In this article, we started to talk about the related content of the spike architecture. The spike architecture can be said to be a very comprehensive scenario, and the interviewer particularly likes to ask questions based on this scenario, so it is necessary to understand it well.
Before we officially start, let's review the content of the previous articles.
In the fifth chapter, we talked about caching. We first store the data in the cache. Each request reads the data through the cache, which greatly reduces the pressure of database read requests. In the sixth article, we talked about the write cache. When the traffic is peaking, we first write the data into the cache, and then gradually move the data to the database, which greatly reduces the pressure of database write requests. In the seventh article, we talked about data collection. Using message queues, we can move the data in the cache to the database. The architecture design ideas involved in these articles will be used in this article.
One, business scenario seven
There is a seckill event, which provides 100 special products (commodity prices are very low) for users to officially start the seckill at 22:10:0 on October 10th.
At that time, the platform had accumulated tens of millions of users, and hundreds of thousands of users were expected to be interested in this special offer. According to the tonality of the spike activity, the specials will generally be robbed within 1-2 seconds, and the flow in the remaining time can only see the spike end interface, so we predict that there will be an instant when the spike is turned on Peak traffic.
This is also a short-lived event. You can't add too many servers or spend too much time on refactoring. To put it bluntly, it means you need to get this spike activity with the least technical cost.
