In this article, I list the most commonly used NLP libraries today and give a brief description of them. They each have advantages and disadvantages in different use cases, so they can all serve as a wealth of knowledge for a good data scientist specializing in NLP.
Descriptions of each library are pulled from their GitHub repositories.
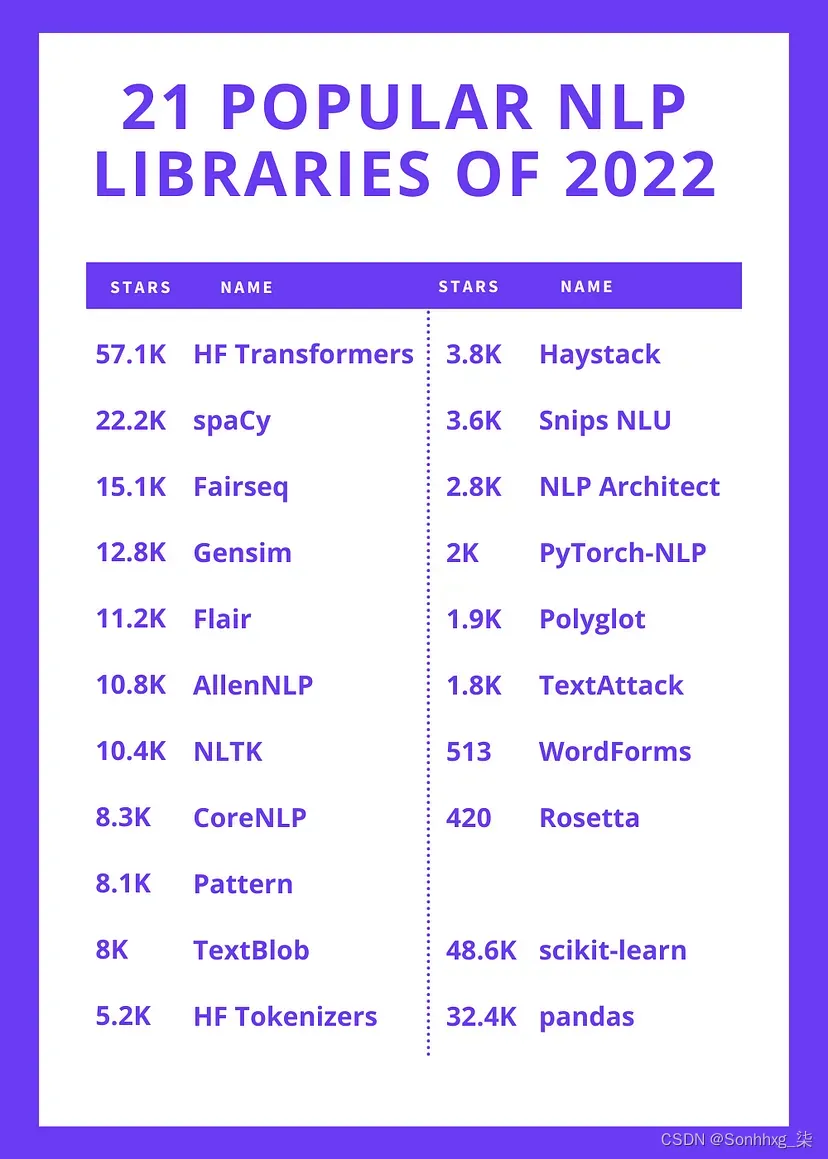
Top NLP Libraries
Here's a list of the top repositories, sorted by GitHub stars.
Hugging Face Transformers
57.1k GitHub stars.
Transformers provides thousands of pre-trained models to perform tasks of different modalities, such as text, vision, and audio. These models can be applied to text (text classification, information extraction, question answering, summarization, translation, text generation, over 100 languages), images (image classification, object detection and segmentation) and audio (speech recognition and audio classification). Transformer Models can also perform tasks combining multiple modalities, such as tabular question answering, optical character recognition, information extraction from scanned documents, video classification, and visual question answering.
