Hello everyone, this article will focus on python crawling Baidu news data. Python crawling news website content is something that many people want to understand. To figure out python crawling article content, you need to understand the following things first.
Python crawls news information, word segmentation statistics and draws word cloud
Chinanews.com is a well-known Chinese news portal and one of the most important original content providers of Chinese news on the global Internet. Relying on China News Agency's global editing and editing network, it provides text, pictures, videos and other diversified information services quickly and accurately to netizens and network media 24 hours a day .
Analyze the content of the page : First, open the page of China News Network and you can see that there are already many category label options in the navigation bar. However, the tags that can be jumped to are not all classified according to the content of the news. 
For example, "Finance", "Autos", and "Sports" in the tabs are divided by content, but "International", "Hong Kong Macau", and "Taiwan" are divided by the source of the news. Such divisions are not uniform.
In order to classify news according to content, it is necessary to extract the news content published in real time and divide it uniformly according to text semantic information.
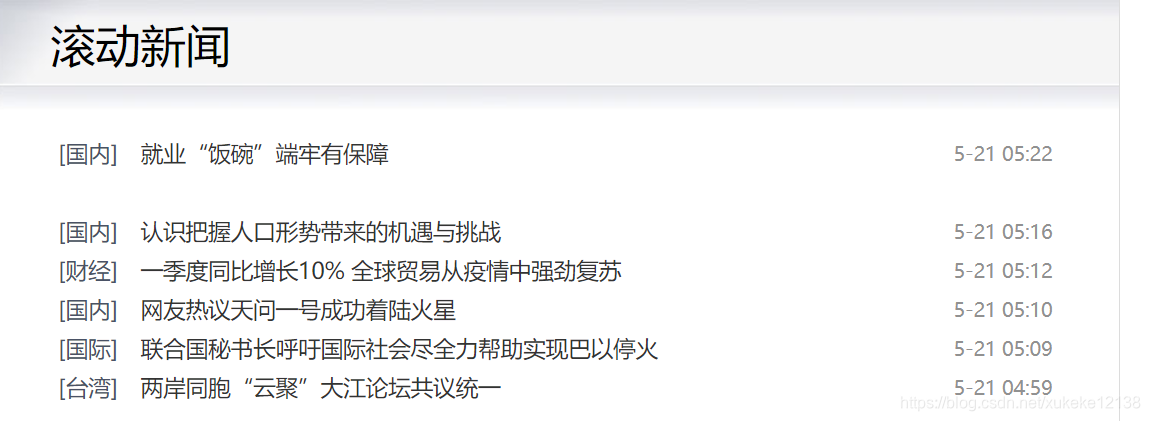
Here, it is found that in the column of China News Network 滚动新闻, you can see a summary of the latest news released in real time. And the news category tags and news titles released in real time can be obtained on the web page . After clicking the link, you can jump to the corresponding details page to get more detailed content text.
For example:
Analyze the source code of the web page : You can see the content of headers in the source code of the scrolling news page. Adding it to the crawler as a request header can simulate a browser to access a website. 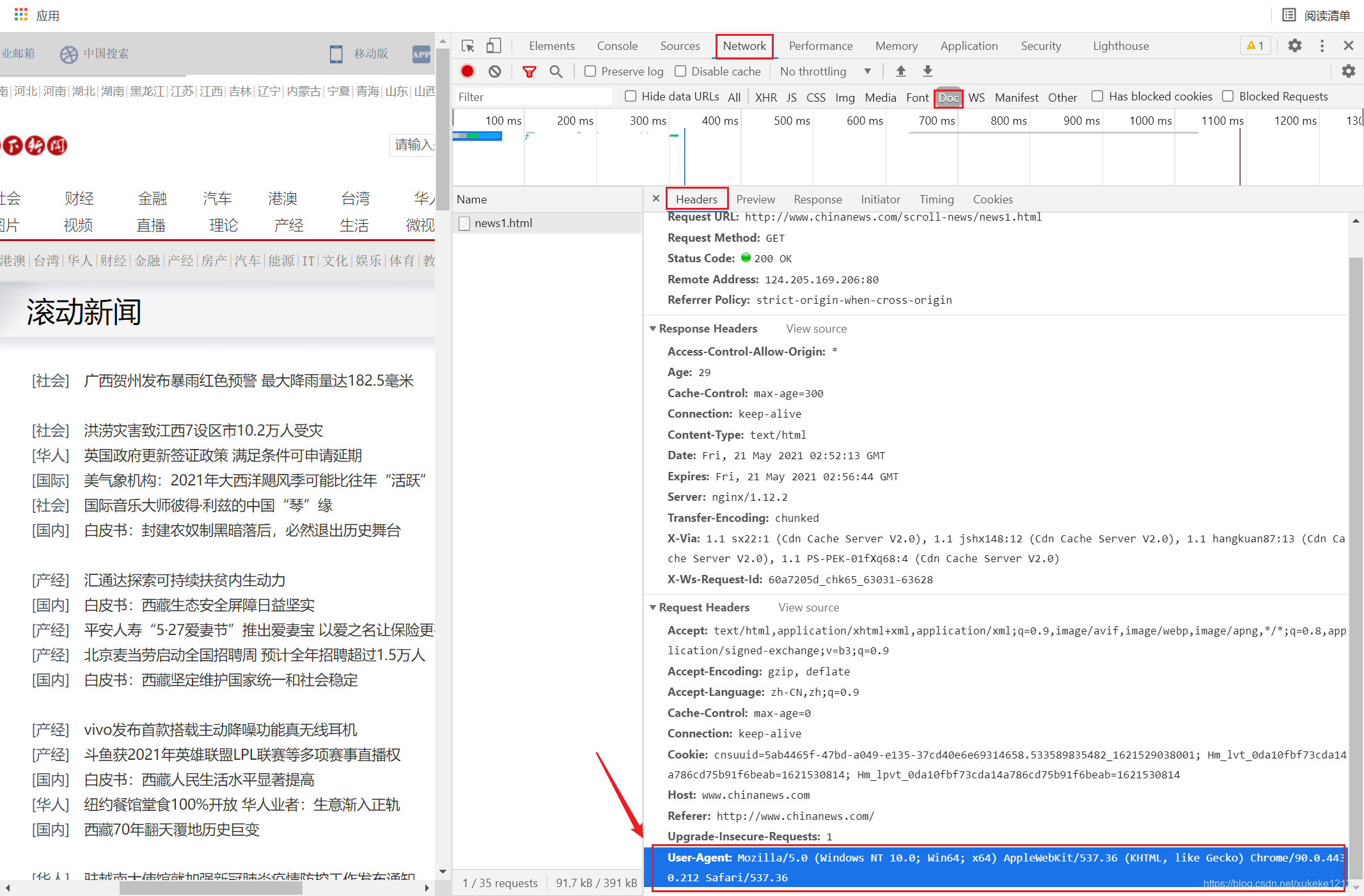
Print out the obtained web page source code on the terminal. It can be seen that the title and label of the news can be obtained from the source code.
However, what is obtained in this step respis still a string. In order to facilitate the parsing of the webpage content, it is necessary to convert the string into webpage structured data, so as to easily find HTML tags and their attributes and content.
