Python crawler crawls pictures on Baidu and implements theme crawlers according to specific keywords
Article Directory
Realize keyword crawling of Baidu pictures and save them
Code and analysis
The tasks you do yourself can be saved as a note at any time.
There are many ways to crawl python
在这里插入代码片
# _*_ coding:utf-8 _*_
# 工程作者:赖正良
# 时间:2020/9/21/11:35
from tkinter import *
import requests
import re
import os
from urllib import parse
from urllib import request
from urllib.request import urlretrieve
from bs4 import BeautifulSoup
import tkinter as tk
# 定义一个gui界面显示
# 显示图像框
def main():
running = 1
global url_input,text,sshow
# 创建空白窗口,作为主载体
root = Tk()
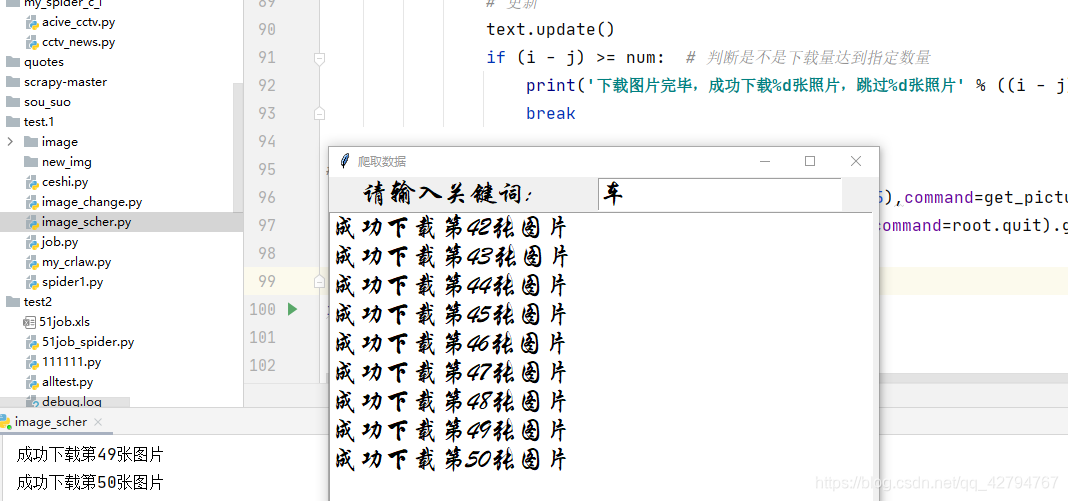
root.title('爬取数据')
# 窗口的大小,后面的加号是窗口在整个屏幕的位置
root.geometry('550x400+398+279')
# 标签控件,窗口中放置文本组件
Label(root,text='请输入关键词:',font=("华文行楷",20)).grid()
# 定位 pack包 place位置 grid是网格式的布局
url_input = Entry(root,font=("华文行楷",20))
url_input.grid(row=0,column=1)
# 输入
#text = Listbox(root,font=('华文行楷',20),width=45,height=10)
text = tk.Text(root, font=('华文行楷', 20), width=45, height=10)
# columnspan 组件所跨越的列数
text.grid(row=1,columnspan=2)
# 爬虫函数,爬取关键字的内容
# 定义一个爬虫函数
def get_picture():
word = url_input.get()
url = ('https://image.baidu.com/search/acjson?'
'tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&'
'queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&'
'word={word}&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=&fr=&'
'pn={pn}&rn=30&gsm=5a&1516945650575=')
pattern = '"thumbURL":"(.+?\.jpg)"'
def geturls(num, word):
word = parse.quote(word)
urls = []
pn = (num // 30 + 1) * 30
for i in range(30, pn + 1, 30):
urls.append(url.format(word=word, pn=i))
return urls
def getimgs(num, urls):
imgs = []
reg = re.compile(pattern)
for url in urls:
page = request.urlopen(url)
code = page.read()
code = code.decode('utf-8')
imgs.extend(reg.findall(code))
# print(code)
return imgs
# 获取url,设置存放图片的位置
word = url_input.get() # 输入关键字进行搜索
num = 50 # 最多打印100张图片
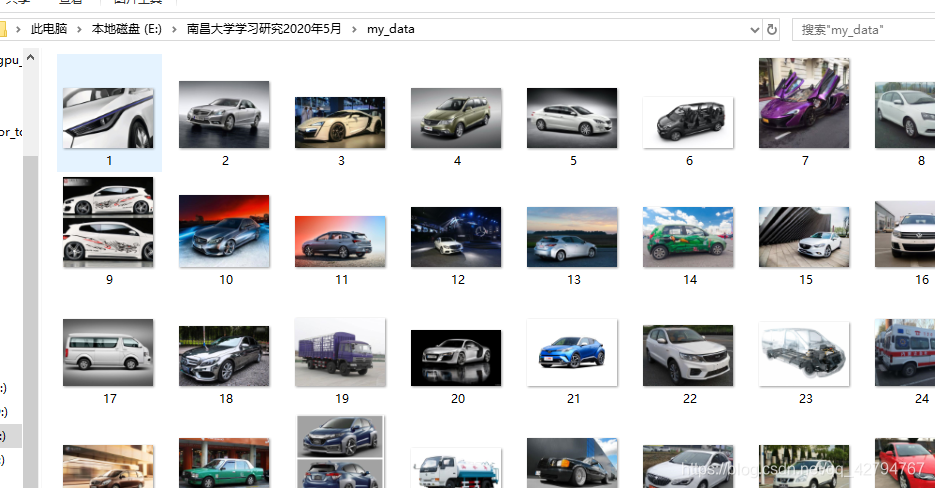
path = r'E:\南昌大学学习研究2020年5月\my_data' # 图片存贮的路径
# 判断图片保存路径是否存在,不存在就创建
if not os.path.exists(path):
os.mkdir(path)
print('路径不存在,但已新建')
# 进入百度图片搜索网页,搜索关键字,获取num整除30页图片搜索页面的地址列表
urls = geturls(num, word) # 百度搜索页面地址
# 打开urls列表中的url,用正则表达式搜索以.jpg结尾的图片源地址url,保存到imgs列表中,imgs中的url是30的倍数
imgs = getimgs(num, urls) # 图片地址
# 获取图片,保存图片
i = 0 # 下载序号
j = 0 # 请求超时数量
for img in imgs:
i += 1
try:
request.urlretrieve(img, path + '/' + '%s.jpg' % (i - j)) # 将图片下载到指定目录
except OSError as err: # 下载超时处理
print('下载第%s图片时请求超时,已跳过该图片' % (i - j))
else:
# stri = print('成功下载第' + str(i - j) + '张图片')
sshow= '成功下载第' + str(i - j) + '张图片'
print(sshow)
text.insert(END,sshow+'\n') # 在gui界面中动态显示下载的图片数量
text.see(END) # 更新每次打印
# 更新
text.update()
if (i - j) >= num: # 判断是不是下载量达到指定数量
print('下载图片完毕,成功下载%d张照片,跳过%d张照片' % ((i - j), j))
break
# 设置按钮 sticky对齐方式,N S W E
button =Button(root,text='开始下载',font=("华文行楷",15),command=get_picture).grid(row=2,column=0,sticky=W)
button =Button(root,text='退出',font=("华文行楷",15),command=root.quit).grid(row=2,column=1,sticky=E)
if running == 1:
root.mainloop()
if __name__ == '__main__':
main()
Summary notes
The key to analyze the html code, record your own notes