This column is based on teacher Yang Xiuzhang’s crawler book "Python Web Data Crawling and Analysis "From Beginner to Proficiency"" as the main line, personal learning and understanding as the main content, written in the form of study notes.
This column is not only a study and sharing of my own, but also hopes to popularize some knowledge about crawlers and provide some trivial crawler ideas.
Column address: Python web data crawling and analysis "From entry to proficiency" For
more crawler examples, please see the column: Python crawler sledgehammer test

Previous article review:
"Python crawler series explanation" 1. Network data crawling overview
"Python crawler series explanation" 2. Python knowledge beginners
"Python crawler series explanation" 3. Regular expression crawler's powerful test
"Python crawler series explanation" 4. BeautifulSoup Technology
"Python crawler series explanation" 5. Use BeautifulSoup to crawl movie information
"Python crawler series explanation" 6. Python database knowledge
"Python crawler series explanation" 7. BeautifulSoup database-based recruitment crawling
"Python crawler series explanation" 8. Selenium technology
"Python crawler series explanation" 9. Use Selenium to crawl online encyclopedia knowledge
"Python crawler series explanation" 10. Selenium blog crawler based on database storage
"Python crawler series explanation" 11. Selenium Weibo crawler based on login analysis
" Python crawler series explanation ``12. Selenium crawler based on image crawling
table of Contents
2.2 Scrapy composition detailed explanation and simple example
3 Use Scrapy to crawl agricultural product data sets
3.4 Create a crawler and execute
3.5 Realize page turning crawling and multi-page crawling functions
3.6 Set pipelines.py file to save data to local
3.7 Setting the settings.py file
If you have been seeing this from the crawler series , I believe that you have a preliminary understanding of Python crawling network data. You can even use regular expressions, BeautifulSoup or Selenium technology to crawl the required corpus, but these technologies also have some problems , Such as low crawling efficiency.
This article will introduce the Scrapy technology, which has a high crawling efficiency. It is an application framework for crawling network data and extracting structured data. It will be introduced in detail from three aspects: installation, basic usage and crawler examples.
1 Install Scrapy
This crawler column series is mainly aimed at Python programming in the Windows environment, so the installed Scrapy extension library is also based on the Windows environment. Enter Python's pip command under Python's Scripts folder to install it.
It is worth noting that, because the scrapy framework is based on Twisted, you must first download its whl package and install it.
Twisted download link: http://www.lfd.uci.edu/~gohlke/pythonlibs/

Search twisted, download and install according to your own version, and then enter a pip command similar to the following in cmd
pip install *****.whl
注:***.whl 是下载到本地的路径地址(可在属性→安全中查看)
Then install Scrapy, scrapy's whl package address: http://www.lfd.uci.edu/~gohlke/pythonlibs/

pip install *****.whl
注:***.whl 是下载到本地的路径地址(可在属性→安全中查看)
After the installation is successful, enter "scrapy" through cmd to view the instructions it contains, as shown in the figure below.

2 Quickly understand Scrapy
Scrapy's official website address is: https://scrapy.org/ , the official introduction is "An open source and collaborative framework for extracting the data you need from websites. In a fast, simple, yet extensible way.".
Scrapy is an application framework written to quickly crawl website data and extract structured data. It was originally designed for page crawling or web crawling. It can also be used to obtain data returned by APIs, such as Amazon Associates Web Services or General-purpose web crawlers are now widely used in fields such as data mining, information crawling or Python crawlers.
2.1 Scrapy basics
The figure below shows the homepage of Scrapy's official website. It is recommended that you learn the usage of the tool from the official website and implement relevant crawler cases. Here, I will explain Scrapy based on the author's relevant experience and official website knowledge.
 The Scrapy crawler framework is shown in the following figure. It uses the Twisted asynchronous network library to process network communication. It contains various intermediate interfaces and can flexibly complete various needs. Only a few modules need to be defined, and the required data can be easily crawled. set.
The Scrapy crawler framework is shown in the following figure. It uses the Twisted asynchronous network library to process network communication. It contains various intermediate interfaces and can flexibly complete various needs. Only a few modules need to be defined, and the required data can be easily crawled. set.

