
Preface
As mentioned in the previous article, there is still a lot of room for development in the testing methods of machine learning systems at an early stage, and there are also many directions involved.
After discussing model evaluation and model testing, let's take a look at how to combine and practice these methods .
How to write model tests
There are usually two types of model testing:
-
Pre-training test (Pre-train tests), eliminate errors early, before training and strive to minimize errors and reduce unnecessary training time model
-
After training test (Post-train tests), using a model trained, a scene of acts of identification
Pre-training test
As a test without model parameters, the relevant content is as follows:
-
Check the output format of the model to ensure that it is consistent with the label of the data set
-
Check the output range and ensure that it is consistent with expectations (for example, the output of the classification model should be a probability distribution)
-
Ensure that the effect of each gradient step on each batch of data is reduced
-
Make reasonable assertions on the data set
-
Check the label integrity of the training set and validation set
Test after training
In order for us to understand the behavior of the model, it is necessary to test the trained model to check whether the logic of the trained model is reasonable .
Here is a paper recommended: Beyond Accuracy: Behavioral Testing of NLP Models with CheckList.
(https://homes.cs.washington.edu/~marcotcr/acl20_checklist.pdf)
This article introduces three good model testing methods for understanding behavior and attributes, let's take a look at them one by one.
Immutability test
The invariance test is to introduce a set of perturbations, but to make this input do not affect the output of the model.
In practice, these disturbances can be used to generate one-to-one input values (original and disturbed), and to check the consistency of model predictions.
This method is closely related to the concept of data increment, meaning that perturbation is applied to the input during training and the original label is retained.
For example, run a sentiment analysis model on the following two sentences:
-
Mark is a great coach. (Mark was a great instructor.)
-
Samantha is a great coach. (Samantha was a great instructor.)
The expectation here is that only changing the names of the actors will not affect the predictions of the model.
Directed expectation test
In contrast, the directional expectation test is to define a set of disturbances to the input, but these disturbances should have a predictable effect on the model output .
For example, if we predict a model for housing prices, we might assert:
-
Increasing the number of bathrooms (keep all other functions unchanged) should not lead to a price drop
-
Reducing the size of the house (keeping all other characteristics unchanged) should not lead to an increase in prices
Here, let us imagine a scenario where the model fails in this test-randomly extract a row from the verification data set and reduce a certain characteristic feature,
As a result, its expected price is higher than the original label. Maybe this is not intuition, so we decided to investigate further.
Finally, it is found that the choice of data set affects the logic of the model in an unexpected way , and this can not be easily found just by checking the performance indicators of the validation set.
Minimal functional test (data unit test)
Just as the software unit test aims to isolate and test the basic modules in the code, the data unit test here is for the performance test of the quantitative model in a specific situation .
Doing so can ensure that the critical scenarios that cause errors are identified, and more generalized data unit tests can be written for the failure modes found during error analysis to ensure that similar errors can be automatically searched in the model in the future.
Fortunately, there are already many shaping methods. Taking Snorkel as an example, its slice function can be used to efficiently and conveniently identify subsets of data sets that meet certain standards.
(https://www.snorkel.org/use-cases/03-spam-data-slicing-tutorial)
For example, you can write a slicing function to recognize sentences with less than 5 words to evaluate the performance of the model on short text fragments.
Build test

In traditional software testing, tests that reflect the organization of the code are usually constructed.
However, this method cannot serve the machine learning model well, because the logic of the machine learning model composed of the learned parameters has become very dynamic , making the traditional testing method no longer applicable.
In the paper Beyond Accuracy: Behavioral Testing of NLP Models with CheckList just recommended,
The author’s suggestion is to build tests for the “skills” that the expected model will acquire when learning to perform a given task .
