点这里在线练习文章知识点,快速入门Python爬虫: https://edu.csdn.net/lab/35660
爬虫介绍
目标:理解爬虫基础知识及其原理
简介:网络爬虫,就是我们制定规则,让程序自动爬取网上的信息,实现操作自动化
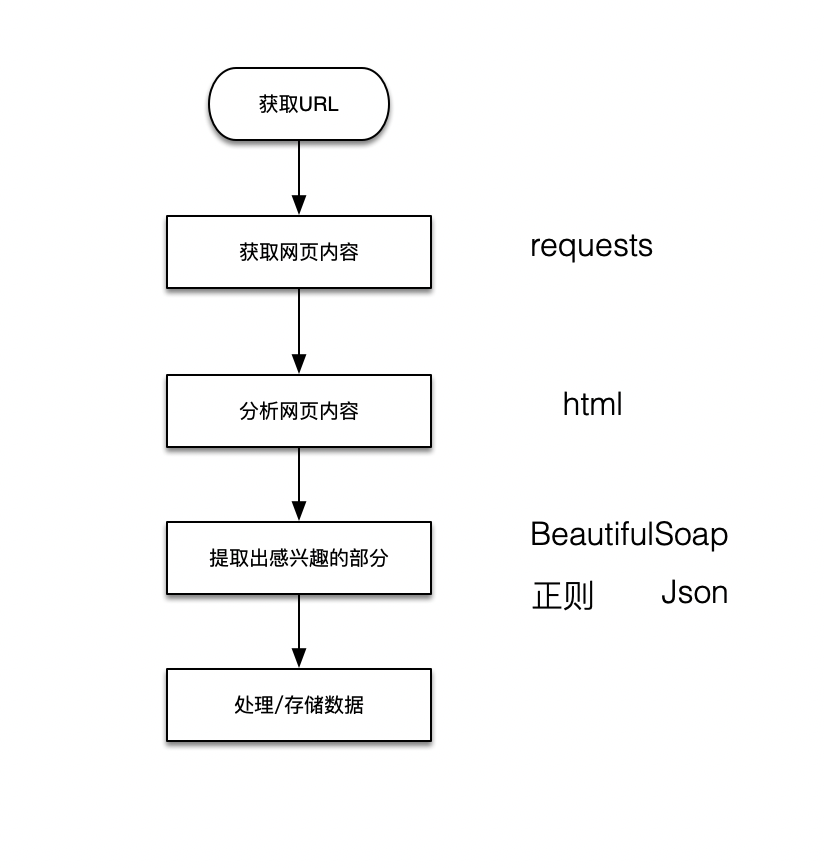
基本流程图
![]()
工作流程:
1.找到想要爬取的网站,利用代码发送请求,等待服务器做出回应(服务器就是存放数据的计算机)
2.服务器做出回应,返回页面内容
3. 分析页面内容,对网页内容进行处理,以便下一步数据提取
4. 使用正则、BeautifulSoap等工具提取所需数据
5. 打印数据或者存储数据
curl是一个命令行工具,它可以基于网络协议,对指定URL进行操作。
跟我练:在右侧命令行中输入下面的命令并按回车键执行命令。这个命令用来获取指定url的网页内容,完成后点击【检测任务】按钮,解锁下一任务。
curl --compressed http://wthrcdn.etouch.cn/weather_mini?city=北京![]()
上面的url http://wthrcdn.etouch.cn/weather_mini?city=北京 可以获取到北京的天气信息。
执行curl命令后,屏幕上将会显示指定url的网页内容。

![]()
把数据打印到屏幕上
Python跟我练可以在线输入Python代码,带你快速专注的学习Python知识,快通过右侧在线环境开始你的第一行Python代码吧!
IPython是一种基于Python的交互式解释器。相较于本地的Python Shell,IPython提供了更为强大的编辑和交互功能。本课程使用ipython作为学习python的环境。
1.在右侧命令行窗口输入ipython,按下回车键,进入到Python解释器环境中。
Hello from CSDN EDU !!!
