First, the basic concept
Data structures mentioned in the string, i.e. a string, a whole of n characters (n> = 0). N characters which can consist of letters, numbers or other characters.
Special string
- Empty string: a string containing zero characters
- Whitespace string: a string containing only spaces. Note the empty string and distinguished, spaces in the string is the content, but contains a space
- Sub-string and main string: String any consecutive string of characters called a sub-string of the string, the string comprising a string of substrings is called the primary.
Stored in the form of strings
- Fixed-length sequential storage
This is well understood that, using an array of fixed length (i.e., static arrays) strings.
char a[20];
- Heap-allocated storage
In the C language, there is a free storage area is called the "reactor", with malloc and free function management function, malloc function is responsible for the application space, free function is responsible for freeing up space.
char *a= (char*)malloc(20*sizeof(char)); 申请了20个char字符空间
When the space is large enough, you can re-apply for more storage space with realloc function.
a = (char*)realloc(a, 50*sizeof(char));
//前一个参数指申请空间的对象;第二个参数,重新申请空间的大小
- Storage block chain
#define size 10
struct string_node{
char s[size];
string_node *next;
};
struct String //标记头尾指针,和长度
{
string_node* head, * tail;
int length;
};
When using the chain block stored, there will be the size of the problem node. Storing a plurality of characters, the operation will lead to misery, it will lead to a waste of storage space.
Two, BF matching algorithm
Two strings to determine whether the relationship with the main string of sub-string exists, the most direct method is holding pattern string, and go from start to finish eleven main string comparison, this is the realization of ideas "BF" algorithm.
int BF(char s[], char t[])
//返回子串t在主串S中字符之后的位置。若不存在,则函数值为0。
{
for (int i = 0; i < strlen(s); i++)
{
int flag = 0;
for (int j = 0; j < strlen(t); j++)
if (s[i + j] != t[j]) {
flag = 1;
break;
}
if (flag == 0) {
cout << i+1 << endl;//加一补足
return i+1;
}
if (i + strlen(t) > strlen(s))
return 0;
}
}
The time complexity is O (M * N)
In fact, the entire algorithm loop perform the following two steps:
- From the start of each round of a reference point to compare two strings;
- Found not fully match the target string, the target string will move the position of a character (i.e., updating the reference point) rearward;
Three, KMP algorithm
KMP algorithm can take advantage of the partial match information pattern string, maintaining unchanged the main string pointer i (no backtracking main string), by modifying the pattern string pointer j (the fluctuation pattern string subscript), so that the pattern string to try to move effective position, to reduce the number of comparisons. Algorithm can be time complexity of O (m + n).
example:
"Start" and BF the KMP algorithm is the same algorithm, the same master pattern string and the string of first aligned left to right of the character by character comparison.
The first round, the pattern string and a string such as the eldest son of the main string comparison, five characters are found before the match, the first six characters do not match,
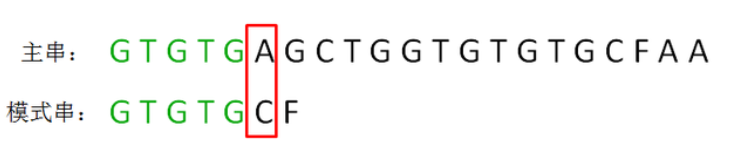
this time, how to effectively use the matched prefix "GTGTG" it?
We can be found in the prefix "GTGTG" among the three characters "GTG" and the first three characters "GTG" are the same:

At the next round of comparison, only two of the same alignment of these fragments, only matching may occur. These two fragments strings, are called the longest substring matches the suffix and prefix longest substring matches.
The second round, we move directly to the mode string two backward, so that the two "GTG" alignment, continue operation begins just a string of bad main character A:

Obviously, the main character strings A character is still bad, this time to shorten the prefix matching become GTG:

Accordance with the idea of the first round, we can re-determine the longest match and the suffix longest substring matching prefix substring may be:

The third round, we again move back two pattern strings, make two "G" alignment, continue operation begins just a string of bad main character A:

The above is the whole idea KMP algorithm: to find the longest prefix among the matched substring matches a suffix and longest matching prefix substring may be, directly to the next round of the two aligned, thereby achieving rapid movement pattern string.
Here we introduce an array next [].
This is a one-dimensional array of integers in the array represents the subscript "next position matched prefix" element value is "next position may be the longest prefix match substrings."
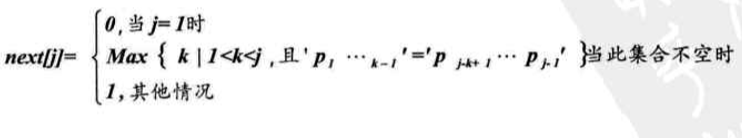
I recommend watching this video , or blog to a deep understanding of next array.
int n[256];
int get_next(char s[])
{
int j = 0;
int k = -1;
n[0] = -1;
while (j < strlen(s)) {
if (k == -1 || s[j] == s[k]) {
//s[k]代表前缀的单个字符,s[j]代表后缀的单个字符
//,此时的 k 即是相同子串的长度
j++, k++;
n[j] = k;
}
else
k = n[k];
//保留了配对失败时的此时前缀字符的k值,方便回溯
}
cout << endl;
return 0;
}
With the next array, write KMP algorithm much easier.
int KMP(char a[], char s[])
{
int i = 0, j = 0;
get_next(s);
int length_a = strlen(a);
//切记不要使用strlen在条件判断中
int length_s = strlen(s);
while (i<length_a&&j<length_s){
if (j == -1 || a[i] == s[j])
i++, j++;
else
j = n[j];
}
if (j == strlen(s))
{
cout << i - j+1 << endl;//位置
return (i - j+1);
}
return 0;
}