Introduction
Beautiful Soup is a powerful parsing library that can be used to parse HTML code to extract information, but it runs slowly. There is no need to learn the corresponding grammar like xpath and regular expressions, and only need to call the corresponding method to achieve information extraction.
commonly used ways
find()
find_all()
get_text()
string
strings
stripped_strings
select
The difference between find() and find_all()
Suppose we already have a html code character that has been obtained
from bs4 import BeautifulSoup
soup = BeautifulSoup(html,'lxml')
#这里选择lxml为解析器,需要先安装lxml这个库
date=soup.find('标签名')
date2=soup.find('标签名')
The note here is that BeautifSoup is found through the nodes in the html code. The
difference between find() and find_all() is that find() returns the data of the first target tag and find_all() returns all
Extract tags with special attributes
Suppose there is a label <div class='123'>456</div>
we just write;
date=soup.find_all('div',class_='123')
Since the attribute class has the same name as the python keyword, we must use an underscore to distinguish it.
Or you can write like this;
date=soup.find_all('div',attrs={
'class':'123'})
If more conditions need to be met at the same time, such as extracting this label;
<div class='123',classx='789'>456</div>
we can do this;
date=soup.find_all('div',attrs={
'class':'123','classx':'789'})
或者;
date=soup.find_all('div',class_='123',classx='789')
Note that what is returned here is an object of element.request instead of a list, but it can also be manipulated like a list.
Extract text and attribute values (string and strings)
1. Extract text, also take the example just now; <div class='123'>456</div>
extract 456 information
Method one;
#由于目前只有一个div标签并且没有或者只有一个子节点如果有多个div可以放进循环当中遍历。
date=soup.find_all('div',class_='123',classx='789')[0]
text=date.string
#这里返回一个字符串,提取当前一个节点下的文字
Method Two;
date=soup.find_all('div',class_='123',classx='789')
#假设div的匹配结果唯一
texts=list(date.strings)
text=[]
for text_one in texts;
text.append(text_one)
"""
这里需要注意的是strings可以提取改节点下所有文字 假设div节点下面有多个子节点,有多个则可以使用strings但是返回的是一个生成器可以遍历出来。
"""
In a more complicated situation, there are multiple div nodes and multiple child nodes (dx) below to extract text.
The code is as follows;
(using strings)
text=[]#存放文本信息
divs=soup.find_all('div',class_='123',classx='789')
for div in divs;
dates=div.strings
for date in dates;
text.append(date)
(Use string)
text=[]#存放文本信息
divs=soup.find_all('div',class_='123',classx='789')
for div in divs;
dxs=div.find_all('dx')
for dx in dxs;
date=dx.string
text.append(date)
How to extract the attribute value. For example <div class='123'>456</div>, the
code of '123' in the extraction is as follows;
date=soup.find_all('div',class_='123')
attribute=date['class']
For every returned object, there are attributes (attributes in html) (attributes in BeautifulSoup).
Handle blanks
Use strings to place the extracted blanks in the list so it can be like this;
use stripped_strings
text=[]#存放文本信息
divs=soup.find_all('div',class_='123',classx='789')
for div in divs;
#dates=div.strings
dates=list(div.stripped_strings)
for date in dates;
text.append(date)
Use select and css statements
The first thing to explain is that select() is similar to find_all(). The difference is that the filter conditions are different.
Such as screening; <div class='123'>456</div>(assuming that it matches the result only)
divs=soup.find_all('div',class_='123',classx='789')
divs=soup.select('div.123')
Both have the same effect, but the latter requires the use of css selection statements.
css select statement
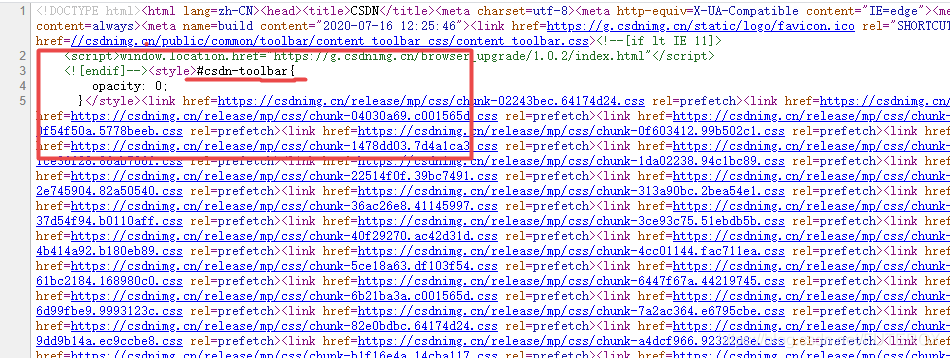
The underlined part in the box is the selection sentence, which is used to filter specific nodes for layout.
