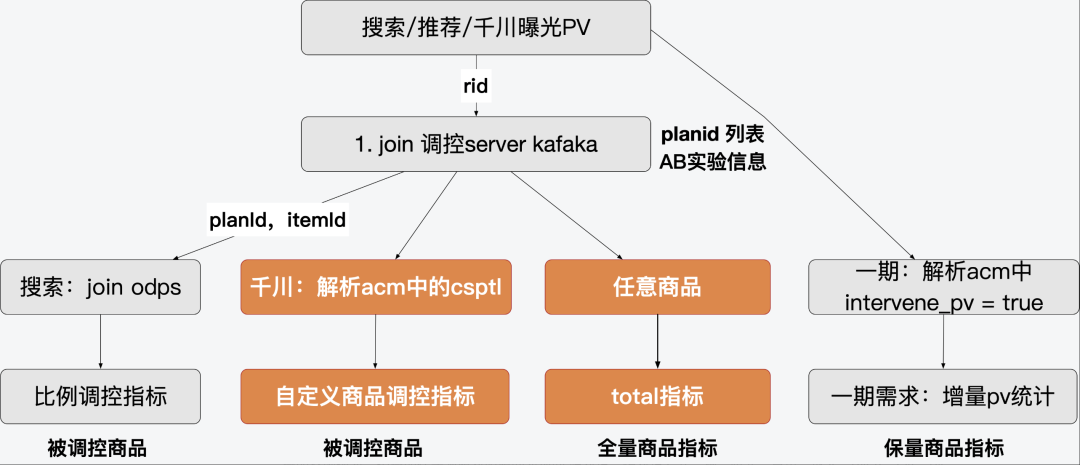
The real-time data relied on by the smooth control of the central control, the fuse mechanism for achieving the goal, and the engine sort/filter plug-in are as follows:

The above indicators are calculated by the real-time data warehouse team based on the buried points reported by the client, the server log kafaka, and the odps dimension table. The calculation logic is simplified as follows:
2.3.2 Performance data:
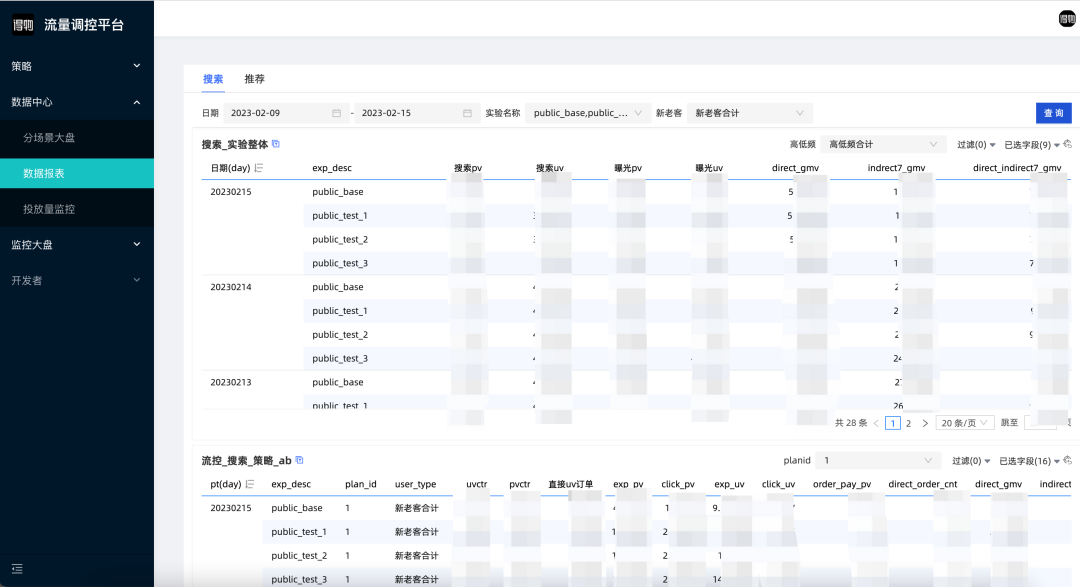
Commodity efficiency report refers to the absolute value and relative value difference between the performance of the commodity in the experimental group and the control group, covering indicators such as exposure, click, transaction, qvctr, cvr, pv value, etc. The impact of a control strategy (plan) on this batch of products needs to be limited to products that are regulated, and the traffic must also be an efficiency report under conditions such as specified scenarios, crowd characteristics, experiments, categories, etc. This part is not difficult understand.
