系列文章目录
MySQL(一)——索引底层数据结构与算法
MySQL(二)——Explain详情与索引最佳实践
MySQL(三)——MySQL的内部组件结构及bin-log归档
MySQL(四)——MySQL索引优化实战
MySQL(五)——MySQL索引优化实战(多表联查优化)
MySQL(六)——深入理解MySQL事务隔离级别与锁机制
MySQL(七)——深入理解MVCC与BufferPool缓存机制
MySQL索引优化实战(多表联查优化)
实例SQL
CREATE TABLE `employees` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) NOT NULL DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`position` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`hire_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`),
KEY `idx_name_age_position` (`name`,`age`,`position`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
分页查询优化
select * from employees limit 10000,10;
从表 employees 中取出从 10001 行开始的 10 行记录。看似只查询了 10 条记录,实际这条 SQL 是先读取 10010 条记录,然后抛弃前 10000 条记录,然后读到后面 10 条想要的数据。因此要查询一张大表比较靠后的数据,执行效率是非常低的。
- 1、根据自增且连续的主键排序的分页查询
explain select * from employees limit 90000,5;
explain select * from employees where id > 90000 limit 5;


结论:优化后的SQL 走了索引,而且扫描的行数大大减少,执行效率更高。
这种改写得满足以下两个条件:
主键自增且连续
结果是按照主键排序的
- 2、根据非主键字段排序的分页查询
explain select * from employees ORDER BY name limit 90000,5;
explain select * from employees e inner join (select id from employees order by name limit 90000,5) ed on e.id = ed.id;

发现并没有使用 name 字段的索引(key 字段对应的值为 null),具体原因:扫描整个索引并查找到没索引的行(可能要遍历多个索引树)的成本比扫描全表的成本更高,所以优化器放弃使用索引。

其实关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录。
原 SQL 使用的是 filesort 排序,而优化后的 SQL 使用的是索引排序。
Join关联查询优化
-- 插入一些示例数据
-- 往t6表插入1万行记录
drop procedure if exists insert_t6;
delimiter ;;
create procedure insert_t6()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t6(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t6();
-- 往t7表插入100行记录
drop procedure if exists insert_t7;
