
About the Author
Zhang Shuwei Head of
Intelligent Operation and Maintenance Platform of China Minsheng Bank
Share: Zhang Shuwei
Edit: Bai Fan
Dear leaders and guests, good morning everyone! I am very happy to be here today to share with you the exploration and practice of Minsheng Bank in intelligent operation and maintenance. Today, I mainly look at what AIOps can do from the perspective of application operation and maintenance, and how we do it.

Today’s sharing is carried out from three parts, what are the challenges of application operation and maintenance, why use AIOps, the second part is about what can be done with intelligent operation and maintenance, how should we think about positioning, and the third part, in this Based on its positioning, Minsheng Bank has made some explorations.

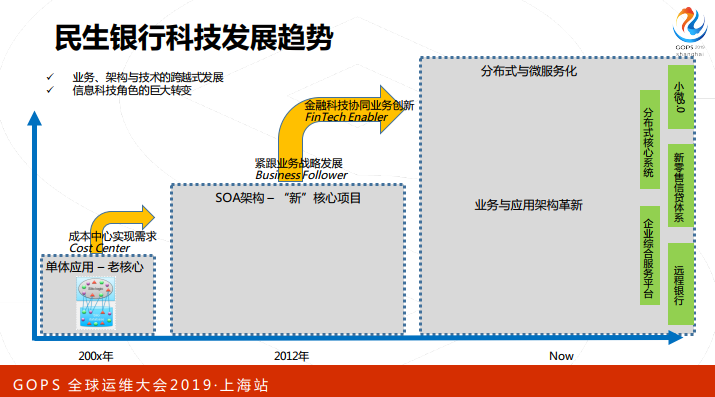
1. Technology development trend of Minsheng Bank
Looking back at the technological development process of Minsheng Bank, we had a centralized architecture around 2000, and launched a new core project based on SOA in 2012. Recently, we are evolving in the direction of distributed and microservices. Everyone knows that we launched the first distributed core system in the industry in 2017, which is used in direct banking.
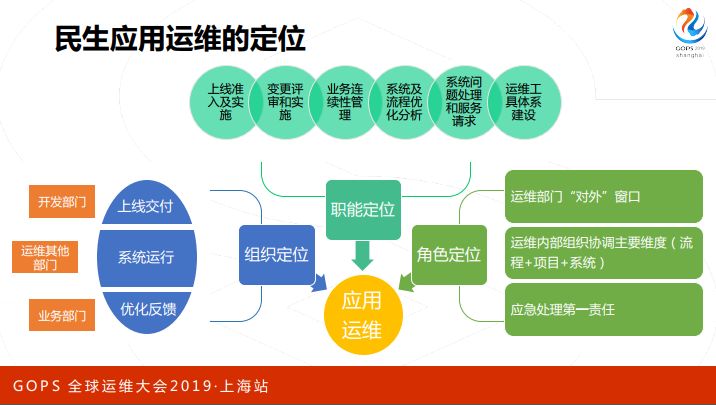
In the entire technological framework, what is the positioning of application operation and maintenance? Application operation and maintenance for application system full life cycle management, including application system launch, access assessment, review of each change and final change release process and monitoring, business process optimization will participate in it, and what the system encounters All problems, including malfunctions and service requests from end users.
It also includes the development of some tool systems. In short, it does all the things related to the application system, like a nanny. Our internal positioning is to look for application operation and maintenance for all things related to application systems, and application operation and maintenance will then promote or drive other departments to cooperate with us to complete this work.
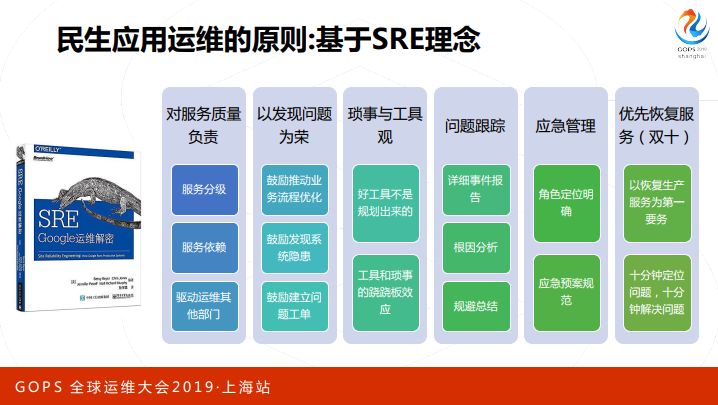
We have summarized some principles in the process of application operation and maintenance, and have also borrowed from many Google SRE concepts, such as being responsible for service quality and taking pride in finding problems. Regarding tool development, Google stipulates that SRE should have 50% of the time used for tool development. Although we have not made mandatory regulations, we also believe that there is a seesaw effect between tools and trivial matters. The better the tools, the better. More trivial matters will be reduced accordingly, which in turn is a vicious circle. A good tool is not planned. It does not mean that we can plan it out when we hold a meeting. Instead, we propose such a tool based on the needs of front-line engineers and actual operation and maintenance scenarios.
