Article Directory
foreword
In troubled times, prepare for a rainy day
1. What is cache breakdown
To put it bluntly, a very frequently used key suddenly fails and the request misses the cache, which causes countless requests to fall on the database, dragging down the database in an instant. And such a key is also called a hot key!
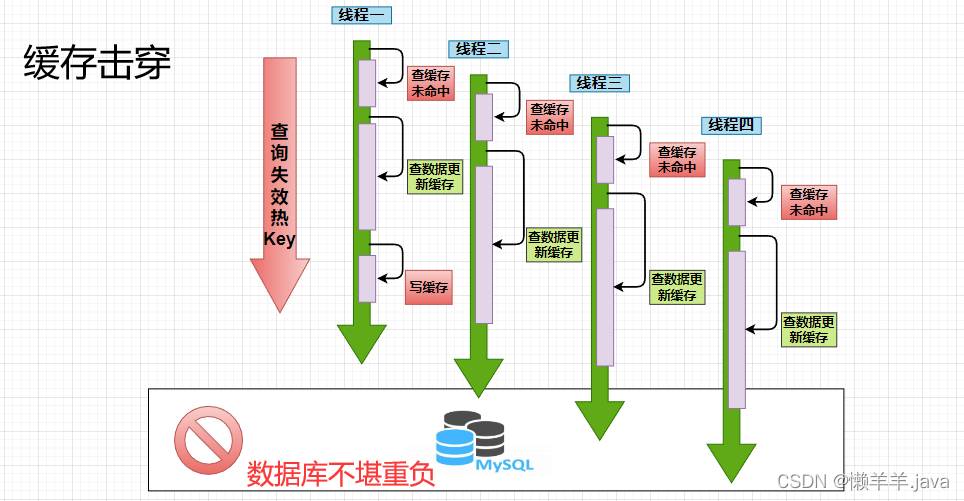
It can be seen intuitively that if you want to solve the cache breakdown, you must not allow so many threads of requests to access the database in a certain period of time.
Based on this, there are two solutions for restricting access to the database:
2. Solve cache breakdown based on mutex
For an id query interface that is accessed frequently, cache breakdown may occur. The following uses a mutex to solve the problem.
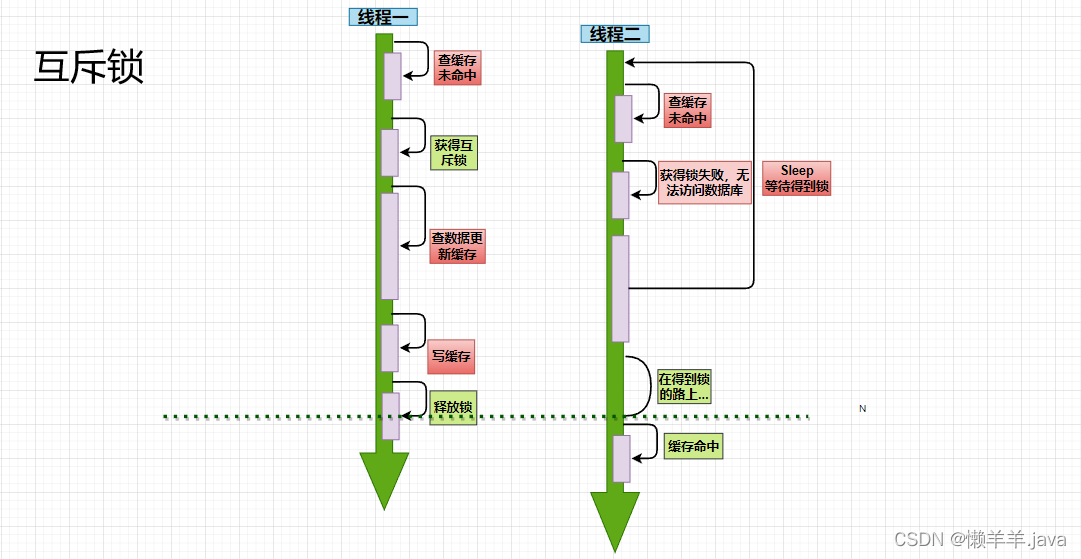
In the past, the id query information interface generally wrote the queried information into the cache, and checked whether it hit the cache. Do the corresponding treatment. In the case of concurrency, when the hot key fails, a large number of requests will directly hit the database and try to rebuild the cache, which is likely to stop the database and cause service interruption. For such a situation, when the cache is missed, the best processing point is the step after judging whether the cache is hit in the business, that is, whether the "extra" request accesses the database or not.
