DataWhale & Pandas (three, index)
Study outline:
table of Contents
DataWhale & Pandas (three, index)
4.1 Multi-level index and its table structure
4.2 loc indexer in multi-level index
5.1. Exchange and deletion of the index layer
5.2 Modification of index attributes
Ex1: Company employee data set
Three, index
First need to import numpy and pandas libraries
import numpy as np
import pandas as pd
3. Indexer
The dataframe is divided into row index and column index.
- Row index: index
- Column index: columns
3.1 Column Index
Column index is relatively common, and it is generally
[]implemented through , for example, the following example extracts the name column from the data set:
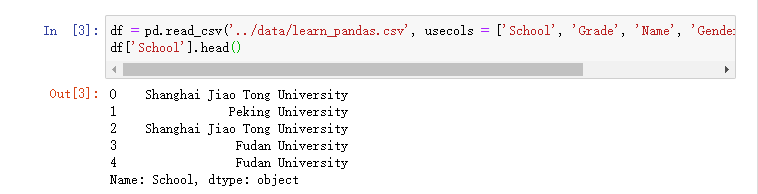
df = pd.read_csv('../data/learn_pandas.csv',
usecols = ['School', 'Grade', 'Name',
'Gender', 'Weight', 'Transfer']) #导入数据集
df['Name'].head() #取出姓名这列
In the same way, taking out the school column is:
We have learned how to extract one column. At this time, we extract multiple columns and try it out. Let's extract two columns of gender and name to try:

note:
- If you want to get a single column, and the column name does not contain spaces, you can use
.列名Get out, which[列名]is equivalent to.NAME = [NAME]
3.2 Row Index
String indexed
Series
- If you take out the corresponding element of a single index, you can use it
[item], ifSeriesthere is only a single value corresponding, then return this scalar value, if there are multiple values corresponding, then return oneSeries- If you take out the corresponding elements of multiple indexes, you can use
[items的列表]- If you want to take out the elements between two indexes, and these two indexes are the only ones in the whole index, you can use slices, and you need to pay attention to the slices here will contain two endpoints
Integer indexed
Series
- When using the data reading function, if the corresponding column is not specified as an index, an integer index starting from 0 will be generated as the default index. Of course, any set of integers that meet the length requirement can be used as an index.
- Like a string, if you use
[int]or[int_list], you can get the value of the corresponding index element- If an integer slice is used, the value of the corresponding index position will be taken out . Note that the integer slice here
Pythondoes not contain the right endpoint like the slice in
note:
Do not use pure floating point and any mixed type (a mixture of string, integer, floating point types, etc.) as an index , otherwise an error may be reported during specific operations or unexpected results may be returned
3.3 loc indexer
For tables, there are two indexers,
- One is an element- based
locindexer,- The other is a location- based
ilocindexer.
locThe general form of the indexer isloc[*, *], where:
*Selection of the first representative row*Selection of the second representative columnIf the second position is omitted
loc[*], this*refers to the filtering of rows.Among them,
*there are five types of legal objects in the position, namely : single element, element list, element slice, boolean list and function
Use the
set_indexmethod here toNameset the column as an index
df_demo = df.set_index('Name')
df_demo.head()
1. *As a single elementAt this point, directly take out the corresponding row or column, if the element is repeated in the index, the result is
DataFrame, otherwise it isSeriesdf_demo.loc['Qiang Sun'] # 多个人叫此名字 df_demo.loc['Quan Zhao'] # 名字唯一
You can also select rows and columns at the same time
df_demo.loc['Qiang Sun', 'School'] # 返回Series df_demo.loc['Quan Zhao', 'School'] # 返回单个元素


2. *List of elementsGet the row or column corresponding to all element values in the list
df_demo.loc[['Qiang Sun','Quan Zhao'], ['School','Gender']]

3. *For sliceAs
Seriesmentioned in the previous use of string indexing, if it is the start and end characters of a unique value, then slices can be used and contain two end points. If they are not unique, an error will be reported.df_demo.loc['Gaojuan You':'Gaoqiang Qian', 'School':'Gender']
It should be noted that if
DataFramean integer index is used, when using integer slicing, it is consistent with the above string index requirements. They are all element slicing, including endpoints and no duplicate values are allowed at the start and end points.df_loc_slice_demo = df_demo.copy() df_loc_slice_demo.index = range(df_demo.shape[0],0,-1) df_loc_slice_demo.loc[5:3] df_loc_slice_demo.loc[3:5] # 没有返回,说明不是整数位置切片


