After learning of the capture, interface requests (such as requests library) and a number of methods of operation Selenium, basically you can write reptiles crawling content of most websites.
In the field of reptiles, Selenium is always the last line of defense. In essence, access the web page is actually an interface request. The request url, returns the page's source code.
We just need to parse html or extract the data we need to pass a regular match.
Some sites we can use requests.get (url), the response text obtained to get all the data. And some web page data is dynamically loaded into the page by the JS. Use requests not obtain or can only get to the portion of the data.
At this point we can use selenium to open the page, use driver.page_source to get the full source code after the JS execution.
For example, we have to crawl, name diro official website handbags, price, url, pictures and other data, you can use the requests to get into the page source:
visit web pages open developer tools, we can see that all the goods are in a
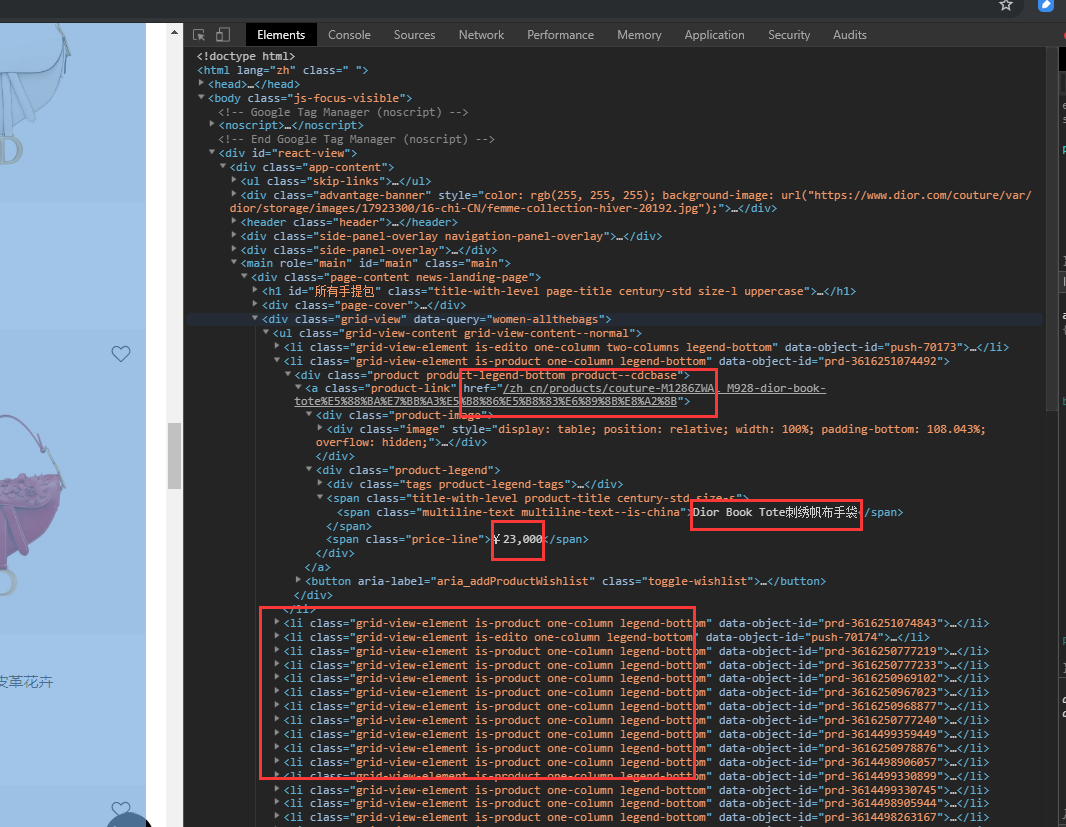
Extracted from the source data in html format, a variety of options, and the like may be used xml.etree embodiment, BS4 is a relatively easy to use html parsing library, mating with lxml faster.
