Article Directory
1. Introduction to thread pool
1. What is a thread pool
First of all, we can refer to the answer given by Baidu Baike:
Thread pool is a form of multi-threaded processing. Tasks are added to the queue during processing, and then these tasks are automatically started after threads are created.
Then we can use the answer of Baidu Baike to further define:
create a certain number of threads at the beginning of the process and add them to the pool to wait for work. When the server receives a request, it will wake up a thread in the pool (if there is an available thread), and pass the request that needs to be serviced to it. Once the thread has completed the service, it will return to the pool and wait for work. If there are no threads available in the pool, the server will wait until there are free threads.
2. Why use thread pool
Here we first use multithreading to implement a simple accumulation scenario:
public class Demo01 {
public static int count = 0;
public static int Max = 100000;
public static void main(String[] args) throws InterruptedException {
long currentTimeMillis = System.currentTimeMillis();
while (count < Max) {
Thread thread = new Thread(() -> {
count++;
});
thread.start();
thread.join();
}
System.out.println("多线程执行时长:" + (System.currentTimeMillis() - currentTimeMillis));
}
}
Here is a look at the running results.

Here, we can find that a simple count accumulation operation, due to the use of multi-threaded processing, the processing time is even longer than single-threaded processing, and thread creation and instantiation are undoubtedly caused frequently. CPU context switching and additional memory overhead, which obviously makes us reluctant to see.
Then we look at the way to use the thread pool
public class Demo01 {
public static int count = 0;
public static int Max = 100000;
public static void main(String[] args) throws InterruptedException {
ExecutorService newCachedThreadPool = Executors.newCachedThreadPool();
long currentTimeMillis = System.currentTimeMillis();
while (count < Max) {
newCachedThreadPool.execute(() -> {
count++;
});
}
System.out.println("线程池执行时长:" + (System.currentTimeMillis() - currentTimeMillis));
newCachedThreadPool.shutdown();
}
}
Results:

So why can the thread pool save so much time?
3. The realization principle of thread pool
As a kind of pooling technology, thread pool is actually a kind of container. There are actually two data structures used to implement the container:
- The first data structure is used to store a collection of worker threads
- The second data structure is used to store the queue of tasks to be executed
Here I simply draw a picture:
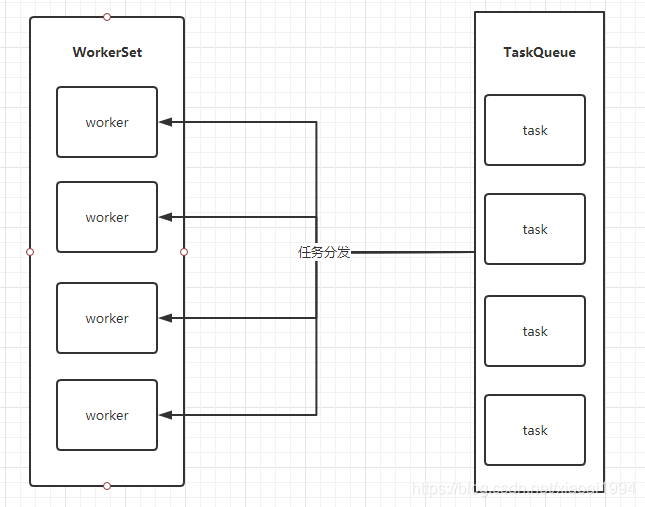
When the user submits a task to the thread pool, he first puts the task into the blocking queue, and then the threads in the thread set will continue to go to the queue to get the task and execute it. When the tasks are all executed , The threads in the thread collection will block. Does this look like the production/consumption model mentioned before when talking about the wait method ? So how do we create a thread pool?
4. The way to create a thread pool
Usually we will use two ways to create a thread pool.
4.1 Created by construction method
Here we first look at how to create a thread pool through the construction method:
public class Demo01 {
public static void main(String[] args) {
new ThreadPoolExecutor(5, 20, 2, TimeUnit.SECONDS, new LinkedBlockingQueue<>(5));
}
}
In fact, it is not difficult to create a thread pool by means of a constructor. The important thing to talk about is some of the parameters involved.

- corePoolSize : refers to the number of core threads in the thread pool. Core threads refer to a part of threads that will not be recycled when the thread pool is idle. Setting the core thread can effectively reduce the performance overhead caused by thread creation and recycling. Of course, it should be noted that it is not very good to set the core thread too large or too small. We can calculate the core thread through a simple formula How much is the most cost-effective setting: number of core threads = number of CPU cores * CPU usage * (1 + throughput ). Of course, if it is some simple applications, we can directly set the number of 2*CPU cores, and get the number of CPU cores by int availableProcessors = Runtime.getRuntime().availableProcessors();
- maximumPoolSize : The maximum number of threads in the thread pool, which refers to the maximum capacity that the thread pool can contain. The setting of the maximum number of threads is best to refer to the business scenario. It is not recommended to set too large, because it may cause OOM problems (out of memory). exception).
- keepAliveTime : Keep alive time, which refers to the maximum survival time of non-core threads in idle state when the current number of threads is greater than the number of core threads. When the idle time is greater than the maximum survival time, the life cycle of the idle thread will end.
- TimeUnit : What is the unit of waiting time, such as hours, minutes, and seconds.
- workQueue : Indicates which kind of waiting queue is used to implement the thread pool. Common queue structures are LinkedBlockedQueue, SynchronousQueue, etc.
4.2 Factory method
Of course, if you think the way to construct a method is too troublesome, Java also provides a factory method class Executors .

