
Introduction: This article starts from the traditional design and solution ideas of hash tables, and introduces new design ideas in a simple way: from avoiding hash conflicts as much as possible, to using appropriate hash conflict probability to optimize calculation and storage efficiency. The new hash table design shows the effective use of the SIMD instruction parallel processing capability, which greatly improves the tolerance of the hash table to hash collisions, improves the query speed, and helps the hash table to progress. The ultimate storage space compression.
1 background
Hash table is a data structure with excellent search performance, and it has a wide range of applications in computer systems. Although the theoretical search time complexity of a hash table is O(1), there are still huge performance differences in the implementation of different hash tables, because engineers have also explored better hash data structures. Never stopped.
1.1 The core of hash table design
From computer theory, a hash table is a data structure that can map Key to Value storage location through a hash function. Then the core of the hash table design is two points:
1. How to improve the efficiency of mapping Key to Value storage location?
2. How to reduce the space overhead of storing data structures?
Because the storage space overhead is also a core control point at design time, in the case of limited space, the mapping algorithm of the hash function has a very high probability to map different keys to the same storage location , Which is a hash collision . The difference in the design of most hash tables lies in how it handles hash collisions.
When encountering a hash conflict, there are common solutions: open addressing, zipper, and secondary hashing. But below we introduce two interesting and infrequent solutions, and lead to our new implementation-the B16 hash table.
2 Avoid hash collisions
The traditional hash table's processing of hash conflicts will add additional branch jumps and memory access, which will make the processing efficiency of streaming CPU instructions worse. Then there must be some consideration, how can we completely avoid hash collisions? So there is such a function, that is, the perfect hash function.
A perfect hash function can map a set of Keys to a set of integers without conflict. If the size of this set of target integers is the same as the input set, then it can be called the smallest perfect hash function.
The design of a perfect hash function is often ingenious. For example, the CDZ perfect hash function provided by the CMPH (http://cmph.sourceforge.net/) library uses the mathematical concept of a non-cyclic random 3-part hypergraph . CDZ uses 3 different Hash functions to randomly map each Key to a hyper-edge of the 3-part hypergraph. If the hypergraph passes the loop detection, then each Key is mapped to a vertex of the hypergraph. Then obtain the final storage index corresponding to the Key through a carefully designed auxiliary array with the same number of vertices as the hypergraph.
The perfect hash function sounds very elegant, but in fact it also has some shortcomings in practicality:
- The perfect hash function can often only be used on a limited set, that is, all possible keys belong to a superset, and it cannot handle keys that have not been used before;
- The construction of a perfect hash function has a certain complexity, and there is a probability of failure;
- The perfect hash function is different from the hash function in cryptography. It is often not a simple mathematical function , but a functional function composed of data structure + algorithm . It also has storage space overhead, access overhead, and additional points. Jump overhead
However, in specific scenarios, such as read-only scenarios, scenarios where the collection is determined (for example, a collection of Chinese characters), the perfect hash function may achieve very good performance.
3 Use hash collision
Even if the perfect hash function is not used, many hash tables will deliberately control the probability of hash collisions. The easiest way is to control the space overhead of the hash table by controlling the Load Factor, so that the bucket array of the hash table retains enough holes to accommodate the newly added Key. Load Factor is like a hyperparameter that controls the efficiency of the hash table. Generally speaking, the smaller the Load Factor, the greater the waste of space and the better the performance of the hash table.
However, the emergence of some new technologies in recent years has allowed us to see another possibility to resolve hash conflicts, which is to make full use of hash conflicts.
3.1 SIMD instruction
SIMD is the abbreviation for Single Instruction Multiple Data. This type of instruction can use a single instruction to manipulate multiple data. For example, the GPUs of these years have achieved the acceleration of neural network calculations through the super-scale SIMD calculation engine.
The previous mainstream CPU processors already have a rich SIMD instruction set support. For example, most of the X86 CPUs that are accessible to everyone already support SSE4.2 and AVX instruction sets, and ARM CPUs also have Neon instruction sets. However, many applications other than scientific computing have insufficient application of SIMD instructions.