The basic components of the picture above are introduced as shown in the following table:
| Component | Introduction |
| Scrapy Engine | Scrapy framework engine, responsible for controlling the flow of data flow in all components of the system, and triggering the event when the corresponding action occurs |
| Scheduler | Scheduler, which accepts requests from the engine and enqueues them so that they can be provided to the engine when the engine requests them |
| Downloader | Downloader, responsible for extracting page data and providing it to the engine, and then providing it to the crawler |
| Spiders | Crawler, it is a class written by Scrapy users to analyze the response (Response) and extract items or additional follow-up URLs. Each crawler is responsible for processing a specific website or some websites |
| Item Pipeline | The project pipeline is responsible for processing the projects extracted by the crawler. Typical processing includes cleanup, verification and storage in the database |
| Downloader Middlewares | Downloader middleware, which is a specific hook between the Scrapy engine and the downloader, handles the response sent by the downloader to the engine (including the request sent by the Scrapy engine to the downloader). It provides a simple mechanism by inserting self Define code to extend Scrapy functionality |
| Spider Middlewares | Crawler middleware, which is a specific hook between the Scrapy engine and Spiders, which handles the input response and output items and requirements of Spiders |
| Scheduler Middlewares | Scheduler middleware, which is a specific hook between the Scrapy engine and the scheduler, which processes the request sent by the scheduler engine to provide it to the Scrapy engine |
- The data flow in the Scrapy framework is controlled by the execution engine. According to the data flow indicated by the dotted arrow in the figure above, the crawling steps of the Scrapy framework are as follows:
- The Scrapy engine opens a website and requests the first URL(s) to be crawled from the crawler;
- The Scrapy engine obtains the first URL to be crawled from the crawler and sends it to the engine, and the engine forwards the URL to the downloader as requested through the downloader middleware;
- The Scrapy engine requests the next URL to be crawled from the scheduler;
- The scheduler returns the next URL engine to be crawled, and the engine forwards the URL to the downloader in a requested manner through the downloader middleware;
- The downloader carries out the downloading work. When the page is downloaded, the downloader will generate a response for the page, and return the response through the downloader middleware and send it to the engine;
- The Scrapy engine receives the response from the downloader and sends it to the crawler for processing through the crawler middleware;
- The crawler processes the response and returns the crawled item content and new requests to the engine;
- The engine sends the crawled items returned by the crawler to the project pipeline. It will post-process the data (including detailed analysis, filtering, storage, etc.), and send the request returned by the crawler to the scheduler.
- Repeat 2~9 until there are no more requests in the scheduler and the Scrapy engine closes the website.
Next, we will experience the working principle and specific usage of Scrapy crawler through simple examples.
2.2 Scrapy composition detailed explanation and simple example
Writing a Scrapy crawler mainly completes the following 4 tasks:
- Create a Scrapy project;
- Define the extracted Item and the column to be crawled at this time;
- Write a crawler that crawls the website and extract items;
- Write Item Piprline to store the extracted Item data.
The following is an example to explain the composition structure and calling process of Scrapy, which is divided into 4 parts corresponding to the above tasks.
2.2.1 New project
First, you need to create a new project in a custom directory, such as creating a test_scrapy project. Note that you need to call the cmd command line to create the project, and enter the following commands in cmd:
scrapy startproject test_scrapyThe project is created in the author's Python file directory, as shown in the figure below. At the same time, it is prompted that you can call the "cd test_scrapy" command to go to this directory, and call the "scrapy genspider example example.com" command to start the first crawler.

The test_scrapy project created by this command contains the following directories. The outermost layer is a test_scrapy directory and a scrapy.cfg file. The test_scrapy folder contains the main crawler files, such as items.py, middlewares.py, pipelines.py, settings .py etc.

