Target-driven visual navigation in indoor scenes based on deep reinforcement learning
Summary
The two less-attained problems of deep reinforcement learning are (1) lack of generalization ability for new targets, and (2) low data efficiency, that is, the model requires several (and usually expensive) trial and error to converge. This makes it unsuitable for real-world scenarios. In this article, we solve these two problems and apply our model to goal-driven visual navigation. To solve the first problem, we propose an actor-critic model whose strategy is a function of the goal and the current state, which allows for better generalization. In order to solve the second problem, we proposed the AI2-Tor framework, which provides an environment with high-quality 3D scenes and physics engines. Our framework enables agents to take actions and interact with objects. Therefore, we can effectively collect a large number of training samples.
We show that our proposed method (1) converges faster than state-of-the-art deep reinforcement learning methods, (2) is suitable for all targets and scenarios, and (3) is suitable for real robot scenes with a small amount of fine-tuning (although the model is simulating (4) is end-to-end trainable, and does not require feature engineering, inter-frame feature matching, or 3D reconstruction of the environment.
Introduction
Many tasks in robotics involve interaction with the physical environment and objects. An essential part of this interaction is to understand the correlation and causality between an agent’s actions and the environmental changes as a result of the actions. Since the 1970s, people have been trying to build a system that can understand this relationship. Recently, with the rise of deep learning models, learning-based methods have been widely popularized [1], [2].
In this article, our main research problem is how to find a given target in a space only through visual input. Successful navigation requires learning the relationship between action and environment. This makes this task very suitable for deep reinforcement learning (DRL) methods. However, general DRL methods (such as [2], [3]) are designed to learn strategies that depend only on the current state, and the target is implicitly embedded in the model parameters. Therefore, it is necessary to learn new model parameters for new targets. This is a problem because the computational cost of training DRL agents is high.
In order to achieve higher adaptability and flexibility, we have introduced a goal-driven model. Our model takes the vision task goal as input. This way we can avoid retraining for each new target. Our model learns a strategy to jointly embed the target and the current state. Essentially, the next action an agent learns to take depends on its current state and goals, not just its current state. Therefore, there is no need to retrain the model for new targets. A key intuition we rely on is that different training sets share information. For example, agents explore a common route during the training phase and receive training to find different targets at the same time. Various scenarios also share similar structure and statistics (for example, a refrigerator may be close to a microwave oven). In short, we took advantage of the fact that it is easier to learn new targets by training models for other targets.
Unfortunately, training and quantitative evaluation of DRL algorithms in real environments is often tedious. One reason is that running the system in physical space is time-consuming. In addition, it is not easy to obtain large-scale action and interaction data in a real environment through common image data collection technology. To this end, we developed the first simulation framework with high-quality 3D scenes, called Interactive House (AI2-Tor). Our simulation framework allows us to collect a large number of visual observations of actions and reactions in different environments. For example, the agent can freely navigate (ie, move and rotate) in various realistic indoor scenes, and can perform low-level and high-level interactions with objects (e.g., apply force or turn on/off microwaves).
We evaluate our method for the following tasks: (1) Goal summary, the goal is to navigate to a goal within the scene that was not used during training. (2) Scene generalization, the goal is to navigate to the goal in the scene that is not used for training. (3) A summary of the real world, we demonstrate the use of real robots to navigate to the target. Our experiments show that we are superior to the most advanced DRL methods in terms of training data efficiency. We also showed the generalized aspects of our model.
In short, we introduced a new reinforcement learning model that can be generalized between goals and scenarios. In order to learn and evaluate the reinforcement learning model, we created a simulation framework with high-quality rendering that enables the agent to interact visually. We also demonstrated real robot navigation using our model, which was generalized to the real world with a small amount of fine-tuning.