[csdn ~]$ ipython![]()
2.在当前的IPython环境里输入以下代码,并按下回车键,打印出你的第一行Python代码。
print('Hello World')![]()
运行结果如下图所示
![]()
注意:
\1. 在代码中,小括号和双引号都需要在英文半角状态下输入;
\2. print全部为小写字母,Python语法区分大小写字母;
\3. 双引号也可换成单引号,但两者不能混用;
\4. 使用exit()可以终止Python解释器,并退出Python环境。
跟我练:在python环境中使用print函数输出如下图所示的文字,完成后点击【检测任务】按钮,解锁下一任务。
学习使用print函数
![]()
安装第三方模块requests
在进行Python程序开发时,有很多第三方的工具包模块可以被开发者直接调用,简单的调用就可以完成平时需要大量代码才能完成的操作,提高开发效率。
在使用第三方模块时,我们应当先并安装这些模块,使用pip命令就可以快速实现。例如任务中需要使用requests库中的某些方法帮助我们获取网页的内容。
请在命令行窗口中输入 pip install requests 指令,安装requests模块:
注意:pip命令需在命令行中执行,若在Python解释器环境内,则需输入 exit() 退出至linux命令行界面。
[csdn ~]$ pip install requests![]()
按下回车执行上面的代码,将在线安装requests模块,安装完成后,环境最后一行会提示以下内容。
![]()
跟我练:请尝试在右侧环境中安装requests模块。
使用requests获取访问天气信息网站
在上一个任务中已经安装了可以帮助我们访问线上地址的模块,接下来我们以模块中的一个方法为例,获取一个网络上开放的城市天气信息接口。
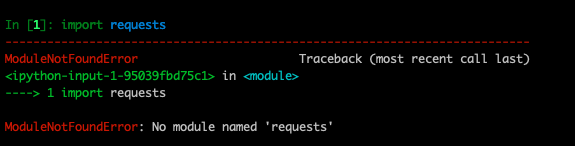
第一步,导入在上一个任务中安装的requests模块,使用import语句实现。 在命令行键入ipython 进入Python解释器环境,输入如下代码:
import requests![]()
Tips: 若运行以上代码出现如下错误,表示你未安装requests模块。requests是一个第三方模块,不是python自带的模块,需要我们自行下载,下载需要退出python环境下载,之后再python环境中调用pip install requests
![]()
第二步,导入成功后我们需要requests库中的get方法,用于请求网站的访问。
requests.get(url)![]()
其中requests.get即是调用requests库的get方法,小括号()中填写需要访问的网站地址(任务中使用北京城市天气信息的网址:http://wthrcdn.etouch.cn/weather_mini?city=北京),并用双引号或引号包住。如果访问成功,则这个requests的get方法会返回一个200的状态码表示访问成功。
我们可以用之前学会的print语句将其打印出来,判断是否访问成功。
import requests
print(requests.get('http://wthrcdn.etouch.cn/weather_mini?city=北京'))![]()
跟我练:请尝试在右侧环境中访问北京天气信息,并输出Response [200],确认访问成功。
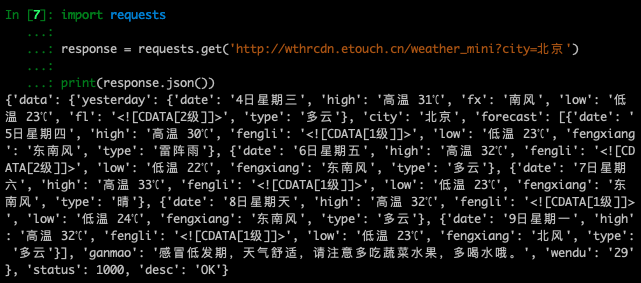
三行代码获取北京天气信息数据
通过以上任务中学会的代码,就可以访问城市天气信息网站。使用requests.get方法访问网站成功后,其实已经获得了网络请求的对象,我们把返回的对象赋值给变量response,然后使用他的json方法获取到北京的天气信息数据。
import requests
response = requests.get('http://wthrcdn.etouch.cn/weather_mini?city=北京')
print(response.json())![]()
跟我练:请在右侧环境内编写代码,并正确的输出经过json方法处理后的北京天气信息数据。
恭喜你,至此,你已经学会了爬虫的基本原理和方法,用Python三行代码,是的,仅仅三行代码,获取北京未来几天的天气数据。你可以通过短信服务接口每天早上发给你当天和未来几天的天气信息,是不是很酷
Tip:天气网站返回的是JSON格式的数据。JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。 易于人阅读和编写。同时也易于机器解析和生成。response.text可获得网页的源代码,如果网页源代码是JSON字符串,使用response. json()方法可返回解析以后的数据,他的类型是python dict,可以用 response.json()'data' 获得昨天北京的天气情况
以上代码运行输出结果如下图
关于爬虫的合法性
编写Python爬虫很容易,不过要想安全地编写Python爬虫,就需要了解更多的至少,不光是技术上的,还有法律上的,Robots协议就是其中之一,如果不了解Robots协议,抓取了不该抓取的东西,可能会面临牢狱之灾哦!
