Table of contents
2. Introduction to Gmmaping algorithm
2.1 Past and Present of Gmapping
2.1.1 Reduce the number of particles
2.1.2 Mitigation of Particle Dissipation and Diversity Loss
2.2 Advantages and disadvantages of Gmapping algorithm
3. Installation and compilation of Gmapping algorithm source code
3.1 Install dependent libraries
3.2 Download Gmapping source code
6. The meaning of each entry in the Gmapping algorithm launch file
7. Appendix: Popular Explanation of Gmapping Common Terms
7.2 Particle degradation, resampling, and particle diversity
1 Introduction
This article is mainly to record my process of reproducing the Gmapping algorithm in the process of learning SLAM, including various problems I encountered, so that I can review it later, and I hope it can be helpful to everyone. Here, I also thank many seniors of CSDN The article gave me a lot of help, thank you here.
2. Introduction to Gmmaping algorithm
Gmapping is a SLAM algorithm based on 2D lidar using RBPF algorithm to complete two-dimensional grid map construction . In the introduction, in order to be friendly to novices, I will not talk too much theoretical knowledge and derivation of related mathematical formulas , try to use popular and easy The words you understand will help you understand. If subsequent readers need to study relevant theoretical knowledge, you can read Gmapping's papers and the explanations of many great gods on the Internet.
2.1 Past and Present of Gmapping
The complete SLAM problem is the simultaneous estimation of robot pose and map given sensor data. However, the reality is that if you need to get an accurate pose, you need to match it with the map, and if you need to get a good map, you need to have an accurate pose to do it. Obviously, this is a contradictory problem.
In order to solve this problem, the FastSLAM algorithm takes a unique approach and uses the RBPF method to decompose the SLAM algorithm into two problems: one is the problem of robot positioning, and the other is the problem of map construction with known robot poses .
The robot trajectory estimation problem in the FastSLAM algorithm uses a particle filter method (map first, then locate) . Due to the use of particle filtering, each particle contains the trajectory of the robot and the corresponding environment map . Two problems will inevitably arise . The first problem is that when the environment is large or the error of the robot odometer is large, more particles are needed to get a better estimate, which will cause a memory explosion ; the second problem is that particle filtering cannot avoid the use of resampling to ensure that The effectiveness of the current particles, however, the problems caused by resampling are particle dissipation and loss of particle diversity. Due to the emergence of these two problems , the FastSLAM algorithm is theoretically feasible, but it cannot be realized in practice. Gmapping proposes two targeted solutions to the above problems : reducing the number of particles and alleviating particle dissipation.
2.1.1 Reduce the number of particles
Purpose: To greatly alleviate the memory explosion by reducing the number of particles.
Method 1: Directly adopt the method of maximum likelihood estimation, according to the predicted distribution of the particle’s pose and the matching degree of the map, scan and match the optimal pose parameters of the particles, and use the pose parameters directly as new particles pose.
Method 2: The Gmapping algorithm limits the Poisson distribution to a narrow effective area through the observation (scen) of the latest frame. Then sample the Poisson distribution in the normal.
2.1.2 Mitigation of Particle Dissipation and Diversity Loss
The Gmapping algorithm uses the particle filter algorithm to estimate the trajectory of the mobile robot, and the process of particle resampling is inevitable. As the number of samples increases, all particles are copied from one particle, so the diversity of particles is completely lost. Therefore, the problem cannot be solved, and we can only go from the idea of reducing resampling . Gmapping proposes a selective resampling method, which determines whether to perform particle resampling according to the degree of dispersion of all particle self-generated weights (that is, the weight variance) .
Summary: Gmapping is based on the FastSLAM algorithm to turn the RBPF method into reality.
2.2 Advantages and disadvantages of Gmapping algorithm
Advantages: Gmapping can build indoor environment maps in real time, with less calculation in small scenes. And the map accuracy is high, and the requirements for the laser radar scanning frequency are low
Disadvantages: As the environment increases, the amount of memory and calculation required to construct the map will become huge, so Gmapping is not suitable for large-scale scene composition.
3. Installation and compilation of Gmapping algorithm source code
Ubuntu18.04 is used here
3.1 Install dependent libraries
sudo apt-get install libsdl1.2-dev
sudo apt install libsdl-image1.2-dev
3.2 Download Gmapping source code
3.2.1 Method 1:
sudo apt-get install ros-melodic-gmappingNote: 1. In the above command, if your Ubuntu version is 16.04, you need to replace melodic with kinetic, and the corresponding Ubuntu version of melodic is 18.04.