Can requests from other threads access the database? When can I access the database?
Can other threads access the database? ——Lock,
when you can only have a lock to access the database? ——Wait for the main thread to release the lock
, what should other threads do when they can't get the lock? ——Go to sleep, come back later
In order to realize that only one thread can acquire the lock when multiple threads are in parallel, we can use the setnx that comes with Redis
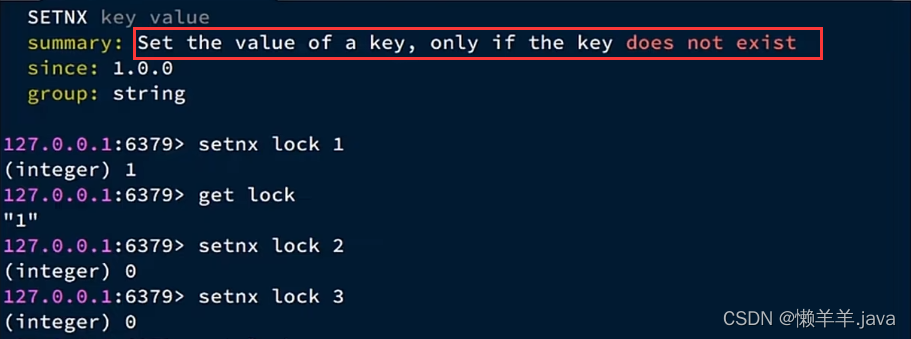
to ensure that the write operation can be performed when the key does not exist, and the write operation cannot be performed when the key exists. It perfectly guarantees that only the first thread to get the lock can write under concurrent conditions, and after he finishes writing (without releasing it), others will not be able to write.
How to get it? Write a Key-Value in,
how to release it? Delete the Key from del lock (usually set a validity period to avoid the situation of not releasing for a long time)
In this way, I can encapsulate two methods based on this condition, one writes the key to try to acquire the lock and the other deletes the key to release the lock. like this:
/**
* 尝试获取锁
*
* @param key
* @return
*/
private boolean tryLock(String key) {
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", 10, TimeUnit.SECONDS);
return BooleanUtil.isTrue(flag);
}
/**
* 释放锁
*
* @param key
*/
private void unlock(String key) {
stringRedisTemplate.delete(key);
}
In parallel, whenever other threads want to acquire the lock, they must write their own key into the tryLock() method to access the cache. If setIfAbsent() returns false, it means that a thread is updating the cache data and the lock has not been released. If it returns true, it means that the current thread has obtained the lock and can access the cache or even operate the cache.
In the following popular query scenario, we use code to implement mutex to solve cache breakdown
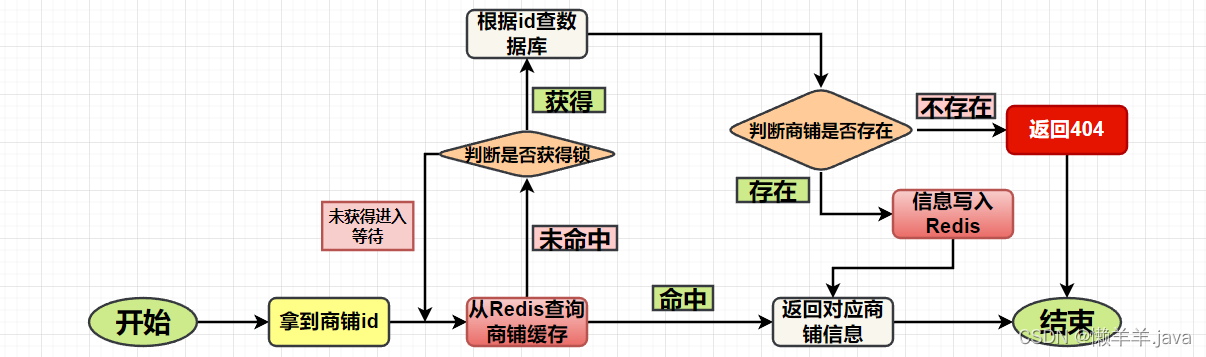
/**
* 解决缓存击穿的互斥锁
* @param id
* @return
*/
public Shop queryWithMutex(Long id) {
String key = CACHE_SHOP_KEY + id;