So a lot of our work is done directly from the application operation and maintenance side. Issue tracking and emergency management are also basically implemented in accordance with the concept of SRE. Let’s talk about the concept of giving priority to service restoration. As an IT person, he always has to troubleshoot the problem as soon as he sees a problem. What is the ins and outs, how to solve it, and what circumvention measures and solutions are there for operation and maintenance. If we want to break this thinking, we must have a consciousness and give priority to restoring services. No matter what happens, we must first normalize the service before looking for the cause.
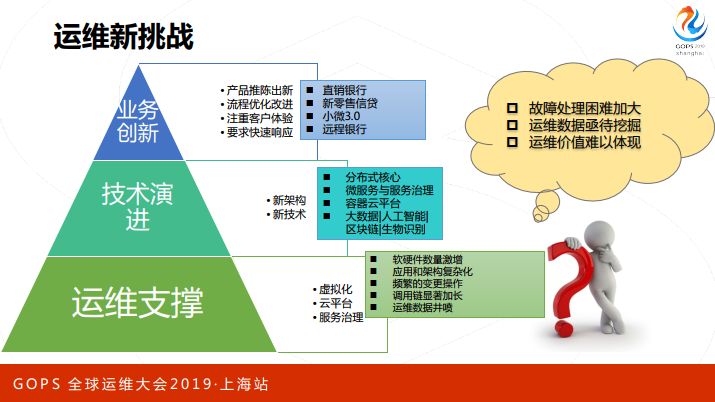
In the past few years, our business has been constantly innovating and innovating. Our technical architecture has been evolving, introducing many new architectures. The concepts of distributed and microservices, including blockchain and artificial intelligence, are all on the top. In terms of operation and maintenance reform, we have to lag behind. We have seen some phenomena. For example, the number of software and hardware has increased significantly, and the complexity of applications and architecture has become more and more complex; application-related changes have to exceed one per year. Ten thousand times, the increase in the call link is also very significant. The longest call link reached 17 times. A terminal request passed through 17 systems in the data center. There are about 20 incremental data on the log platform every day . T, the monitoring indicators are millions per minute, and the transaction details are hundreds of millions per day. In short, troubleshooting becomes more difficult. In addition, there must be a way to analyze and excavate so many data that people can’t come by. There are also so many operation and maintenance personnel. How does the value of operation and maintenance reflect? Everyone does not know that you are unknown when there is a problem. This is also a big challenge. We hope to help us solve these problems through AIOps.
