CNN
1.Image Classification
CNN is often used for image recognition. That is, a picture is then classified to determine what is in it. In the article, it is assumed that the image size of the model input is fixed. Fixed is 100*100. The actual pictures are big and small, and not all pictures are square. What about rectangular ones?

The common processing method today is to throw it into the image recognition system, which is to first rescale all the pictures into the same size, and then throw them into the image recognition system. In the end we need to output categories, so we use one-hot one-hot encoding. target is called

In this One-Hot Vector, assuming that our current category is a cat, the value of the Dimension (dimension) corresponding to the cat is 1, and the value of the Dimension corresponding to other things is 0, then the length of this
Dimension It is determined how many different types of things your current model can recognize. If the length of your vector is
2000, it means that your model can recognize 2000 different things. Today’s relatively strong image recognition system, It can often identify more than 1,000 kinds of things, even tens of thousands of different objects. If you want your image recognition system to recognize tens of thousands of objects, then your Label will be a tens of thousands of objects. The dimension is tens of thousands of One-Hot Vector.
When it's big it's a little too much
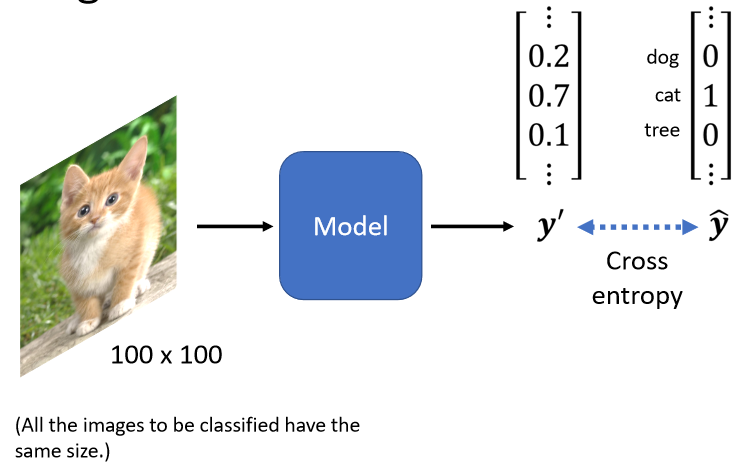
After the output of my model passes through Softmax, the output is, and then we hope that the smaller the Cross Entropy, the better. The next question is how to use an image as the input of a model.
In fact, for a Machine, a picture In fact, it is a three-dimensional Tensor
tensor is "tensor" (the translation is really difficult to understand, breaking the concept). In fact, it is basically the same format as numpy arrays, vectors, and matrices. But it is specially designed for GPU , it can run on GPU to speed up calculation efficiency, don't be scared.
In PyTorch, Tensor is the most basic unit of operation. Similar to NDArray in NumPy, Tensor represents a multidimensional matrix. The difference is that Tensor in PyTorch can run on the GPU, while NumPy's NDArray can only run on the CPU. Since Tensor can run on the GPU, the calculation speed is greatly accelerated.
One sentence summary: a multi-dimensional data that can run on the gpu
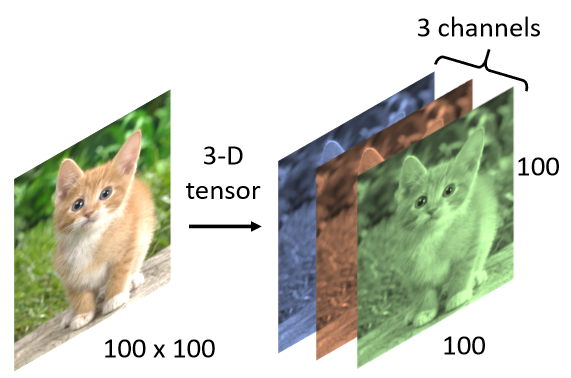
A picture is a three-dimensional Tensor, where one dimension represents the width of the picture, another one represents the height of the picture, and one dimension represents the number of channels of the picture.
A color picture, today each Pixel is composed of three colors of RGB, so these three Channels represent the three colors of RGB, and the length and width represent the resolution of this picture today , representing the number of Pixels and pixels in this picture.
Then we will straighten this three-dimensional Tensor, pull it into a vector, and then throw it into a Network.