//1.从Redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key); //JSON格式
//2.判断是否存在
if (StrUtil.isNotBlank(shopJson)) {
//不为空就返回 此工具类API会判断""为false
//存在则直接返回
Shop shop = JSONUtil.toBean(shopJson, Shop.class);
//return Result.ok(shop);
return shop;
}
//3.判断是否为空值
if (shopJson != null) {
//返回一个空值
return null;
}
//4.缓存重建
//4.1获得互斥锁
String lockKey = "lock:shop"+id;
Shop shopById=null;
try {
boolean isLock = tryLock(lockKey);
//4.2判断是否获取成功
if (!isLock){
//4.3失败,则休眠并重试
Thread.sleep(50);
return queryWithMutex(id);
}
//4.4成功,根据id查询数据库
shopById = getById(id);
//5.不存在则返回错误
if (shopById == null) {
//将空值写入Redis
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
//return Result.fail("暂无该商铺信息");
return null;
}
//6.存在,写入Redis
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shopById), CACHE_SHOP_TTL, TimeUnit.MINUTES);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
//7.释放互斥锁
unlock(lockKey);
}
return shopById;
}
3. Solve cache breakdown based on logical expiration
Logical expiration is not real expiration. We don't need to set TTL for the corresponding Key, but use business logic to achieve an effect similar to "expiration". Its essence is to limit the number of requests falling to the database! But the premise is to sacrifice consistency to ensure availability, or the interface of the previous business, and solve the cache breakdown by using logical expiration:
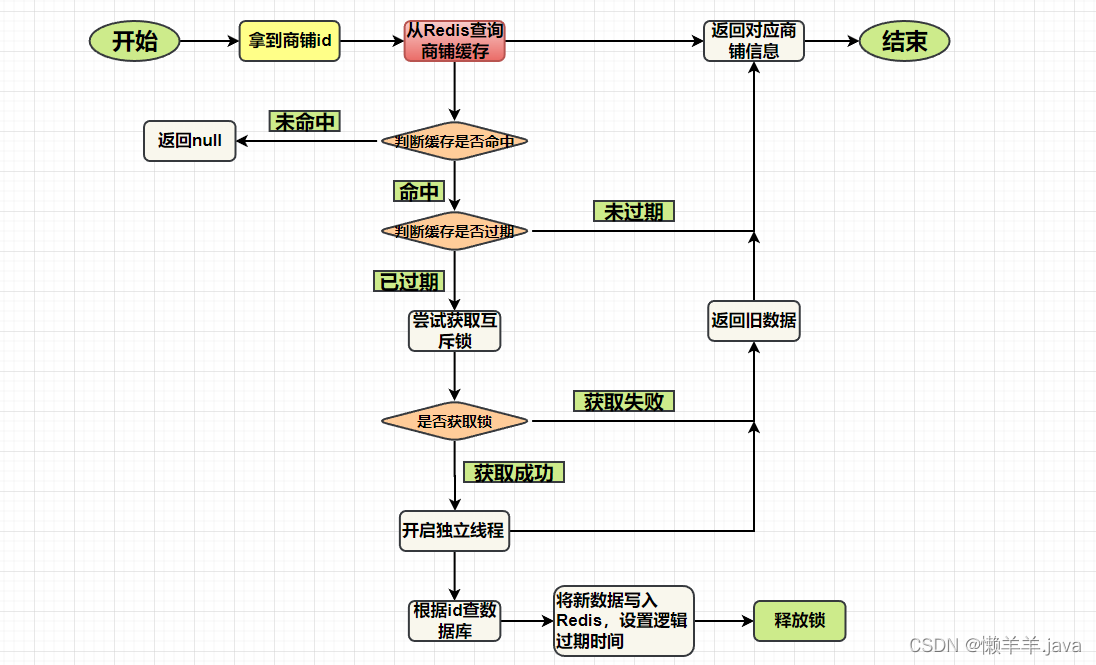
in this way, the cache will basically be hit, because I did not set any expiration time for the cache, and for The key set is all selected in advance. If there is a miss, it can basically be judged that he is not in the selection, so I can directly return an error message. In the case of a hit, it is necessary to first determine whether the logical time has expired, and then decide whether to rebuild the cache based on the result. And the logical time here is to reduce a large number of requests to a "gateway" that falls to the database
After reading the above paragraph, I believe everyone is still confused. Since there is no expiration time set, why do you still need to judge the logical expiration time? Why is there still a problem of whether it has expired?