The specific meaning of these files are listed in the table below, and the follow-up content will introduce each file in detail.
| file | meaning |
| scrapy.cfg | Project configuration file |
| test_scrapy / items.py | Item file in the project, define the column |
| test_scrapy / pipelines.py | The piplines file in the project, storing data |
| test_scrapy / settings.py | Project settings file |
| test_scrapy / spiders/ | Directory where spiders code is placed |
The following will take Scrapy to crawl the author's blog site as an entry example.
2.2.2 Define Item
Item is a container for storing crawled data. Its usage is similar to a Python dictionary, and it provides a corresponding protection mechanism to avoid undefined field errors caused by spelling errors.
Here first create a scrapy.item class and define scrapy.Field class attributes, and then use the scrapy.Field class attributes to define a corresponding field in an Item. For example, the code in the items.py file defines three fields: title, hyperlink, and summary, as follows:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class TestScrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 标题
url = scrapy.Field() # 超链接
dedscription = scrapy.Field() # 摘要
Through the Item defined in this file, readers can easily use the various methods provided by the Scrapy crawler to crawl the data of these three fields, which corresponds to the Item defined by themselves.
2.2.3 Extract data
Next, you need to write a crawler program, a class for crawling website data. This class contains an initial URL for downloading, which can follow up the hyperlinks in the webpage and analyze the content of the webpage, extract and generate the Item. The scrapy.spider class contains 3 common attributes, as follows:
- name : The name field is used to distinguish crawlers. It should be noted that the name must be unique, and the same name cannot be set for different crawlers.
- start_urls : This field contains a list of URLs that the crawler performs when it starts.
- parse() : A method of the crawler. When called, the Response object generated after each initial URL is downloaded will be passed to the method as the only parameter. This method is responsible for parsing the returned data, extracting the data, and generating the Request object of the URL that needs further processing.
Then create a BlogSpider.py file in the test_scrapy / spiders directory, and the project directory is as shown below:
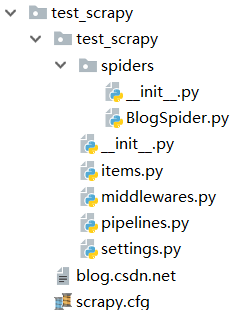
The added code is as follows. Note that the class name and the file name are consistent, both are "BlogSpider".
BlogSpiders.py
import scrapy
class BlogSpider(scrapy.Spider):
name = "IT_charge"
allowed_domains = ["https://blog.csdn.net/IT_charge"]
start_urls = [
"https://blog.csdn.net/IT_charge"
]
def parse(self, response):
filename = response.url.split("/")[-2]
with open(filename, 'wb') as f:
f.write(response.body)Next, execute the following command on the cmd command line to start the crawler:
cd test_scrapy
scrapy crawl IT_charge"Scrapy crawl IT_charge" starts the crawler and crawls the blog website. The running result is shown in the figure below:

At this point, Scrapy creates a scrapy.Request object for each URL in the crawler's start_urls attribute, and assigns the parse() method as a callback function to the Request object; in addition, the Request object is scheduled to execute to generate scrapy.http. The Response object is returned to the spider parse() method.
Scrapy uses an analysis method based on XPath or Selenium technology when extracting Item, such as:
- /html/head/title : locate and select the <title> element under the <head> tag in the HTML document;
- /html/head/title/text() : locate the <title> element and get the text content in the title element;
- //td : select all <td> elements;
- //div[@class="price"] : Select all div elements with the "class="price"" attribute.
The following table lists the 4 commonly used methods of Selector:
| method | meaning |
| xpath() | Use XPath technology to analyze, pass in XPath expressions, and return the list of corresponding nodes |
| css() | Pass in a CSS expression, and return the Selector list of all nodes corresponding to the expression |
| extract() | Serialize the node as a unicode string and return a list list |
| re() | Extract the data according to the regular expression passed in, and return a list of unicode strings |
Assuming that you need to crawl the title content of the blog website, modify the BlogSpider.py file in the test_scrapy \ spiders directory, the code is as follows:
BlogSpiders.py
import scrapy
class BlogSpider(scrapy.Spider):
name = "IT_charge"
allowed_domains = ["https://blog.csdn.net/IT_charge"]
start_urls = [
"https://blog.csdn.net/IT_charge"
]
def parse(self, response):
for t in response.xpath('//title'):
title = t.extract()
print(title)
for t in response.xpath('//title/text()'):
title = t.extract()
print(title)Enter the "scrapy crawl IT_charge" command, and the title code of the website will be crawled: "<title>Rongzai's blog_Rongzai! The most beautiful boy!_CSDN blog-Analysis of 23 types of object-oriented programming B from the perspective of the glory of the king Design pattern, java, Python domain blogger</title>", if you need to get the title content, use the text() function to get "Rongzai’s blog_Rongzai! The most beautiful boy!_CSDN blog-in the perspective of the glory of kings Next, analyze 23 design patterns in object-oriented programming B, java, Python bloggers".