3.2 F14 hash table
The F14 hash table open sourced by Facebook in the Folly library has a very sophisticated design, which is to map the Key to the block, and then use the SIMD command in the block for efficient filtering. Because the number of blocks is smaller than that of traditional buckets, this is equivalent to adding a hash conflict, and then using SIMD instructions in the block to resolve the conflict.
The specific approach is this:
- Calculate two hash codes for Key through a hash function: H1 and H2 , where H1 is used to determine the block to which the Key is mapped, and H2 has only 8 bits, which is used to filter within the block;
- Each block can store up to 14 elements, and the block header has 16 bytes. The 14 bytes of the block header store the H2 corresponding to the 14 elements . The 15th byte is the control byte. It mainly records how many elements in the block overflowed from the previous block. The 16th byte is The out-of-bounds counter mainly records how many elements should be placed if the space of the block is large enough.
- When inserting, when 14 positions in the block to which the Key is mapped are still empty, insert directly; when the block is full, increase the out-of-bounds counter and try to insert into the next block;
- When querying, H1 and H2 are calculated by the key to be searched . After determining the block to which it belongs by taking the modulus of the block number by H1 , first read the block header, and use the SIMD instruction to compare whether H2 is the same as the H2s of the 14 elements . If there is the same H2 , then check whether the Key is the same to determine the final result; otherwise, judge whether the next block needs to be compared according to the 16th byte of the block header.
In order to make full use of the parallelism of SIMD instructions, F14 uses 8 bits of hash value H2 in the block . Because a SIMD instruction with 128 bits width can perform parallel comparison of up to 16 8 bits integers. Although the theoretical collision probability of an 8-bit hash value is 1/256 not low, it is equivalent to the possibility of 255/256, eliminating the overhead of key-by-key pairing, so that the hash table can tolerate a higher collision probability.
4 B16 hash table
Regardless of the internal design of the block, F14 is essentially an open-addressable hash table. The 15th and 16th bytes of each block header are used for the open addressing control strategy, and only 14 bytes are left for the hash code, which is also named F14.
Then we consider whether we can start from another degree and use the zipper method to organize the blocks. Since the control information is omitted, 16 elements can be placed in each block, we named it B16.
4.1 B16 hash data structure
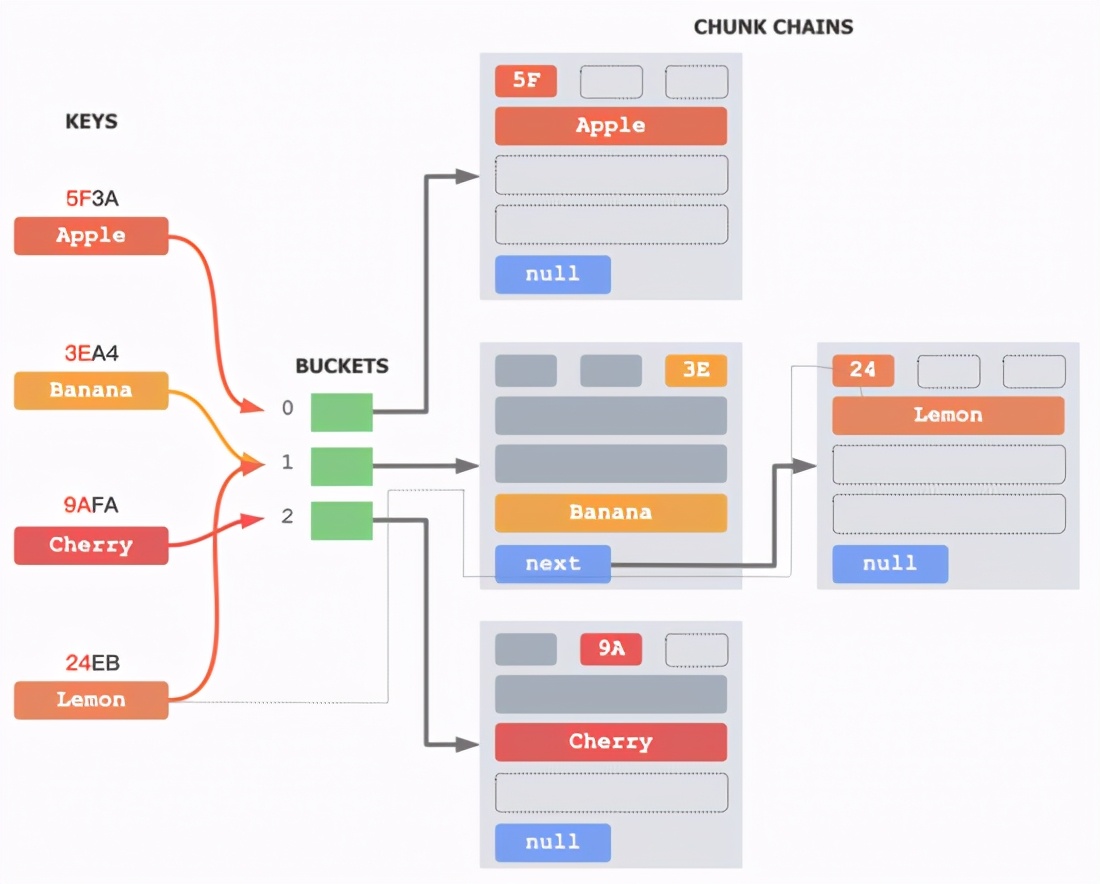
△ B16 hash table data structure (3 element example)