The Network we have talked about so far, its input is actually a vector, so we only need to be able to Turning a picture into a vector, we can regard it as the input of the Network, but how to turn this three-dimensional Tensor into a vector, the most intuitive way is to straighten it directly.
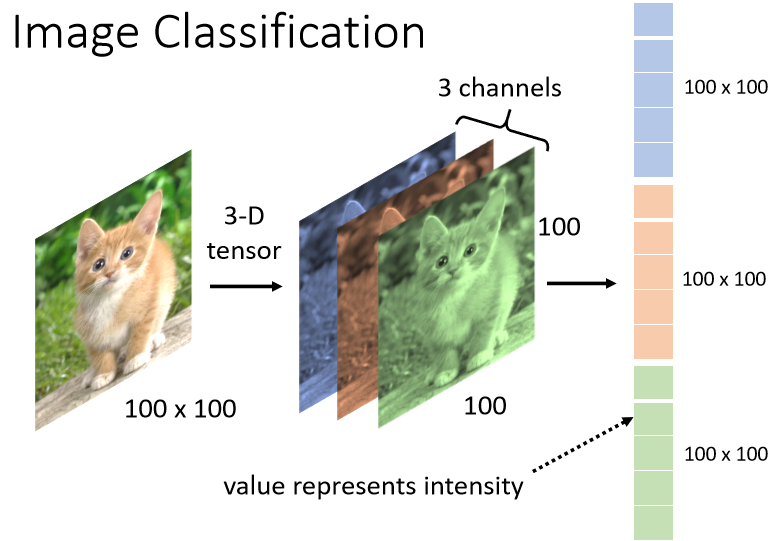
How many numbers are there in a three-dimensional Tensor?
In this example, there are 100 × 100 × 3 numbers. Take out all these numbers and arrange them in a row, which is a huge vector. This vector can be used as the input of the Network and this
vector Inside, the value stored in each dimension is actually the intensity of a certain color of a certain Pixel, and each Pixel is composed of three colors of RGB.
For this vector, if you use FCN (Fully Connected Network) to take this as the input of the Network, the length of the Feature Vector on the input side is 100*100*3. At this time, if the first layer (if there are several layers), each Neuron and each vector will have a value, there will be a Weight, so the current weight used is as many as 3*10 to the 7th power .
Although more parameters can increase flexibility, it will also cause the possibility of Overfitting. The greater the elasticity, the more likely Overfitting is.
So CNN will be used. It is not necessary for every Neuron and every input feature to have a Weight
Observation 1
We now have a picture and we want to know what kind of animal this is. Perhaps for an image recognition system, for an image recognition Neuron, for the nerves in an image recognition-like neural network, what it needs to do is to detect whether there are some Particularly important patterns
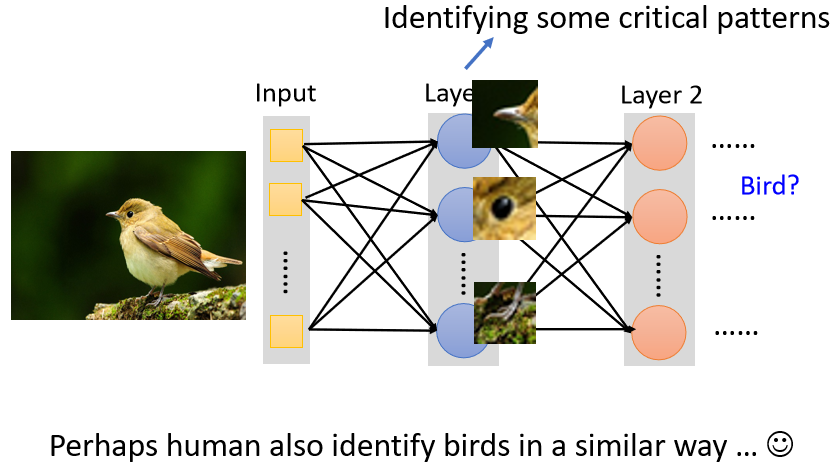
For example, the beak, the eyes, and the feet.