Next, you need to get the title, hyperlink, and abstract, and analyze the source code through the browser, as shown in the figure below.

You can see that the article is located between the <div>...</div> tags, and its class attribute is "article-item-box csdn-tracking-statistics". Locate the "h4" tag under the <div> node to get it The title, <p> tag can get the abstract.
The BlogSpider.py file corresponding to the crawl title, hyperlink, and summary content is modified as follows:
BlogSpiders.py
import scrapy
class BlogSpider(scrapy.Spider):
name = "IT_charge"
allowed_domains = ["https://blog.csdn.net/IT_charge"]
start_urls = [
"https://blog.csdn.net/IT_charge"
]
def parse(self, response):
for sel in response.xpath('//*[@id="mainBox"]/main/div[2]/div[1]'):
title = sel.xpath('h4/a/text()').extract()[0]
url = sel.xpath('h4/a/@href').extract()[0]
description = sel.xpath('p/a/text()').extract()[0]
print(title)
print(url)
print(description)Similarly, enter "input "scrapy crawl IT_charge" command" under the cmd command line, and the running result is shown in the following figure:

2.2.4 Save data
To save data, you need to use the pipeline.py file, which mainly saves the item list returned by the crawler and writes to a file or database. It is implemented through the process_item() function.
First, modify the BlogSpiders.py file to generate an item type through the Test13Item() class to store the title, hyperlink and summary. The code is as follows:
BlogSpiders.py
import scrapy
from Scrapy_project.test_scrapy.test_scrapy.items import *
class BlogSpider(scrapy.Spider):
name = "IT_charge"
allowed_domains = ["https://blog.csdn.net/IT_charge"]
start_urls = [
"https://blog.csdn.net/IT_charge"
]
def parse(self, response):
for sel in response.xpath('//*[@id="mainBox"]/main/div[2]/div[1]'):
item = TestScrapyItem()
item['title'] = sel.xpath('h4/a/text()').extract()[0]
item['url'] = sel.xpath('h4/a/@href').extract()[0]
item['description'] = sel.xpath('p/a/text()').extract()[0]
return item
Next, modify the pipelines.py file, the specific modification code is as follows:
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
import codecs
class TestScrapyPipeline(object):
def __init__(self):
self.file = codecs.open('F:/blog.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
Then in order to register and start the Pipeline, you need to find the settings.py file, and then add the class to be registered to the configuration of "ITEM_PIPELINES", and add the following code to settings.py, where "Scrapy_project.test_scrapy.pipelines.TestScrapyPipeline" is what the user wants For the registered class, the "1" on the right represents the priority of the pipeline, where the priority range is 1~1000, the smaller the priority, the higher the priority.
