This column is based on teacher Yang Xiuzhang’s crawler book "Python Web Data Crawling and Analysis "From Beginner to Proficiency"" as the main line, personal learning and understanding as the main content, written in the form of study notes.
This column is not only a study and sharing of my own, but also hopes to popularize some knowledge about crawlers and provide some trivial crawler ideas.
Column address: Python web data crawling and analysis "From entry to proficiency" For
more crawler examples, please see the column: Python crawler sledgehammer test

Previous article review:
"Python crawler series explanation" 1. Network data crawling overview
"Python crawler series explanation" 2. Python knowledge beginner
"Python crawler series explanation" 3. Regular expression crawler's slasher test
table of Contents
1 Install and import BeautifulSoup
2 Quickly start BeautifulSoup parsing
2.2 Simple access to web page tag information
2.3 Locate tags and get content
3 In-depth understanding of BeautifulSoup
3.2 Traverse the document tree
1 Install and import BeautifulSoup
BeautifulSoup is a Python extension library that can extract data from HTML or XML files, and is a parser that analyzes HTML or XML files. It implements document navigation, search, and modification of documents through a verified converter; it can handle irregular marks and generate a parse tree (Parse Tree); the navigation function (Navigation) provided can easily and quickly search the parse tree and Modify the parse tree.
BeautifulSoup technology is usually used to analyze the structure of web pages, crawl corresponding Web documents, and provide certain completion functions for irregular HTML documents, thereby saving developers time and effort.
The pip command is mainly used to install BeautifulSoup in Python 3.x.
pip install BeautifulSoup4Note: There are two commonly used versions of BeautifulSoup: BeautifulSoup 3 (discontinued development) and BeautifulSoup 4 (abbreviated as bs4)
BeautifulSoup supports the HTML parser in the Python standard library, as well as some third-party parsers:
One of them is lxml
pip install lxmlAnother alternative parser is html5lib implemented in pure Python
pip install html5lib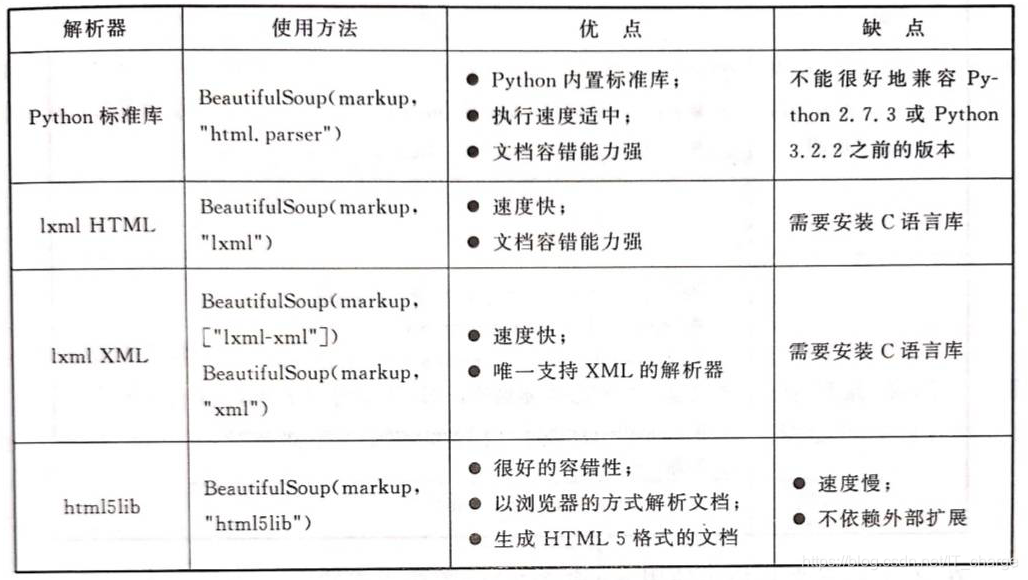
After the installation is successful, import the BeautifulSoup library into the program as follows
from bs4 import BeautifulSoup2 Quickly start BeautifulSoup parsing
First introduce an html file as an example to introduce the use of BeautifulSoup
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>BeautifulSoup 技术</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
床前明月光,<br/>
疑是地上霜。<br/>
举头望明月,<br/>
低头思故乡。<br/>
</p>
<p class="other">
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%94%AB/63508" class="poet" id="link1">杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="https://baike.baidu.com/item/%E6%9D%8E%E5%95%86%E9%9A%90/74852" class="poet" id="link2">李商隐</a>
与<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%89%A7" class="poet" id="link3">杜牧</a>
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
</p>
</body>
</html>Open the webpage through the browser, as shown in the figure below:

2.1 BeautifulSoup parses HTML
# 通过解析HTML代码,创建一个 BeautifulSoup 对象,然后调用 prettify() 函数格式化输出网页
from bs4 import BeautifulSoup
html = '''
<html lang="en">
<head>
<meta charset="UTF-8">
<title>BeautifulSoup 技术</title>
</head>
<body>
<p class="title"><b>静夜思</b></p>