Related work
There is a lot of work on visual navigation. We provide a brief overview of some related work. Map-based navigation methods require a global map of the environment to make navigation decisions (for example, [4], [5], [6], [7]). Compared with these methods, one of the main advantages of our method is that it does not require a priori map of the environment. Another type of navigation method is to dynamically reconstruct the map and use it for navigation [8], [9], [10], [11], [12], or to construct the map through the training phase under the guidance of humans [13 ], [14]. In contrast, our method does not require environmental maps because it does not have any assumptions about environmental landmarks, and it does not require a human-guided training phase. Mapless navigation methods are also common [15], [16], [17], [18], [19]. These methods mainly focus on obstacle avoidance for a given input image. Our method is considered to be mapless. However, it possesses implicit environmental knowledge. A survey of visual navigation methods can be found in [20].
Please note that our method is not based on feature matching or 3D reconstruction, for example, unlike [21], [22]. In addition, unlike for example [23], [24], our method does not require supervised training for identifying unique landmarks
Reinforcement learning has been widely used. [25] proposed a gradient RL method for quadruped robot motion strategy. [26] Discuss the strategy gradient method of learning motion primitives. [27] proposed a method based on reverse logistics that uses a monocular camera for obstacle detection. [28] Apply reinforcement learning to automatic helicopter flight. [29] Use RL to automate the data collection process for mapping. [30] proposed a kernel-based reinforcement learning algorithm for large-scale settings. [31] Use RL to make decisions in Atari games. In contrast to these methods, our model uses deep reinforcement learning to process high-dimensional sensory input.
Recently, methods that combine deep learning methods with reverse learning have shown promising results. [2] Propose deep Q network to play Atari games. [32] proposed a new search algorithm based on the combination of Monte Carlo tree search and deep RL to defeat the world champion in the Go game. [3] proposes a deep reverse link method in which the parameters of the deep network are updated by multiple asynchronous copies of agents in the environment. [1] The original image is directly mapped to the torque of the robot motor using a deep reverse engineering method. Our work deals with inputs that are much more complex than the TARI game, or images taken in a limited laboratory background. In addition, our method can be generalized to new scenarios and new goals, and the above method should be retrained for new games, or when the rules of the game change.
Some efforts have been made to develop learning methods that can be generalized to different target tasks [33], [34]. Similar to UVFA [35], our model directly takes the target as input and does not need to be retrained.
Recently, physics engines have been used to learn the dynamics of real-world scenes from images [36], [37], [38]. In this work, we show that the model trained in simulation can be generalized to real-world scenarios.
AI2-THOR framework
In order to train and evaluate our model, we need a framework to perform actions and perceive the results in a 3D environment. Integrating our model with different types of environments is the main requirement for the generalization of our model. Therefore, this framework should have a plug-and-play architecture so that different types of scenarios can be easily combined. In addition, the framework should have a detailed physical model of the scene, so that the interaction of motion and objects can be correctly expressed.
To this end, we propose the Interaction House (AI2-Tor) framework, which is designed by combining the physics engine (unified 3D) with the deep learning framework. The general idea is that the rendered image of the physics engine is streamed to the deep learning framework, and the deep learning framework issues control commands based on visual input and sends them back to the agent in the physics engine. [39], [40], [44], [42], [41] have proposed similar frameworks, but the main advantages of our framework are as follows: (1) Physics engine and deep learning framework directly communicate (with [38 ] The separation of physics engine and controller is opposite). Direct communication is important because feedback from the environment can be used immediately for online decision-making. (2) We try to imitate the appearance distribution of real-world images as much as possible. For example, [39] is dedicated to Atari games, which is a 2D environment with limited appearance. [43] is a collection of synthetic scenes. These synthetic scenes do not have photo-realism and do not conform to the distribution of real-world scenes in terms of lighting, object appearance, texture and background clutter. This is important for images that enable us to generalize to the real world.
In order to create an indoor scene for our framework, we provided reference images to the artist to create a 3D scene with texture and lighting similar to the image. So far, we have 32 scenes, which belong to the 4 common scene types in the home environment: kitchen, living room, bedroom and bathroom. On average, each scene contains 68 object instances.