delimiter ;;
create procedure insert_t7()
begin
declare i int;
set i=1;
while(i<=100)do
insert into t7(a,b) values(i,i);
set i=i+1;
end while;
end;;
delimiter ;
call insert_t7();
mysql的表关联常见有两种算法
Nested-Loop Join 算法
Block Nested-Loop Join 算法
1、 嵌套循环连接 Nested-Loop Join(NLJ) 算法
一次一行循环地从第一张表(称为驱动表)中读取行,在这行数据中取到关联字段,根据关联字段在另一张表(被驱动表)里取出满足条件的行,然后取出两张表的结果合集。
EXPLAIN select * from t6 inner join t7 on t6.a= t7.a;

从执行计划中可以看到这些信息:
- 1.驱动表是 t7,被驱动表是 t6。先执行的就是驱动表(执行计划结果的id如果一样则按从上到下顺序执行sql);优化器一般会优先选择小表做驱动表,用where条件过滤完驱动表,然后再跟被驱动表做关联查询。所以使用 inner join 时,排在前面的表并不一定就是驱动表。
- 2.当使用left join时,左表是驱动表,右表是被驱动表,当使用right join时,右表时驱动表,左表是被驱动表,当使用join时,mysql会选择数据量比较小的表作为驱动表,大表作为被驱动表。
- 3.使用了 NLJ算法。一般 join 语句中,如果执行计划 Extra 中未出现 Using join buffer则表示使用的 join 算法是 NLJ。
上面sql的大致流程如下:
从表 t7 中读取一行数据(如果t7表有查询过滤条件的,用先用条件过滤完,再从过滤结果里取出一行数据);
从第 1 步的数据中,取出关联字段 a,到表 t6 中查找;
取出表 t6 中满足条件的行,跟 t7 中获取到的结果合并,作为结果返回给客户端;
重复上面 3 步。
整个过程会读取 t7 表的所有数据(扫描100行),然后遍历这每行数据中字段 a 的值,根据 t7 表中 a 的值索引扫描 t6 表中的对应行(扫描100次 t6 表的索引,1次扫描可以认为最终只扫描 t6 表一行完整数据,也就是总共 t6 表也扫描了100行)。因此整个过程扫描了 200 行。
如果被驱动表的关联字段没索引,使用NLJ算法性能会比较低(下面有详细解释),mysql会选择Block Nested-Loop Join算法。
2、 基于块的嵌套循环连接 Block Nested-Loop Join(BNL)算法
把驱动表的数据读入到 join_buffer 中,然后扫描被驱动表,把被驱动表每一行取出来跟 join_buffer 中的数据做对比。
EXPLAIN select * from t6 inner join t7 on t6.b= t7.b;

Extra 中 的Using join buffer (Block Nested Loop)说明该关联查询使用的是 BNL 算法。
上面sql的大致流程如下:
- 1.把 t7 的所有数据放入到 join_buffer 中
- 2.把表 t6 中每一行取出来,跟 join_buffer 中的数据做对比
- 3.返回满足 join 条件的数据
整个过程对表 t6 和 t7 都做了一次全表扫描,因此扫描的总行数为10000(表 t6 的数据总量) + 100(表 t7 的数据总量) = 10100。并且 join_buffer 里的数据是无序的,因此对表 t6 中的每一行,都要做 100 次判断,所以内存中的判断次数是 100 * 10000= 100 万次。
