cminus_compiler-2021-fall
foreword
The experimental document comes from the Compilation Principles course of Hunan University, and the experimental report is written by the author .
Lab1 experimental documentation
0. Basic knowledge
In this experiment we focus on the language used andFLEX adapted from the base . Here is a brief introduction to it.C-cminus-f
0.1 cminus-f lexical
C MINUSIt is a subset of the C language, and the syntax of the language is described in detail in the appendix of Chapter 9 of "Compilation Principles and Practice". Instead , floating-point operations cminus-fare C MINUSadded to it.
1. Keywords
else if int return void while float
2. Special symbols
+ - * / < <= > >= == != = ; , ( ) [ ] {
} /* */
3. Identifier ID and integer NUM, defined by the following regular expressions:
letter = a|...|z|A|...|Z
digit = 0|...|9
ID = letter+
INTEGER = digit+
FLOAT = (digit+. | digit*.digit+)
4. Comments are /*...*/indicated with more than one line. Comments cannot be nested.
/*...*/
- Note:
[,], and[]are three different tokens.[]Used to declare an array type[]without spaces.a[]should be recognized as two tokens:a,[]a[1]should be recognized as four tokens:a,[,1,]
0.2 FLEX is easy to use
FLEXis a tool for generating lexical analyzers. Using FLEX, we only need to provide the lexical regular expression, the corresponding C code can be automatically generated. The whole process is as follows:

First, the C code source file is generated by reading the specification of the lexical scanner FLEXfrom the input file *.lexor . Then, compile and link with the library to produce an executable . Finally, its input stream is analyzed to convert it into a sequence of tokens.stdiolex.yy.clex.yy.c-lfla.outa.out
Let's take a simple word count program wc.l as an example:
%{
//在%{和%}中的代码会被原样照抄到生成的lex.yy.c文件的开头,您可以在这里书写声明与定义
#include <string.h>
int chars = 0;
int words = 0;
%}
%%
/*你可以在这里使用你熟悉的正则表达式来编写模式*/
/*你可以用C代码来指定模式匹配时对应的动作*/
/*yytext指针指向本次匹配的输入文本*/
/*左部分([a-zA-Z]+)为要匹配的正则表达式,
右部分({ chars += strlen(yytext);words++;})为匹配到该正则表达式后执行的动作*/
[a-zA-Z]+ {
chars += strlen(yytext);words++;}
. {
}
/*对其他所有字符,不做处理,继续执行*/
%%
int main(int argc, char **argv){
//yylex()是flex提供的词法分析例程,默认读取stdin
yylex();
printf("look, I find %d words of %d chars\n", words, chars);
return 0;
}
Generate lex.yy.c with Flex
[TA@TA example]$ flex wc.l
[TA@TA example]$ gcc lex.yy.c -lfl
[TA@TA example]$ ./a.out
hello world
^D
look, I find 2 words of 10 chars
[TA@TA example]$
Note: When using stdin as input, you need to press ctrl+D to exit
So far, you have successfully completed a simple analyzer using Flex!
1. Experimental requirements
In this experiment, students need to complete the lexical_analyer.lcminux-f file according to the lexical grammar , complete the lexical analyzer, and be able to output the identified , , , , . Such as:tokentypeline(刚出现的行数)pos_start(该行开始位置)pos_end(结束的位置,不包含)
Text input:
int a;
Then the recognition result should be:
int 280 1 2 5
a 285 1 6 7
; 270 1 7 8
For specific tokens to be identified, refer to lexical_analyzer.h
In particular, for some tokens, we only need to filter, that is, they only need to be identified, but they should not be output to the analysis results. Because these tokens have no effect on the program running.
Note that the only files you need to modify should be [lexical_analyzer.l]…/…/src/lexer/lexical_analyzer.l). The
FLEXusage has been briefly introduced above. For more advanced usage, please refer to Baidu, Google and official instructions.
1.1 Directory structure
The whole repostructure is as follows
.
├── CMakeLists.txt
├── Documentations
│ └── lab1
│ └── README.md <- lab1实验文档说明
├── README.md
├── Reports
│ └── lab1
│ └── report.md <- lab1所需提交的实验报告(你需要在此提交实验报告)
├── include <- 实验所需的头文件
│ └── lexical_analyzer.h
├── src <- 源代码
│ └── lexer
│ ├── CMakeLists.txt
│ └── lexical_analyzer.l <- flex文件,lab1所需完善的文件
└── tests <- 测试文件
└── lab1
├── CMakeLists.txt
├── main.c <- lab1的main文件
├── test_lexer.py
├── testcase <- 助教提供的测试样例
└── TA_token <- 助教提供的关于测试样例的词法分析结果
1.2 Compile, run and verify
lab1The code is mostly composed of Cand python, cmakecompiled using .
-
compile
# 进入workspace $ cd cminus_compiler-2021-fall # 创建build文件夹,配置编译环境 $ mkdir build $ cd build $ cmake ../ # 开始编译 # 如果你只需要编译lab 1,请使用 make lexer $ makeThe compilation is
${WORKSPACE}/build/successful and thelexercommand will be generated under -
run
$ cd cminus_compiler-2021-fall # 运行lexer命令 $ ./build/lexer usage: lexer input_file output_file # 我们可以简单运行下 lexer命令,但是由于此时未完成实验,当然输出错误结果 $ ./build/lexer ./tests/lab1/testcase/1.cminus out [START]: Read from: ./tests/lab1/testcase/1.cminus [ERR]: unable to analysize i at 1 line, from 1 to 1 ...... ...... $ head -n 5 out [ERR]: unable to analysize i at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize n at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize t at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize at 1 line, from 1 to 1 258 1 1 1 [ERR]: unable to analysize g at 1 line, from 1 to 1 258 1 1 1We provide
./tests/lab1/test_lexer.pypython scripts for callinglexerbatches to complete analysis tasks.# test_lexer.py脚本将自动分析./tests/lab1/testcase下所有文件后缀为.cminus的文件,并将输出结果保存在./tests/lab1/token文件下下 $ python3 ./tests/lab1/test_lexer.py ··· ··· ··· #上诉指令将在./tests/lab1/token文件夹下产生对应的分析结果 $ ls ./tests/lab1/token 1.tokens 2.tokens 3.tokens 4.tokens 5.tokens 6.tokens -
verify
We use
diffdirectives for verification. Compare your own generated results with those provided by your teaching assistantTA_token.$ diff ./tests/lab1/token ./tests/lab1/TA_token # 如果结果完全正确,则没有任何输出结果 # 如果有不一致,则会汇报具体哪个文件哪部分不一致Please note that the test provided by the teaching assistant
testcasecannot cover all the test situations. You can only get the basic score after completing this part. Please design your owntestcasetest.
experimental report
Experimental requirements
According to the lexical completion of cminux-f lexical_analyer.l file, complete the lexical analyzer, can output the recognized token, type, line (the number of lines that have just appeared), pos_start (the starting position of the line), pos_end (the end position, not included)
Text input:
int a;
Then the recognition result should be:
int 280 1 2 5
a 285 1 6 7
; 270 1 7 8
For some tokens, we only need to filter, that is, only need to be recognized, but should not be output to the analysis results. Because these tokens have no effect on the program running.
Experiment Difficulties
- The construction and configuration of the experimental environment, such as the installation of ubuntu20.04 and the configuration of the flex compilation environment, etc.
- Learn and master cminus-f syntax, providing regular expressions for its lexical expressions.
- FLEX is a tool for generating lexical analyzers, and we need to learn its simple application.
experimental design
1. First, you need to write a regular expression, similar to the macro definition in the C language. As shown in the following figure, it is the definition of regular expressions such as keywords, special symbols, identifier IDs, etc. in the cminus-f syntax. For example, we can define 0|[1-9][0-9]*It is INTEGER, so as long as a number greater than or equal to 0 is read, it is recognized as INTEGER, and the keyword else is recognized as ELSE. EOL [\n]+This is because there may be more than one newline, and [\n]+ is syntactic sugar to indicate one or more newlines.