2. 关于智能运维的思考
数据中心提出了数据驱动运维的理念,就是要用数据说话、用数据决策。我们想到了数据、信息和知识这三个词,我们知道数据是原始分散的,是描述性的东西,比如说一个机器 CPU 使用率达到了60%,这是一个描述事实,是一个描述性语言,什么是信息,这样的数据经过我们的监控系统,变成了一条告警,属于某个系统数据库的机器,发生了一个主要告警,这个告警会发送到运维人员手上,运维人员可能会对这个告警进行分析,进行经验总结,把前面的告警进一步联系了很多其他的信息,变成了一条经验,这就是知识。

这部分工作现在我们完全是由人工来做的,我们希望看智能运维能不能替代其中一部分工作,也就足够了。
所以我们说智能运维是下一代运维技术的必然选择,前面说的海量数据、复杂关系,处理问题时对人的依赖。智能运维希望通过算法驱动、智能决策,帮助我们从各个方面来提升。
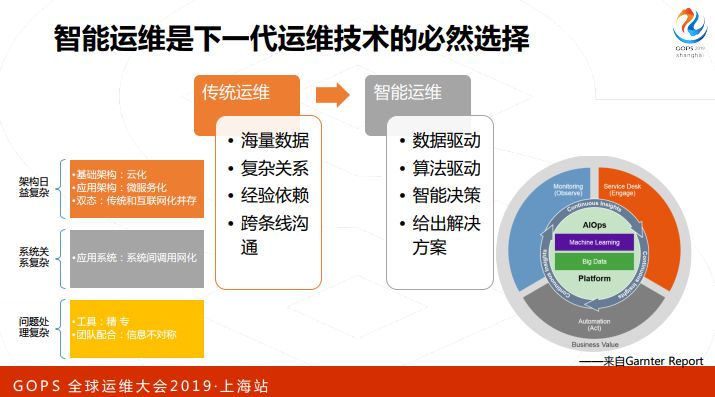
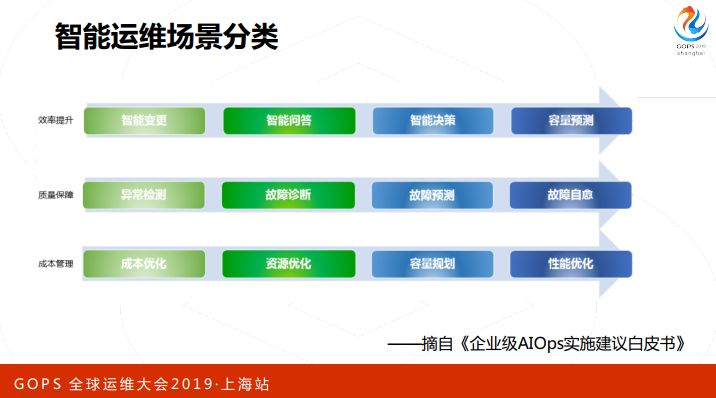
智能运维到底能够做什么事情?这个图是我从AIOps实施建议白皮书里面摘的,主要是三个方面,效率提升、质量保障、成本管理。
效率提升,智能变更、智能问答、智能决策、容量预测、职场检测、故障诊断、故障预测、故障自愈、成本优化这么多事情,智能运维是万能的吗?我们觉得可能不是,智能运维在落地过程当中还有一些局限和面临一些挑战的,所以我们需要做一个准确定位。
第一个局限我们觉得是AI本身的局限,有人讲AI是现代统计学,是对历史规律的总结,不会产生新的知识,包括现在有一些生成式文本的东西也是对历史规律的总结,并没有给我们惊喜。
AI对关联关系和因果关系没有明确的分割,没办法识别哪个是关联关系,哪个是因果关系,可能我们可以做到我们在交易量升高的时候发现CPU也升高,但是AI是不知道是因为交易量升高了导致CPU升高,还是CPU升高导致交易量增加。第二部分是数据挑战,我们知道运维数据比较杂比较乱缺少标准的,我们可以通过数据治理搞定这个事情,但是还有一些事情是数据治理也搞不定的就是数据完备性,刚才讲的这些事情,运维可能有很多背景支持是在人的脑子里的,没有办法数据化。技术方面现在的 AI 技术都是对单一场景比较有效,之前 AlphaGo 比较火爆,也是对围棋这样一个单一场景比较奏效,是一个规则很明确,数据很完备的场景。但是运维的场景,比如说根因分析,输入输出是什么,其实都是很模糊的概念,没有人可以把这个概念定义清楚,我们需要把这个场景继续拆解。