The figure above shows the data structure of the B16 hash table with 3 elements in each block. The green in the middle is the regular BUCKET array, which stores the head pointer of the CHUNK zipper in each bucket. Each CHUNK on the right is relative to F14, without the control byte, and adding a next pointer to the next CHUNK.
B16 also calculates two hash codes for Key through a hash function: H1 and H2 . For example, the two hash codes of "Lemon" are 0x24EB and 0x24. Using the high position of H1 as H2 is generally enough.
When inserting, calculate the bucket where the Key is located by modulating the bucket size by H1 . For example, the bucket where "Lemon" is located is 0x24EB mod 3 =1. Then find the first space in the block zipper of the No. 1 bucket, and write the H2 and element corresponding to the Key into the block. When the divided zipper does not exist or is already full, a new divided zipper is created for loading inserted elements.
When searching, first find the corresponding bucket zipper through H1 , and then perform the H2 alignment based on the SIMD instruction for each block . Load the block header 16 bytes of each block into the 128 bits register, which contains 16 H2's , expand the H2 to the 128 bits register repeatedly, and perform 16-way simultaneous pairing through the SIMD instruction. If they are all different, then compare the next block; if there is the same H2 , continue to compare whether the Key of the corresponding element is the same as the Key you searched for. Until the complete zipper is traversed, or the corresponding element is found.
When deleting, first find the corresponding element, and then cover the corresponding element with the element at the end of the block zipper.
Of course, the number of elements in each block of the B16 hash table can be flexibly adjusted according to the width of the SIMD instruction. For example, the block size of 32 elements can be selected using the 256 bits width instruction. However, it is not only the lookup algorithm that affects the performance of the hash table, the speed and continuity of memory access are also very important. A control block size of 16 or less can fully utilize the cache line of the x86 CPU in most cases, which is a better choice.
In the ordinary zipper hash table, each node of the zipper has only one element. B16 This kind of block zipper method, each node contains 16 elements, which will cause a lot of holes. In order to make the holes as few as possible, we must increase the probability of hash collisions, that is, reduce the size of the BUCKET array as much as possible. We have found through experiments that when the Load Factor is between 11-13, the overall performance of B16 is the best. In fact, this is equivalent to transferring the holes that originally existed in the BUCKET array to the CHUNK zipper, and it also saves the overhead of the next pointer for each node of the ordinary zipper.