2. Write the corresponding action when the specified pattern is matched. The yytext pointer points to the input text matched this time. We write the regular expression to be matched in the left part, and the right part is the action to be executed after matching the regular expression. Except for some special regular expressions such as COMMENT to be analyzerimplemented in the function, most of them are the same, first set pos_start to pos_end, which is the position where the last recognition ended, and then set pos_end+=strlen(yytext), strlen(yytext) ) is the length identified this time, and finally return it. The last .{return ERROR;}representation returns an error if other undefined characters are recognized

3. In the analyzerfunction, add the action to be executed after matching the comment COMMENT, space BLANK and line feed EOL. Because it has been returned in step 2, only the relevant changes about pos_start, pos_end and lines need to be written here.
(1) For the comment COMMENT, first obtain the length of yytext as len, and then judge whether there is a newline character in the comment through the while loop, that is, determine whether yytext[i] is a newline character, if it is a newline \n, set pos_start and pos_end If it is 1, add 1 to lines; otherwise, pos_end++; break when the loop ends;

(2) For the space BLANK, we only need to set the value change of its pos_start and pos_end, pos_start=pos_end, pos_end+=strlen(yytext) as shown in the following code:

(3) For linefeed EOL, you only need to set its pos_start and pos_end to 1, and add strlen(yytext) to lines to indicate how much the number of lines has changed

Validation of experimental results
1. Create a build folder, configure the compilation environment, execute the command make lexer to run the code, and then execute the command python3 ./tests/lab1/test_lexer.pyto generate the corresponding token.

2. As shown in the figure, when the 6 tokens are compared with the TO_token provided by the teaching assistant, there is no output result, indicating that the results are exactly the same and correct.

3. Write a special code by yourself to test the regular definition of COMMENT comments to determine whether it can recognize /*//*/such comments, and check the arrays a[], a[n] at the same time.

Using the command ./build/lexer ./tests/lab1/testcase/7.mytest out, you get the following output:
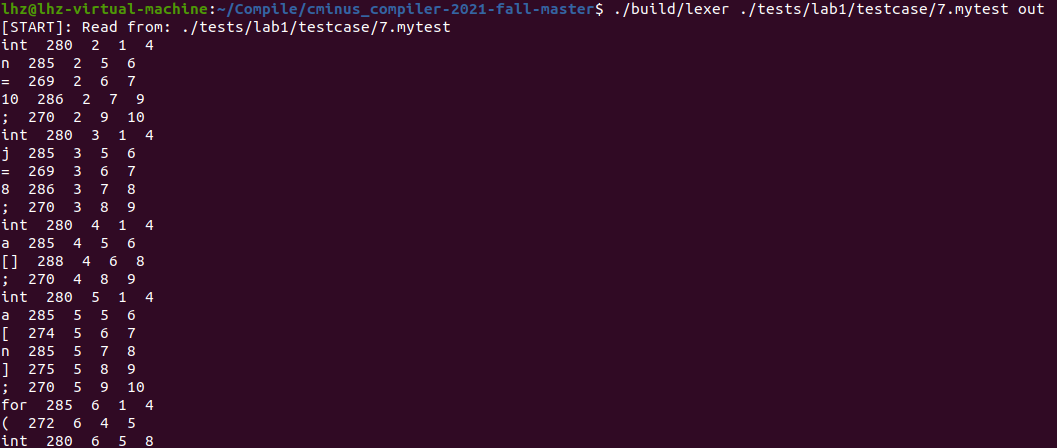
Result analysis: /*//*/Parts can be correctly identified (no output because it is directly filtered), and the result is correct. At the same time, the identification of the array is also correct.