还有就是算法是不典型的,因为我们现在这几年AI发展,用的比较好的地方,我感觉都是在分类方面用的比较好,都是一些有监督算法,但是我们运维的场景往往很难打标注或者成本很高,只能用一些无监督方法进行处理。

我们需要给智能运维一个准确定位,我们认为运维经过了这么多年的发展,其实积累出了非常多的经验,每个应用运维工程师在处理问题的时候,脑子里面都有一套方法论,所以我们觉得现在的智能运维还不能超越人,只能向人学习经验,把人处理问题的过程抽象出来,把其中可以被自动化或者AI化的部分替换掉,这是一个可行的路径,从而提升人的效率,把人的精力解放出来做更加高阶的工作。
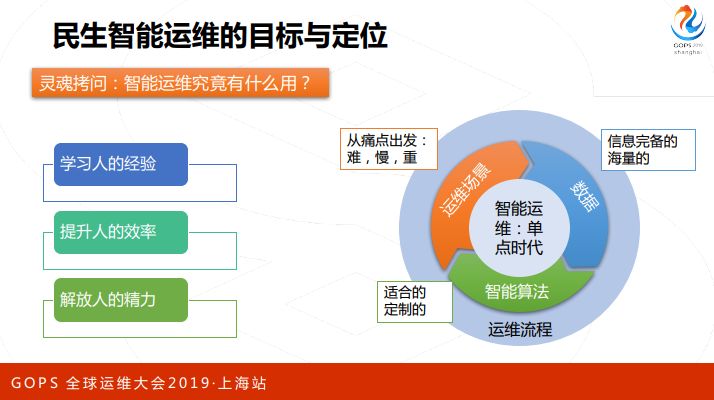
所以民生这边我们会从一些痛点出发,从痛点场景出发,人处理比较难的,比较慢的,比较重复的工作,同时具备信息比较完备,再加上一些适合的算法。
还有一点很重要就是要嵌入运维流程,不要打破现在已经运行良好的秩序,而是融入这个秩序里面去。
3. 民生银行的探索与实践
基于上面这些认识,我们来看一下民生银行的探索和实践。第一部分是我们的架构设计,其实比较简单,最底下一层是运维对象层,可能有机房,机房里面的设备,数据库、操作系统、存储,把他们的状态收集上来,收集上来进入智能运维平台里面去。平台主要分三个部分,第一部分就是数据;第二部分算法;第三部分算力。经过这样一个加工之后,对外做一个输出,最后在质量保障、效率提升和成本优化方面提升我们的运维水平。
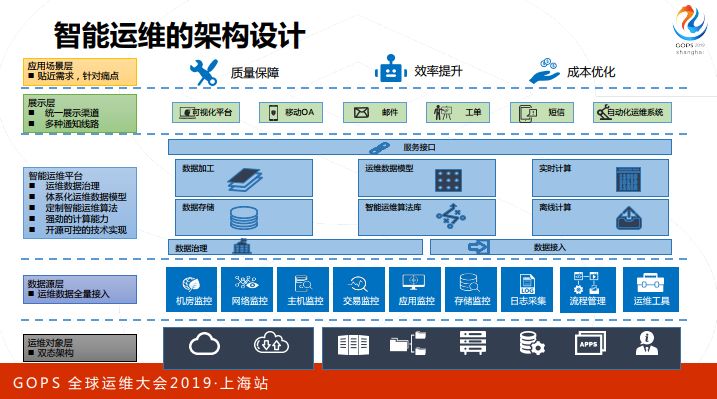
说智能运维肯定离不开数据支撑,数据这边我们先对所有的运维数据进行了摸底,然后把数据给出一些标准,每类数据都有一些标准,最后可能梳理下来有28个数据模型,这些模型是不是都一次性全部接到我们的平台里面去,只是说把现在条件比较好的,数据比较齐全的,这部分数据接进来,使用过程当中不断补充、不断提高数据的质量。
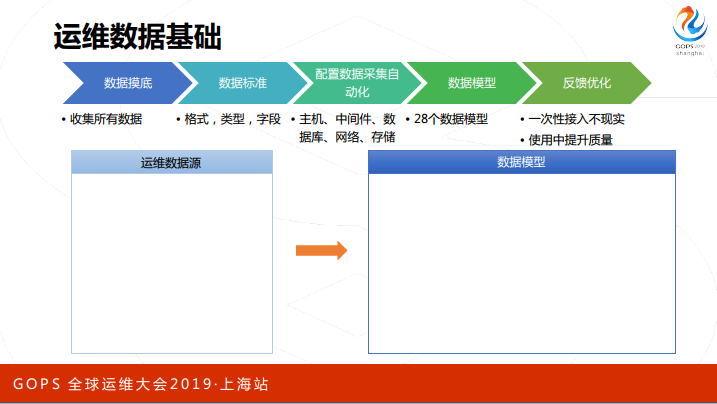
前面讲的到应用运维最大的挑战就是故障处理,接下来会对故障处理的框架做一个更详细的说明,把人工排障故事抽象一下做了梳理。
首先从告警出,告警是触发我们做故障分析的来源,有了告警以后我们会讲,现在这个问题是全局的还是局部的,到底有多严重。这可能决定了我们后面具体要怎样来处理这个问题,会有一个影响分析的过程,有了影响分析之后我们会想这个问题是自己的问题还是由别的系统引起的,这需要问题界定工作。