Therefore, the design goal of our spike architecture this time is to make minor changes to ensure that the torrent of traffic at the spike time will not overwhelm the server.
For the design of the spike architecture, the difficulty lies in the fact that there are too many monks. Therefore, when designing the spike architecture, it is generally necessary to follow that things cannot be oversold, successful order data cannot be lost, servers and databases cannot be linked, and try not to allow robots to steal products. 4 principles.
How to achieve these 4 principles? Let's start with the overall idea.
2. Overall thinking
In fact, the design scheme of the spike architecture is a process of constantly filtering requests. From the perspective of system architecture, the hierarchical design idea of the spike system is shown in the following figure:
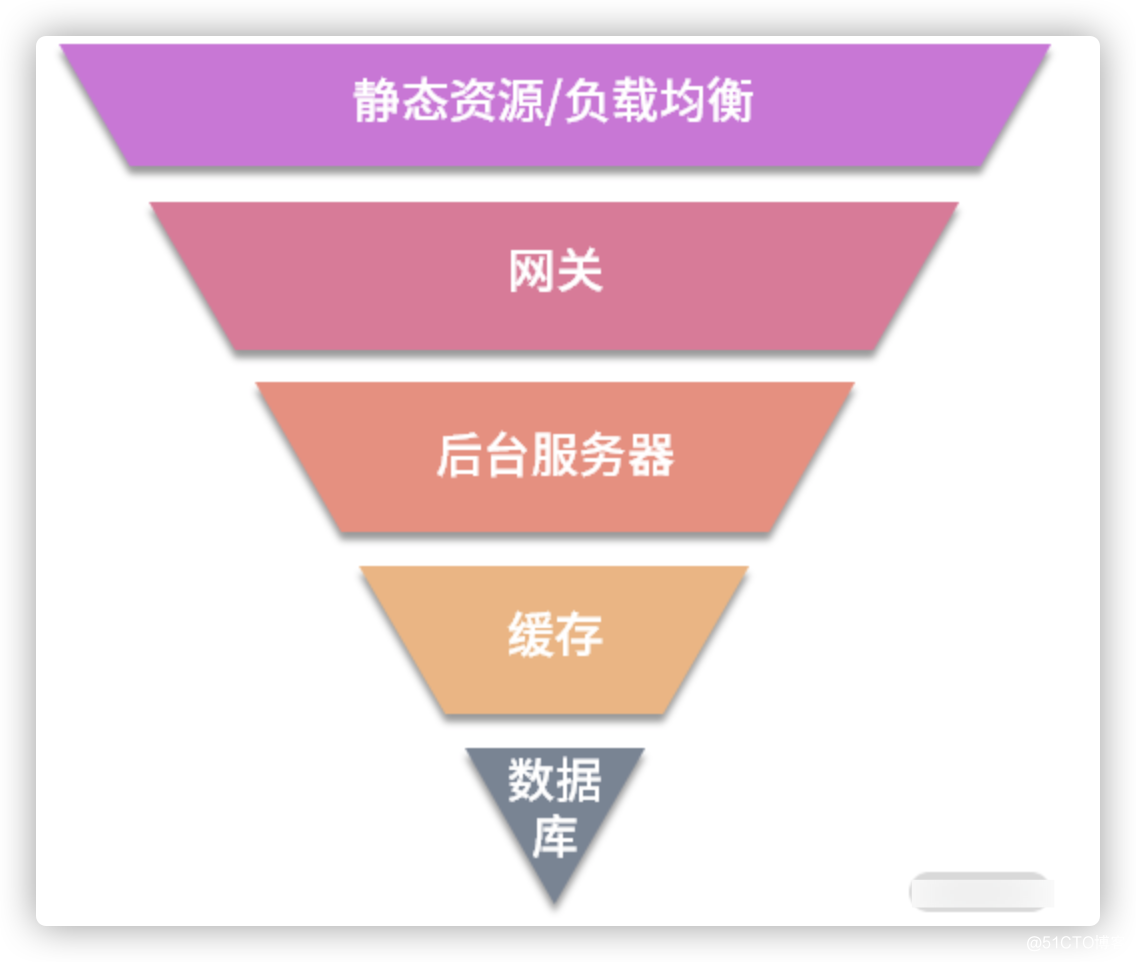
As you can see in the above figure, the architectural design goal of the spike system is to try to handle the user's request at the upper level and prevent it from swimming down. How to achieve it?
Since the entire spike system involves multiple user operation steps, when solving the problem of how to intercept the request at the upper level of the system, we need to combine the actual business process and take each user's operation step into consideration.
In order to facilitate understanding, we use a picture to describe the specific business process of the spike system, as shown in the following figure: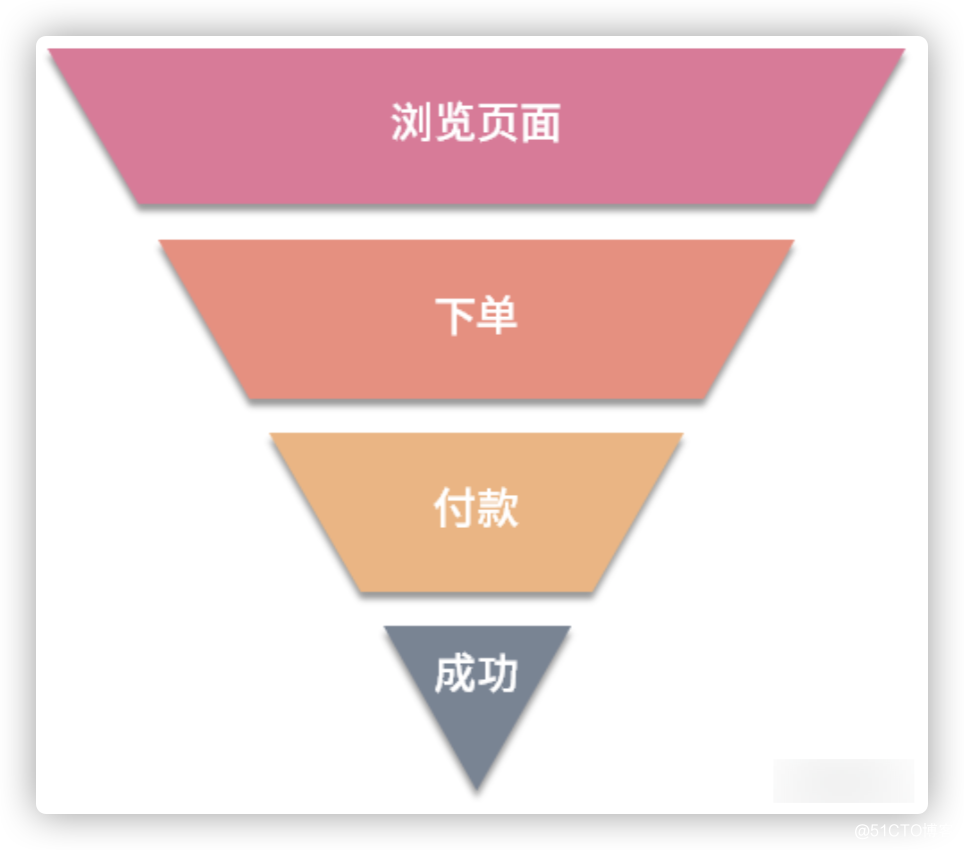
Next, we follow the business process of the spike architecture system to explain step by step how to intercept the request upstream of the system.