Currently updated.
spaCy
22.2k GitHub stars.
spaCy is a free and open source library for natural language processing in Python and Cython. It is built on the latest research and designed from the ground up for use in production environments. spaCy comes with pre-trained pipelines that currently support tokenization and training in over 60 languages. It features state-of-the-art speed and neural network models for tagging, parsing, named entity recognition, text classification, multi-task learning with pretrained transformers like BERT, and a production-ready training system and simple model packaging, deployment, and workflow manage. spaCy is commercial open source software, released under the MIT license.
Currently updated.
Fairseq
15.1k GitHub stars.
Fairseq is a sequence modeling toolkit that allows researchers and developers to train custom models for translation, summarization, language modeling, and other text generation tasks. It provides reference implementations for various sequence modeling papers.
Currently updated.
Name
13.9k GitHub stars
Jina 是一个神经搜索框架,可在几分钟内构建最先进且可扩展的神经搜索应用程序。Jina 允许构建用于索引、查询、理解多/跨模态数据(例如视频、图像、文本、音频、源代码、PDF)的解决方案。
目前已更新。
Gensim
12.8k GitHub 星数。
Gensim 是一个用于主题建模、文档索引和大型语料库相似性检索的 Python 库。目标受众是 NLP 和信息检索 (IR) 社区。Gensim 具有流行算法的高效多核实现,例如在线潜在语义分析 (LSA/LSI/SVD)、潜在狄利克雷分配 (LDA)、随机投影 (RP)、分层狄利克雷过程 (HDP) 或 word2vec 深度学习。
目前已更新。
Flair
11.2k GitHub 星数。
Flair 是一个强大的 NLP 库。Flair 允许您将最先进的 NLP 模型应用于您的文本,例如命名实体识别 (NER)、词性标注 (PoS)、对生物医学数据的特殊支持、语义消歧和分类,支持对于数量迅速增加的语言。Flair 具有简单的界面,允许您使用和组合不同的单词和文档嵌入,包括 Flair 嵌入、BERT 嵌入和 ELMo 嵌入。该框架直接构建在 PyTorch 上,可以轻松训练您自己的模型并使用 Flair 嵌入和类试验新方法。
目前已更新。
AllenNLP
10.8k GitHub 星数。
一个基于 PyTorch 构建的 Apache 2.0 NLP 研究库,用于在各种语言任务上开发最先进的深度学习模型。它提供了广泛的现有模型实现集合,这些模型实现具有良好的文档记录和高标准设计,使它们成为进一步研究的重要基础。AllenNLP 提供了一种高级配置语言来实现 NLP 中的许多常见方法,例如 transformer 实验、多任务训练、视觉+语言任务、公平性和可解释性。这允许纯粹通过配置对广泛的任务进行实验,因此您可以专注于研究中的重要问题。
目前已更新。
NLTK
10.4k GitHub 星数
NLTK——自然语言工具包——是一套支持自然语言处理研究和开发的开源 Python 模块、数据集和教程。它为超过 50 个语料库和词汇资源(如 WordNet)提供易于使用的界面,以及一套用于分类、标记化、词干提取、标记、解析和语义推理的文本处理库,以及工业级 NLP 库的包装器。
目前已更新。
CoreNLP
8.3k GitHub 星数。
Stanford CoreNLP 提供了一套用 Java 编写的自然语言分析工具。它可以采用原始人类语言文本输入并给出单词的基本形式、词性、是否是公司名称、人名等,规范化和解释日期、时间和数字数量,标记句子结构在短语或单词依存关系方面,并指出哪些名词短语指代相同的实体。