The advantage of using a physics engine to model the world is that it is highly scalable (it is not easy to stretch a robot in a real house). In addition, training models can be performed cheaper and safer (for example, robot actions may damage objects). One of the main disadvantages of using synthetic scenes is the lack of detailed modeling of the real world. However, the latest developments in the graphics community have made possible a rich representation of the appearance and physics of the real world, narrowing the difference between the real world and simulation. Figure 2 provides a qualitative comparison between the scenarios in our framework and the example scenarios in other frameworks and datasets. As shown in the figure, our scene better simulates the appearance properties of real-world scenes. In this work, we focus on navigation, but the framework can be used for more fine-grained physical interactions, such as applying force, grabbing, or object manipulation, such as turning the microwave on and off. Figure 3 shows several examples of high-level interactions. We will provide Python APIs with a framework for artificial intelligence agents to interact with 3D scenes.
Target-driven navigation model
In this section, we first define the formula for goal-driven visual navigation. Then we described the deep Siamese actor-critic network we built for this task.
A. Problem statement
Our goal is to find the minimum length action sequence that moves the agent from its current position to the target specified by the RGB image. We have developed a deep reinforcement learning model that takes an RGB image of the current observation and another RGB image of the target as input. The output of the model is an action in 3D, such as moving forward or turning right. Note that the model learns the mapping from 2D images to actions in 3D space.

B. Formula problem
Vision-based robot navigation requires mapping from sensory signals to motion commands. Previous work on reinforcement learning usually does not consider high-dimensional perceptual input [48]. The recent Deep Reinforcement Learning (DRL) model [2] provides an end-to-end learning framework that converts pixel information into actions. However, DRL is largely focused on learning specific goal models that handle individual tasks independently. This kind of training setting is quite inflexible to changing mission objectives. For example, as noted by Lake et al. [49], changing the rules of the game will have a devastating performance impact on the DRL-based Go system [32]. This limitation stems from the fact that the standard DRL model [2], [3] aims to find a direct mapping from the state representation s to the strategy π (represented by the deep neural network π). In this case, the target is hard-coded in the neural network parameters. Therefore, the change of the target needs to update the network parameters.
This limitation is particularly problematic for mobile robot navigation. When applying DRL to multiple navigation targets, the network should be retrained for each target. In fact, exhausting every target in a scene is forbidden. This is a problem caused by the lack of versatility—that is, when a new target is included, we must retrain the new model. Therefore, it is better to have a single navigation model, which learns to navigate to new targets without retraining. To this end, we specify the task target (ie, the navigation destination) as the input of the model, instead of embedding the target in the model parameters. We call this problem goal-driven visual navigation. Formally, the learning goal of the goal-driven model is to learn a random strategy function π ππ , it accepts two inputs, the representation of the current state represents the representation of the target g, and in the action spaceπ (st, g) π(s_t, g)π ( st, G ) produces a probability distribution. For testing, the mobile robot continues to take actions in the strategy distribution until it reaches the destination. In this way, the action depends on the state as well as the goal. Therefore, there is no need to retrain for new targets.

C. Learning settings
Before introducing our model, we first describe the key elements of reinforcement learning settings: action space, observation and goals, and reward design.
1) Action space: Real-world mobile robots have to deal with low-level mechanics. However, these mechanical details make learning more challenging. A common approach is to learn at a certain level of abstraction, where the underlying physics is handled by a lower-level controller (for example, a 3D physics engine). We train our model with command-level actions. For our visual navigation task, we consider four actions: forward, backward, turn left, and turn right. We use a constant step size (0.5 meters) and rotation angle (90 degrees). This essentially discretizes the scene space into a grid world representation. In order to simulate the uncertainty in real-world system dynamics, we add Gaussian noise to the step size N (0, 0.01) and turn N (0, 1.0) of each position.
2) Observation and target: Both the observation and target are the images taken by the proxy RGB camera in its first-person view. The advantage of using images as target descriptions is that new targets can be specified flexibly. Given a target image, the task goal is to navigate to the location and viewpoint where the target image was taken.
3) Reward design: We focus on minimizing the length of the trajectory to the navigation target, although other factors such as energy efficiency can also be considered. We only provide a reward (10.0) for reaching the goal when the task is completed. To encourage shorter trajectories, we added a small time penalty (-0.01) as an instant reward.