(1) How to block the request upstream when browsing the page?
In the past experience of the spike system architecture, there has been such a moth: At that time, we took all aspects of the system into consideration. After checking, we felt very good, but when the activity went online, the system immediately showed abnormality. After a check, we It was found that the performance indicators of all servers were okay, except that the export bandwidth had a problem. (It is full)
As a result, everyone knows that there was a serious freeze on the page when participating in the event, and users continued to complain.
Through this painful experience, we have made relevant adjustments to our design thinking. In the later stage, we can use CDN for static resources. If it involves a PC website, the front and back ends must be separated first, and then the CDN can be used for static resources.
Seeing this, it is necessary for us to first understand what a CDN is.
For example, the request we usually visit is https://static.resource.xx/1.jpg.
This address points to our own server. After transformation, we will resolve the domain name static.resouce.xx to the CDN service provider. Because CDN service providers have servers all over the country, the servers store the cache of static resources we want. After CDN receives this domain name, it will first find a server with the fastest response and point to the IP of this server. (In general, this is the case. If you are interested in the details, you can leave a message to tell me, we will introduce it with an article. Pay attention to the official account: select the server technology and leave a message)
Therefore, the advantage of using CDN is that it does not waste its own server resources and bandwidth, and the response speed is fast. In this way, we can intercept the pressure of static resources outside the system hierarchy.
What if it is a dynamic request? There are three implementation methods as follows.
- For example, requests for comments, product attribute details, and number of purchases are usually called dynamically through the JS background. In this scenario, we can integrate dynamic data with the page, such as turning the detail page of each spike product into a static page, and then put it into the CDN. If the transformation is too large, we can also put it in the Redis cache, but I prefer CDN.
- Judge the server time to enable the seckill logo: Generally, there is a JS in the page, which obtains the server time by accessing the server, and then turns on the seckill order button based on the time, that is, when the seckill is judged to start, we will set the order button to be available for purchase. For this request to obtain server time, we can put it on the static resource or load balancing layer, so that user requests will not enter the downstream of the system.
- Judging the result of the spike: Our approach is to put the mark of the end of the spike in the cookie. If there is no end mark in the cookie, the request will go to the backend server. The backend server judges that there is no end mark in the local memory and it will enter the cache. If it is in the cache There is no end sign, which means that the spike is not over.
In general, for user behavior when browsing pages, we need to intercept user requests as much as possible on the CDN, static resources, or load balancing side. It is impossible to intercept them in the cache.
(2) How does the order page intercept the request upstream?
When the user enters the order page, it is mainly divided into two operation actions: enter the order page and submit the order. Let's talk about how to intercept requests in the upstream of the system in these two links.
(1) Enter the order page
In order to prevent others from crawling the order page information through the crawler, which will increase the pressure on the server, we need to do the following two layers of protection in the order page to prevent (malicious) requests from being submitted repeatedly.
- Page URL background dynamic acquisition: According to the normal activity design process, users can only enter the order page after the spike activity is started, but it is inevitable that peers will directly obtain the order page URL and refresh it continuously before the activity starts, so malicious requests will be made. Went to the background server. Although the backend server can also intercept malicious requests, it adds a lot of pressure. At this time, we mainly use a weird URL for processing. (We don't put it in a static page, but get it dynamically through the background.) Earlier we introduced that JS can be used to determine the start time of the spike. Once the spike time is up, it can obtain the URL through another request.
- The user clicks the purchase button on the order page to directly disable, so we also need to prevent users from constantly clicking the purchase button.
(2) Order submission
The focus of the spike system architecture solution is order submission, because the order submission step is the most complicated, and the other steps are only the logic of page display. It is not difficult to use cache or CDN to deal with high concurrency problems.