2. Method 1 Although there is no problem with the installation during operation, sometimes there will be problems during the map building test, and the source code installation needs to be re-installed.
3.2.2 Method two:
Step 1: Create a file in the main directory, name it gmapping (this name is optional), and then create a src compilation space under the gmapping folder 
Open the terminal in the src directory, create a workspace, and enter
catkin_init_workspaceStep 2: Download the Gmapping source code
git clone https://github.com/ros-perception/openslam_gmapping
git clone https://github.com/ros-perception/slam_gmapping.git
git clone https://github.com/ros-planning/navigation.git
git clone https://github.com/ros/geometry2.git
git clone https://github.com/ros-planning/navigation_msgs.git
After downloading, the effect is as shown in the figure
Note: Sometimes the download fails, as shown in the figure below. This is generally a problem with the network speed. You can repeat the download command several times.

Step 3: Compile, return to the gmapping directory, open the terminal , and enter
catkin_make_isolated
Note: The reason for not compiling with catkin_make is that the function packages between the downloaded source codes may have interdependence problems, and errors will be reported when compiling at the same time.
4. Download the dataset
Baidu network disk self-fetching
链接:https://pan.baidu.com/s/1o5n10WIBEhYXUUuioURKXQ?pwd=28jn
提取码:28jn
After downloading, put the dataset in the gmapping directory, as shown in the figure
5. Dataset testing
Step 1: Open a terminal and enter
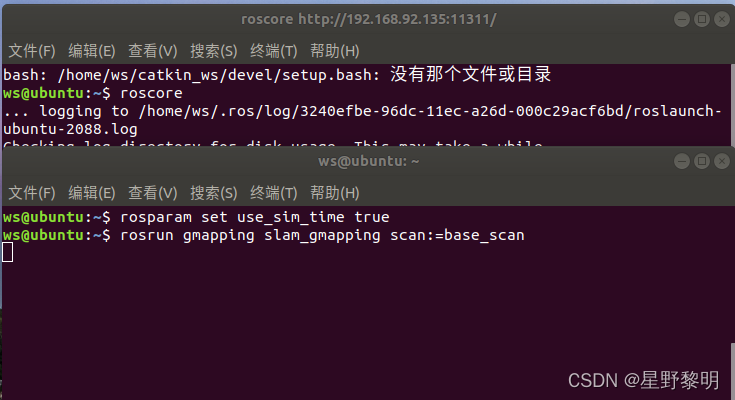
roscoreStep 2: Open another terminal and enter
rosparam set use_sim_time true//设置ROS 启用重放数据中的时间而非本机时间,因为在默认情况下ros使用Ubuntu系统的时间,即当前时间。由于我们重放的文件是历史文件,它记录的是历史时间,所以需要设置ROS 从现在起开始启用模拟时间。
rosrun gmapping slam_gmapping scan:=base_scan //启动gmapping,并监听scan_base topic 发来消息。
Note: 1. The second line of command ~$ rosrun gmapping slam_gmapping scan:=base_scen The gmapping in the file is not the name of the folder you created, but the name of the function package of the gmapping source code you downloaded. Even if the folder you created is called "abc (or whatever)", the second line is written like this.
2. The second line of command is used to monitor topic news. You have not run the relevant topic yet, so it is normal that there is no news under this command. Only when you run the feature pack will there be information displayed under this.