有了这个工作之后,就会关注到一个真正有问题的系统,现在的问题能不能总结出一些规律,有没有一些特征,是说某一个服务有问题,还是说我们的响应码,报错响应码都是一样的,还是说报错都来自于同样一个地区,这对于我们排查是有用的,如果没有任何特征,这可能是全局的问题。
接下来需要做监控指标排查,我们有这么多监控指标,有这么多机器,哪些监控指标和现在的问题有关联有关系。我们的监控指标正常吗?现在主要的做法是通过监控指标告警,但是监控指标告警现在也是基于固定阈值,报出来的都是比较严重的问题,还有一些监控指标并没有被纳入进来,并没有被纳入监控里面去,是一些很细微很长尾的监控指标,排查起来是有困难的。还有就是日志监控,看日志里面有什么东西。其实做排障过程当中,脑子里面一直想,这个事情有没有出现过,如果和上次出现的问题有点像,当时是怎么处理的的,这个问题要拿过来借鉴,如果说这部分也没有解答我们的问题,可能我们会做一些其他的联想,比如说现在有五个机器都有一样的现象,这就很奇怪了,我们想看看这五个机器是否有一些共性,是否都基于某一个存储,或者说基于宿主机,有共性在里面,如果这些都解决不掉,只能去现场分析了。最后我们找到了问题原因,面临具体操作的问题。
我们希望把里面抽象出来的框框全部换成AI可以做的事情,接下来分场景来介绍一下。

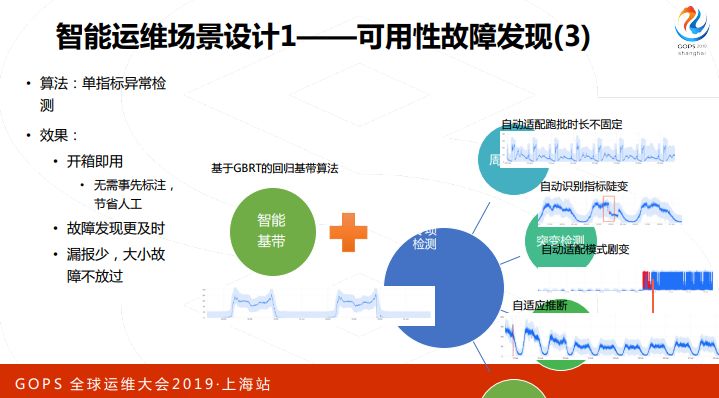
第一个场景,可用性故障发现,要解决的问题是及时发现故障,要少一点漏报,少一点误报,故障发现的对象是什么呢?是我们的核心指标,就是四个黄金指标,这些指标出了问题,多半系统服务有问题,和我们SRE的目标是一致的,现在的做法是固定阈值,会带来漏报误报比较多,人工维护成本比较多的问题。我们发现简单的算法也不能奏效,我们也试了一下,用3sigma和孤立森林这些做法进行检测,在单一一个KPI曲线上,经过我们的调参可以很完美把这个问题解决掉,如果换一个曲线,这个算法就没用了,这是一个核心挑战。另外还有一些节假日的规律,工作日的周一和节假日的周一是完全不一样的。我们的算法是单指标检测,首先算出来历史规律是什么样的,不要超过这个规律就是正常的,除了这个还加上一些专项检测和一些特殊的检测。
比如说突变检测,同样在基栈里面,上一分钟还是一百,下一分钟变成了50,变化量很大,要检测出来。还有一个是剧变适配,如果用传统的方法可能需要好久的时间,可能需要几周的时间才能适应这个新的模型,如果发现这个指标有变化,我们需要快速适应新的模型。