Therefore, in the order submission link, we must do everything possible to filter out some unnecessary requests in each layer of the system.
Gateway level filtering request
For the system, if we can intercept user requests at the gateway level, it can be said that this solution is very cost-effective. If more than 95% of requests can be filtered at this level, the entire system will be very stable.
How to implement request filtering at the gateway level? Here I share three ways.
- Limit the frequency of access for each user: for example, place an order every 5 seconds.
- Limit the frequency of access to each IP: In this way, we worry that some people will automatically place orders through robots, so we will kill real users by mistake.
- Intercept a percentage of requests within a period of time, or only allow a certain number of requests to enter the background server. (Here we can use flow-limiting leaky bucket or token algorithm, which will be expanded in detail in a later article)
Backend server filtering request
After the request enters the backend server, our goal is not how to filter the request, but how to ensure that the specials are not oversold, and how to ensure the accuracy of the order data of the specials.
How to implement it? We can use the following three ways.
- Commodity inventory is placed in the cache : If every request goes to the database to query the commodity inventory, the database will definitely not be able to carry it, so we need to store the inventory in the cache, so that every time the user places an order, first use decr to deduct the inventory and judge return value. If the inventory of Redis is deducted <0, it means that the spike failed and the inventory incr is returned; if the inventory of Redis is deducted >=0, it means that the spike is successful and the order is created.
- Orders are written into the cache : In the sixth chapter of writing the cache, we mentioned a scheme, that is, the order data is not put into the database first, but first put into the cache, and then batch insert orders at regular intervals (100ms) . We know that after placing an order, the user first enters a waiting page, and then this page regularly polls the background for order data. In the process of polling the order data, the backend first queries the order data in Redis. If it fails to find the order data, it will go to the database to query the order data and return it to the user directly. The user can directly enter the payment after receiving the message notification. The page is paid. When querying the order data in the database, no indication is found that the spike failed. (Theoretically, it will not be impossible to find out. If you have not been able to find out, remember to throw an exception for follow-up and follow up.
- Batch drop-off of orders : We need to drop orders in batches on a regular basis, and deduct the inventory in the database when the orders are dropped.
The above is the architecture design of the order submission operation. It is not difficult to see that we mainly carry out related design at the gateway layer and the back-end server.
(3) How does the payment page block the request upstream?