For example, if
there is a certain Neuron in 1, it sees the pattern of bird beak;
2, a certain Neuron says that it sees the pattern of eyes;
3, another Neuron says that it sees the pattern of bird claws
Maybe seeing these Patterns combined means that we saw a bird, and the neural network can tell you that because it saw these Patterns, it saw a bird and synthesized it through multiple Patterns.
So, we don't actually need every Neuron to see a complete picture. Because we all use part of the pattern to judge a whole picture. So these Neurons may not need to take the whole picture as input, they only need to take a small part of the picture as input, which is enough for them to detect whether some particularly critical Patterns have appeared. This is the first An observation, according to this observation, we can do the first simplification, how to simplify it.
Simplification 1
There is such a practice in CNN. We set an area called Receptive Field, and each Neuron only cares about what happens in its own Receptive Field. For example, you will first define
the blue Neuron, which The defensive range is this Receptive Field, and there are 3×3×3 values in this Receptive Field, so for the blue Neuron, it only needs to care about this small range, not the whole picture There is something in it. Then this Neuron, how do you think about whether something happened in this Receptive Field?
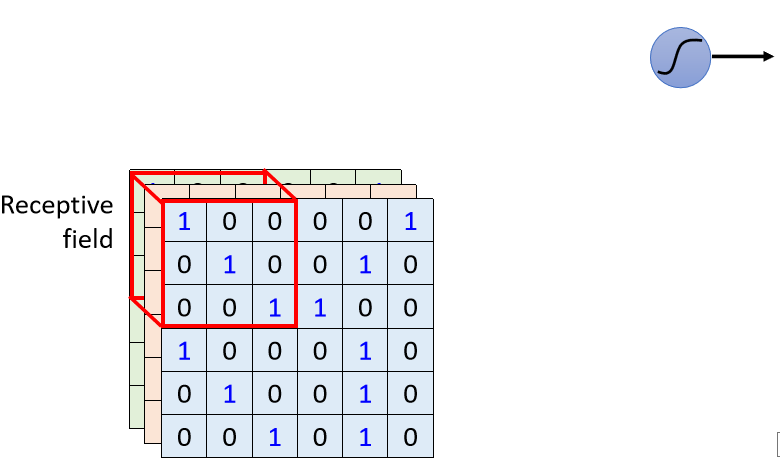
Receptive field Receptive field.
What it has to do is
1. Straighten the 3×3×3 value into a vector with a length of 3×3×3, which is 27 dimensions, and then use this 27-dimensional vector as the input of this Neuron
2 .This Neuron will give a 27-dimensional vector, and each Dimension has a Weight, so this Neuron has 3×3×3 27 Weight
3. In addition to the output obtained by Bias, this output is sent to the next layer of Neuron as enter.

So each Neuron only considers its own Receptive Field, so how to determine this Receptive Field, then you have to ask yourself! ! ! But to be honest, how to confirm the receptive field is really a problem
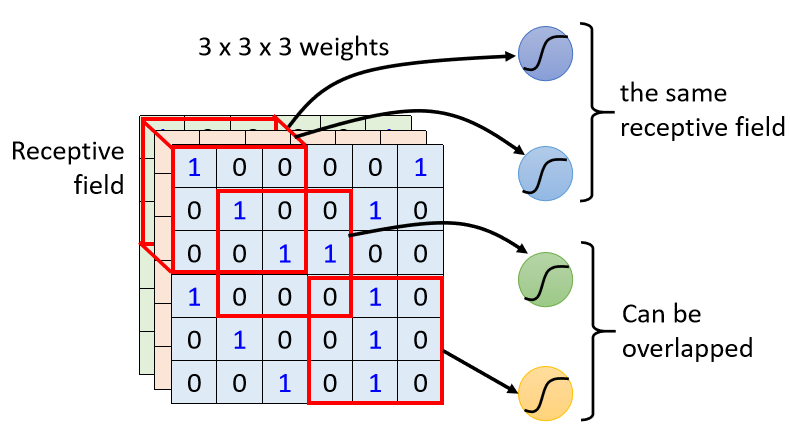
1. You can say that there is a blue Neuron here, it looks at the upper left corner, this is its Receptive Field
2. There is another yellow Neuron, it looks at the 3×3×3 lower right corner 3. The
Receptive Fields can also overlap with each other. For example, if I draw a Receptive Field now, this place is the green Neuron’s defense range, and it overlaps with the blue and yellow ones Space
4. Then you can even use two different Neurons. They can see the same range. Maybe use one Neuron to defend a range. You can’t detect all the patterns, so the same range can have multiple different patterns. Neuron, so with Receptive Field, they can have multiple Neurons together, but each one focuses on different features
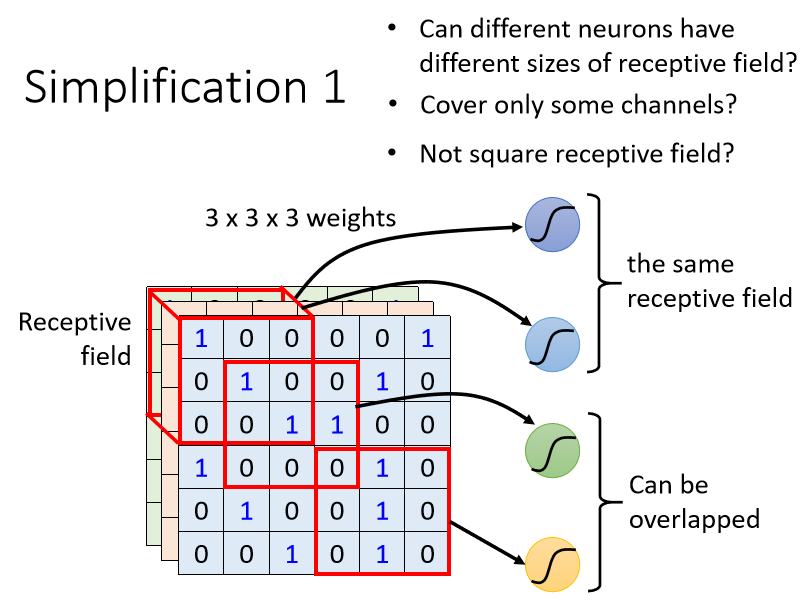
Then next, for example.
1. Can I make the Receptive Field different in size? Because after all, some patterns are relatively small and some are relatively large. Some patterns may be detected within the range of 3×3, and some patterns may be detected. The range of 11×11 can be detected. Yes, this is a common move. 2. Can