Step 3 : Create a terminal under the dataset file , enter
rosbag play basic_localization_stage.bag //这个basic_localization_stage.bag是我的数据包里的,如果是别的数据包,只需要将名字即basic_localization_stage.bag换了即可。
Note: This command corresponds to the data set of the link I sent. If it is another data set, remember to change the name of the subsequent data package
Step 4: Open a new terminal and open the visual interface
Note: There is no image in the visual interface at this time, and parameters need to be adjusted
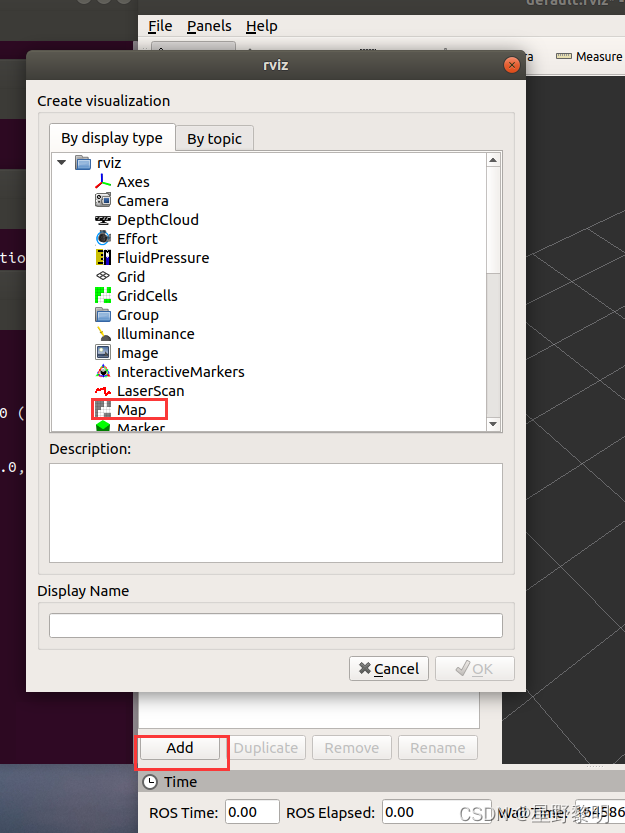
Step 5: Adjust the parameters, open Add in the lower left corner of the visualization interface, select map, open the map option, select /map in the Topic option, and the image will come out.
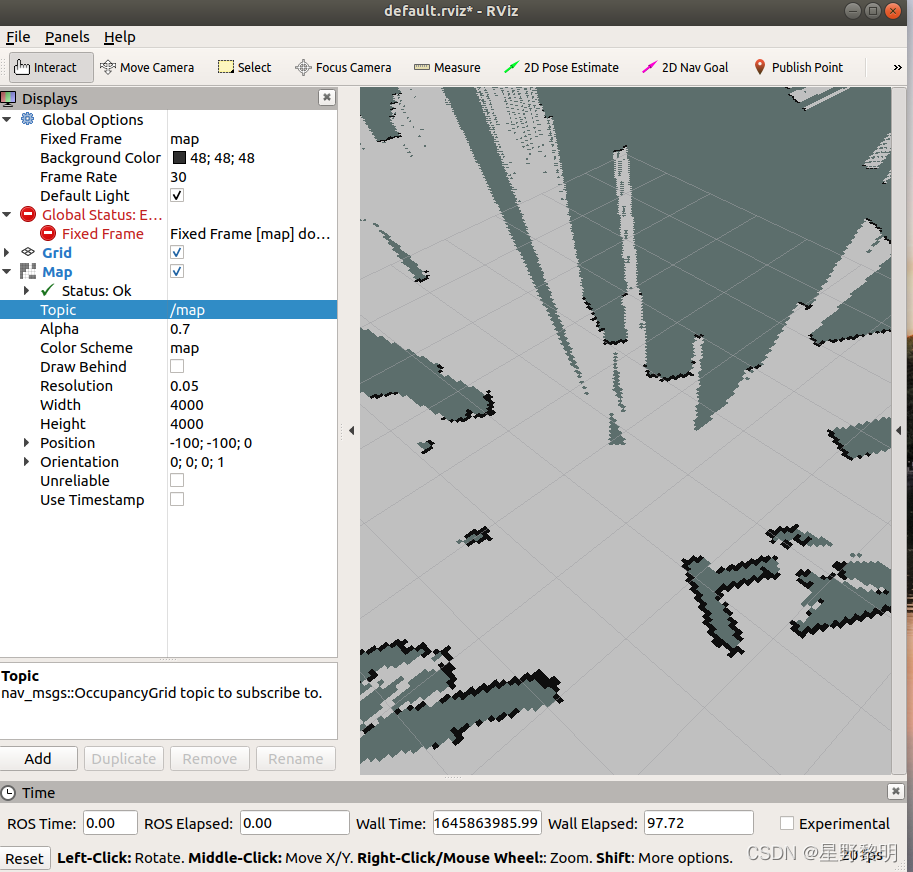
Doing this step is regarded as a successful reproduction of the Gmapping algorithm.
6. The meaning of each entry in the Gmapping algorithm launch file
In this regard, there have been many great gods on CSDN who have introduced it in detail, so I will not make mistakes. Here I recommend an article that I have read, which is very comprehensive.
https://blog.csdn.net/qq_42037180/article/details/100819788
7. Appendix: Popular Explanation of Gmapping Common Terms
In the process of learning, I found that many people are somewhat vague about the concepts of particle filtering, resampling, particle diversity, and particle degradation. For this reason, I found in the articles I read that someone made an analogy for this, which is easy to understand. Share it with everyone here.