On the payment page, we basically don’t need to filter user requests anymore. In this link, in addition to ensuring data consistency, we also need to pay attention to one important point: if an order is cancelled due to not being paid in time in business logic, remember to add back the database and Redis inventory.
Third, the overall server architecture
Let's review the previous layered design idea of the spike system architecture, which is also the overall server architecture scheme of the spike system.
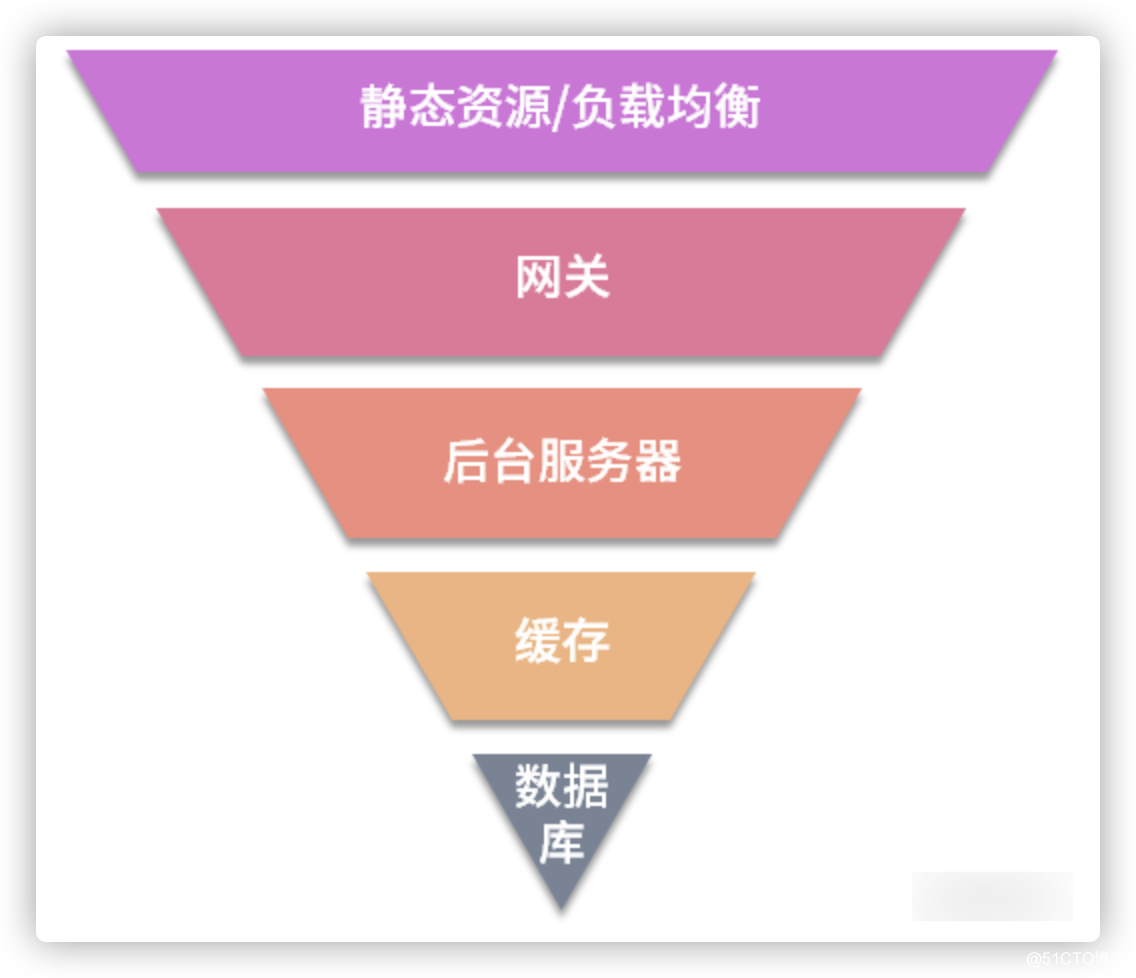
In order to ensure the high availability of the spike system, in the overall server architecture, we need to ensure that all levels in the above figure are highly available. Therefore, static resource servers, gateways, and backend servers need to be configured with load balancing, while cache Redis and databases need to be configured with cluster mode.
There is also an important part of the overall server architecture-MQ, because this time the spike architecture solution does not involve its design logic, so we did not mention it in the above layering. However, when a notification is triggered between services, we need to use it, so we also need to ensure that it is highly available. (Here we have to take the master-slave, fragmentation, and failover mechanisms into consideration.)
Four, summary
Having said that, the precautions for the spike architecture are over. Because many points of attention have been introduced in Chapters 5, 6, and 7, the content in this article is relatively concise.
The following table has compiled a check list of the spike architecture. This part of the knowledge may be useful to you when you design the spike system.
| Process | matter |
|---|---|
| Browse page | CDN for static resources |
| Browse page | During the spike, some dynamic data requests are put into the static page |
| Browse page | The start time of the spike depends on the server |
| Browse page | The sign of the end of spike is placed in various places |
| Place an order | Get the order URL dynamic background |
| Place an order | Grayed out when the purchase button is clicked |
| Place an order | The gateway filters requests from three aspects: <br>1. User access frequency. <br>2. IP access frequency. <br>3. Overall flow control. |
| Place an order | The inventory is placed in Redis, and the cache is judged to prevent oversold every time. |
| Place an order | Orders are placed in the cache and then batched out. |
| payment | Remember to add back to the database and Redis inventory if the order is cancelled. |
| Server architecture | Static resource server load balancing. |
| Server architecture | Gateway load balancing |
| Server architecture | Back-end service load balancing |
| Server architecture | Redis cluster |
| Server architecture | MQ cluster |
| Server architecture | Database cluster |
In this article, there are two points that we have not mentioned.
- Current limit at the gateway layer.
- Assuming that a certain service in the background goes down due to a spike, how to avoid an avalanche of other services.
In the next article, we will start from the simplest service management, talk about microservices related knowledge, welcome to pay attention! ! !