I use the Receptive Field to only consider certain channels? It seems that our Receptive Field is RGB three channels. All are considered, but maybe some patterns will only appear in the red channel, and maybe some patterns will only appear in the blue channel. Can I have a Neuron that only considers one channel? Yes, in fact, when we talk about Network Compression later, we will talk about this kind of Network architecture. You don’t often think about it like this in general CNNs, but there is such a way. 3. Some people will ask about the Receptive
here . Fields are all squares. In the example you just gave, 3×3 11×11 are also squares. Can they be rectangles? Can! It can be rectangular, which is completely designed by yourself. The Receptive Field is defined by yourself. You can completely decide what you think the Receptive Field should look like based on your understanding of this issue
.You might say that the Receptive Field must be connected? Can we say that there is a Neuron, its Receptive Field is the upper left corner and the upper right corner of the image. In theory, it is possible, but you have to think about why you want to do this. Is there any pattern? Yes, you can only find it by looking at the upper left corner and lower right corner of a picture. Maybe there is no. If not, this This kind of Receptive Field is useless. The reason why our Receptive Field is a connected territory is that we feel that we want to detect a Pattern. Then this Pattern appears at a certain position in the whole picture instead of appearing. It is not divided into several parts and appears in different positions in the picture, so the Receptive Field is all phases, and what is usually seen are connected territories.
If you say that you want to design a very strange Receptive Field to solve very special problems, it is also possible.
Simplification 1 – Typical Setting
Here will introduce a very common, very classic Receptive Field arrangement
1. View all Channels

Generally, when doing image recognition, we may, you may not think that some patterns only appear in a certain Channel, so we will look at all Channels, so since we will look at all Channels
When we describe a Receptive Field, we only need to talk about its height and width , and we don’t need to talk about its depth . Anyway, the depth must consider all Channels, and the combination of height and width is called Kernel Size (convolution core size)
For example, in this example, our Kernel Size is 3×3. Generally, our Kernel Size will not be too large. In image recognition, a Kernel Size of 3×3 is often enough. If you Say you set a 7×7 9×9, then this is quite a large Kernel Size, usually 3×3
Some people may doubt that if the Kernel Size is 3×3, it means that we think that when doing image recognition, the important patterns can be detected only in the small range of 3×3. Listen to It seems strange, some patterns may be very large, maybe the range of 3×3 cannot be detected.