The statement is shown in the following table;
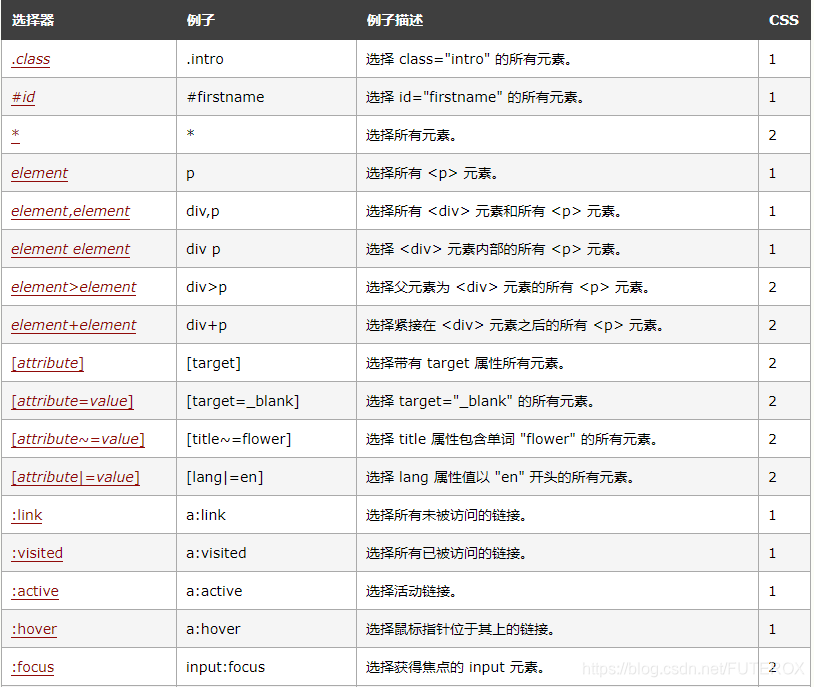
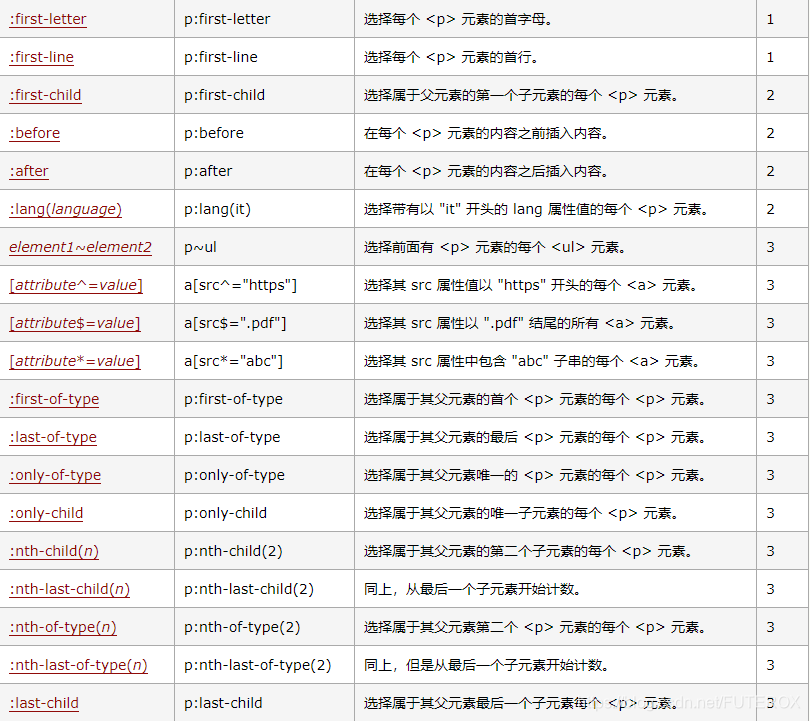
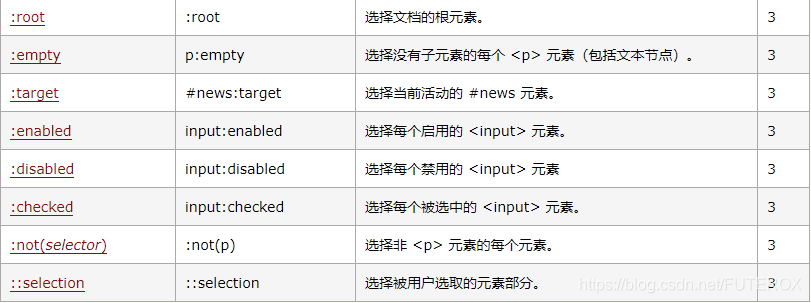
More specific content can be viewed at 3wschool , but generally speaking, you can’t use that much, basically you can use find_all() to achieve, and the efficiency of simple web page information crawling and extracting information is lower than that of Xpath. It is a better choice to choose regular Because it can not only extract html information, it can extract almost all text information. If you are interested, you can check the python crawler series on the blog I wrote before
(3)