Pandas can handle time series data in any field. Using Numpy datetime64 and timedelta64 types, Pandas integrates a large number of functions from other Python libraries, such as Scikits.TimeSeries, and creates a large number of new functions for processing time series data.
1. Time sequence creation
1. Four types of time variables
| name |
description |
Element type |
Create method |
| Datetimes (time point/time) |
Describe a specific date or point in time |
Timestamp |
to_datetime或date_range |
| Timespans (period/period) |
A period of time defined by a point in time |
Period |
Period或period_range |
| Dateoffsets (relative time difference) |
Relative size of time (It has nothing to do with summer/winter time) |
Dateoffset |
DateOffset |
| Timedeltas (absolute time difference) |
The absolute size of a period of time (Related to summer/winter time) |
Timedelta |
to_timedelta or timedelta_range |
For time series data, the traditional approach is to represent the time component in the Series or DataFrame index, so that operations can be performed on the time elements. However, Series and DataFrame can also directly support the time component as the data itself. When passed to these constructors, Series and DataFrame extend data type support and functions for date time, time increment, and period data. However, DateOffset data will be stored as object data.
#在index加入时间成分,dtype为int64
pd.Series(range(3), index=pd.date_range('2000', freq='D', periods=3))
#直接定义时间成分,dtype为datetime64[ns]
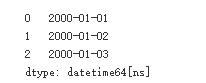
pd.Series(pd.date_range('2000', freq='D', periods=3))
2. Time point creation
Timestamped is the most basic time series data type that associates values with points in time. For pandas objects, this means using points in time.
(A) to_datetime method
Pandas gives a lot of freedom in the input format regulations established at the time point. The following statements can correctly establish the same time point
print(pd.to_datetime('2020.1.1'))
print(pd.to_datetime('2020 1.1'))
print(pd.to_datetime('2020 1 1'))
print(pd.to_datetime('2020 1-1'))
print(pd.to_datetime('2020-1 1'))
print(pd.to_datetime('2020-1-1'))
print(pd.to_datetime('2020/1/1'))
print(pd.to_datetime('1.1.2020'))
print(pd.to_datetime('1.1 2020'))
print(pd.to_datetime('1 1 2020'))
print(pd.to_datetime('1 1-2020'))
print(pd.to_datetime('1-1 2020'))
print(pd.to_datetime('1-1-2020'))
print(pd.to_datetime('1/1/2020'))
print(pd.to_datetime('20200101'))
print(pd.to_datetime('2020.0101'))
#pd.to_datetime('2020\\1\\1') #报错
#pd.to_datetime('2020`1`1') #报错
#pd.to_datetime('2020.1 1') #报错
#pd.to_datetime('1 1.2020') #报错Use the format parameter to force matching
print(pd.to_datetime('2020\\1\\1',format='%Y\\%m\\%d'))
print(pd.to_datetime('2020`1`1',format='%Y`%m`%d'))
print(pd.to_datetime('2020.1 1',format='%Y.%m %d'))
print(pd.to_datetime('1 1.2020',format='%d %m.%Y'))You can also use the list to turn it into a point-in-time index
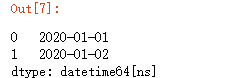
pd.Series(range(2),index=pd.to_datetime(['2020/1/1','2020/1/2']))View type
type(pd.to_datetime(['2020/1/1','2020/1/2']))
For DataFrame, if the columns have been arranged in chronological order, use to_datetime to automatically convert
df = pd.DataFrame({'year': [2020, 2020],'month': [1, 1], 'day': [1, 2]})
pd.to_datetime(df)
(B) Time accuracy and range limitation
The accuracy of Timestamp is far more than day, it can be as small as nanoseconds, and its range is
pd.to_datetime('2020/1/1 00:00:00.123456789')
#最小范围
print(pd.Timestamp.min) #output:Timestamp('1677-09-21 00:12:43.145225')
#最大范围
print(pd.Timestamp.min) #output:Timestamp('2262-04-11 23:47:16.854775807')(C) date_range method
start/end/periods (number of time points)/freq (interval method) are the most important parameters of this method, given 3 of them, the remaining one will be sing
The freq parameters are as follows:
| symbol |
D/B |
W |
M/Q/Y |
BM/BQ/BY |
MS/QS/YS |
BMS / BQS / BYS |
H |
T |
S |
| description |
Day/working day |
week |
End of month |
Month/quarter/year end |
Month/quarter/year-end working day |
Month/Quarter/New Year's Day |
Time |
minute |
second |
3.Dateoffset object
(A) The difference between DateOffset and Timedelta
The feature of Timedelta absolute time difference means that no matter whether it is winter time or summer time, only 24 hours are calculated for an increase or decrease of 1 day.
The relative time difference of DateOffset means that whether a day is 23/24/25 hours, the increase or decrease of 1day is consistent with the same time of the day
For example, on March 29th, 2020, 01:00:00 local time in the UK, the clock is adjusted forward by 1 hour to become March 29th, 2020, 02:00:00, and daylight saving time starts
ts = pd.Timestamp('2020-3-29 01:00:00', tz='Europe/Helsinki')
ts + pd.Timedelta(days=1)![]()
ts = pd.Timestamp('2020-3-29 01:00:00', tz='Europe/Helsinki')
ts + pd.DateOffset(days=1)![]()
The tz attribute can be removed to make the two consistent.
