In the first blog post, we have a simple understanding of Zookeeper, and it is relatively simple and easy to understand. In this blog post, we understand its basic concepts, as shown in the following figure:
Understanding its basic concepts will help us to learn later. Although today's articles are conceptual content, they are of great significance.
1. Cluster roles:
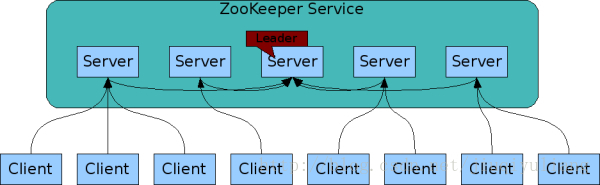
Zookeeper clusters usually have three roles: Leader, Follower, Observer.
| Role | describe |
|---|---|
| Leader server | The core of the entire Zookeeper cluster working mechanism does not accept requests from clients, and is mainly responsible for the initiation and resolution of voting, and updating the system status. |
| Follower server | Followers of the Zookeeper cluster state, used to accept client requests and return results to clients, and participate in voting initiated by the leader. |
| ObServer server | Acting as an observer, ObServer can receive client connections and forward write requests to the leader node. But ObServer does not participate in the voting process and only synchronizes the state of the leader. The purpose of ObServer is to expand the system and improve the reading speed. |
The system model is shown in the figure:
2. Session:
Session refers to the connection between the client and the ZooKeeper server. The session in ZooKeeper is called Session. The client maintains a Session by establishing a long TCP connection with the server. When the client starts, it first establishes a TCP connection with the server. With this connection, the client can maintain a valid session with the server through heartbeat detection, and can also send a request to the Zookeeper server and get a response.
3. Data Node:
There are two types of nodes in Zookeeper:
1. A machine in the cluster becomes a node
2. The data unit Znode in the data model is divided into persistent nodes and temporary nodes
The data model of Zookeeper is a tree, and the node of the tree is the Znode, and the information can be stored in the Znode.
As shown below:
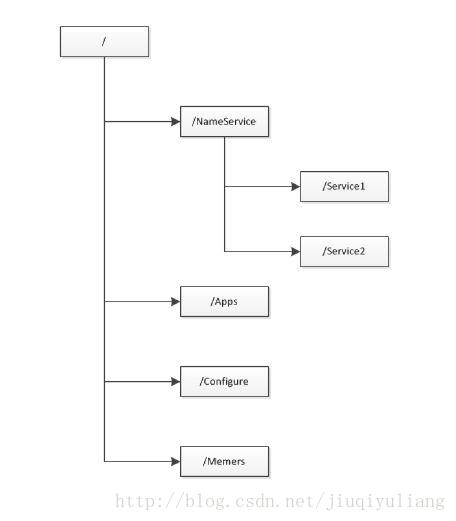
The general data structure of ZK is consistent with the above figure. As shown in the figure above, this figure is like a tree. This tree has a root node, and then some sub-nodes under it, and then each sub-node can have sub-nodes under it. Most of the development is to deal with these data nodes of zk, to read and write these data nodes, to complete the task.
Unlike traditional file systems, data in ZooKeeper is stored in memory, enabling high throughput and low latency for distributed synchronization services.
In the data model of ZooKeeper in the example above, there are the following points:
- Each node (ZNode) stores synchronization-related data (this is the original intention of ZooKeeper design, the amount of data is very small, about the order of B to KB), such as status information, configuration content, location information, etc.
- A ZNode maintains a state structure that includes: version number, ACL changes, and timestamp. Each time ZNode data changes, the version number is incremented so that client read requests can retrieve state-related data based on the version number.
- Each ZNode has an ACL that restricts access to that ZNode.
- Within a namespace, both read and write request operations performed on the data stored on the ZNode are atomic.
- The client can set a watch on a ZNode. If the ZNode data changes, ZooKeeper will notify the client, thereby triggering the execution of the logic implemented in the watch.
- Each client connects to ZooKeeper to establish a session (Session). During the session, three states of CONNECTING, CONNECTED and CLOSED may occur.