AB experiment splitting, the control server undertakes requests from various sources, and unifies the two-layer orthogonal AB, the logic of the control layered experimental group and the control group is as follows:
a. Independent experiment
i. Control group: Independent experimental control group (fixed)
ii. Experimental group: Experimental group configured by strategy (plan), determined according to the configuration of each strategy
b. Public experiment (a traffic group in the public experiment may superimpose multiple experiments, and check the impact on the product dimension according to different commodity ranges):
i. Control group: Public experimental control group (fixed)
ii. Experimental group: Experimental group configured by strategy (plan), determined according to the configuration of each strategy
Above, the BI team can give an example of a support strategy (plan) for some new products, and the observable reports are similar to the following:
The real-time + offline data link ultimately serves the regulation engine and algorithm central control
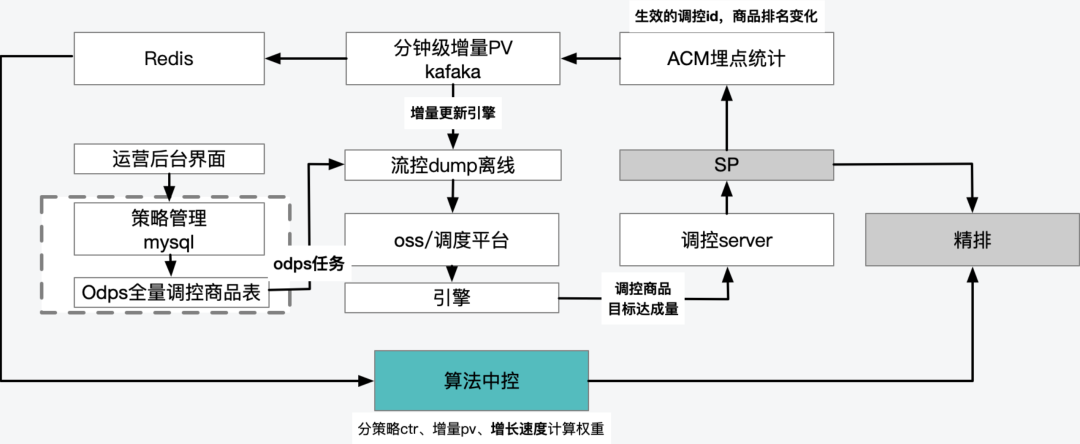
2.3.3 Algorithm central control:
In response to the demand for quantitative goals, the PID calculation logic performed by the algorithm central control based on real-time feedback data is as follows:
- Sorting based on score=rs weight + correlation score or score=rs pctr/median(pctr)* weight + correlation score weight = 1+ pid_score, weight range [0.1,10]
pid_score=(current target exposure - current cumulative exposure Amount)/Current Target Exposure KI
Current Target Exposure = Planning Target Current Time Exposure Ratio
There are slight differences in the ratio control requirements for exposure ratio types:
Support when the proportion is lower than the target:
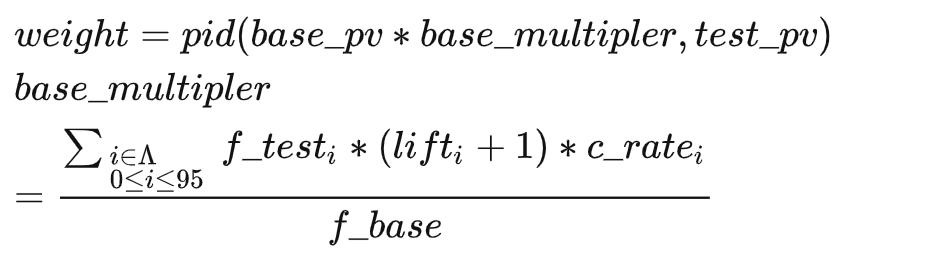
Suppress when the proportion is higher than the target:
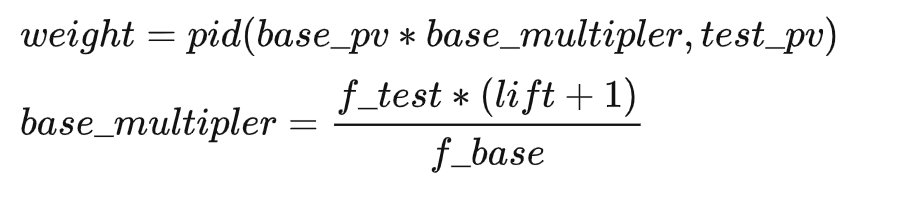
3 noteworthy
3.1 Learn from the independent recall link of the advertising system
Compared with the previous work experience and the research results of other platforms, the independent recall link similar to the advertising system has the following characteristics:
(1) In fields such as new product support, relying on the logic of natural recall and then judging whether it is a regulated product, there is no particularly good solution to the problem of "difficult to recall". The problems of violent intervention, upper limit of white list and poor correlation have not been solved. In the independent recall link, we naturally limit the pot to only regulated products. If the correlation layer meets the requirements, the position of regulated products will not be occupied by non-regulated products. At the same time, relying on the completion rate logic customized by Soshen's self-developed engine can also prevent the problem that some regulated products crowd out the flow of other regulated products. Online can actually guarantee that 99% of new products can obtain effective incremental exposure brought about by regulation (exposure position is advanced), and at the same time, the achievement rate of the overall maintenance target can also meet business requirements
(2) It is more accurate in judging the incremental exposure: Naturally, there is no recall, and only the concept of recall can help us judge. No matter whether the pit position of this product changes, only the recall of the link is bound to increase. amount of exposure. It is helpful to continue to promote the background system based on operating group budget management
(3) Compared with post-filtering, pre-filtering can give other products more opportunities within a limited amount of recall