<p class="content">
床前明月光,<br/>
疑是地上霜。<br/>
举头望明月,<br/>
低头思故乡。<br/>
</p>
<p class="other">
李白(701年-762年) ,字太白,号青莲居士,又号“谪仙人”,
唐代伟大的浪漫主义诗人,被后人誉为“诗仙”,与
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%94%AB/63508" class="poet" id="link1">杜甫</a>
并称为“李杜”,为了与另两位诗人
<a href="https://baike.baidu.com/item/%E6%9D%8E%E5%95%86%E9%9A%90/74852" class="poet" id="link2">李商隐</a>
与<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%89%A7" class="poet" id="link3">杜牧</a>
即“小李杜”区别,杜甫与李白又合称“大李杜”。
据《新唐书》记载,李白为兴圣皇帝(凉武昭王李暠)九世孙,与李唐诸王同宗。
其人爽朗大方,爱饮酒作诗,喜交友。
</p>
'''
# 按照标准的所进行时的结构输出
soup = BeautifulSoup(html)
print(soup.prettify())
It is worth pointing out that the HTML code source tag defined earlier lacks an end tag, specifically, the </body> and </html> tags are missing, but the output of the prettify() function is automatically completed. Tags, this is an advantage of BeautifulSoup.
Even if BeautifulSoup gets a corrupted tag, it will generate a DOM tree that is as consistent as possible with the meaning of the original document content. This measure usually helps users collect data more correctly.
In addition, you can use local HTML files to create BeautifulSoup objects
soup = BeautifulSoup(open('t.html'))2.2 Simple access to web page tag information
When using BeautifulSoup to parse a web page, sometimes you want to get the information between a certain tag, the specific code is as follows
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
# 获取标题
title = soup.title
print('标题:', title)
# 获取头部
head = soup.head
print('头部:', head)
# 获取 a 标签
a = soup.a
print('超链接内容:', a)
# 获取 p 标签
p = soup.p
print('超链接内容:', p)
2.3 Locate tags and get content
The following code will achieve all the hyperlink tags and corresponding URL content of the web page
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
# 从文档中找到 <a> 的所有标签链接
for a in soup.find_all('a'):
print(a)
# 获取 <a> 的超链接
for link in soup.find_all('a'):
print(link.get('href'))
# 获取文字内容
for poeter in soup.find_all('a'):
print(poeter.get_text())
3 In-depth understanding of BeautifulSoup
3.1 BeautifulSoup object
BeautifulSoup converts complex HTML documents into a tree structure. Each node is a Python object. The official BeautifulSoup document summarizes all objects into 4 types:
- Tag;
- NavigableString;
- BeautifulSoup;
- Comment。
3.1.1 Tag
The Tag object represents a tag in an XML or HTML document. It will be a tag in HTML in layman's terms. This object is the same as a tag in an HTML or XML native document. Tag has many methods and attributes. BeautifulSoup is defined as Soup.Tag, where Tag is a tag in HTML, such as head, title, etc., which returns the complete tag content of the result, including tag attributes and content.
<title>BeautifulSoup 技术</title>
<p class="title"><b>静夜思</b></p>
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%89%A7" class="poet" id="link3">杜牧</a>For example, in the above code, title, p, a, etc. are all tags, starting tags (<title>, <p>, <a>) and ending tags (</title>, </p>, </a>) Add content in between is Tag. The tag acquisition method code is as follows
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.title)
print(soup.head)
print(soup.p)
print(soup.a)
It’s worth noting that the content it returns is the first one that meets the requirements.
Obviously, tags and tag content can be easily obtained through the BeautifulSoup object, which is much more convenient than the regular expression in the third lecture.