(B) Increase or decrease for a period of time
pd.Timestamp('2020-01-01') + pd.DateOffset(minutes=20) - pd.DateOffset(weeks=2)(C) Various commonly used offset objects
pd.Timestamp('2020-01-01') + pd.offsets.Week(2) #增加两星期
pd.Timestamp('2020-01-01') + pd.offsets.BQuarterBegin(1) #营业季度开始(D) Offset operation of sequence
Use the apply function
pd.Series(pd.offsets.BYearBegin(3).apply(i) for i in pd.date_range('20200101',periods=3,freq='Y'))
Use object addition and subtraction directly
pd.date_range('20200101',periods=3,freq='Y') + pd.offsets.BYearBegin(3)Custom offset, you can specify weekmask and holidays parameters
pd.Series(pd.offsets.CDay(3,weekmask='Wed Fri',holidays='2020010').apply(i)
for i in pd.date_range('20200105',periods=3,freq='D'))Second, the index and attributes of the time series
1. Index slice
rng = pd.date_range('2020','2021', freq='W')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
ts['2020-01-26':'20200726'].head() #日期从01-26,到07-26,字符自己转换成合理的2. Subset index
#只取7月份数据
ts['2020-7'].head()
#支持混合形态索引
ts['2011-1':'20200726'].head()3. The attributes of the point in time
Use dt objects to easily obtain information about time
#2020年有52个星期
pd.Series(ts.index).dt.week
#每星期是在几号
pd.Series(ts.index).dt.dayUse strftime to modify the time format
pd.Series(ts.index).dt.strftime('%Y-间隔1-%m-间隔2-%d').head()For datetime objects, you can get information directly through attributes
#每个星期所在的月份
pd.date_range('2020','2021', freq='W').month
#每个星期所在的月份
pd.date_range('2020','2021', freq='W').weekday #The number of the day of the week with Monday=0, Sunday=6Three, resampling
Resampling refers to the resample function, which can be regarded as a time series version of the groupby function
1. The basic operation of the resample object
The sampling frequency is generally set to the offset character mentioned above
df_r = pd.DataFrame(np.random.randn(1000, 3),index=pd.date_range('1/1/2020', freq='S', periods=1000),
columns=['A', 'B', 'C'])
r = df_r.resample('3min')
r.sum()
2. Sampling aggregation
df_r = pd.DataFrame(np.random.randn(1000, 3),index=pd.date_range('1/1/2020', freq='S', periods=1000),
columns=['A', 'B', 'C'])
r = df_r.resample('3T')
#只求一个值
r['A'].mean()
#表示多个
r['A'].agg([np.sum, np.mean, np.std])
#使用lambda
r.agg({'A': np.sum,'B': lambda x: max(x)-min(x)})3. Iteration of sampling group
The iteration of the sampling group is completely similar to the groupby iteration, and the corresponding operation can be done for each group.
small = pd.Series(range(6),index=pd.to_datetime(['2020-01-01 00:00:00', '2020-01-01 00:30:00'
, '2020-01-01 00:31:00','2020-01-01 01:00:00'
,'2020-01-01 03:00:00','2020-01-01 03:05:00']))
resampled = small.resample('H')
for name, group in resampled:
print("Group: ", name)
print("-" * 27)
print(group, end="\n\n")
Four, window function
1.Rolling
(A) Commonly used aggregation
s = pd.Series(np.random.randn(1000),index=pd.date_range('1/1/2020', periods=1000))
#
s.rolling(window=50)
#
s.rolling(window=50).mean()
#min_periods是指需要的非缺失数据点数量阈值
s.rolling(window=50,min_periods=3).mean()In addition, count/sum/mean/median/min/max/std/var/skew/kurt/quantile/cov/corr are commonly used aggregate functions
(B) Rolling apply aggregation
When using apply aggregation, you only need to remember that the incoming series is the window size, and the output must be a scalar.
#计算变异系数
s.rolling(window=50,min_periods=3).apply(lambda x:x.std()/x.mean()).head()(C) Rolling based on time
Optional closed='right' (default) \'left'\'both'\'neither' parameter, which determines the inclusion of the endpoint
s.rolling('15D').mean().head()
#添加closed
s.rolling('15D', closed='right').sum().head()2.Expanding
(A) Expanding function
The ordinary expanding function is equivalent to rolling(window=len(s),min_periods=1), which is the cumulative calculation of the sequence, apply is also applicable
#rolling
s.rolling(window=len(s),min_periods=1).sum().head()
#expanding
s.expanding().sum().head()
#apply
s.expanding().apply(lambda x:sum(x)).head()(B) Several special Expanding type functions
cumsum/cumprod/cummax/cummin are all special expanding cumulative calculation methods
shift/diff/pct_change all involve element relationships
①Shift refers to the sequence index unchanged, but the value moves backward
②diff refers to the difference between the elements before and after, the period parameter represents the interval, the default is 1, and can be negative
③ pct_change is the percentage change of elements before and after the value, the period parameter is similar to diff