(4) There are certain flaws in the negative direction. The number of independent link recalls is smaller than the overall recall number, which will lead to a decline in the suppression effect. This point is more professional in that the anti-cheating platform and the blacklist of the risk control system directly connect to the commodity pot.
3.2 Unified AB experiment across scenarios
Each scene and each service is connected to the AB platform independently, and they are isolated from each other, and the hash rules are also customized. In the follow-up, we expect that in the joint regulation of multiple scenarios, the allocation ratio of incremental targets can be dynamically and automatically optimally allocated, and the ROI indicators of each scenario can be recovered at the same time. Students who are familiar with the report can see that even with the AB data after going to Wansan high customer list, there are still differences in the indicators in the case of multiple experiments in the same experimental group. The independent and unified regulation and orthogonal layering can ensure that whether it is the same user who is searched or recommended, the hit experiment or strategy is the same, and the joint regulation can be based on this hierarchical data as a reference.
4 follow-up directions

(1) Improve platform capabilities:
a; Basic capacity building, including the access of Yueyue components, opening up the collection information of circle products, realizing one-stop maintenance of circle products and circle product rules; the access of crowd rule platform, simplifying the identification process of online service FeatureCondition
b: Regulate the ease of use of the platform operation center and the construction of user experience, and polish the product from the aspects of data analysis, cross-platform information connection, small tools, removal of redundant operations and early warning notifications, from "usable" to "good" long-term goal of using
c: Add a configuration center in the background, ark configuration visualization, reduce the cost of changing complex json; later realize functions such as one-click downgrade; add debug tools to test whether the online system recall and weight meet expectations, and improve the efficiency of debugging and online problem location
d: The abnormal circuit breaker mechanism is perfect, the abnormal notification can be communicated to the owner and the person in charge of operation, and the effect of abnormal loss can be evaluated.
(2) Capacity building for non-commodity regulation:
a: Shading words & search discovery words, search box drop-down recommendation words and other word shopping guide scene coverage, combined with query direct access, can support business support for specified goods through more low-cost scenarios
b: Community content is the core scene of Dewu, and the product tags and dynamic detail page product cards in the current community content have established a good mechanism for content-guided transactions, whether it is for the content regulation of product tags, or for the author to push pending There is space and value for exploration in directions such as the reminder of supporting products, and we look forward to exploring the landing scenarios of community & transaction joint regulation in the future.
(3) Support scene expansion:
a: Support more recommendation scenarios, and expect to conduct experiments on brand landing pages, category tabs and other scenarios in the future, and explore the optimal ROI solutions for different types of product collections in different scenarios.
b: Exploration of cross-scenario joint control capabilities, cross-scenario target allocation, product quality estimation and evaluation, and cross-scenario core index alignment; help business parties get results in the exploration of refined human-goods matching.