settings.py
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Scrapy_project.test_scrapy.pipelines.TestScrapyPipeline': 1
}Similarly, cmd enters the "scrapy crawl IT_charge" command to execute.
If Chinese garbled or Unicode encoding appears, modify the BlogSpider.py or pipelines.py file to convert the unicode encoding.
A project example is given below to explain how to use the Scrapy framework to quickly crawl website data.
3 Use Scrapy to crawl agricultural product data sets
When doing data analysis, we usually encounter the situation of predicting commodity prices. Before predicting the price, it is necessary to crawl a large amount of commodity price information, such as Taobao, Jingdong commodities, etc. Here, Scrapy technology is used to crawl the Guizhou agricultural product data set.
Enter the URL " http://www.gznw.com/eportal/ui?pageId=595091 " to open the Guizhou Agricultural Economic Network, you can view the daily price fluctuations of agricultural products in various regions of Guizhou, as shown in the figure below, which mainly includes 6 fields : Variety name, price type, price, unit, market name and release time.
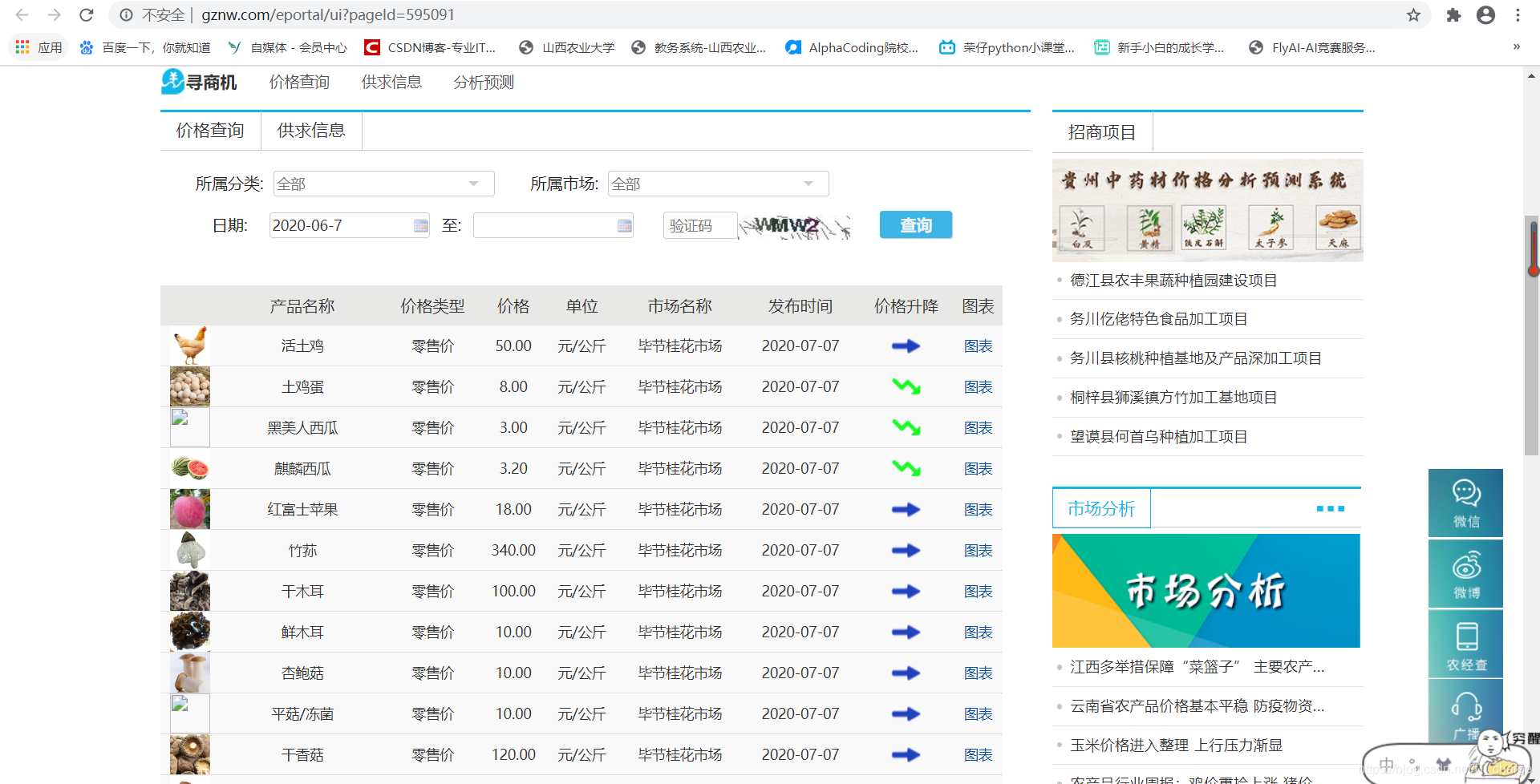
The main steps of Scrapy framework custom crawler are as follows:
- Create a crawler project under the cmd command line model, that is, create a SZProject project to crawl Guizhou Agricultural Economic Net.
- Define the data column to be captured in the items.py file, corresponding to the 6 fields of variety name, price type, price, unit, market name and release time.
- Analyze the DOM structure of the content to be crawled through the browser review element function and locate the HTML node.
- Create crawler files, locate and crawl the required content.
- Analyze the web page turning method, and send multiple page jump crawling requests, and continue to execute the crawler until the end.
- Set up the pipelines.py file and store the crawled data set in a local JSON file or CSV file.
- Set the settings.py file to set the execution priority of the crawler.
The following is the complete implementation process, focusing on how to achieve page turning crawling and multi-page crawling.
3.1 Create a project
In the Windows environment, press the Ctrl + R shortcut key to open the Run dialog box, then enter the cmd command to open the command line mode, then call the "cd" command to a certain directory, and then call the "scrapy startproject GZProject" command to create a crawling Guizhou farm Crawler project for product information through the web.