4.2 B16Compact Hash Data Structure
In order to further squeeze the storage space of the hash table, we also designed a B16 read-only compact data structure, as shown in the following figure:
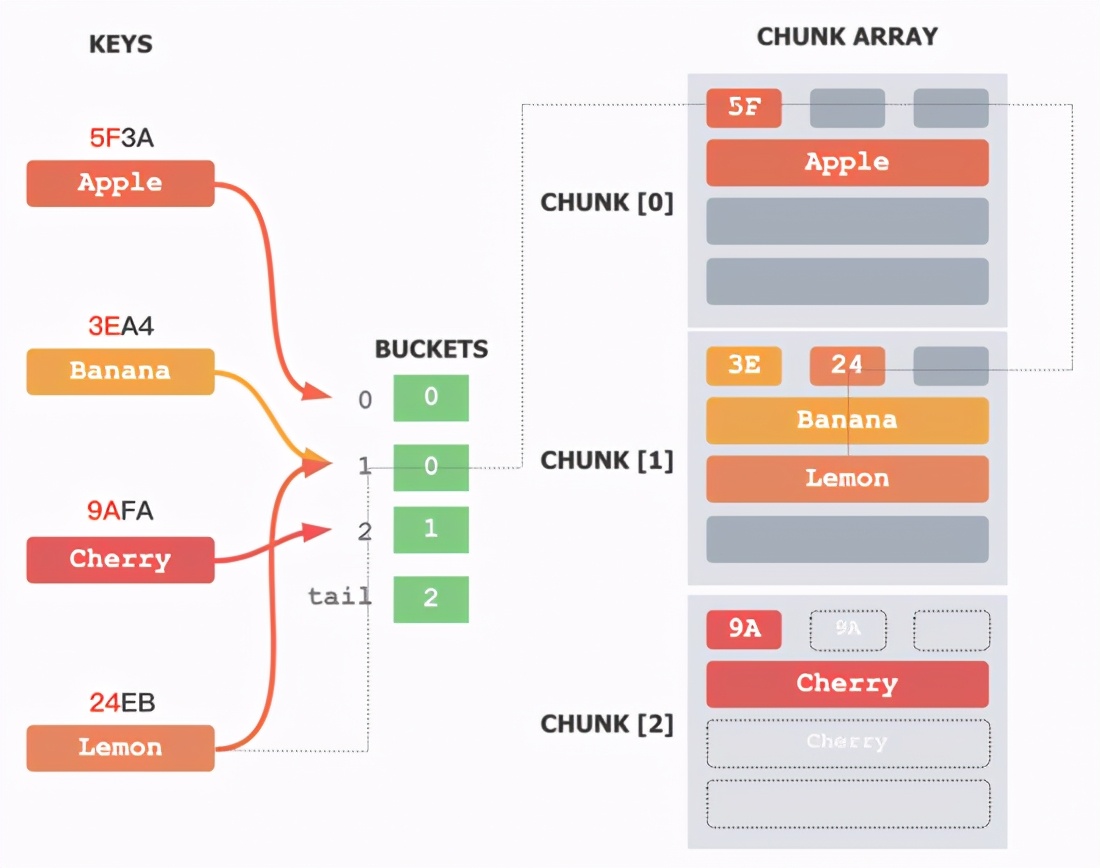
△ B16Compact hash table data structure (3 element example)
B16Compact has made extreme compression on the hash table structure.
First, it saves the next pointer in CHUNK, merges all CHUNKs into an array, and fills in all CHUNK holes. For example, the zipper of BUCKET[1] in [Figure 1] originally had 4 elements, including Banana and Lemon, and the first two elements were added to CHUNK[0] in [Figure 2]. By analogy, all CHUNKs are full except for the last CHUNK in the CHUNK array.
Then it saves the pointer to the CHUNK zipper in BUCKET, and only retains an array subscript that points to the CHUNK where the first element in the original zipper is located. For example, the first element of the zipper of BUCKET[1] in [Figure 1] is added to BUCKET[0] in [Figure 2], then only the subscript 0 is stored in the new BUCKET[1].
Finally, a tail BUCKET is added to record the index of the last CHUNK in the CHUNK array.
After such processing, the original elements in each BUCKET zipper are still continuous in the new data structure, and each BUCKET still points to the first CHUNK block that contains its elements, and the subscript in the next BUCKET is still You can know the last CHUNK block containing its elements. The difference is that each CHUNK block may contain multiple BUCKET zipper elements. Although there may be more CHUNKs to be searched, since each CHUNK can be quickly filtered through the SIMD instruction, the impact on the overall search performance is relatively small.