Robots协议简介
Robots协议也称作爬虫协议、机器人协议,它的全名是网络爬虫排除标准(Robots Exclusing Protocol),用来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以抓取。该协议的内容通常放在一个名为robots.txt的文本文件中,该文件一般位于网站的根目录下。
注意,robots.txt文件中的内容只是告诉爬虫应该抓取什么,不应该抓取什么,但并不是通过技术手段阻止爬虫抓取那些被禁止的资源,而只是通知爬虫而已。尽管编写爬虫可以不遵循robots.txt文件的描述,但作为一只有道德、有文化、有纪律的爬虫,应该尽量遵循robots.txt文件描述的规则。否则,有可能会引起法律纠纷。
当爬虫访问一个网站时,首先会检查这个网址根目录下是否存在robots.txt文件,如果存在,爬虫就会根据该文件中定义的抓取范围来抓取Web资源。如果这个文件并不存在,爬虫就会抓取这个网站所有可直接访问的页面。
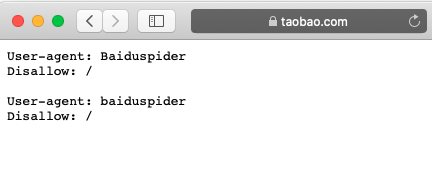
以淘宝网为例,在浏览器中访问 https://www.taobao.com/robots.txt,如下图所示
![]()
Baiduspider是百度搜索引擎的爬虫程序,这里的意思是不允许百度爬虫爬取淘宝的任何数据。 我们上个任务中的天气信息网站是没有定义robots.txt文件的,所以我们可以合法的爬取他的数据。
![]()
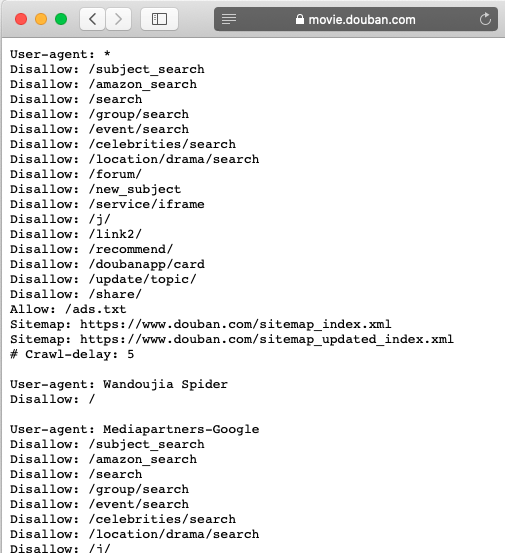
由于我们下个任务要爬取豆瓣电影的榜单数据,我们看一下豆瓣电影的的robots文件,如下图。榜单地址/top250没有在禁止名单里,是可以爬取的。
![]()
分析爬虫协议
Robots协议并不需要我们自己去分析,urllib库的robotparser模块提供了相应的API来解析robots.txt文件,这就是RobotFileParser类。可以用多种方式使用RobotFileParser类。例如,可以通过set_url方法设置robots.txt文件的URL,然后进行分析,代码如下:
from urllib.robotparser import RobotFileParser
robot = RobotFileParser()
robot.set_url('https://www.taobao.com/robots.txt')
robot.read()
print(robot.can_fetch('Baiduspider','https://www.taobao.com'))![]()
其中can_fetch方法用来获得该网站某一个URL根据Robots协议是否有权抓取,如果可以抓取,返回True,否则返回False。
您可以在python环境中运行上面的代码,代码输出是False,表示百度爬虫是不能爬取淘宝网站的。
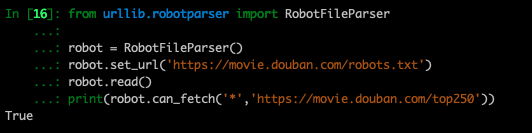
跟我练:请尝试在右侧环境中用代码来判断,豆瓣电影榜单网页地https://movie.douban.com/top250 ,是否可以被爬取,并打印出结果。
以下是参考代码
![]()