Preface:
The HASH table is really unintelligible to me, especially the construction of the HASN function...
Some classmates also said to talk about HASN, so I will give out another point of self-study.
HASH table
The hash table is mainly for searching, and the searching time complexity of searching the data in the memory efficiently and quickly is O(1).
There are three keys to constructing a hash table: how to control the length of the hash table , how to design the hash function , and how to deal with hash conflicts
How to control the length of the hash table
The length of the HASH table is generally fixed. Before storing the data, we should know how large the data is stored, and we should avoid frequent expansion of the HASH table as much as possible.
But if the design is too large, then space will be wasted, because we don't need so much space to store our current data scale;
If the design is too small, then HASH conflicts will easily occur, and the efficiency of the HASH table will not be reflected.
Therefore, the size of the HASH table we design must reduce the HASH conflict as much as possible, and not waste space as much as possible. Choosing the appropriate HASH table size is the key to improving the performance of the HASH table.
When we choose the HASH function, we often choose to divide and leave the remainder method, that is, divide the key value of the stored data by the total length of the HASH table, and the remainder obtained is its HASH value.
Common sense tells us that when a number is divided by a prime number, it will produce the most scattered remainder. Since we usually use the size of the table to perform modulo operation on the result of the HASH function,
If the size of the table is a prime number, then we will generate scattered HAHS values as much as possible.
Another concept of the HASH table is the filling factor. I will not elaborate on its formula and properties.
As for why there is such a concept, my understanding is that if the more data in a HASH table is installed, the more likely HASH conflicts will occur.
If when the HASH table is full enough that only one subscript can be inserted, at this time we have to insert data into the HASH table, so we may reach an O(n) level of insertion efficiency.
We even have to traverse the entire HASH table to find the location that can be stored.
Usually, what we focus on is to minimize the average lookup length of the HASH table and ensure the average lookup length is O(1) time complexity.
The smaller the value of the filling factor a, the smaller the chance of conflict, but it should not be too small, so we will cause a larger waste of space.
If we take a 0.1 0.10 . . 1 , the length of the HASH table is100 1001 0 0 , then we only installed10 101 0 key-valuekey keyK E Y pair is less than the stored, HASH table is necessary for the expansion, while the remaining 90 key-key keyk e y is actually a waste of space.
Under normal circumstances, as long as a is appropriate (usually between 0.7 and 0.8), the average lookup length of the hash table will be constant, which is O(1) level.
To summarize, the method of constructing a HASH table size that is as efficient as possible:
·确保哈希表长度是一个素数,这样会产生最分散的余数,尽可能减少哈希冲突
·设计好哈希表装填因子,一般控制在0.7-0.8
·确认我们的数据规模,如果确认了数据规模,可以将数据规模除以装填因子,根据这个结果来寻找一个可行的哈希表大小
·当数据规模会动态变化,不确定的时候,这个时候我们也需要能够根据数据规模的变化来动态给我们的哈希表扩容,
所以一开始需要自己确定一个哈希表的大小作为基数,然后在此基础上达到装填因子规模时对哈希表进行扩容。
HASH function (string HASH)
Hash function is used to calculate the hash value of stored data. According to the type of stored data, different hash functions can be designed.
Teacher Guo said that constructing a good HASH function can reduce conflicts and speed up search. .
Generally, the string HASH generally belongs to this formula:
HASH值 = 计算后的存储值 / HASH表的大小
If the stored number is an integer, you don't need to calculate it at all, and directly use the integer value as the stored value after calculation in the above formula.
Now take string as an example to talk about common string hash algorithms. Other types of data can use similar ideas to design their own HASH algorithms.
For example, take a fixed value PPP , treat the string asPPThe base number of P , and assign a value greater than 0 to represent each character. Generally speaking, the assigned value is less thanPPP。
For example, for a string composed of lowercase letters, the first thought should be ASCLL ASCLLA S C L L code, put this lowercase letterASCLL ASCLLAssign the A S C L L code to it.