- ZooKeeper supports the concept of ephemeral nodes, which are related to sessions in ZooKeeper. If the connection is disconnected, the node is deleted.
Fourth, the version:
The version in ZK is used to record the modification times of the node data or the child node list of the node or the permission information. Note that this is the modification times. If the version of a node is 1, it means that the node has been modified once since its creation, so how to use this version? Typically, we can use version to implement distributed lock services. We know that in the database, there are generally two kinds of locks, one is pessimistic locking and the other is optimistic locking.
pessimistic lock
Pessimistic lock, also known as pessimistic concurrent lock, is a very strict locking strategy in the database. It has strong exclusivity and can avoid data inconsistency caused by concurrent updates of the same data by different transactions. Before the previous transaction is completed, the next transaction The same resources cannot be accessed, which is suitable for scenarios where data update competition is very fierce.
optimistic locking
Compared with pessimistic locks, optimistic locks are used in more scenarios. Pessimistic locks believe that when transactions access the same data, there will be mutual interference, so the exclusive access method is used simply and rudely, while optimistic locks believe that different transactions access the same resource. Mutual interference rarely occurs, so concurrency control is not required during transaction processing. Of course, optimistic locking is also a lock, and it still has concurrency control! For the database, our usual practice is to add a version field to each table. Before the transaction modifies the data, the data is read out. Of course, the version number is also read out, and then the read version number is added to the update statement. In the condition, for example, the read version number is 1, we can write the statement to modify the data like this, update XX table set field 1 = XX value where id=1 and version=1, then if the update fails, it will be explained later Other transactions have modified the data, then the system needs to throw an exception to the client, let the client handle it by itself, and the client can choose to retry. Lock, the version in ZK has a similar effect.
There are three version types of ZK: version cversion aversion
| Version type | illustrate |
|---|---|
| version | The version number of the data content of the current data node |
| cversion | The version number of the child node of the current data node |
| aversion | The current data node ACL changes the version number |
Five, watcher (event listener):
We can understand watcherWatcher as an event listener.
ZooKeeper allows users to register some watchers on specified nodes. When the data node changes, the Zookeeper server will send a notification of the change to interested clients.
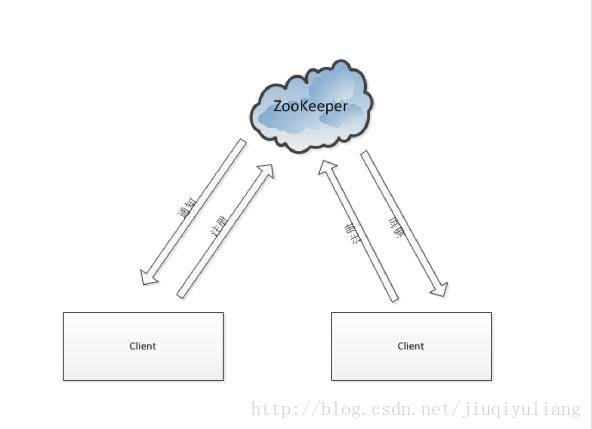
Both clients have registered watchers (event listeners) in the zookeeper cluster, then when the node data in zk changes, zk will send a notification of the change to the client, and when the client receives the change When notified, it can go back to zk to get the details of this data.
6. ACL permission control:
ACL is the abbreviation of Access Control Lists. ZooKeeper uses the ACL strategy to control permissions. It has the following permissions:
1. CREATE: permission to create child nodes
2. READ: permission to obtain node data and child node lists
3. WRITE: to update node data Permission
4. DELETE: permission to delete child nodes
5. ADMIN: permission to set node ACL
The above permissions are a bit similar to the permission management of our information system. We generally manage these permissions for data when developing the system. A zk cluster may serve a lot of business, especially for some large companies, the nodes of the zk cluster will If important information is stored, then this information is usually only open to a part of the visitors. Through acl, we can authorize the access of certain nodes to ensure the security of the data.
In the next blog post, we will build a zookeeper cluster.