This read-only hash table only supports search, and the search process is not much different from the original one. Taking Lemon as an example, first find the corresponding bucket 1 through H1=24EB, and get the start CHUNK subscript of the zipper corresponding to the bucket as 0 and the end CHUNK subscript as 1. Use the same algorithm as B16 to search in CHUNK[0], but no Lemon is found, and then continue to search CHUNK[1] to find the corresponding element.
The theoretical additional storage overhead of B16 Compact can be calculated by the following formula:
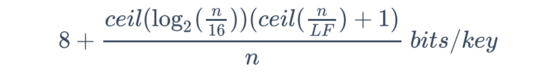
Among them, n is the number of elements in the read-only hash table.
When n is 1 million and Load Factor is 13, the theoretical extra storage cost of the B16Compact hash table is 9.23 bits/key, that is, the extra cost of storing each key is only a bit more than 1 byte. This is almost comparable to some of the smallest perfect hash functions, and there is no build failure.
The B16Compact data structure contains only two arrays, the BUCKET array and the CHUNK array, which means that its serialization and deserialization can be minimal. Since BUCKET stores the array subscripts, the user does not even need to load the entire hash table into the memory. The file offset can be used to perform a hash lookup based on external memory. For huge hashes Table can effectively save memory.
5 Experimental data
5.1 Experimental settings
The Key and Value types of the hash table used in the experiment are both uint64_t, and the input array of Key and Value pairs is pre-generated by the random number generator. The hash table is initialized with the number of elements, that is, there is no need to rehash during the insertion process.
- Insertion performance: It is obtained by dividing the total time of inserting N elements one by one by N, the unit is ns/key;
- Query performance: Get 200,000 random Key queries (all hits) + 200,000 random Value queries (may be missed) to obtain the total time taken divided by 400,000, the unit is ns/key;
- Storage space: Obtained by dividing the total allocated space by the size of the hash table, the unit is bytes/key. For the total allocated space, F14 and B16 have corresponding interface functions that can be directly obtained, and unordered_map is obtained by the following formula:
// 拉链节点总⼤⼩
umap.size() * (sizeof(uint64_t) + sizeof(std::pair<uint64_t, uint64_t>) + sizeof(void*))
// bucket 总⼤⼩
+ umap.bucket_count() * sizeof (void *)
// 控制元素⼤⼩
+ 3 * sizeof(void*) + sizeof(size_t);
Folly library uses-mavx-O2 to compile, Load Factor uses default parameters; B16 uses-mavx-O2 to compile, Load Factor is set to 13; unordered_map uses the Ubuntu system's own version, and Load Factor uses default parameters.
The test server is a 4-core 8G CentOS 7u5 virtual machine, the CPU is Intel(R) Xeon(R) Gold 6148 @ 2.40GHz, and the program is compiled and executed in Ubuntu 20.04.1 LTS Docker.