4. *Boolean listIn actual data processing, it is very common to filter rows based on conditions.
locThe Boolean list passed in here has theDataFramesame length, andTruethe row corresponding to the position of the list will be selected andFalseremoved.For example, select students who weigh more than 70kg
df_demo.loc[df_demo.Weight>70].head() #选出体重超过70kg的学生 df_demo.loc[df_demo.Grade.isin(['Freshman', 'Senior'])].head() #选出所有大一和大四的同学信息 # 选出复旦大学中体重超过70kg的大四学生,或者北大男生中体重超过80kg的非大四的学生 condition_1_1 = df_demo.School == 'Fudan University' condition_1_2 = df_demo.Grade == 'Senior' condition_1_3 = df_demo.Weight > 70 condition_1 = condition_1_1 & condition_1_2 & condition_1_3 condition_2_1 = df_demo.School == 'Peking University' condition_2_2 = df_demo.Grade == 'Senior' condition_2_3 = df_demo.Weight > 80 condition_2 = condition_2_1 & (~condition_2_2) & condition_2_3 df_demo.loc[condition_1 | condition_2] ##同时使用多个条件时可以通过定义布尔值变量进行多条件筛选


5.
*For functionsThe function here must use one of the four legal forms as the return value, and the input value of the function
DataFrameitself.def condition(x): condition_1_1 = x.School == 'Fudan University' condition_1_2 = x.Grade == 'Senior' condition_1_3 = x.Weight > 70 condition_1 = condition_1_1 & condition_1_2 & condition_1_3 condition_2_1 = x.School == 'Peking University' condition_2_2 = x.Grade == 'Senior' condition_2_3 = x.Weight > 80 condition_2 = condition_2_1 & (~condition_2_2) & condition_2_3 result = condition_1 | condition_2 return result df_demo.loc[condition] ##这里的函数返回值必须是前面要求的布尔值列表

note:
Don't use chain assignment
When assigning a value to a table or sequence, you should directly perform the assignment operation after using a layer of indexer. This is because the assignment is assigned to the temporarily returned
copycopy after multiple indexing , and the element is not actually modified and theSettingWithCopyWarningwarning is reported . .
3.4.iloc
.iloc() is an integer-based index , which uses the index number of the element on each axis to select. If the number exceeds the range, an IndexError is generated. When slicing, the number is allowed to exceed the range.
- Integer, similar to .loc, uses only one dimension, that is, for row selection, the subscript starts from 0 by default. For example: df.iloc[5], select row 6 of df.
- Integer list or array, such as df.iloc[[5, 1, 7]], select df row 6, row 2, and row 8.
- The slicing operation whose elements are integers is different from .loc, and the data whose subscript is stop is not selected. For example: df.iloc[0:3], which only contains rows 0, 1, and 2, but does not contain row 3.
- You can also use Boolean arrays for filtering, such as df.iloc[np.array(df.A>0.5)], df.iloc[list(df.A>0.5)].
- Note that when using a boolean array to filter, you can use list or array. Using Series will cause errors, NotImplementedError and ValueError. The former is when the index of the Series is different from the index of the DataFrame to be sliced, an error will be reported. Use Boolean array with .loc, you can use list, array, or Series. When using Series, the index needs to be consistent, otherwise IndexError will be reported.
4. Multi-level index
4.1 Multi-level index and its table structure
1. Implicitly created
Implement multiple arrays such as index and colunms in the constructor (both datafarme and series are available)
2. Explicitly create pd.MultiIndex
Among them. from_arrays is the parameter, it is recommended to use a simple from_product function
4.2 loc indexer in multi-level index
df_m=df.set_index(['School','Grade'])

note:
- Index names and values of properties are by
namesandvaluesget- If you want to get the index of a certain layer, you need to
get_level_valuesget- But for the index, whether it is a single-level or a multi-level, the user cannot
index_obj[0] = itemmodify the element inindex_name[0] = new_namea way , nor can the name be modified in a way- It is best to
MultiIndexsort before indexing to avoid performance warnings- Similar to a single-level index, if there are duplicate elements, slices cannot be used. Please remove the duplicate index and give an example of element slices
5. Common methods of indexing
5.1. Exchange and deletion of the index layer