In fact, the so-called logical expiration time here is just an attribute field of a class. It has not risen to Redis at all, but to the cache level, which is used to assist in judging the query object. That is to say, the so-called expiration time is separated from the cached data. Yes, so there is no problem of cache expiration at all, and naturally the database will not be under pressure.
code stage:
In order to conform to the principle of opening and closing as much as possible, the attributes of the original entity are not extended by inheritance, but by combination.
@Data
public class RedisData {
private LocalDateTime expireTime;
private Object data; //这里用Object是因为以后可能还要缓存别的数据
}
Encapsulate a method to simulate the update logic expiration time and cached data to run in the test class to achieve the effect of data and heat
/**
* 添加逻辑过期时间
*
* @param id
* @param expireTime
*/
public void saveShopRedis(Long id, Long expireTime) {
//查询店铺信息
Shop shop = getById(id);
//封装逻辑过期时间
RedisData redisData = new RedisData();
redisData.setData(shop);
redisData.setExpireTime(LocalDateTime.now().plusSeconds(expireTime));
//将封装过期时间和商铺数据的对象写入Redis
stringRedisTemplate.opsForValue().set(CACHE_SHOP_KEY + id, JSONUtil.toJsonStr(redisData));
}
Query interface:
/**
* 逻辑过期解决缓存击穿
*
* @param id
* @return
*/
public Shop queryWithLogicalExpire(Long id) throws InterruptedException {
String key = CACHE_SHOP_KEY + id;
Thread.sleep(200);
//1.从Redis查询缓存
String shopJson = stringRedisTemplate.opsForValue().get(key); //JSON格式
//2.判断是否存在
if (StrUtil.isBlank(shopJson)) {
//不存在则直接返回
return null;
}
//3.判断是否为空值
if (shopJson != null) {
//返回一个空值
//return Result.fail("店铺不存在!");
return null;
}
//4.命中
//4.1将JSON反序列化为对象
RedisData redisData = JSONUtil.toBean(shopJson, RedisData.class);
Shop shop = JSONUtil.toBean((JSONObject) redisData.getData(), Shop.class);