D. Model
We focus on learning the goal-driven strategy function π through deep reinforcement learning. We design a new deep neural network as a nonlinear function approximator of π, where the action a at time t can be drawn by the following formula:
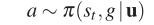
where u is the model parameter, st s_tstIs the currently observed image, and g is the image of the navigation target. When the target g belongs to a finite discrete set, π can be regarded as a mixed model, where g is the correct parameter set for each target index. However, the number of targets in the real world is often countless (due to many different positions or highly variable object appearances). Therefore, it is best to learn to transform the target into a projection into the embedding space. This projection allows knowledge to be transferred in this embedding space, thus allowing the model to be generalized to new goals.
Navigation decisions need to understand the relative spatial position between the current position and the target position, as well as the overall feeling of the scene layout. We developed a new in-depth siamese actor-critic network to capture this intuition. Figure 4 illustrates our goal-driven navigation task model. In general, the input to the network is two images, representing the agent's current observations and goals. The way we reason about the spatial arrangement between the current position and the target is to project them into the same embedding space, where their geometric relationship is preserved. Deep Siamese Network is a two-stream neural network model for distinguishing embedded learning [50]. We use the Siamese laminar flow shared by two weights to transform the current state and target into the same embedding space. The information from the two embeddings is fused to form a joint representation. This joint representation is delivered through scene-specific layers (see Figure 4). The purpose of having a scene-specific layer is to capture the special features of the scene (for example, room layout and object arrangement) that are essential for navigation tasks. Finally, the model produces policy and value output similar to the dominant actor-critician model [3]. In this model, all targets in the scene share the same common Siamese layer, and all targets in the scene share the same scene-specific layer. This allows the model to better generalize between the target and the scene.
E. Training protocol
The traditional reverse learning model learns individual tasks in separation, which leads to inflexibility in target changes. Since our deep actor-critic network shares the parameters of different tasks, it can benefit from learning multiple goals at the same time. A3C [3] is a reinforcement learning model that learns by running multiple copies of training threads in parallel and updates a set of shared model parameters in an asynchronous manner. It has been shown that these parallel training threads are mutually stable and achieve the most advanced performance in the field of video games. We use a training protocol similar to A3C. However, each thread runs a different navigation target, rather than running a copy of the game. Therefore, the gradient is backpropagated from the actor-critic output back to the lower layers. Scene-specific layers are updated by the gradual changes of navigation tasks in the scene, and general Siam layers are updated by all targets.
F. Network architecture
The bottom of the Siam layer is the imagenet pretreated Resnet-50[51] layer (the softmax layer is truncated), which produces 2048-d features on the 224×224×3 RGB image. We freeze these ResNet parameters during training. We connect the characteristics of 4 historical frames to illustrate the past actions of the agent. The 8192-d output vectors of these two streams are projected into the 512-d embedding space. The fusion layer adopts 1024-d cascaded embedding of state and target to generate 512-d joint representation. This vector further passes through two fully connected scene-specific layers to produce 4 strategy outputs (ie action probabilities) and a single value output. We use a shared RMSProp optimizer with a learning rate of 7×104 to train this network.
experiment
The main goal of our goal-driven navigation is to find the shortest trajectory from the current position to the goal. We first evaluate our model with a baseline navigation model based on heuristics and standard deep learning models. One of the main advantages of our proposed model is that it can be generalized to new scenarios and new goals. We conducted two other experiments to evaluate the ability of our model to transfer knowledge across goals and scenarios. In addition, we show the expansion of our model to continuous space. Finally, we use a real robot to demonstrate the performance of our model in a complex real environment.
A. Navigation results
We implemented our models in Tensorflow [47] and trained them on NVIDIA GeForce GTX Titan X GPU. We follow the training protocol described in Section 12. In order to train our deep Siamese actor-critic model with 100 threads (see Figure 4), each thread learns for a different goal. It takes about 1.25 hours to pass one million training frames on all threads. We report performance as the average number of steps (ie average trajectory length) required to reach the goal from a random starting point. Navigation performance is reported on 100 different targets randomly sampled from 20 indoor scenes in our dataset. We compare the final model with heuristic strategies, standard deep learning models, and variants of our model. The models we compare are:
-
Random walk is the simplest navigation heuristic. In this baseline model, the agent randomly selects one of the four actions at each step.