5.2 Experimental data
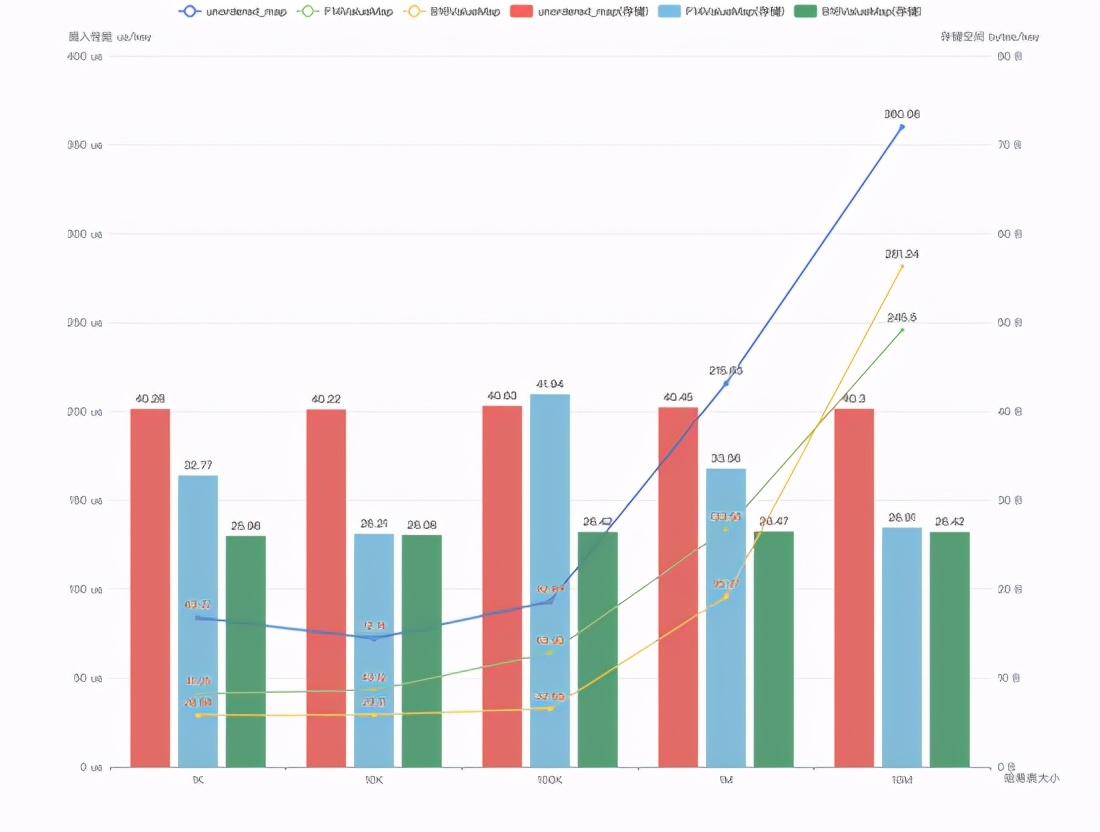
△ Plug-in performance comparison
The broken line in the figure above shows the plug-in performance comparison of unordered_map, F14ValueMap and B16ValueMap. Different bars show the storage overhead of different hash tables.
It can be seen that the B16 hash table still provides significantly better insertion performance than unordered_map when the storage overhead is significantly smaller than that of unordered_map.
Because the F14 hash table has different automatic optimization strategies for Load Factor, the storage space overhead of F14 fluctuates under different hash table sizes, but the overall storage overhead of B16 is still better than F14. The insertion performance of B16 is better than F14 when it is under 1 million keys, but it is inferior to F14 when it is 10 million keys. This may be because the locality of B16 zipper memory access is slightly worse than F14 when the amount of data is large.
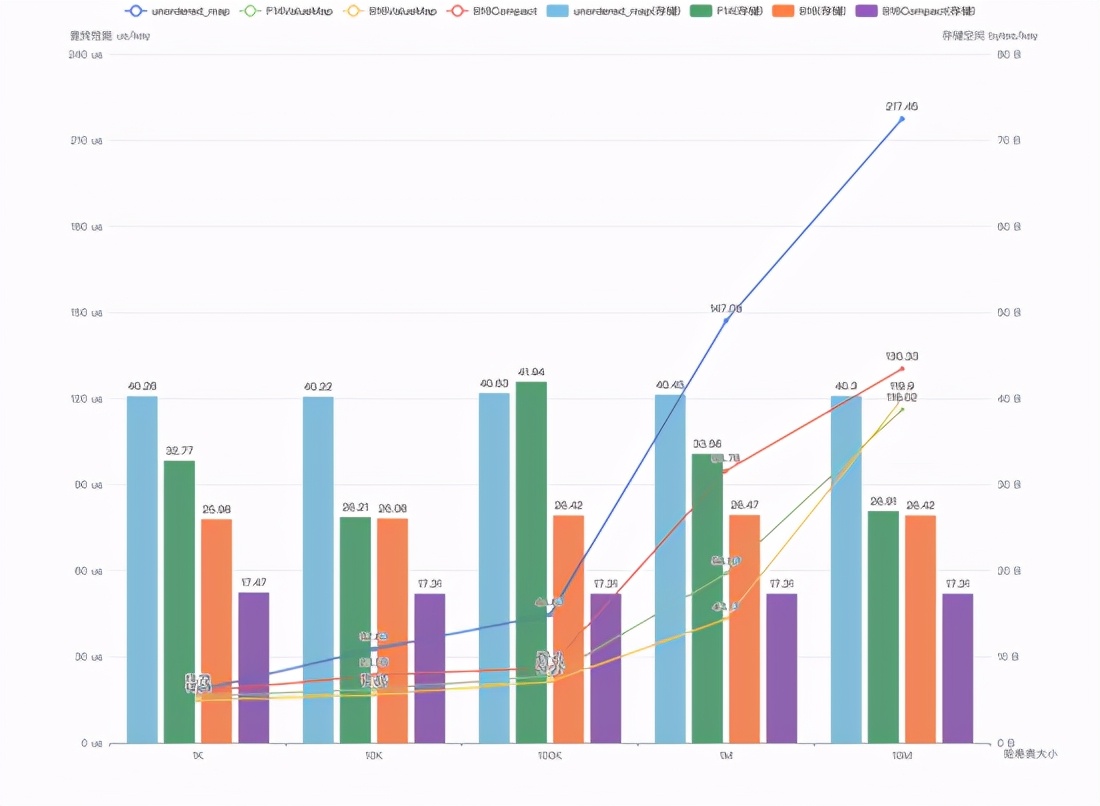
△ Find performance comparison
The broken line in the figure above shows the search performance comparison of unordered_map, F14ValueMap, B16ValueMap, and B16Compact. Different bars show the storage overhead of different hash tables.
It can be seen that the B16 and B16Compact hash tables still provide significantly better search performance than unordered_map when the storage overhead is significantly smaller than that of unordered_map.
The lookup performance comparison between the B16 and F14 hash tables is similar to the insertion performance. It is significantly better than F14 when it is less than 1 million keys, but slightly worse than F14 when it is 10 million.
It is worth noting the performance of the B16Compact hash table. Since the Key and Value types of the experimental hash table are both uint64_t, storing the Key and Value pair itself consumes 16 bytes of space. However, the B16Compact hash table is stable at about 17.31 bytes/key for hash tables of different sizes. For storage, this means that the hash structure only costs 1.31 extra bytes for each Key. The reason why the theoretical overhead of 9.23 bits/key is not reached is because our BUCKET array does not use bitpack for extreme compression (which may affect performance), but instead uses uint32_t.
