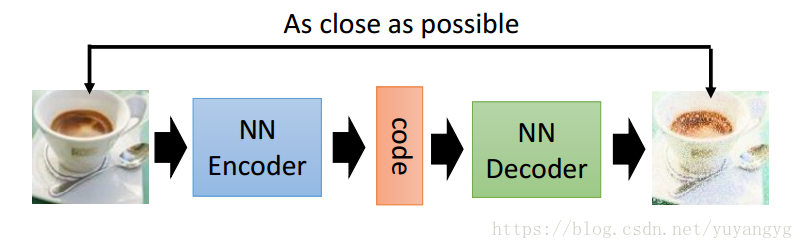
A stolen image, the auto-encoder is about an input image, or other signals, after a series of operations, such as convolution, or linear transformation, transform to obtain a vector, this vector is called the image of the image. Encoding, this process is called encoder, for a specific encoding, after a series of deconvolution or linear transformation, an image is obtained, this process is called decoder, that is, decoding.
So now there are two main applications of autoencoders, the first is data denoising, and the second is visual dimensionality reduction. Yet another function of autoencoders is to generate data.
However, this application has not been used yet. It should be emphasized here that autoencoder is not clustering, because although there is no corresponding label for each image, the task of autoencoder is not to classify images.
__author__ = 'SherlockLiao'
import torch
import torchvision
from torch import nn
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision.utils import save_image
from torchvision.datasets import MNIST
import them
if not os.path.exists('./dc_img'):
os.mkdir('./dc_img')
def to_img(x):
x = 0.5 * (x + 1)
x = x.clamp(0, 1)
x = x.view(x.size(0), 1, 28, 28)
return x
num_epochs = 100
batch_size = 128
learning_rate = 1e-3
img_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = MNIST('./data', transform=img_transform)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
class autoencoder(nn.Module):
def __init__(self):
super(autoencoder, self).__init__()
self.encoder = nn.Sequential(
nn.Conv2d(1, 16, 3, stride=3, padding=1), # b, 16, 10, 10
nn.ReLU(True),
nn.MaxPool2d(2, stride=2), # b, 16, 5, 5
nn.Conv2d(16, 8, 3, stride=2, padding=1), # b, 8, 3, 3
nn.ReLU(True),
nn.MaxPool2d(2, stride=1) # b, 8, 2, 2
)
self.decoder = nn.Sequential(
nn.ConvTranspose2d(8, 16, 3, stride=2), # b, 16, 5, 5
nn.ReLU(True),
nn.ConvTranspose2d(16, 8, 5, stride=3, padding=1), # b, 8, 15, 15
nn.ReLU(True),
nn.ConvTranspose2d(8, 1, 2, stride=2, padding=1), # b, 1, 28, 28
nn.Tanh()
)
def forward(self, x):
x = self.encoder(x)
x = self.decoder(x)
return x
model = autoencoder (). cuda ()
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate,
weight_decay=1e-5)
for epoch in range(num_epochs):
for data in dataloader:
img, _ = data
img = Variable(img).cuda()
# ===================forward=====================
output = model(img)
loss = criterion(output, img)
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ===================log========================
print('epoch [{}/{}], loss:{:.4f}'
.format(epoch+1, num_epochs, loss.data[0]))
if epoch % 10 == 0:
pic = to_img(output.cpu().data)
save_image(pic, './dc_img/image_{}.png'.format(epoch))
torch.save(model.state_dict(), './conv_autoencoder.pth')


Encode and decode output. Click to open the link

An autoencoder is an unsupervised neural network model that can learn the implicit features of the input data, which is called coding, and at the same time use the learned new features to reconstruct the original input data, which is called Decoding. Intuitively, autoencoder can be used for feature dimensionality reduction, similar to PCA, but its performance is stronger than PCA, because the neural network model can extract more effective new features. In addition to feature dimensionality reduction, new features learned by the autoencoder can be fed into the supervised learning model, so the autoencoder can function as a feature extractor. As an unsupervised learning model, autoencoders can also be used to generate new data that is different from the training samples, so that autoencoders (Variational Autoencoders) are generative models.
This article will describe the basic principles of autoencoders and a commonly used autoencoder model: Stacked Autoencoder. Subsequent articles will explain other models of autoencoders: Denoising Autoencoder, Sparse Autoencoder, and Variational Autoencoder. All models will be implemented programmatically using Tensorflow.
Autoencoder Principle
The basic structure of the auto-encoder is shown in Figure 1, including two processes of encoding and decoding:
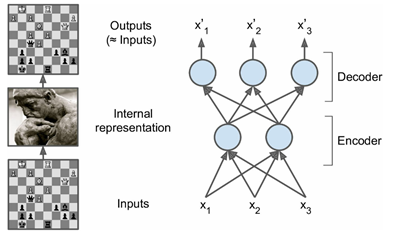 Figure 1 Encoding and decoding of autoencoders
Figure 1 Encoding and decoding of autoencoders
The auto-encoder encodes the input to obtain new features
, and hopes that the original input
can be
reconstructed from the new features. The encoding process is as follows:
It can be seen that, like the neural network structure, its encoding is a linear combination followed by a nonlinear activation function. If there is no nonlinear packing, then the autoencoder is not fundamentally different from ordinary PCA. Using the new features , the input can be
reconstructed , that is, the decoding process:
We want the reconstructed to be as consistent as possible, and we can train this model with a loss function that minimizes the negative log-likelihood:
For data with Gaussian distribution, it is good to use mean square error, and for Bernoulli distribution, cross entropy can be used, which can be derived from the likelihood function. In general, we will impose some restrictions on the auto-encoder. The most common one is to make , which is called tied weights, and all the auto-encoders in this article have this restriction. Sometimes, we also add more constraints to the autoencoder, which is the case with denoising autoencoders and sparse autoencoders, because most of the time it doesn't make sense to simply reconstruct the original input, we It is hoped that the autoencoder will be able to capture more valuable information from the original input while approximately reconstructing the original input.