下面有一个复盘的例子,有一天有一个很重要的系统出现了一个响应率低的情况,当然这个告警是在比较晚的时候,大概六点钟的时候发出来了,原因可能是因为头一天上线之后,内存一直泄露,直到晚上七点钟才对系统造成了影响,我们用这个算法复盘,相对于固定阈值,我们可以提前一个小时发现,可以节约出很多故障排查时间。
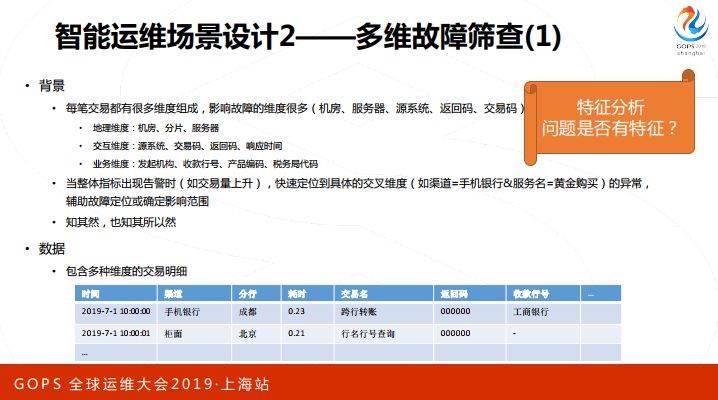
第二个,介绍一下多维故障筛查,主要用来解决当前的问题能不能总结出一些特征这件事。我们知道每笔交易都有很多维度,地理维度:是哪个机房哪个分片哪个服务器,还有很多业务属性,我们希望挖掘到业务属性,发起机构是哪里,产品编码是什么,会是一些很个性化的维度。当出现这样的问题之后,我们能不能快速定义到这样一个交叉维度,这对于迅速定位问题是有很大作用的。
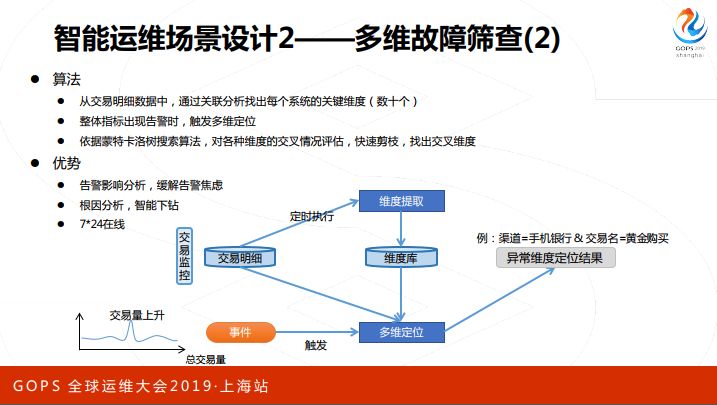
具体做法,从交易明细出发,用关联办法提取每个系统的关键维度,把同时共现的维度抽出来,然后在出现故障的时候用多维定位的算法,基本上是基于蒙特卡洛树搜索算法。因为我们不可能24小时都在,不可能一出问题马上做这个事情,所以这是给我们事件快速总结特征的好办法。
同样展示一个案例,我们有一套系统,有一天未响应交易量突然飙升,快速定位到一个交易码是某个查询交易,原系统是某某某,直接就定位到了原因。
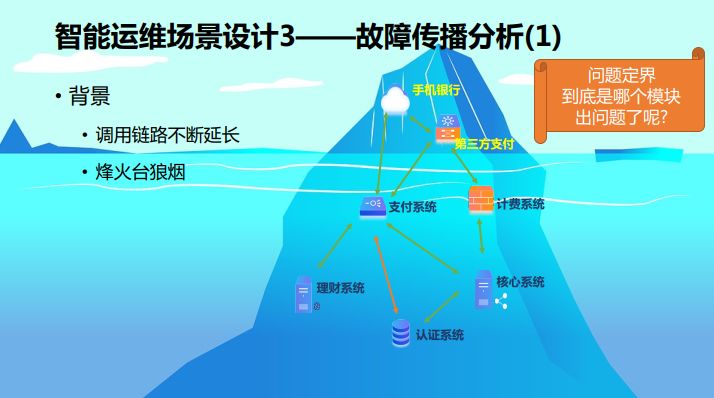
故障传播分析,主要解决的故障是到底是哪个模块的问题。随着调用链不断加长,在外面看到的只是冰山上面的部分,冰山下面还存在着很多系统。传统的方法一个系统出问题就一个一个往下找,像烽火台上的狼烟一样,我们希望从上帝视角告诉你现在就是认证系统的问题,就会减少很多人员的精力。
下一个场景,监控指标排查。如果前面这些都不奏效,那么监控指标到底有没有异常,原来是靠告警的,但是只会对比较严重的问题告警,长尾指标关注不到,轻微指标异常也不会告警。我们用算法来做,用一个非参数校验的办法把每个指标的异常程度做一个打分,有了这个打分之后再根据前面提到的指标分类,我们再算每个分类和每个节点里面的严重程度做一个排序。最后告诉我们的是某一个模块里面的MySQL有问题,或者说磁盘有问题,然后再往下看详细的指标。
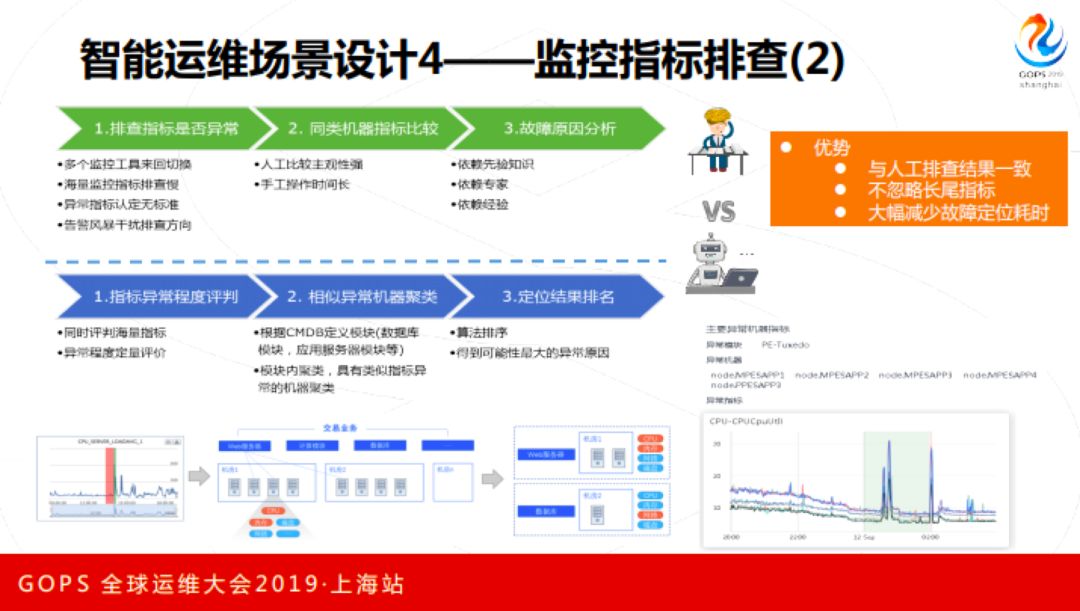