-
The shortest path provides the upper limit performance for our navigation model. Because we use a constant step length to separate the walking space (see Section 12). We can calculate the shortest path from the starting position to the target position. Please note that in order to calculate the shortest path, we can access the complete map of the environment, and the input to our system is just an RGB image.
-
A3C [3] is an asynchronous dominant actor-critic model that achieves the most advanced results in Atari games. The experimental results show that using more threads can improve the data efficiency in the training process. Therefore, we evaluate the A3C model in two settings, where we use 1 thread and 4 threads for training for each target.
-
Step Q [3] is an asynchronous variant of deep Q network [2].
-
The goal-driven single branch is a variant of our deep Siam model, which has no scene-specific branches. In this case, all targets will use and update the same scene-specific parameters, including two Fibre Channel layers and a policy/value output layer.
-
The goal-driven final is the in-depth Siamese actor-critic model we launched at Sec.
For all learning models, we report their performance after training for 100M frames (across all threads). Performance is measured by the average trajectory length (ie, the number of steps taken) of all targets. When the agent reaches the goal, or after 10,000 steps, the episode ends. For each target, we randomly initialize the starting position of the agent and evaluate 10 episodes. The results are listed in Table 1

We use the learning curve in Figure 5 to analyze the data efficiency of several deep RL models. Q-learning converges slowly. A3C performs better than Q-learning; in addition, increasing the number of learning threads per target participant from 1 to 4 can improve learning efficiency. The target-driven navigation model we proposed is significantly better than the standard depth RL model in 100-meter frame training. We hypothesize that this is because both the cross-target weight distribution scheme and the asynchronous training protocol help to learn generalizable knowledge. In contrast, specially constructed RL models are less data efficient because there is no simple mechanism to share information across different scenarios or goals. The average trajectory length of the final model is three times shorter than that of the single-branch model. It proves that the use of scene-specific layers is reasonable because it captures specific features of the scene, which may differ between scene instances.

To understand what the model learned, we examined the embeddings learned by the universal Siam layer. Figure 6 shows the t-SNE visualization of embedding vectors calculated from observations at different locations in four different directions [52]. We observe that there is a significant spatial correspondence between the spatial arrangement of these embedding vectors and their corresponding t-SNE projections. Therefore, we assume that the model learns to project the observation images into the embedding space while preserving their spatial configuration. In order to verify this hypothesis, we compared the embedded distance of the paired projections with the distance of their corresponding scene coordinates. The Pearson correlation coefficient is 0.62, and the p value is less than 0.001, indicating that the embedding space retains the information of the original position of the observation. This means that the model learns a rough map of the environment and has the ability to locate relative to the map.

B. Cross-target summary
In addition to the data efficiency of the goal-driven RL model, it also has a built-in generalization ability, which is a significant advantage over a specially constructed baseline model. We evaluate its generalization ability from two aspects: 1. Promote to the new target in the scene. Promote to new scenes. We focus on cross-objective generalizations in this section, and explain scenario generalizations in the next section.
We test the model to navigate to the new target. These targets are not trained, but they may share a common route with trained targets, allowing knowledge transfer. We selected the 10 largest scenes in the dataset, and each scene has about 15 targets. We use our goal-driven model to gradually increase the number of training goals (from 1, 2, 4 to 8). All models are trained with 20M frames. During the test, we ran 100 episodes for each of the 10 new targets. These new targets are randomly selected from a set of positions with a constant distance (1, 2, 4, and 8 steps) from the nearest training target. The result is shown in Figure 7. We use the success rate (the percentage of trajectories shorter than 500 steps) to measure performance. We chose this indicator because of the bipolar behavior of our model on the new goal-it will either reach the new goal quickly or fail completely. Therefore, this metric is more effective than the average track length. In Figure 7, we observe a trend of increasing success rate as the number of training targets (x-axis) increases. In each histogram group, the success rate is positively correlated with the adjacency between the training target and the new target. It shows that the model has a clearer understanding of the neighboring area around the training target than the distance.