Observe the HTML structure of the web page, and convert the HTML format string obtained in the previous step into a BeautifulSoup object. In this way, the corresponding content can be found through tags.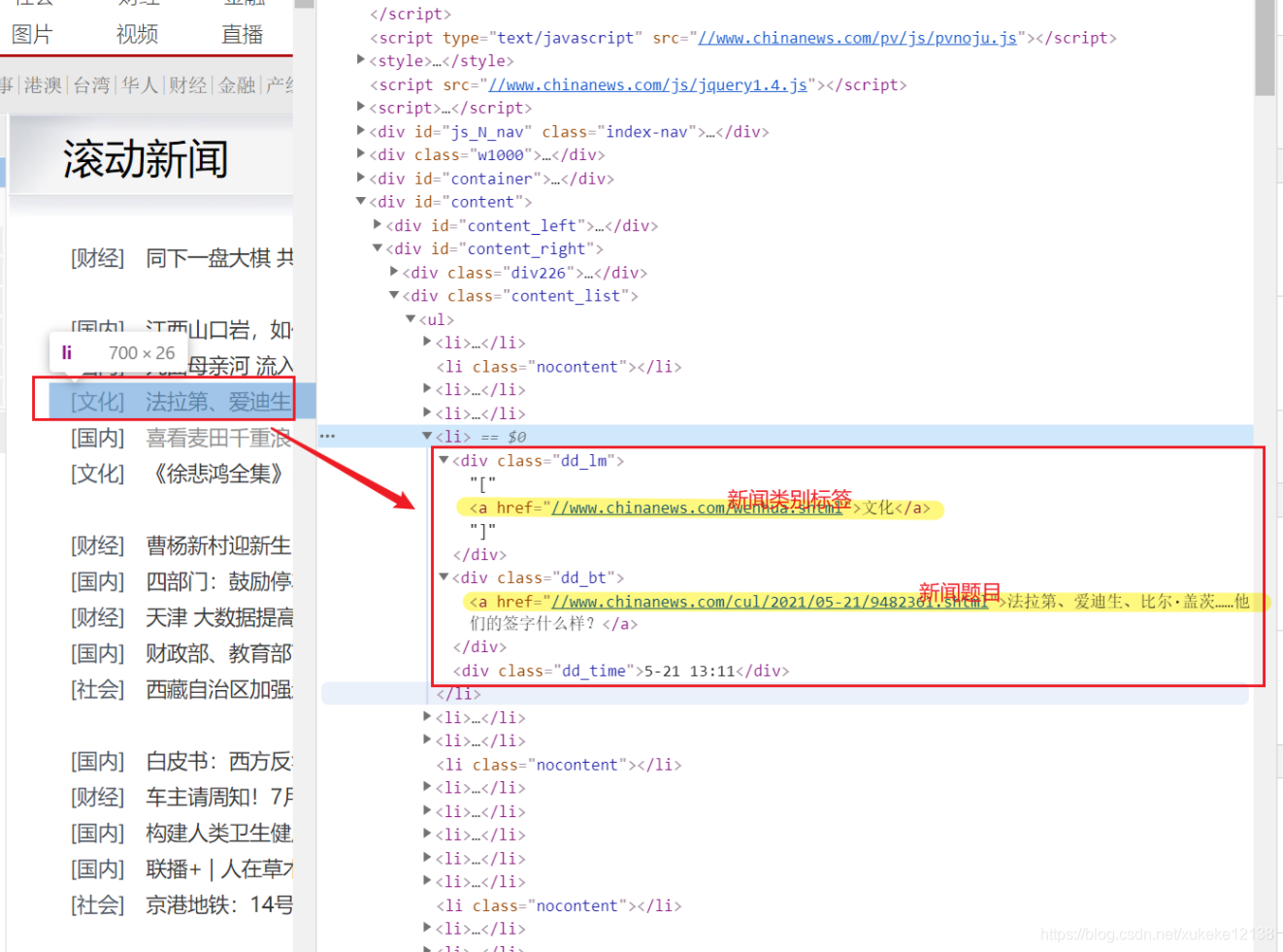
Information screening and storage : Next, we need to filter out the content we need in the web page.
Notice that the information on the webpage is displayed in three sections according to the category name , title and time , and the accessed content is also divided into these three parts. 
Use regular expressions to match the obtained strings. We can get a and
put the obtained information into the text.