We will answer this question later, so let me tell you now that the common way to set the Receptive Field is Kernel Size 3×3, and generally the same Receptive Field will not only have one Neuron to take care of it, it will often There is a group of Neurons to guard it, for example, 64 or 128 Neurons to guard the range of a Receptive Field,
2. So far we have talked about a Receptive Field (receptive field), what is the relationship between different Receptive Fields, you will move your Receptive Field in the upper left corner to the right a little , and then create another Receptive Field, the amount of this movement is called Stride, which is the step size. But to be honest, I still can't figure out how the different characteristics determine where to search.
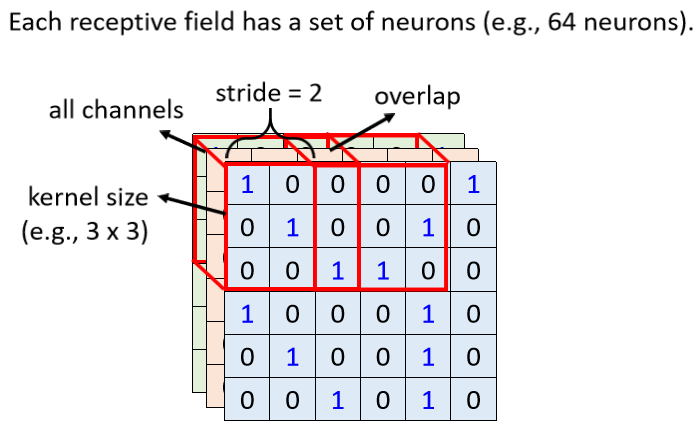
Stride is also a hyperparameter, which is generally not set too large, usually at one or two. That Stride is a Hyperparameter that you decide.
Because you want these Receptive Fields to overlap with the Receptive Fields, because assuming that the Receptive Fields do not overlap at all, then a Pattern will just appear, and it will become no Neuron at the junction of the two Receptive Fields. To detect it, then you may miss this Pattern, so we hope that the Receptive Fields have a high degree of overlap with each other. Suppose we set Stride = 2, then the first Receptive Field is here, and the second The second will be here.
3. Move two grids to the right and put it here, then there is a problem here, what should I do if it exceeds the range of this pixel of the image.
If there is a Pattern just in the range of the corner, there is no Neuron to observe and guard the Pattern, and Padding (filling) can be used for the excess, which is to fill in 0, or fill in the value, and can fill in the entire average or the number on the edge
In addition to horizontal value movement, there is also straight value movement, movement in the vertical direction
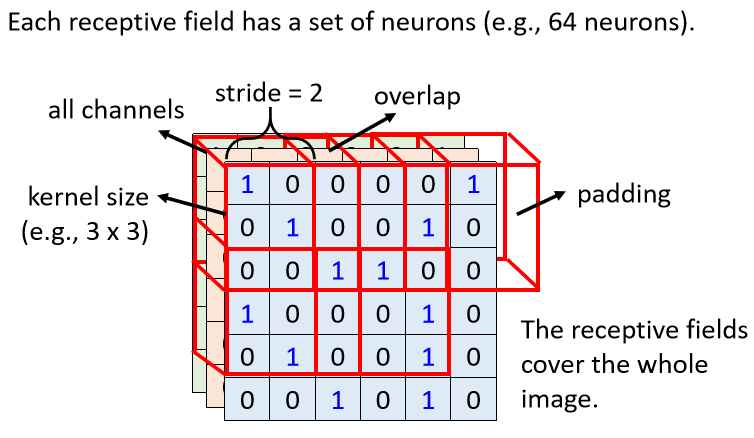
Here we also set the vertical Stride to 2, so you have a Receptive Field here, move two squares in the vertical direction, and there will be a Receptive Field in this place, you can scan the entire picture in this way, So in the whole picture, every inch of land is covered by a certain, Receptive Field, that is, every position in the picture, there is a group of Neurons detecting that place, if there is any pattern, then this is
it The first way to simplify, Fully Connected Network