目前已更新。
Pattern
8.1k GitHub 星数。
Pattern 是 Python 的 Web 挖掘模块。它具有用于数据挖掘的工具:Web 服务(Google、Twitter、Wikipedia)、Web 爬虫和 HTML DOM 解析器。它有几个自然语言处理模型:词性标注器、n-gram 搜索、情感分析和 WordNet。它实现了机器学习模型:向量空间模型、聚类、分类(KNN、SVM、感知器)。模式也可用于网络分析:图形中心性和可视化。
2 年前的最后一次更新。
TextBlob
8k GitHub 星数。
TextBlob 是一个用于处理文本数据的 Python 库。它提供了一个简单的 API,用于深入研究常见的自然语言处理任务,例如词性标记、名词短语提取、情感分析、分类、翻译等。TextBlob 站在 NLTK 和 Pattern 的巨人肩膀上,可以很好地与两者配合使用。
目前已更新。
Hugging Face Tokenizers
5.2k GitHub 星数。
这个库提供了当今最常用的分词器的实现,重点是性能和多功能性。
目前已更新。
Haystack
3.8k GitHub 星数。
Haystack 是一个端到端的框架,使您能够为不同的搜索用例构建功能强大且可用于生产的管道。无论您想执行问答还是语义文档搜索,您都可以使用 Haystack 中最先进的 NLP 模型来提供独特的搜索体验,并允许您的用户使用自然语言进行查询。Haystack 以模块化方式构建,因此您可以结合其他开源项目(如 Huggingface 的 Transformers、Elasticsearch 或 Milvus)的最佳技术。
目前已更新。
Snips NLU
3600 颗 GitHub 星。
Snips NLU 是一个 Python 库,它允许从用自然语言编写的句子中提取结构化信息。每当用户使用自然语言与 AI 交互时,他们的话语都需要被翻译成机器可读的含义描述。Snips NLU 的 NLU(自然语言理解)引擎首先检测用户的意图(又名意图),然后提取查询的参数(称为槽)。
2 年前的最后一次更新。
NLP Architect
2.8k GitHub 星数。
NLP Architect 是一个开源 Python 库,用于探索最先进的深度学习拓扑和技术,以优化自然语言处理和自然语言理解神经网络。它是一个设计灵活、易于扩展的库,允许在应用程序中轻松快速地集成 NLP 模型,并展示优化的模型。
目前已更新。
PyTorch-NLP
2k GitHub 星数。
PyTorch-NLP 是 PyTorch NLP 的基本实用程序库。它扩展了 PyTorch,为您提供基本的文本数据处理功能。
目前已更新。
Polyglot
1.9k GitHub 星。
Polyglot 是一种支持海量多语言应用的自然语言管道:Tokenization(165 种语言)、语言检测(196 种语言)、命名实体识别(40 种语言)、词性标注(16 种语言)、情感分析(136 种语言)、Word嵌入(137 种语言)、形态分析(135 种语言)和音译(69 种语言)。
最后一次更新是 3 年前。
TextAttack
1.8k GitHub 星数。
TextAttack 是一个用于 NLP 中的对抗性攻击、数据增强和模型训练的 Python 框架。
目前已更新。
Word Forms
513 个 GitHub 星数。
单词形式可以准确地生成英语单词的所有可能形式。它可以共轭动词和复数单数名词。它可以连接词的不同部分,例如名词到形容词、形容词到副词、名词到动词等。
最后更新 1 年前。
Rosetta
420 个 GitHub 星。
Rosetta 是一个基于 TensorFlow 的隐私保护框架。它集成了主流的隐私保护计算技术,包括密码学、联邦学习和可信执行环境。Rosetta 重用了 TensorFlow 的 API,并允许将传统的 TensorFlow 代码转换为隐私保护方式,只需进行最少的更改。
目前已更新。
Honorable Mentions
我在这里列出了一些数据科学库,它们并非特定于 NLP,但在 NLP 项目中经常使用。
scikit-learn
48.6k GitHub 星数。
Scikit-learn(也称为 sklearn)是 Python 编程语言的免费软件机器学习库。它具有各种分类、回归和聚类算法,包括支持向量机、随机森林、梯度提升、k-means 和 DBSCAN,旨在与 Python 数值和科学库 NumPy 和 SciPy 互操作。
目前已更新。
pandas
32.4 GitHub 星数。
pandas 是一个 Python 包,它提供快速、灵活和富有表现力的数据结构,旨在使处理“关系”或“标记”数据既简单又直观。它的目标是成为用 Python 进行实用的、真实世界的数据分析的基本高级构建块。此外,它还有更广泛的目标,即成为任何语言中最强大、最灵活的开源数据分析/操作工具。
目前已更新。