LocalDateTime expireTime = redisData.getExpireTime();
//4.2判断是否过期
if (expireTime.isAfter(LocalDateTime.now())) {
//5.未过期则返回店铺信息
return shop;
}
//6.过期则缓存重建
//6.1获取互斥锁
String LockKey = LOCK_SHOP_KEY + id;
boolean isLock = tryLock(LockKey);
//6.2判断是否成功获得锁
if (isLock) {
//6.3成功,开启独立线程,实现缓存重建
CACHE_REBUILD_EXECUTOR.submit(() -> {
try {
//重建缓存
this.saveShop2Redis(id, 20L);
} catch (Exception e) {
throw new RuntimeException(e);
} finally {
//释放锁
unlock(LockKey);
}
});
}
//6.4返回商铺信息
return shop;
}
4. Interface test
It can be seen that the interface test is performed by simulating concurrent scenarios through APIfox, and the average time-consuming is still very short, and the console log does not have frequent access to the database:
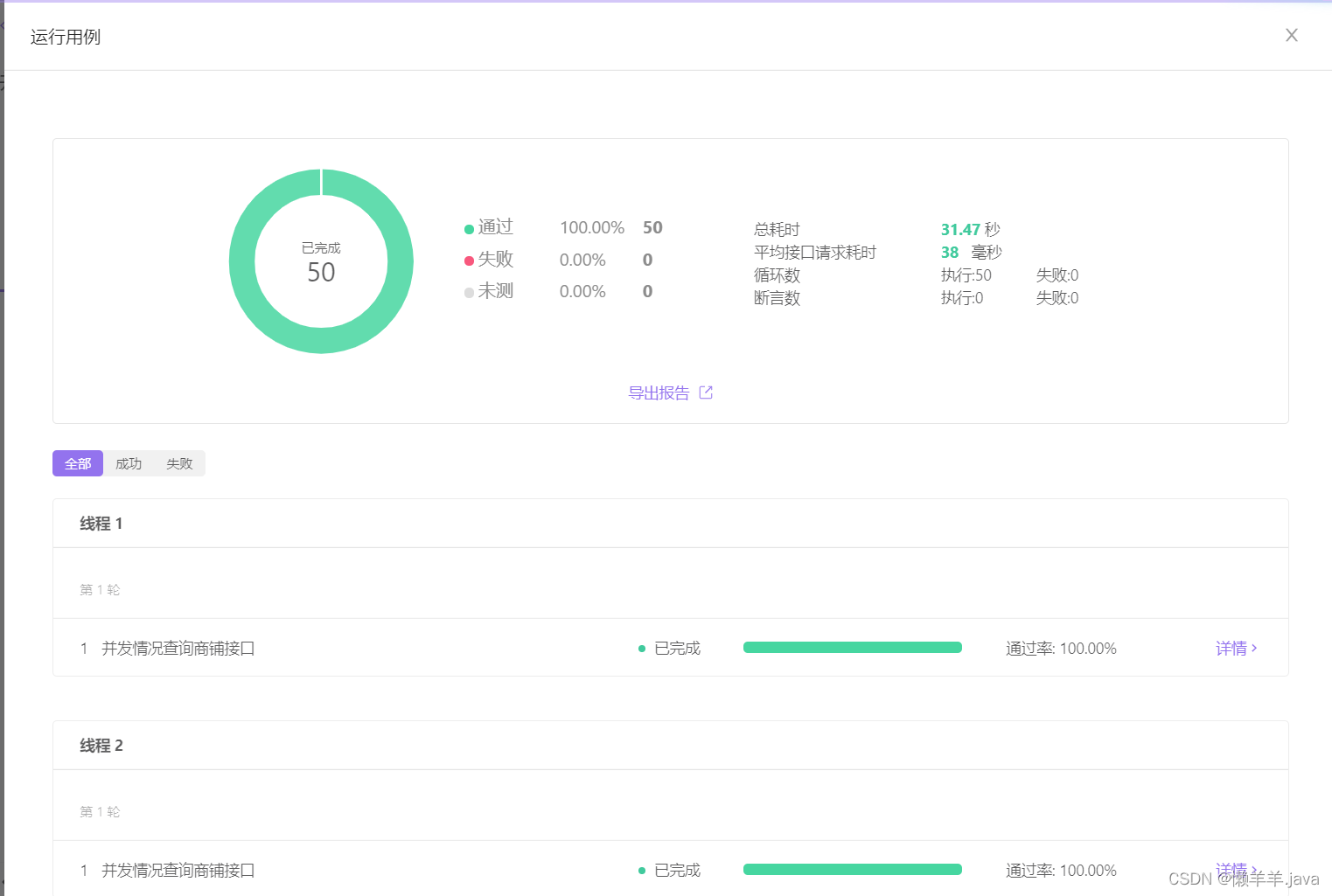
since ApiFox does not support a large number of threads, I used jmeter to test with 1550 threads After a while, the interface can still run through!

It seems that the performance of the interface is not bad in concurrent scenarios, and the QPS is also quite ideal
Five. Comparison between the two
It can be seen that the code level of the mutex method is simpler, and only two simple methods need to be encapsulated to operate the lock. The logical expiration method is more complicated, and additional entity classes need to be added. After encapsulating the method, it is necessary to simulate data warm-up in the test class.
In contrast, the former does not consume additional memory (does not open new threads), and has strong data consistency, but threads need to wait, performance may be poor and there is a risk of deadlock. The latter opens up a new thread with additional memory consumption, sacrificing consistency to ensure availability, but the performance is better without waiting.