Converting jupyter to pdf is very simple. It is nothing more than installing pandoc, then installing the MikTex.exe program, setting the MikTexPATH environment variable, opening jupyter and then clicking on the conversion will pop up a window asking you to install the macro package, and then check the background silent installation. Then restart jupyter and convert the pdf. However, there is no Microsoft character support for windows added by default (that is, the character set cannot be recognized by the MikTex program), that is, the Chinese in jupyter cannot be converted to pdf.
Do you have to issue a command to convert it every time? ? ? No, there is a once and for all method below.
1. Locate the context of Anaconda3\Lib\site-packages\nbconvert\templates\latexthe path. In the case of virtual environment, enter the virtual environment path first. Under Anaconda, it is usually Anaconda3\envs\虚拟环境名称+ Lib\site-packages\nbconvert\templates\latex
2. base.tplx input code to solve the Chinese problem:
base.tplx file is inserted after ((* block packages *)):
\usepackage{
fontspec, xunicode, xltxtra}
\setmainfont{
Microsoft YaHei}
\usepackage{
ctex}
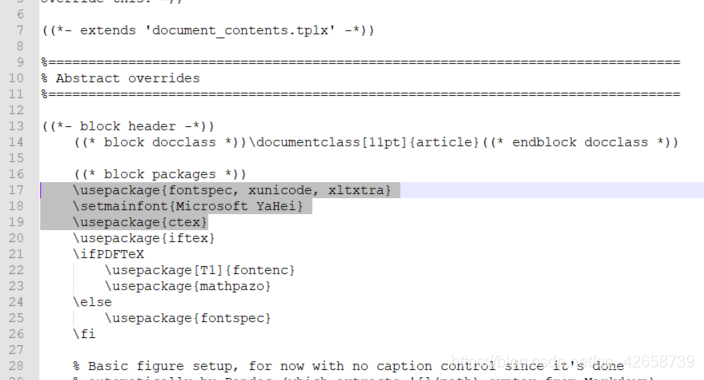
After adding, the normal output of Chinese PDF: The
following figure is my previous draft of Likou, with two sentences in Chinese, and the normal output is pdf:
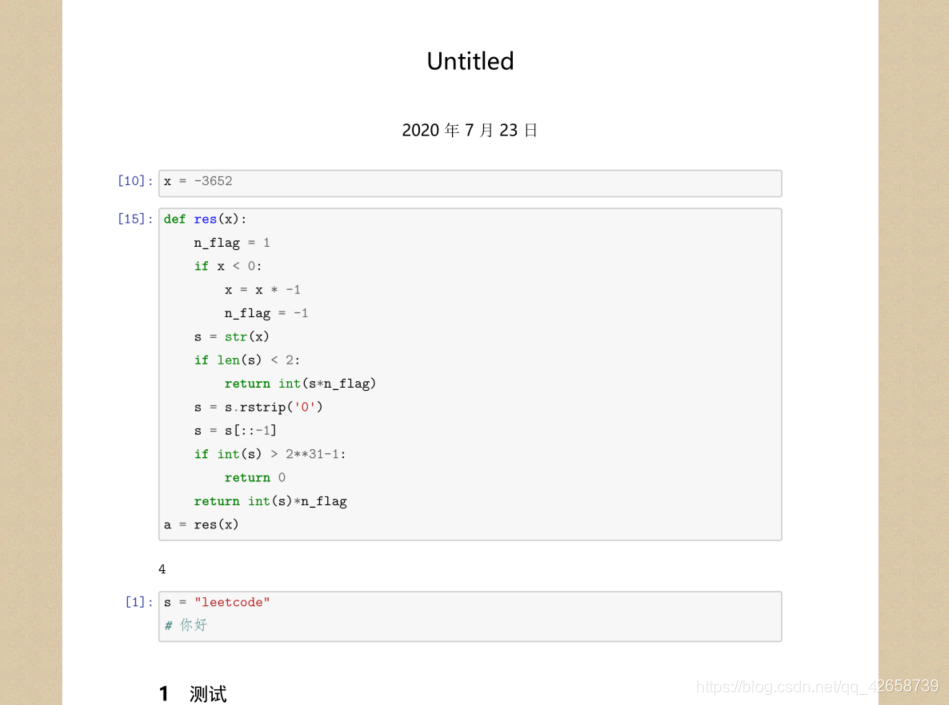
In addition: install the Jupyter plugin:
pip install jupyter_contrib_nbextensions
jupyter contrib nbextension install --user
pip install jupyter_nbextensions_configurator
jupyter nbextensions_configurator enable --user
jupyter nbextension enable codefolding/main