The command to create a Scrapy crawler is as follows:
scrapy startproject GZProject
3.2 Set the items.py file
Then define the fields that need to be crawled in the items.py file, here are mainly 6 fields. Call the Field() function of the scrapy.Item subclass to create a field, the code is as follows:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class GzprojectItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
num1 = scrapy.Field() # 品种名称
num2 = scrapy.Field() # 价格类型
num3 = scrapy.Field() # 价格
num4 = scrapy.Field() # 单位
num5 = scrapy.Field() # 市场名称
num6 = scrapy.Field() # 发布时间Next is the core content, analyzing the web page DOM structure and writing the corresponding crawler code.
3.3 Browser review elements
Open the browser, press the F12 key on the keyboard, and use the "Element Selector" to locate the specific target to view its corresponding HTML source code, as shown in the following figure:

It is observed that each row of data is located under the <tr> node; then the XPath, css and other functions of the scrapy framework are called to crawl.
3.4 Create a crawler and execute
Create a Python file under the Spider folder-GZSpider.py file, which is mainly used to implement crawler code. The specific code is as follows:
import scrapy
from scrapy import Request
from scrapy.selector import Selector
# from GZProject.items import *
class GZSpider(scrapy.Spider):
name = "gznw" # 贵州农产品爬虫
allowed_domains = ["gznw.gov.vn"]
start_urls = [
"http://www.gznw.com/eportal/ui?pageId=595091"
]
def parse(self, response):
print('----------------------Start-----------------------')
print(response.url)
for t in response.xpath('//title'):
title = t.extract()
print(title)Next execute the following command to start the crawler:
cd GZProject
scrapy crawl gznw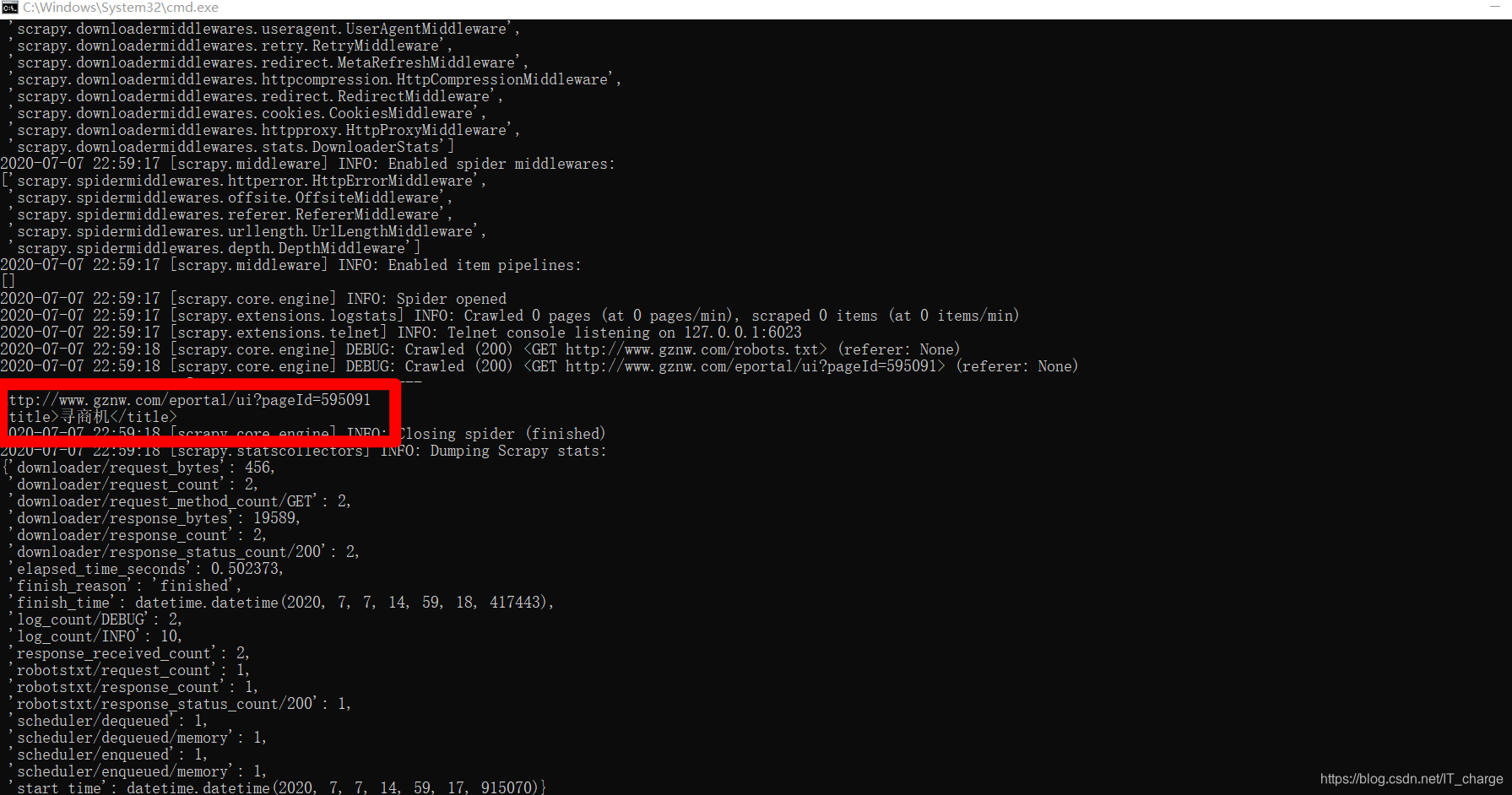
Next, crawl the product information and write the complete code as follows:
import scrapy
import os
import time
from selenium import webdriver
from scrapy import Request
from scrapy.selector import Selector
from GZProject.items import *
class GZSpider(scrapy.Spider):
name = "gznw" # 贵州农产品爬虫
# allowed_domains = ["http://www.gznw.com/eportal/ui?pageId=595091"]
start_urls = [
"http://www.gznw.com/eportal/ui?pageId=595091"
]
def parse(self, response):
print('----------------------Start-----------------------')
print(response.url)