5.2 Modification of index attributes
By
rename_axiscan modify the name of the index layer, commonly used method is to modify the mapping of incoming Dictionary
df_ex.rename_axis(index={'Upper':'Changed_row'}, columns={'Other':'Changed_Col'}).head()
renameYou can modify the value of the index through , if it is a multi-level index, you need to specify the modified layer numberlevel
df_ex.rename(columns={'cat':'not_cat'}, level=2).head()
5.3. Index setting and reset
new_df= pd.DataFrame({'H':list('hello'),'W':list('World'),'S':[1,2,3,4,5]})
# 索引的设置可以使用 set_index 完成,
# 其主要参数是 append ,表示是否来保留原来的索引,直接把新设定的添加到原索引的内层
df_new.set_index('A')
df_new.set_index('A', append=True)
#可以同时指定多个列作为索引
df_new.set_index(['A', 'B'])
#如果想要添加索引的列没有出现再其中,那么可以直接在参数中传入相应的Series
my_index = pd.Series(list('WXYZA'), name='D')
new_df=new_df.set_index(['H',my_index])
df_new
# reset_index 是 set_index 的逆函数,其主要参数是 drop ,
df_new.reset_index(['D'])
# 表示是否要把去掉的索引层丢弃,而不是添加到列中
df_new.reset_index(['D'],drop=True)
#如果重置了所有的索引,那么pandas会直接重新生成一个默认索引
df_new.reset_index()
5.4 Deformation of Index
In some cases, it is necessary to expand or eliminate the index. More specifically, it is required to give a new index and fill the corresponding elements of the corresponding index in the original table into the table formed by the new index.
#要求增加一名员工的同时去掉身高列并增加性别列
df_reindex = pd.DataFrame({"Weight":[60,70,80], "Height":[176,180,179]}, index=['1001','1003','1002'])
df_reindex.reindex(index=['1001','1002','1003','1004'], columns=['Weight','Gender'])
#这种需求常出现在时间序列索引的时间点填充以及ID编号的扩充。另外,需要注意的是原来表中的数据和新表中会根据索引自动对其,例如原先的1002号位置在1003号之后,而新表中相反,那么reindex中会根据元素对其,与位置无关。
#还有一个与reindex功能类似的函数是reindex_like,其功能是仿照传入的表的索引来进行被调用表索引的变形。例如,现在以及存在一张表具备了目标索引的条件,那么上述功能可以如下等价地写出
df_existed = pd.DataFrame(index=['1001','1002','1003','1004'], columns=['Weight','Gender'])
df_reindex.reindex_like(df_existed)6. Index operation
6.1. Set algorithm

