First, the fitting principle of neurons
A neuron consists of the following key knowledge points: activation function; loss function; gradient descent.
Single neuron network model:
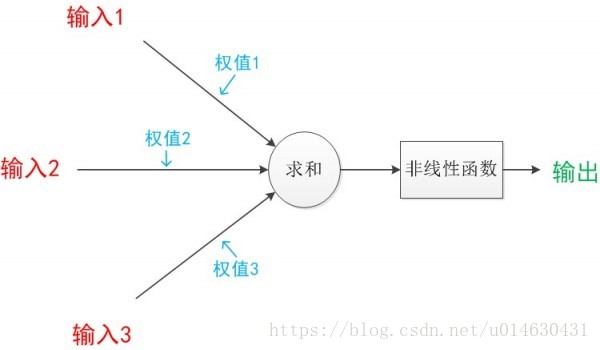
its calculation formula: 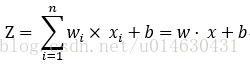
the learning of the model is to adjust w and b to obtain a suitable value, and finally the logic formed by this value and the operation formula is the model of the neural network. When we assign w and b appropriate values, and then cooperate with the appropriate activation function, we will find that it can produce a good fitting effect.
1. Forward propagation: The flow of data from input to output is forward propagation. It is only on the basis of an assumption of suitable w and b that the correct fitting to the real environment can be achieved. But in the actual process, we cannot know what the values of w and b are to be considered normal. Therefore, a training process is added, and the model is automatically corrected by the method of reverse error transmission, and finally an appropriate weight is generated.
2. Backpropagation: The meaning of backpropagation – tells the model how much we need to tune w and b. When the appropriate weight is not obtained at the beginning, the result generated by forward propagation is wrong with the actual label. Back propagation is to pass this error to the weight, so that the weight can be adjusted appropriately to achieve a suitable output. BP algorithm is also called "error back propagation algorithm". Our ultimate goal is to minimize the error between the output of forward propagation and the label, which is the core idea of back propagation.
In order to minimize the loss value (subtract the output value from the label directly, or perform operations such as square difference), we use mathematical knowledge to select an expression for the loss value so that this expression has a minimum value, and then derive the way to find the slope of the function tangent (that is, the gradient) at the minimum moment, so that the values of w and b are adjusted along this gradient.
As for how much to adjust each time, we introduce a parameter called "learning rate" to null, so that through continuous iteration, the error is gradually approached to the minimum value, and finally our goal is achieved.
2. Activation function
The main function of the activation function is to add nonlinear factors to solve the defect of insufficient expression ability of the linear model, and it plays a crucial role in the entire neural network.
Because the mathematical foundation of neural network is differentiable everywhere, the selected activation function should ensure that the data input and output are also differentiable.
Commonly used activation functions in neural networks are Sigmoid, Tanh, and relu.
3. Softmax algorithm
Softmax can basically be regarded as the standard for classification tasks.
In real life, a problem needs to be classified in multiple ways, and then the soft max algorithm needs to be used. If it is judged that the probability of the input belonging to a certain class is greater than the probability of belonging to other classes, then the value corresponding to this class is close to 1, and the value of other classes is close to 0. The main application of this algorithm is multi-classification, and it is mutually exclusive, that is, it can only belong to one of the classes. Unlike the activation function of the sigmoid class, the general activation function can only be divided into two categories, so it can be understood that soft max is an extension of the activation function of the sigmoid class, and its algorithm formula is: soft max = exp(logits)/reduce_sum( exp(logits), dim)
Fourth, the loss function
The loss function is used to describe the difference between the predicted value of the model and the true value. There are generally two more common algorithms – mean squared difference (MSE) and cross entropy.
5. Gradient descent
Gradient descent is an optimization algorithm, also known as the steepest descent method. It is often used in machine learning and artificial intelligence to recursively approximate the minimum deviation model. The direction of gradient descent is to use the negative gradient direction as the search direction, and descend along the gradient. Find the minimum value in the local direction.
In the training process, the loss value between the output value and the real value will be obtained after each forward propagation. The smaller the loss value, the better the model, so the gradient descent algorithm is used here to help find the smallest loss. value, so that the corresponding learning parameters w and b can be reversed to achieve the effect of optimizing the model.
Commonly used gradient descent methods can be divided into: batch gradient descent, stochastic gradient descent and mini-batch gradient descent.
1. Degenerate learning rate: finding a balance between speed and accuracy of training
6. Initialize the learning parameters
When defining learning parameters, you can use get_variable and Variable. For a network model, the initialization of different parameters will have a great impact on the network, so TensorFlow provides many initialization functions with different characteristics.
7. Extension of a single neuron-Maxout network
The Maxout network can be understood as the expansion of a single neuron, mainly to expand the activation function in a single neuron.
The function of a neuron is similar to that of human nerve cells. Different neurons will produce different outputs due to different inputs, that is, different cells care about different signals. Relying on this principle, the current practice is equivalent to using multiple neurons together at the same time, and whichever is effective will be used. So such a network will have better results.
Maxout is to turn the activation function into a network selector. The principle is to put multiple neurons side by side, find the largest one from their output results, which represents the most sensitive feature response, and then take the result of this neuron participate in subsequent operations.
Maxout's fitting function is very powerful, but it also has the disadvantages of too many nodes, too many parameters, and too slow training.
Reading Notes "Introduction, Principles and Advanced Practice of Tensor Flow in Deep Learning" – Li Jinhong