这个例子里表 t7 才 100 行,要是表 t7 是一个大表,join_buffer 放不下怎么办呢?·
join_buffer 的大小是由参数 join_buffer_size 设定的,默认值是 256k。如果放不下表 t7 的所有数据的话,策略很简单,就是分段放。
比如 t7 表有1000行记录, join_buffer 一次只能放800行数据,那么执行过程就是先往 join_buffer 里放800行记录,然后从 t6 表里取数据跟 join_buffer 中数据对比得到部分结果,然后清空 join_buffer ,再放入 t7 表剩余200行记录,再次从 t6 表里取数据跟 join_buffer 中数据对比。所以就多扫了一次 t6 表。
被驱动表的关联字段没索引为什么要选择使用 BNL 算法而不使用 Nested-Loop Join 呢?
如果上面第二条sql使用 Nested-Loop Join,那么扫描行数为 100 * 10000 = 100万次,这个是磁盘扫描。
很显然,用BNL磁盘扫描次数少很多,相比于磁盘扫描,BNL的内存计算会快得多。
因此MySQL对于被驱动表的关联字段没索引的关联查询,一般都会使用 BNL 算法。如果有索引一般选择 NLJ 算法,有索引的情况下 NLJ 算法比 BNL算法性能更高
对于关联sql的优化
- 关联字段加索引,让mysql做join操作时尽量选择NLJ算法,驱动表因为需要全部查询出来,所以过滤的条件也尽量要走索引,避免全表扫描,总之,能走索引的过滤条件尽量都走索引
- 小表驱动大表,写多表连接sql时如果明确知道哪张表是小表可以用straight_join写法固定连接驱动方式,省去mysql优化器自己判断的时间
straight_join解释:straight_join功能同join类似,但能让左边的表来驱动右边的表,能改表优化器对于联表查询的执行顺序。
比如:select * from t2 straight_join t1 on t2.a = t1.a; 代表指定mysql选着 t2 表作为驱动表。
straight_join只适用于inner join,并不适用于left join,right join。(因为left join,right join已经代表指定了表的执行顺序)
尽可能让优化器去判断,因为大部分情况下mysql优化器是比人要聪明的。使用straight_join一定要慎重,因为部分情况下人为指定的执行顺序并不一定会比优化引擎要靠谱。
对于小表定义的明确
在决定哪个表做驱动表的时候,应该是两个表按照各自的条件过滤,过滤完成之后,计算参与 join 的各个字段的总数据量,数据量小的那个表,就是“小表”,应该作为驱动表。
in和exsits优化
原则:小表驱动大表,即小的数据集驱动大的数据集
in:当B表的数据集小于A表的数据集时,in优于exists
select * from A where id in (select id from B)
#等价于:
for(select id from B){
select * from A where A.id = B.id
}
exists:当A表的数据集小于B表的数据集时,exists优于in
将主查询A的数据,放到子查询B中做条件验证,根据验证结果(true或false)来决定主查询的数据是否保留
select * from A where exists (select 1 from B where B.id = A.id)
#等价于:
for(select * from A){
select * from B where B.id = A.id
}
#A表与B表的ID字段应建立索引
1、EXISTS (subquery)只返回TRUE或FALSE,因此子查询中的SELECT * 也可以用SELECT 1替换,官方说法是实际执行时会忽略SELECT清单,因此没有区别