For example, a sentiment analysis model requires a certain understanding of the following items:
-
Vocabulary and parts of speech (vocabulary and parts of speech)
-
Robustness to noise
-
Identifying named entities
-
Temporal relationships (emporal relationships)
-
Negation of words in grammar
An image recognition model needs to recognize the following concepts:
-
Object rotation
-
Partial occlusion
-
Perspective shift
-
Lighting conditions
-
Weather phases, such as rain, snow, fog (weather artifacts, eg, rain, snow, fog)
-
Camera virtual images, such as ISO noise, motion blur (camera artifacts, eg, ISO noise, motion blur)
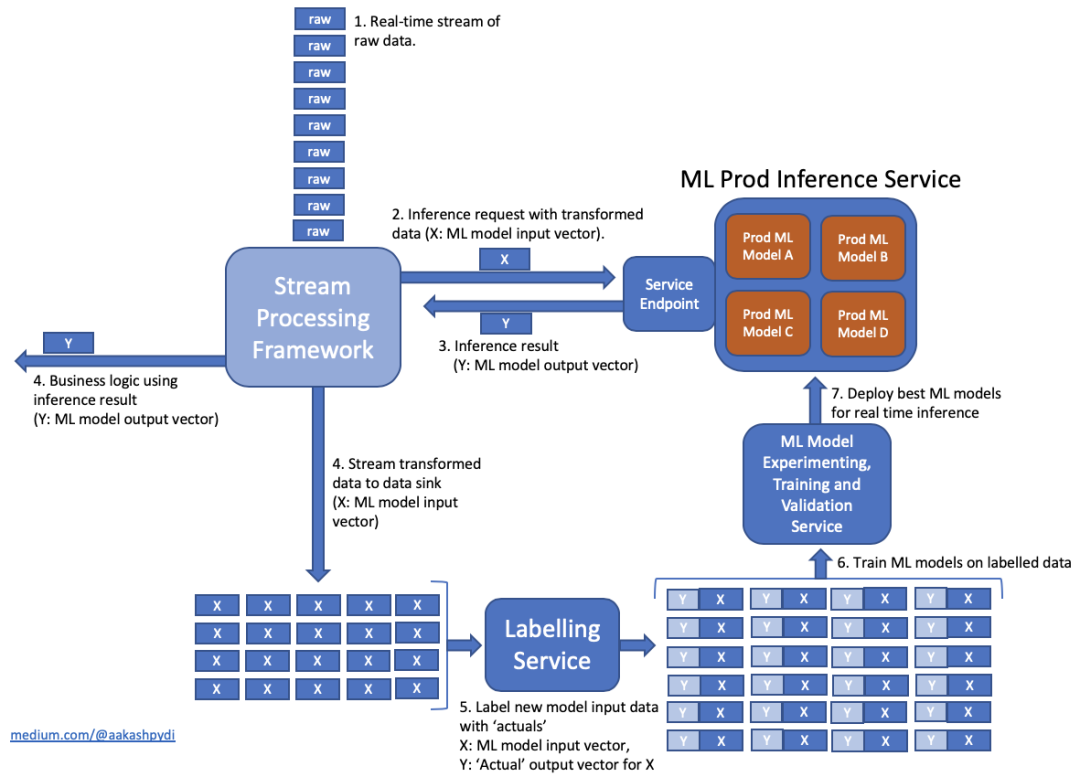
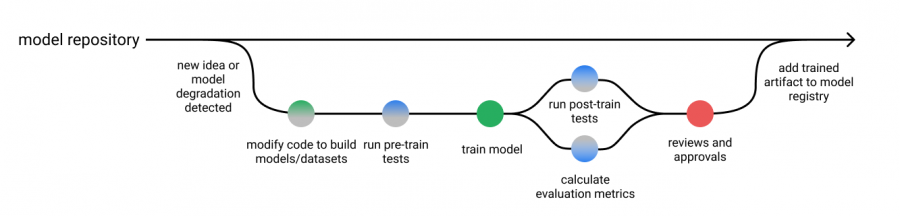
Machine learning model development process
Putting the various methods and elements mentioned above together, then we can modify the model development process we mentioned in the first article of this series, including pre-training and post-training tests.
These test outputs can be displayed with the model evaluation report so that they can be reviewed at the last step of the process.
Of course, according to the respective nature of the training model and certain specified standards, you can choose whether to automate the approval.
in conclusion
I have to say that in reality, the testing of machine learning systems is tricky, because the system logic cannot be clearly written during the development process.
However, this does not mean that a lot of manual adjustments are involved, and automated testing is still an important part of developing high-quality software systems.
These tests can provide us with reports on the behavior of the training model and can be a systematic method of error analysis.
In this blog post, the author separates "traditional software development" and "machine learning model development" into two relatively independent concepts. This simplification makes it easier to discuss related to testing machine learning systems;
However, the real world is much more chaotic. The development of machine learning models still relies on a large number of "traditional software development" models to process data input, create model features, perform data expansion, design training models, and expose interfaces to external systems, etc. Wait.
Therefore, effective testing of machine learning systems still requires an organic combination of a traditional software testing process (for model development infrastructure) and a model testing process (for trained models).
It is hoped that this article can provide some reference for the work of related practitioners. At the same time, readers are also welcome to share their own work experience.