Before talking about the different thread pools created by these different factory methods, we need to mention that the method of using the factory method to create a thread pool is not recommended for use in a production environment. The reason is also very simple, because the thread pool created by the factory method The default maximum number of threads is Integer.MAX_VALUE, as mentioned before when talking about the maximum number of threads, if the maximum number of threads is too large, it will cause memory overflow.
Next, I will briefly talk about several common thread pools:
- newCachedThreadPool : Create a cacheable thread pool. If the length of the thread pool exceeds the processing needs, idle threads can be recycled flexibly. If there is no recyclable, a new thread will be created.
2. newFixedThreadPool : Create a fixed-length thread pool, and create a worker thread whenever a task is submitted. If the number of worker threads reaches the maximum number set by the thread pool, it will be submitted to threads in the thread pool to complete the task.
3. newSingleThreadExecutor : Single-threaded Executor only creates a single worker to perform tasks. All tasks are executed in FIFO order. If the current thread is abnormal, a new thread will be created to replace him and continue to perform the task. Its biggest feature is that the order of execution of tasks is orderly.
4. newScheduleThreadPool : A fixed-length thread pool that supports periodic task execution.- NewSingleThreadScheduledExecutor is a single-threaded thread pool that can execute tasks periodically.
Second, the common API of thread pool
1. execute
Let's first look at the definition of methods in the API documentation.

The execute method is mainly used to perform tasks that we want to delegate to the thread pool. Since his return value is void, it means that he will not return any object when the method ends, and he will throw an exception as soon as it encounters an exception. Here we can look at the source code of the execute method:
public void execute(Runnable var1) {
if (var1 == null) {
throw new NullPointerException();
} else {
int var2 = this.ctl.get();
if (workerCountOf(var2) < this.corePoolSize) {
if (this.addWorker(var1, true)) {
return;
}
var2 = this.ctl.get();
}
if (isRunning(var2) && this.workQueue.offer(var1)) {
int var3 = this.ctl.get();
if (!isRunning(var3) && this.remove(var1)) {
this.reject(var1);
} else if (workerCountOf(var3) == 0) {
this.addWorker((Runnable) null, false);
}
} else if (!this.addWorker(var1, false)) {
this.reject(var1);
}
}
}
Let's briefly analyze the implementation steps of the execute method in the source code:
- Get the number of core threads in the current thread pool. If the number of core threads that exist at this time is less than the maximum number of core threads set, then a new core thread will be created and added to the thread pool at this time
- If a task task has been added to the queue, you still need to re-judge whether you need to add a new thread, because at this time the newly created I want to love you may have died or the thread pool may be restarted, so we need to recheck the thread status In order to roll back the task when necessary.
- If the task cannot be added to the queue and a new thread cannot be obtained, it means that the thread pool is saturated or dead, and the task will be rejected.
2. submit
By convention,
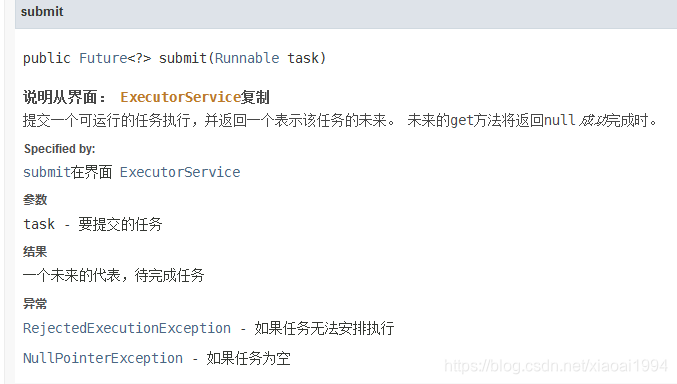
let’s take a look at the official document first: The submit method is very similar to the execute method, both of which are used to perform tasks that we want to delegate to the thread pool, but the submit method will return a future object representing the result of the task after execution. If an exception occurs during operation, the exception will be swallowed by the submit method and added to the future object. Of course, there is one more thing to note. The submit method allows two types of parameters to be received. One is an object that implements the runnable interface. In this case, although the future object can get, the result is always null. The other is an object that implements the callable interface, where the submit method has a return value and allows exceptions to be thrown.
3. The difference between execute method and submit method
- execute() parameter Runnable; submit() parameter (Runnable) or (Runnable and result T) or (Callable)
- execute() has no return value; submit() has return value
- The return value of submit() Future calls the get method, you can catch and handle exceptions
Three, thread pool tools
Here I provide a simple thread pool tool class implementation, which can be adjusted according to the actual situation.
public class ThreadPoolUtil {
// 自适应核心线程数
private static final int corePoolSize = Runtime.getRuntime().availableProcessors() * 2;
// 最大线程数
private static final int maximumPoolSize = 500;
// 存活时间
private static final int keepAliveTime = 10;
// 存活时间计数方式
private static final TimeUnit timeUnit = TimeUnit.SECONDS;
// 任务队列
private static final BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(10);
// 单例模式
private static volatile ThreadPoolExecutor threadPool;
public static ThreadPoolExecutor getPool() {
if (threadPool == null) {
synchronized (ThreadPoolUtil.class) {
if (threadPool == null) {
threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, timeUnit,
workQueue);
}
}
}
return threadPool;
}
private ThreadPoolUtil() {
super();
// TODO Auto-generated constructor stub
}
}