C. Cross-scene summary
We further evaluated the ability of our model to generalize scenes. Since common Siamese layers are shared in all scenes, we examined the possibility of transferring knowledge from these layers to new scenes. In addition, we studied how the number of training scenarios will affect the transferability of the general layer parameters. We gradually increased the number of training scenes from 1 to 16, and tested on 4 invisible scenes. We randomly select 5 targets from each scene for training and testing. In order to adapt to the invisible scene, we train the scene-specific layer while repairing the ordinary Siamese layer. Figure 8 shows the result. As the number of training scenarios increases, we observe faster convergence. Compared with training from scratch, transferring the general-purpose layer significantly improves the data efficiency of learning in the new environment. We also evaluate the single-branch model in the same setting. Since a single branch model includes a single scene-specific layer, we can apply the trained model (trained on 16 scenes) to a new scene without additional training. However, this resulted in worse performance than accidental, indicating the importance of adapting to specific layers of the scene. The single-branch model converges slightly faster than training from scratch, but much slower than our final model.

D. Continuous space
Spatial discretization eliminates the need to deal with complex system dynamics, such as noise in motor control. In this section, we show the empirical results that the same model can cope with more challenging continuous spaces.
To illustrate this point, we trained the same goal-driven model for the task of finding a door in a large living room scene. The goal is to reach the balcony through a door. We used the same 4 actions as before (see Section 10). IV-C); However, the movement and steering of the agent is controlled by the physics engine. In this case, the method should explicitly handle forces and collisions, because the agent may be blocked by obstacles or slide along heavy objects. Although this setting requires more training frames (about 50M) to train a single target, the same model requires an average of 15 steps to reach the door, while a random agent requires an average of 719 steps. We provide a sample test set in the video.
E. Robot experiment
In order to verify the versatility of our method for real-world settings, we conducted experiments using the SCITOS mobile robot modified by [53] (see Figure 9). We train our model in three different environments: 1) train on real images from scratch; 2) train only scene-specific layers, while freezing the general layer parameters trained on 20 simulated scenes; and 3) Training scene specific layer and fine-tuning general layer parameters.

We train our model on 28 discrete locations in the scene (backward motion disabled), which are approximately 30 inches apart from each other in each dimension. At each position, the robot uses the head camera to take 4 RGB images (90-degree intervals). During the test, the robot moves and rotates according to the predictions of the model. We evaluate a robot with two goals in the room: the door and the microwave oven. Although the model is trained on a discretized space, it is robust to random starting points, noise dynamics, changing step lengths, lighting and object layout changes, etc. A sample test set is provided in the video. Due to the small scale of the real scene, all three settings converged to a near-optimal strategy. However, we found that parameter transfer and fine-tuning from simulation to real data provided the fastest convergence of these three settings (44% faster than training from scratch). This provides supporting evidence for the value of simulation in learning real-world interactions and demonstrates the possibility of generalizing from simulation to real images with a small amount of fine-tuning.
in conclusion
We propose a deep reinforcement learning (DRL) framework for goal-driven visual navigation. The most advanced DRL methods are usually applied to video games and environments that do not simulate natural image distribution. This work is a step towards a more realistic setting.
The state-of-the-art DRL method has some limitations that make it impossible to apply in real-world environments. In this work, we have resolved some of these limitations. We solve the cross-target and cross-scenario generalization problem, improve data efficiency compared with the most advanced DRL methods, and provide the AI2-Tor framework, which can collect action and interaction data cheaply and efficiently.
Our experiments show that our method is suitable for new targets and scenarios that are not used in the end-to-end training of the model. We also show that our method converges with fewer training samples compared to the state-of-the-art DRL method. In addition, we proved that the method is effective in both discrete and continuous domains. We also show that models trained in simulation can be adapted to real robots with a small amount of fine-tuning. The visualization we provide shows that our DRL method implicitly performs positioning and mapping. Finally, our method is end-to-end trainable. Unlike common visual navigation methods, it does not require explicit feature matching or 3D reconstruction of the environment.
Our future work includes increasing the number of high-quality 3D scenes in the framework. We also plan to evaluate our model in a more distant and dynamic environment, and build models to learn physical interactions and object operations in the framework.