6.2. General index operations
Since the elements of the set are different, but there may be the same elements in the index, use unique to remove duplicates before performing operations. Two
simplest example tables are constructed below for demonstration:
df_set_1 = pd.DataFrame([[0,1],[1,2],[3,4]],index = pd.Index(['a','b','a'],name='id1'))
df_set_2 = pd.DataFrame([[4,5],[2,6],[7,1]],index = pd.Index(['b','b','c'],name='id2'))
id1, id2 = df_set_1.index.unique(), df_set_2.index.unique()
id1.intersection(id2)
Index(['b'], dtype='object')
id1.union(id2)
Index(['a', 'b', 'c'], dtype='object')
id1.difference(id2)
Index(['a'], dtype='object')
id1.symmetric_difference(id2)
Index(['a', 'c'], dtype='object')
# 上述的四类运算还可以用等价的符号表示代替如下:
id1 & id2
Index(['b'], dtype='object')
id1 | id2
Index(['a', 'b', 'c'], dtype='object')
(id1 ^ id2) & id1
Index(['a'], dtype='object')
id1 ^ id2 # ^ 符号即对称差
Index(['a', 'c'], dtype='object')
#若两张表需要做集合运算的列并没有被设置索引,一种办法是先转成索引,运算后再恢复,另一种方法是利
#用isin 函数,例如在重置索引的第一张表中选出id 列交集的所在行:
df_set_1
| 0 | 1 | |
|---|---|---|
| id1 | ||
| a | 0 | 1 |
| b | 1 | 2 |
| a | 3 | 4 |
df_set_2
| 0 | 1 | |
|---|---|---|
| id2 | ||
| b | 4 | 5 |
| b | 2 | 6 |
| c | 7 | 1 |
df_set_in_col_1 = df_set_1.reset_index()
df_set_in_col_2 = df_set_2.reset_index()
df_set_in_col_1[df_set_in_col_1.id1.isin(df_set_in_col_2.id2)]
| id1 | 0 | 1 | |
|---|---|---|---|
| 1 | b | 1 | 2 |
7. Practice
Ex1: Company employee data set
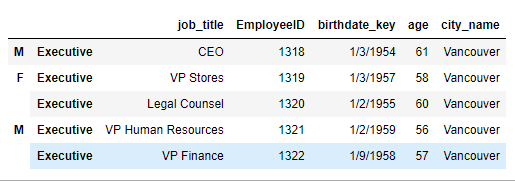
There is a company employee data set:
df = pd.read_csv('data/company.csv')
df.head(3)
#
EmployeeID birthdate_key age city_name department job_title gender
0 1318 1/3/1954 61 Vancouver Executive CEO M
1 1319 1/3/1957 58 Vancouver Executive VP Stores F
2 1320 1/2/1955 60 Vancouver Executive Legal Counsel F
Respectively only use
queryandlocselect men who are under forty years old and whose work department isDairyorBakery.condition_1 = df['age'] <= 40 condition_2 = df['department'].isin(['Dairy', 'Bakery']) condition_3 = df['gender'] == 'M' condition = condition_1 & condition_2 & condition_3 df.loc[condition].head()
df.query('(age<=40) and (department == ["Dairy", "Bakery"]) and gender == "M"').head()
Select
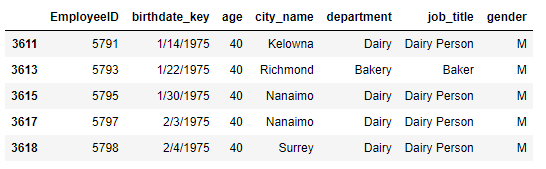
IDthe first, third, and second-to-last columns of the row where the employee number is odd.df.loc[df['EmployeeID']%2==1].iloc[:, [0, 2, -2]]
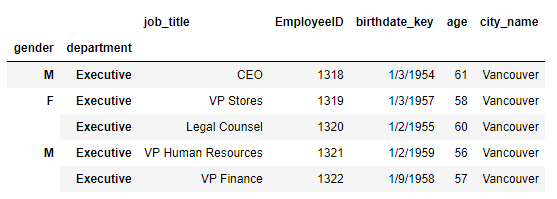
Follow the steps below to index:
- Exchange the inner and outer layers after setting the last three columns as indexes
df_cp = df.set_index(['department', 'job_title', 'gender']) df_cp = df_cp.swaplevel(0, 2, axis=0) df_cp.head()
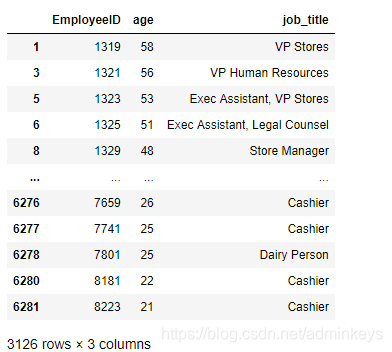
- Restore the middle layer
df_cp = df_cp.reset_index(['job_title']) df_cp.head()
- Modify the outer index name
Genderdf_cp = df_cp.rename_axis(index={'gender': 'Gender'}) df_cp.head()
- Combine two levels of row index with underscore
new_idx = df_cp.index.map(lambda x: x[0] + '_' + x[1]) df_cp.index = new_idx df_cp.head()
- Split the row index into the original state
new_idx = df_cp.index.map(lambda x: tuple(x.split('_'))) df_cp.index = new_idx df_cp.head()
- Modify the index name to the original table name
df_cp = df_cp.rename_axis(index=['gender', 'department']) df_cp.head()
- Restore the default index and keep the column as the relative position of the original table
df_cp = df_cp.reindex(df.columns, axis=1) df_cp.head()






Ex2: Chocolate data set
There is a data set on chocolate evaluation:
df = pd.read_csv('data/company.csv')
df.head(3)
| Company | Review\nDate | Cocoa\nPercent | Company\nLocation | Rating | |
|---|---|---|---|---|---|
| 0 | A. Morin | 2016 | 63% | France | 3.75 |
| 1 | A. Morin | 2015 | 70% | France | 2.75 |
| 2 | A. Morin | 2015 | 70% | France | 3.00 |
- Replace the column index names
\nwith spaces.df.columns = [' '.join(i.split('\n')) for i in df.columns] df.head()
- The chocolate
Ratingscore is from 1 to 5, and each 0.25 point is graded. Please selectCocoa Percenta sample with a score of 2.75 or less and a cocoa content above the median.df['Cocoa Percent'] = df['Cocoa Percent'].str.strip('%').astype('float64')/100 condition_1 = df['Rating'] <= 2.75 condition_2 = df['Cocoa Percent'] >= df['Cocoa Percent'].median() df[condition_1 & condition_2].head()
- Will
Review DateandCompany Locationthe set index, electedReview Dateafter 2012 andCompany Locationnot part ofFrance, Canada, Amsterdam, Belgiumthe sample