6 Summary
In this article, we start from the core of hash table design and introduce two interesting and not "common" hash conflict resolution methods: perfect hash function and F14 hash table based on SIMD instructions.
Inspired by F14, we designed the B16 hash table, using a data structure that is easier to understand, making the implementation logic of adding, deleting, and checking simpler. Experiments show that the storage overhead and performance of B16 is better than F14 in some scenarios.
In pursuit of the ultimate storage space optimization, we have tightly compressed the B16 hash table, and designed the B16Compact hash table, which is comparable to the smallest perfect hash function. The storage overhead of the B16Compact hash table is significantly lower than that of the F14 hash table (between 40%-60%), but it provides quite competitive query performance. This can be very useful in situations where memory is tight, such as embedded devices or mobile phones.
The new hash table design shows the effective use of the SIMD instruction parallel processing capability, which greatly improves the tolerance of the hash table to hash collisions, improves the query speed, and helps the hash table to progress. The ultimate storage space compression. This makes the design idea of hash tables shift from avoiding hash conflicts as much as possible to using appropriate hash conflict probabilities to optimize calculation and storage efficiency.
Original link: https://mp.weixin.qq.com/s?__biz=Mzg5MjU0NTI5OQ==&mid=2247485012&idx=1&sn=8948d52f405ff7f9064e54780d7b061e
If you think this article is helpful to you, you can pay attention to my official account and reply to the keyword [Interview] to get a compilation of Java core knowledge points and an interview gift package! There are more technical dry goods articles and related materials to share, let's learn and make progress together!