# 打开 Chrome 浏览器,这顶等待加载时间
chromedriver = 'E:/software/chromedriver_win32/chromedriver.exe'
os.environ["webdriver.chrome.driver"] = chromedriver
driver = webdriver.Chrome(chromedriver)
# 模拟登录 163 邮箱
url = 'http://www.gznw.com/eportal/ui?pageId=595091'
driver.get(url)
time.sleep(5)
# 用户名、密码
for i in driver.find_elements_by_xpath(
'//*[@id="5c96d136291949729295e25ea7e708b7"]/div[2]/div[2]/table/tbody/tr'):
print(i.text)
3.5 Realize page turning crawling and multi-page crawling functions
Here are 3 page turning methods, please study the specific details:
Method 1: Define URL hyperlink list to crawl separately
start_urls = [
"地址 1"
"地址 2"
"地址 3"
] Method 2: Splicing URLs of different web pages and sending requests to crawl
next_url = "前半段URL地址" + str(i)Method 3: Get the next page hyperlink and request to crawl its content
i = 0
next_url = response.xpath('//a[@class="page=link next"]/@href').extract()
if next_(url is not None) and i < 20:
i = i + 1
next_url = '前半段网址' + next_url[0]
yield.Request(next_url, callback=self.parse)3.6 Set pipelines.py file to save data to local
import codecs
import json
class GzprojectPipline(object):
def __init__(self):
self.file = codecs.open('guizhou.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()3.7 Setting the settings.py file
ITEM_PIPELINES = {
'GZProject.piplines.GzprojectPipeline':1
}At this point, a complete Scrapy crawler example idea has been explained. I hope this article will be helpful to you, and I believe everyone has learned something.
4 Summary of this article
We can obtain information on various websites based on BeautifulSoup or Selenium technology web crawlers, but its crawling efficiency is too low, and Scrapy technology solves this problem well. Scrapy is a high-efficiency application framework for crawling network data and extracting structured data. The bottom layer is the asynchronous framework Twisted. The most popular part of Scrapy is its performance, good concurrency, high throughput improves its crawling and parsing speed, and the downloader is also multi-threaded. At the same time, Scrapy also has a good storage function, you can set rules to crawl URLs with certain rules, especially when you need to crawl a lot of real data, Scrapy is a convincing good framework.
Welcome to leave a message, learn and communicate together~
Thanks for reading