The use of bs4
from bs4 import BeautifulSoup
soup = BeautifulSoup(网页源代码字符串,'lxml')
soup.find(...).find(...)
soup.findall()
soup.select('css selector语法')soup.find () you can search through the node attributes, such as, soup.find('div', id='节点id')or soup.find('li', class_='某个类名')or soup.find('标签名', 属性=属性值), after finding a node, this node may be used to continue to look at its subnodes.
soup.findall () is to find more of the same attributes of nodes, it returns a list.
soup.select () is to use css selector syntax lookup returns a list.
Following is sample code:
from selenium import webdriver
from bs4 import BeautifulSoup
driver = webdriver.Chrome()
driver.get('https://www.dior.cn/zh_cn/女士精品/皮具系列/所有手提包')
soup = BeautifulSoup(driver.page_source, 'lxml')
products = soup.select('li.is-product')
for product in products:
name = product.find('span', class_='product-title').text.strip()
price = product.find('span', class_='price-line').text.replace('¥', '').replace(',','')
url = 'https://www.dior.cn' + product.find('a', class_='product-link').attrs['href']
img = product.find('img').attrs['src']
sku = img.split('/')[-1]
print(name, sku, price)
driver.quit()Operating results, as shown below:
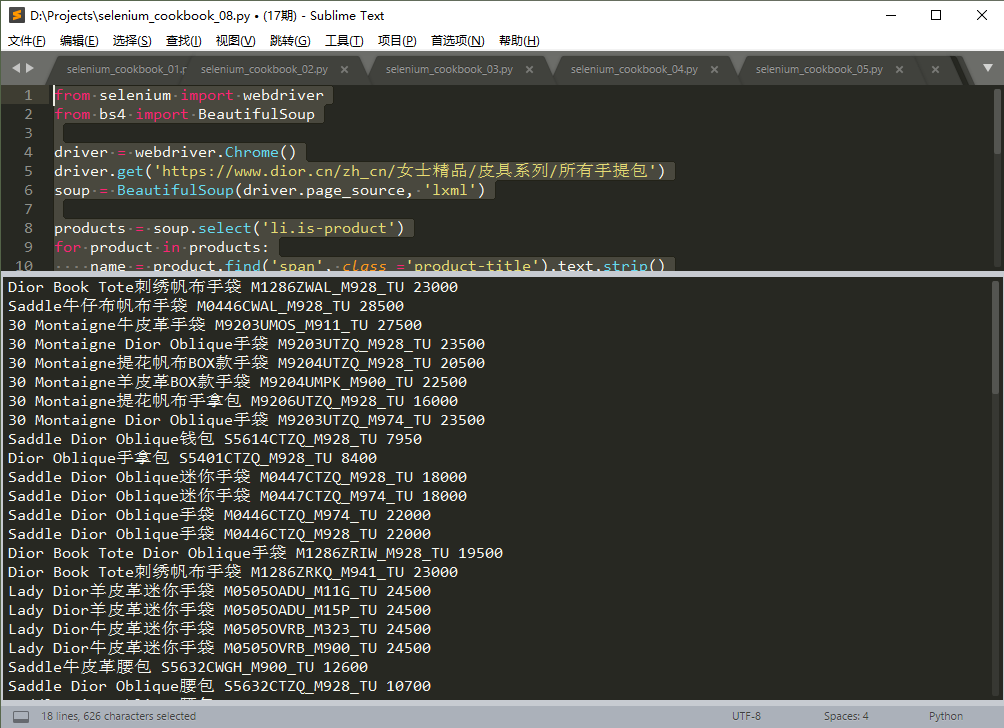
Note: In this example, may be used requests.get () Get page source code, the format and use of slightly different loading selenium.
The general steps to write a simple reptiles are:
- Into the list page, open developer tools, refresh the page and scroll down to see the new product is loaded, if you can catch XHR data interface (direct return JSON format for all product data interfaces)
- If there is such an interface, try to modify the values of the parameters in the pagination, and the total value of the request to see if the interface from a return of all product data
- If only Doc types of interfaces return to the page, try using requests.get () requests a page, analyzing the response text, contains all the product data
- If you can not get product data requests or incomplete data can be used selenium load the page, and then use bs4 direct extraction, if there is more than one page, one by one cycle of operation can be.