Scrolling the page can turn the page, crawling a total of 10 pages of information will get 1250 news information. Put these news information in the dictionary and save them in the excel form. 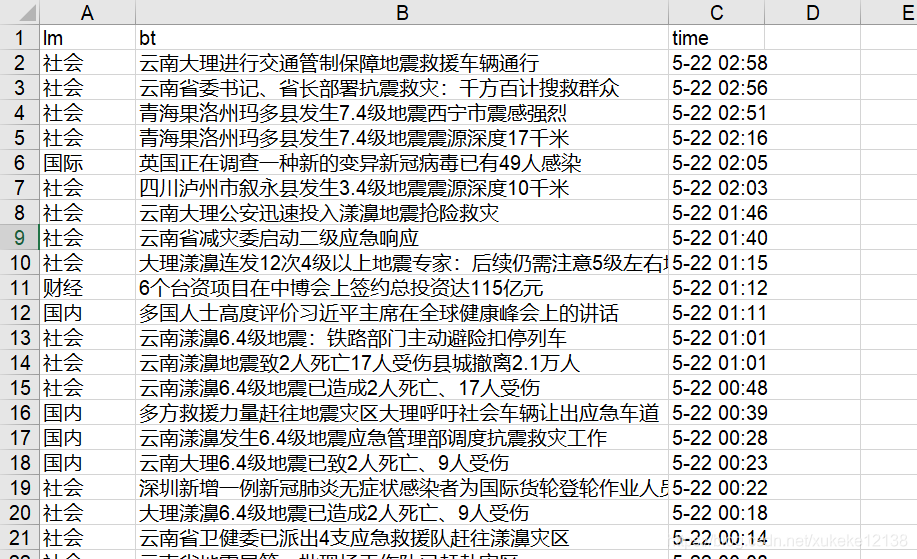
Noticing that different news categories will have different numbers, we will count the tags of the news with different contents crawled as follows: You can see that the number of news releases 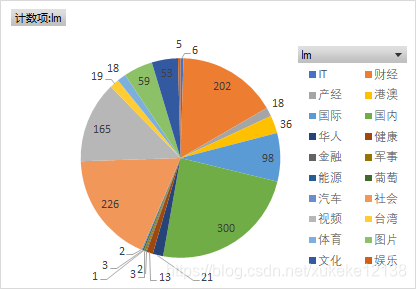
in which " domestic ", " finance " and " society " are the main subjects most. There are also many content published very rarely, such as "IT", "Military".
At the same time, the contents of all news headlines are integrated. Use the jieba library for word segmentation, and use the wordcloud library to draw a word cloud display:
It can be seen that the word " China " appears most often in news headlines, followed by "international", "development" and so on.
import requests
from bs4 import BeautifulSoup
import re
import xlwt
import jieba
import wordcloud
def req():
url_head = "http://www.chinanews.com/scroll-news/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
all_news = []
news_list = [[] for i in range(20)]
id2tp = { }
id = {}
cnt = 0
txt = " "
for i in range(10):
url = url_head + "news" + str(i+1) + ".html"
resp = requests.get(url=url, headers=headers)
resp = resp.content.decode('utf-8', 'ignore') # 不加第二个参数ignore会报错 忽略掉一些utf编码范围外的不知名字符
#print(resp)
soup = BeautifulSoup(resp, 'html.parser')
news = soup.select('body #content #content_right .content_list ul li')
#print(news)
for new in news:
new = new.text
if new == '':
continue
ti = re.compile("[0-9][0-9]:[0-9][0-9]")
date = re.compile("[0-9]{1,2}\-[0-9]{1,2}")
#print(new)
time = new[-10:]
new = ti.sub('', new)
new = date.sub('', new)
lm = new[1:3]
if len(lm.strip()) == 1:
lm = "IT"
bt = new.split(']')[1].replace(' ', '')
txt = txt + " " + bt
if lm not in id.keys():
id[lm] = cnt
id2tp[cnt] = lm
cnt += 1
all_news.append({
"lm": lm,
"bt": bt,
"time": time
})
print(len(all_news))
print(id)
#print(id2tp)
workbook = xlwt.Workbook() #注意Workbook的开头W要大写
sheet1 = workbook.add_sheet('sheet1',cell_overwrite_ok=True)
sheet1.write(0, 0, "lm")
sheet1.write(0, 2, "bt")
sheet1.write(0, 4, "time")
for idx, dictionary in enumerate(all_news):
news_list[id[dictionary["lm"]]].append(dictionary["bt"])
sheet1.write(idx + 1, 0, dictionary["lm"])
sheet1.write(idx + 1, 2, dictionary["bt"])
sheet1.write(idx + 1, 4, dictionary["time"])
workbook.save('news.xls')
for i in range(13):
print(id2tp[i], len(news_list[i]))
w=wordcloud.WordCloud(width=1000, font_path='chinese.ttf', height=700, background_color='white')
lis = jieba.lcut(txt)
# 人为设置一些停用词
string = " ".join(lis).replace('的', '').replace('在', '').replace('为', '').replace('是', '').replace('有', '').replace('和', '')
print(string)
w.generate(string)
w.to_file("news.png")
if __name__ == "__main__":
req()
# test()