Take a fixed value M, and find the remainder of the P base number to M, as the hash value of this string
As for other methods of constructing HASH function, just look at PPT.
Ways to resolve conflicts
Foreword:
I was shocked by what Senior Tao Liyu said. See below:
Why resolve the HASH conflict? It will only be slower if it is not resolved. Why resolve the HASH conflict? If it is not resolved, it will only be slower. Is what it should solution must H A S H Chong conflict , no solution decided it just would slow Yi Dian and has

Development addressing method:
This method is easier to understand, which is H i HiH i keeps looping, finding a suitable location and then loading it in.
The increment di can have the following three values:
线性取值,1,2,3....这样,也就是从冲突位置不断往后找下一个可以存放的下标
二次取值,1,4,9....这样,也就是从冲突位置不断往后找x的二次方的下标,其中x从1开始线性增大
随机取值,di可以去任意随机值,随机找一个。
The same method is time-consuming, and elements cannot be deleted.
Then HASH method:
As we all know another meaning of the word, so if the first is not completely HASH
To resolve the conflict, then construct another one.
Then HASH bucket)-zipper method: (the ideas borrowed here and borrow a picture)
Each subscript is stored in a linked list, and the key with the same hash value is inserted directly after the linked list in the subscript.
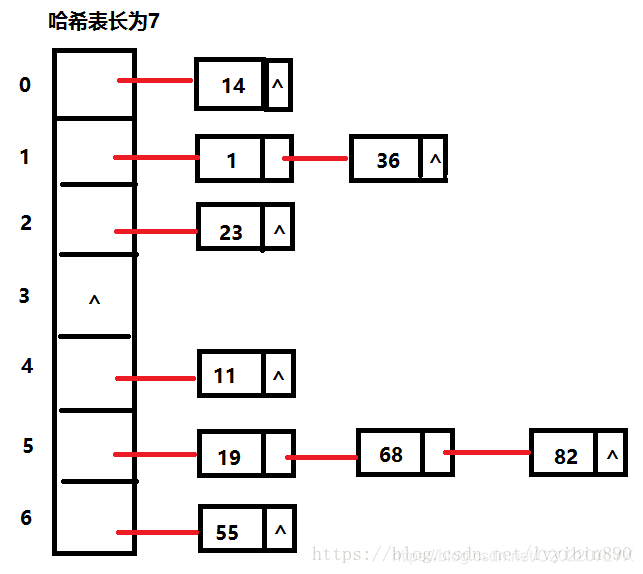
The characteristic of this method is that the size of the table is about the same as the amount of data stored (not a big deal, only one node is placed in each subscript. If the subscript is the same, it is placed in the linked list of the same subscript, and it does not occupy the new subscript. ),
Therefore, the hash bucket method does not particularly depend on the load factor. When the hash table block is full, it can still achieve better efficiency, and the development of the addressing method needs to ensure the load factor.
Of course, the hash bucket method is not a panacea, and it also has its disadvantages:
It needs a little more space to store the element, because there is also a pointer to the next node.
Each detection also takes more time, because it needs to refer to the pointer indirectly instead of directly accessing the element.
But in fact, the above shortcomings will not have much impact on current computers, so these shortcomings are insignificant, so in actual use of hash, the hash bucket is generally used to resolve conflicts.
It should be noted that the hash table cannot make this linked list infinitely long.
For example, if the hash value of all my data is the same, there will only be one subscript, and the other subscripts are not used, which creates an extreme situation.
In this case, if we want to find it, it is equivalent to searching in a linked list. Its search efficiency is O(n), which obviously violates the thinking of hash table design.
Therefore, when the length of a certain linked list or several linked lists reaches a certain length, the hash table needs to be expanded. The specific details still depend on the design.
But compared to the development addressing method, the frequency that it will expand is much smaller, because the development addressing method must ensure its own filling factor, so it will expand more frequently.
So in terms of efficiency, the zipper method is better than the development addressing method.