For crawlers, Python may be the first choice for many partners. We have to focus on learning Python crawlers. This article teaches you how to quickly master the core of Python crawlers! If there is something unclear, you can leave a message!
1 Overview
This article mainly implements a simple crawler, whose purpose is to download pictures from a Baidu Tieba page. The steps to download pictures are as follows:
Many people learn python and after mastering the basic grammar, they don't know where to find cases to get started.
Many people who have done case studies do not know how to learn more advanced knowledge.
So for these three types of people, I will provide you with a good learning platform, free to receive video tutorials, e-books, and the source code of the course!
QQ group: 701698587
(1) Get the html text content of the webpage;
(2) Analyze the html tag characteristics of the pictures in html, and use regular analysis to parse out the list of all picture url links;
(3) Download the picture to the local folder according to the url link list of the picture.
2. Implementation of urllib+re
#!/usr/bin/python
# coding:utf-8
# 实现一个简单的爬虫,爬取百度贴吧图片
import urllib
import re
# 根据url获取网页html内容
def getHtmlContent(url):
page = urllib.urlopen(url)
return page.read()
# 从html中解析出所有jpg图片的url
# 百度贴吧html中jpg图片的url格式为:<img ... src="XXX.jpg" width=...>
def getJPGs(html):
# 解析jpg图片url的正则
jpgReg = re.compile(r'<img.+?src="(.+?\.jpg)" width') # 注:这里最后加一个'width'是为了提高匹配精确度
# 解析出jpg的url列表
jpgs = re.findall(jpgReg,html)
return jpgs
# 用图片url下载图片并保存成制定文件名
defdownloadJPG(imgUrl,fileName):
urllib.urlretrieve(imgUrl,fileName)
# 批量下载图片,默认保存到当前目录下
def batchDownloadJPGs(imgUrls,path ='./'):
# 用于给图片命名
count = 1
for url in imgUrls:
downloadJPG(url,''.join([path,'{0}.jpg'.format(count)]))
count = count + 1
# 封装:从百度贴吧网页下载图片
def download(url):
html = getHtmlContent(url)
jpgs = getJPGs(html)
batchDownloadJPGs(jpgs)
def main():
url = 'http://tieba.baidu.com/p/2256306796'
download(url)
if __name__ == '__main__':
main()
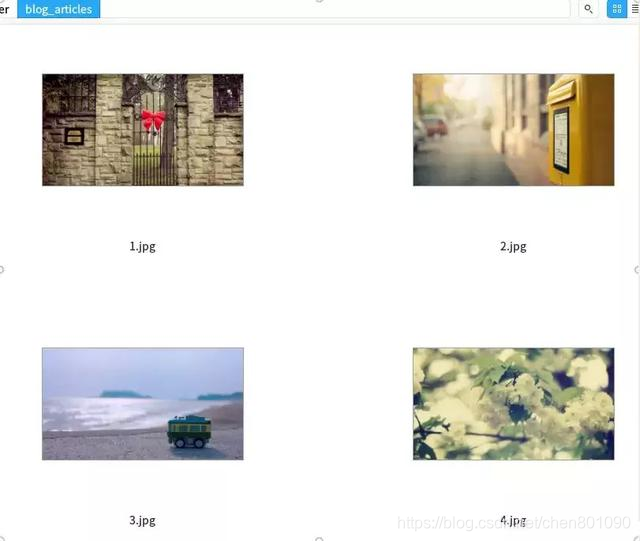
Run the above script, after a few seconds, the download is complete, and you can see that the image has been downloaded in the current directory:
3. Realization of requests + re
The following uses the requests library to realize the download, and reimplement both the getHtmlContent and downloadJPG functions with requests.
#!/usr/bin/python
# coding:utf-8
# 实现一个简单的爬虫,爬取百度贴吧图片
import requests
import re
# 根据url获取网页html内容
def getHtmlContent(url):
page = requests.get(url):
return page.text
# 从html中解析出所有jpg图片的url
# 百度贴吧html中jpg图片的url格式为:<img ... src="XXX.jpg" width=...>
def getJPGs(html):
# 解析jpg图片url的正则
jpgReg = re.compile(r'<img.+?src="(.+?\.jpg)" width') # 注:这里最后加一个'width'是为了提高匹配精确度
# 解析出jpg的url列表
jpgs = re.findall(jpgReg,html)
return jpgs
# 用图片url下载图片并保存成制定文件名
def downloadJPG(imgUrl,fileName):
# 可自动关闭请求和响应的模块
from contextlib import closing
with closing(requests.get(imgUrl,stream = True)) as resp:
with open(fileName,'wb') as f:
for chunk in resp.iter_content(128):
f.write(chunk)
# 批量下载图片,默认保存到当前目录下
defbatchDownloadJPGs(imgUrls,path ='./'):
# 用于给图片命名
count = 1
for url in imgUrls:
downloadJPG(url,''.join([path,'{0}.jpg'.format(count)]))
print '下载完成第{0}张图片'.format(count)
count = count + 1
# 封装:从百度贴吧网页下载图片
def download(url):
html = getHtmlContent(url)
jpgs = getJPGs(html)
batchDownloadJPGs(jpgs)
def main():
url = 'http://tieba.baidu.com/p/2256306796'
download(url)
if __name__ == '__main__':
main()
Output: Same as before.
Hope this simple python crawler case can help you who are new to Python crawler!