# 该段代码输出的是该对象的类型,即Tag对象
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(type(soup.html))
There are many Tag attributes and methods, of which the two most important attributes: name and attrs.
(1)name
The name attribute is used to get the label name of the document tree. If you want to get the head tag name, just use the soup.head.name code. For internal tags, the output value is the name of the tag itself. The BeautifulSoup object is rather special, its name is document.
print(soup.name)
print(soup.head.name)
print(soup.title.name)
(2)attrs
A tag (Tag) may have multiple attributes, for example
<a href="https://baike.baidu.com/item/%E6%9D%9C%E7%94%AB/63508" class="poet" id="link1">杜甫</a>It has two attributes: one is the class attribute, the corresponding value is "poet"; the other is the id attribute, the corresponding value is "link1". The operation method of Tag attribute is the same as that of Python dictionary. Get all attribute codes of p tag as follows to get a dictionary value. What it gets is the attribute and attribute value of the first paragraph p.
print(soup.p.attrs)
If you want to get an attribute separately, you can use the following two methods to get the value of the class attribute of the hyperlink.
print(soup.a['class'])
print(soup.a.get('class'))
Each Tag of BeautifulSoup may have multiple attributes, which can be obtained through ".attrs". Tag attributes can be modified, deleted, and added.
Here is a simple example to introduce:
# 该段代码输出的是该对象的类型,即Tag对象
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup('<b class="test" id="zzr">荣仔</b>', "html.parser")
tag = soup.b
print(tag)
print(type(tag))
# NAME
print(tag.name)
print(tag.string)
# Attributes
print(tag.attrs)
print(tag['class'])
print(tag.get('id'))
# 修改属性,增加属性name
tag['class'] = 'abc'
tag['id'] = '1'
tag['name'] = '2'
print(tag)
# 删除属性
del tag['class']
del tag['name']
print(tag)
# print(tag['class']) # 此语句会报错
3.1.2 NavigableString
The previous section describes how to get the name and attrs of the label. If you want to get the content corresponding to the label, you can use the string attribute to get it.
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.a['class'])
print(soup.a.string)
As can be seen from the above code, it is much more convenient to use the string attribute to get the content between the tags <> and </> than to use regular expressions.
BeautifulSoup uses the NavigableString class to wrap the string in Tag, where NavigableString represents a traversable string. A NavigableString string is the same as a Unicode string in Python, and supports some of the features included in traversing the document tree and searching the document tree.
# 该段代码用来查看 NavigableString 的类型
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
print(type(tag.string))
Of course, you can directly convert NavigableString objects into Unicode strings through the unicode() method.
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
unicode_string = tag.string
print(unicode_string)One last point, the string contained in the label cannot be edited, but it can be replaced with other strings, using the replace_with() method to achieve
tag.string.replace("Content before replacement", "Content after replacement")
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
tag = soup.title
unicode_string = tag.string
print(unicode_string)
a = tag.string.replace("BeautifulSoup 技术", " NavigableString ")
print(a)
3.1.3 BeautifulSoup
The BeautifulSoup object represents the entire content of a document, usually as a Tag object. The BeautifulSoup object supports most of the methods described in traversing the document tree and searching the document tree.
type(soup)
# <class 'bs4.BeautifulSoup'>The above code calls the type() function to view the data type of the soup variable, which is the BeautifulSoup object type. Because the BeautifulSoup object is not a real HTML and XML tag, it has no name and attrs attributes.
But sometimes it is convenient to look at the ".name" property of the BeautifulSoup object, because it contains a special property with a value of "[ document ]"—soup.name.
soup.name
# [document]3.1.4 Comment
Comment object is a special type of NavigableString object, used to process comment objects.
# 本段代码用于读取注释内容
from bs4 import BeautifulSoup
markup = "<b><!--This is comment code.--></b>"
soup = BeautifulSoup(markup, "html.parser")
comment = soup.b.string
print(type(comment))
print(comment)
3.2 Traverse the document tree
In BeautifulSoup, a tag may contain multiple strings or other tags. These are called subtags of the tag.
3.2.1 Child node
In BeautifulSoup, the contents of the child nodes of the label are obtained by the contents value and output in the form of a list.