7.1 Particle Filtering
从知乎上看到的一个有趣的解释。
简单来说,在机器人定位问题中,我们想要估计机器人的位置和姿态。
最初,我们完全不知道机器人在哪,那就索性假设机器人以同等的概
率出现在地图上的任意一个位置。比如,假如地图是整个中国,那么
机器人就等可能地出现在北京、上海、广州、哈尔滨等地。于是我们
就可以用一个粒子代表一个机器人可能出现的位置。现在,机器人说
话了,它说它感觉特别冷,雪落在了它洁白的脖子上。于是,我当即
排除了长江以南的城市,南方怎么可能下雪呢!机器人系上围脖,继
续向前走。没走几步,它又抱怨道,“今天空气质量可真不怎么样,
我的双目都要失明了。”显然,它是遇到了雾霾天,这种天气在北方某
帝都倒是挺常见的。它点亮了IR主动光探测,雾霾天上路多加小心总
没有错。转眼间,机器人来到一个庞大的建筑物面前,这里人声鼎沸,
还有遍地的商贩在叫卖着不知什么东西。它借助自身廉价的激光雷达
小心翼翼地在人群中穿梭。突然,它若有所思地停了下来,似乎发现
了一个美丽的秘密。虽然外面寒冬凌冽,这里却如春天般富有生机,
到处洋溢着绿色的海洋。人声此起彼伏,它依稀听出了五个字,“国
安是冠军”...在上面的例子中,“我”作为机器人的大脑,根据机器人
的感受,可以得出如下推理。机器人发现下雪了,那么可以确定机器
人应该在北方的某个城市。接着,机器人遇到了雾霾天,那么说明该
城市的空气质量很差,这就进一步把搜索范围缩小到了某几个重点空
气污染城市。最后,机器人听到的五个字“国安是冠军”,彻底让我锁
定了它所在的城市——“北京”。这就是一个形象的粒子滤波案例。机器
人不断地通过运动、观测的方式,获取周围环境信息,逐步降低自身
位置的不确定度,最终得到准确的定位结果。Attach the article link: https://www.guyuehome.com/14967
7.2 Particle degradation, resampling, and particle diversity
这里回答一下什么是粒子退化:
粒子退化主要指正确的粒子被丢弃和粒子多样性减小,而频繁重采样则加剧了
正确的粒子被丢弃的可能性和粒子多样性减小速率。这里先涉及一下重采样的知识,我
们知道在执行重采样之前会计算每个粒子数的权重,有时会因为环境相似度高或是由于
噪声的影响会使接近正确状态的粒子数权重较小而错误状态的粒子的权重反而会大。重
采样是依据粒子权重来重新采粒子的,这样正确的粒子就很有可能会被丢弃,频繁的重
采样更加剧了正确但权重较小粒子被丢弃的可能性。这也就是粒子退化原因之一。
另外一个原因就是频繁重采样导致的粒子多样性减小速率加大,什么是粒子多
样性呢?就是粒子的不同,就像最开始有十个粒子,如果发生重采样后其中有两个粒子
共享一个父亲,而上一次十个粒子中,其中一个粒子没有孩子则说明粒子多样性减小。
再通俗点解释,比如兔子生兔子这个问题。我们的笼子只能装十个兔子,所以在任意时
刻我们只能有十只兔子,但兔子是会繁殖的,那么怎么办呢?索性把长的不好看的兔子
干掉(这里的好看就是粒子权重,好看的权重就高不好看的权重就低,哈哈作者就是这
么任性)。让好看的兔子多生一只补充干掉的兔子。我们假设兔子一月繁殖一回,这样
的话在多年后这些兔子可能就都是一个兔子的后代。就是说兔子们的DNA都是一样的了,
也就是兔子DNA的多样性减小。为什么频繁执行重采样会使粒子多样性减小呢,这就好
比我兔子一月繁殖一会我可能五年后这些兔子的才会共有一个祖先。但如果让兔子一天
繁殖一会呢?可能一个月后这些兔子就全是最开始一只兔子的后代了,兔子们的DNA就
成一样了。因此为了防止粒子退化就要减少重采样的次数。Attach the article link: https://www.codetd.com/article/3003143
8. Epilogue
Seeing this, in fact, I have introduced the Gmapping algorithm very comprehensively, and almost synthesized all the articles about Gmapping that I have seen on the Internet. In the future, I will reproduce and introduce other classic SLAM algorithms, including vision, laser, and fusion of vision and laser. If interested readers think that my writing is not bad, please click three links (like, bookmark, follow), thank you all.