2、EXISTS子查询的实际执行过程可能经过了优化而不是我们理解上的逐条对比
3、EXISTS子查询往往也可以用JOIN来代替,何种最优需要具体问题具体分析
count(*)查询优化
-- 临时关闭mysql查询缓存,为了查看sql多次执行的真实时间
set global query_cache_size=0;
set global query_cache_type=0;
EXPLAIN select count(1) from employees;
EXPLAIN select count(id) from employees;
EXPLAIN select count(name) from employees;
EXPLAIN select count(*) from employees;
注意:以上4条sql只有根据某个字段count不会统计字段为null值的数据行
四个sql的执行计划一样,说明这四个sql执行效率应该差不多
字段有索引:count(*)≈count(1)>count(字段)>count(主键 id)
字段有索引,count(字段)统计走二级索引,二级索引存储数据比主键索引少,所以count(字段)>count(主键 id)
字段无索引:count(*)≈count(1)>count(主键 id)>count(字段)
字段没有索引count(字段)统计走不了索引,count(主键 id)还可以走主键索引,所以count(主键 id)>count(字段)
count(1)跟count(字段)执行过程类似,不过count(1)不需要取出字段统计,就用常量1做统计,count(字段)还需要取出字段,所以理论上count(1)比count(字段)会快一点。
count( * ) 是例外,mysql并不会把全部字段取出来,而是专门做了优化,不取值,按行累加,效率很高,所以不需要用count(列名)或count(常量)来替代 count(*)。
为什么对于count(id),mysql最终选择辅助索引而不是主键聚集索引?因为二级索引相对主键索引存储数据更少,检索性能应该更高,mysql内部做了点优化(应该是在5.7版本才优化)。
常见优化方法
1、查询mysql自己维护的总行数
对于myisam存储引擎的表做不带where条件的count查询性能是很高的,因为myisam存储引擎的表的总行数会被mysql存储在磁盘上,查询不需要计算

对于innodb存储引擎的表mysql不会存储表的总记录行数(因为有MVCC机制,后面会讲),查询count需要实时计算
2、show table status
如果只需要知道表总行数的估计值可以用如下sql查询,性能很高
show table status like 'employees';
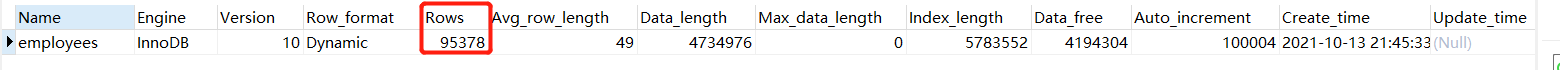
3、将总数维护到Redis里
插入或删除表数据行的时候同时维护redis里的表总行数key的计数值(用incr或decr命令),但是这种方式可能不准,很难保证表操作和redis操作的事务一致性
4、增加数据库计数表
插入或删除表数据行的时候同时维护计数表,让他们在同一个事务里操作
MySQL数据类型选择
在MySQL中,选择正确的数据类型,对于性能至关重要。一般应该遵循下面两步:
(1)确定合适的大类型:数字、字符串、时间、二进制;
(2)确定具体的类型:有无符号、取值范围、变长定长等。
在MySQL数据类型设置方面,尽量用更小的数据类型,因为它们通常有更好的性能,花费更少的硬件资源。并且,尽量把字段定义为NOT NULL,避免使用NULL。
1、数值类型
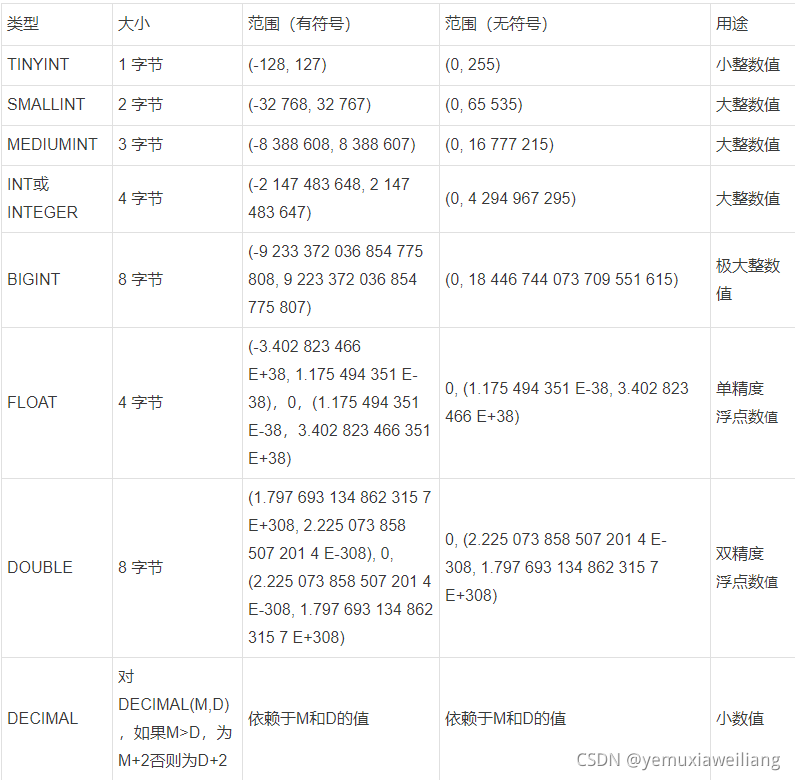
优化建议
- 1.如果整形数据没有负数,如ID号,建议指定为UNSIGNED无符号类型,容量可以扩大一倍。