有一个例子,某系统响应率和失败率有下降,通过这个算的定位发现有一个进程,几个监控指标有这样一些微小波动,这个波动其实是非常非常小的,监控不可能监控到这么细的程度的。只有通过这种办法发现出来,最后证明确实这个进程有问题。最后是日志分析,日志大家知道里面的信息非常多,我们怎么进行分析呢?

我们现在已经建了一个日志平台,每天十几T的日志人肯定分析不过来,我们的做法就是把相似的日志聚在一起,然后做一个模板,有固定的部分和有变量的部分,固定的部分可以统计出现频率做成时序数据进行异常检测。我们有一天有一个文件系统就飚上去了,通过对比前一天和当时的日志,我们发现有一种类型的日志打印非常非常多,其中一种变量的分布也发生了很大变化,有助于我们快速定位到真正的问题。当然关于日志方面我们还在不断的探索。
最后做一下小结,我们认为智能运维不是万能的,需要给一个合理定位,我们要把人工步骤抽象出来,把其中可以被自动化的替换掉。数据质量如果达不到的话,智能运维无从谈起。
In addition, there is a huge gap between the algorithm DEMO and the product, and the process needs to be connected and the effect is polished. Practice is the only truth for testing algorithms. Don't try to change the process, but integrate into the process. Intelligent operation and maintenance is still in the era of single point application. In the future, as the entire industry works together, I believe that a rapid development trend will be achieved from point to surface.
That's all for today's sharing, thank you all!

Note: The above is the sharing by Zhang Shuwei, the person in charge of the intelligent operation and maintenance platform of Minsheng Bank, at GOPS 2019 · Shanghai.