# 本段代码用于获取 <head> 标签子节点内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.head.contents) Since there are two line breaks between <title> and </title>, the obtained list includes two line breaks. If you need to extract an element, the code is as follows
Since there are two line breaks between <title> and </title>, the obtained list includes two line breaks. If you need to extract an element, the code is as follows
print(soup.head.contents[3])
Of course, you can also use the children keyword to get, but it does not return a list, but can get the content of all child nodes by traversing
print(soup.head.children)
for child in soup.head.children:
print(child)
The contents and children attributes described earlier only contain the direct child nodes of the tag. If you need to get all the child nodes of the Tag, even descendants, you need to use the descendants attribute.
for child in soup.descendants:
print(child) Obviously, all the HTML tags are printed.
Obviously, all the HTML tags are printed.
3.2.2 Node content
If the label has only one child node, and the content of the child node needs to be obtained, the string attribute is used to output the content of the child node, usually returning the label content of the mouth layer.
# 本段代码用于获取标题内容
from bs4 import BeautifulSoup
# 创建本地文件 soup 对象
soup = BeautifulSoup(open('t.html', encoding='utf-8'), "html.parser")
print(soup.head.string)
print(soup.title.string) It can be seen from the above code that when the tag contains multiple child nodes (the content of <head> includes two newline elements), Tag cannot determine which child node the string gets, and the output result at this time is None.
It can be seen from the above code that when the tag contains multiple child nodes (the content of <head> includes two newline elements), Tag cannot determine which child node the string gets, and the output result at this time is None.
If you need to get the content of multiple nodes, use the strings attribute
for content in soup.strings:
print(content) At this time we found a problem, that is, it contains too many spaces or line breaks. At this time, we need to use the stripped_strings method to remove the extra white space.
At this time we found a problem, that is, it contains too many spaces or line breaks. At this time, we need to use the stripped_strings method to remove the extra white space.
for content in soup.stripped_strings:
print(content)
3.2.3 Parent node
Call the parent property to locate the parent node. If you need to get the label name of the node, use parent,name.
p = soup.p
print(p.parent)
print(p.parent.name)
content = soup.head.title.string
print(content.parent)
print(content.parent.name)
If you need to get all the parent nodes, use the parents property to get it cyclically
content = soup.head.title.string
for parent in content.parents:
print(parent.name)
3.2.4 Sibling nodes
The sibling node refers to the node at the same level as the current node. The next_sibling attribute is to get the next sibling node of the node. On the contrary, the precious_sibling is to take the previous sibling node of the node. If the node does not exist, it returns None .
print(soup.p.next_sibling)
print(soup.p.precious_sinling)
It is worth noting that the next_sibling and previous_sibling attributes of the tag in the actual document are usually strings or blanks, because blanks or Korean Air can also be regarded as a node, so the available results may be blanks or newlines.
3.2.5 Front and back nodes
Call the attribute next_element to get the next node, and call the attribute precious_element to get the previous node.
print(soup.p.next_element)
print(soup.p.precious_element)
3.3 Search the document tree
For searching the document tree, the most commonly used method is the find_all() method.
If the line gets all the <a> tags from the web page, the code using the find_all() method is as follows
urls = soup.find_all('a')
for url in urls:
print(url)
Similarly, this function supports passing regular expressions as parameters, and BeautifulSoup will match the content through regular expression match().
The following code example is to find all the tags beginning with b:
import re
for tag in soup.find_all(re.compile("^b")):
print(tag.name)
Similarly, if you want to pass the values of label a and label b, you can use the following function
soup.find_all(["a", "b"])Note: The fina_all() function can receive parameters for specific node query
soup.find_all(id="link1")Similarly, multiple parameters can also be accepted, such as:
soup.find_all("a", class_="poet") # 得到一个列表
At this point, the entire BeautifulSoup technology has been explained. It can be seen that it is much more convenient than the previous regular expression, and it can only crawl a lot of functions.
4 Summary of this article
BeautifulSoup is a Python library that can extract the required data from HTML or XML files, and it is regarded as a technology here. On the one hand, BeautifuSoup has the powerful function of intelligently crawling web information. Compared with the previous regular expression crawlers, it has better convenience and applicability. Through the entire web document in transit and calling related functions to locate the node of the required information, Then crawl related content; on the other hand, BeautifulSoup is relatively simple to apply, its API is very user-friendly, it uses analysis technology similar to XPath to locate tags, and supports CSS selectors. The development efficiency is relatively high. It is widely used in Python data crawling. Take the field.
Welcome to leave a message, learn and communicate together~
Thanks for reading