- 2.建议使用TINYINT代替ENUM、BITENUM、SET。
- 3.避免使用整数的显示宽度(参看文档最后),也就是说,不要用INT(10)类似的方法指定字段显示宽度,直接用INT。
- 4.DECIMAL最适合保存准确度要求高,而且用于计算的数据,比如价格。但是在使用DECIMAL类型的时候,注意长度设置。
- 5.建议使用整形类型来运算和存储实数,方法是,实数乘以相应的倍数后再操作。
- 6.整数通常是最佳的数据类型,因为它速度快,并且能使用AUTO_INCREMENT。
2、日期和时间
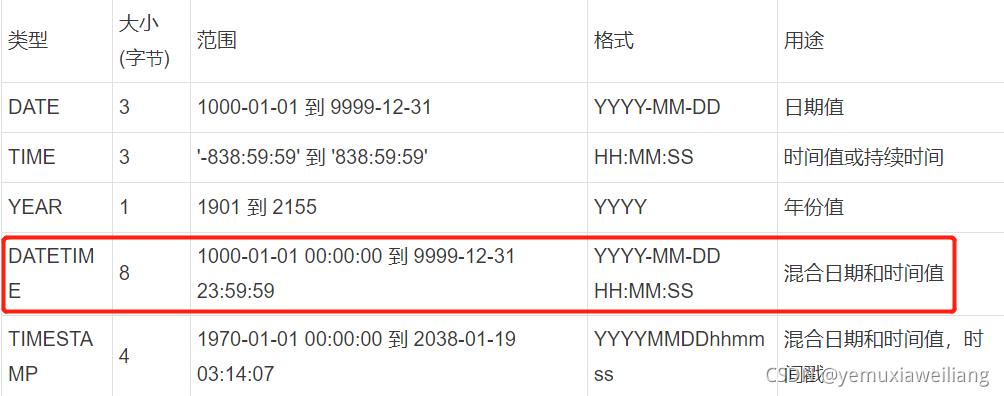
优化建议
- 1.MySQL能存储的最小时间粒度为秒。
- 2.建议用DATE数据类型来保存日期。MySQL中默认的日期格式是yyyy-mm-dd。
- 3.用MySQL的内建类型DATE、TIME、DATETIME来存储时间,而不是使用字符串。
- 4.当数据格式为TIMESTAMP和DATETIME时,可以用CURRENT_TIMESTAMP作为默认(MySQL5.6以后),MySQL会自动返回记录插入的确切时间。
- 5.TIMESTAMP是UTC时间戳,与时区相关。
- 6.DATETIME的存储格式是一个YYYYMMDD HH:MM:SS的整数,与时区无关,你存了什么,读出来就是什么。
- 7.除非有特殊需求,一般的公司建议使用TIMESTAMP,它比DATETIME更节约空间,但是像阿里这样的公司一般会用DATETIME,因为不用考虑TIMESTAMP将来的时间上限问题。
- 8.有时人们把Unix的时间戳保存为整数值,但是这通常没有任何好处,这种格式处理起来不太方便,我们并不推荐它。
3、字符串
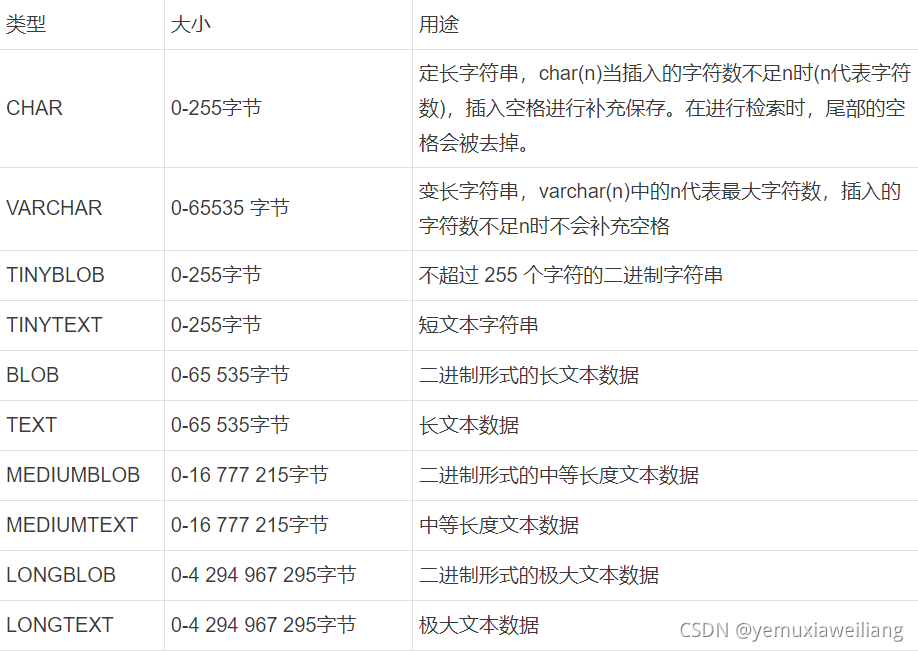
优化建议
- 1.字符串的长度相差较大用VARCHAR;字符串短,且所有值都接近一个长度用CHAR。
- 2.CHAR和VARCHAR适用于包括人名、邮政编码、电话号码和不超过255个字符长度的任意字母数字组合。那些要用来计算的数字不要用VARCHAR类型保存,因为可能会导致一些与计算相关的问题。换句话说,可能影响到计算的准确性和完整性。
- 3.尽量少用BLOB和TEXT,如果实在要用可以考虑将BLOB和TEXT字段单独存一张表,用id关联。
- 4.BLOB系列存储二进制字符串,与字符集无关。TEXT系列存储非二进制字符串,与字符集相关。
- 5.BLOB和TEXT都不能有默认值。
4.INT显示宽度
我们经常会使用命令来创建数据表,而且同时会指定一个长度,如下。但是,这里的长度并非是TINYINT类型存储的最大长度,而是显示的最大长度。
CREATE TABLE `user`(
`id` TINYINT(2) UNSIGNED
);
这里表示user表的id字段的类型是TINYINT,可以存储的最大数值是255。所以,在存储数据时,如果存入值小于等于255,如200,虽然超过2位,但是没有超出TINYINT类型长度,所以可以正常保存;如果存入值大于255,如500,那么MySQL会自动保存为TINYINT类型的最大值255。
在查询数据时,不管查询结果为何值,都按实际输出。这里TINYINT(2)中2的作用就是,当需要在查询结果前填充0时,命令中加上ZEROFILL就可以实现,如:
`id` TINYINT(2) UNSIGNED ZEROFILL
这样,查询结果如果是5,那输出就是05。如果指定TINYINT(5),那输出就是00005,其实实际存储的值还是5,而且存储的数据不会超过255,只是MySQL输出数据时在前面填充了0。
换句话说,在MySQL命令中,字段的类型长度TINYINT(2)、INT(11)不会影响数据的插入,只会在使用ZEROFILL时有用,让查询结果前填充0。