About kmp algorithm
KMP algorithm is an improved string matching algorithm, proposed by DEKnuth, JHMorris and VRPratt, so people call Knuth - Morris - Pratt operation (referred KMP algorithm). The core KMP algorithm using information fails to match, to minimize the number of main string pattern string match to achieve the purpose of fast matching. Specific implementation is implemented by a function next (), local matching function itself contains information pattern string. KMP time complexity of the algorithm O (m + n).
simply put:
kmp algorithm, using the same pattern string is the longest prefix and suffix to move, and does not require the main string back, so as to achieve fast match.
for example:
Below, when a mismatch occurs at the arrows, to find the longest prefix and suffix of the same before an arrow pattern string substring is AB;

and the prefix to the suffix AB AB moved position;

continue to match the same token, does not occur match found pattern string before the arrow longest substring same prefix and suffix for a;

and the prefix moved to the position a of the suffixes a, because it is beyond the length of the main string match fails.

Another example:
Below, when a mismatch occurs at the arrows, to find the longest prefix and suffix of the same before an arrow pattern string substring of ABA;

and the prefix to the suffix ABA ABA moved position;

continue to match the same token, it does not occur match found pattern string before the arrow longest substring same prefix and suffix for a;

and the prefix moved to the position a of the suffix a, continues to match, the match succeeds.

Obtained next array
String set mode is p, pattern string is to be noted that the index is from 0 to p.size () - 1, and the next array corresponding thereto is 1 to p.size (), next [0] = - 1.
void getNext(string p, int *next)
{
next[0]=-1;
int i=0,j=-1;//j是前缀,y是后缀
while (i<p.size())
{
if(j==-1||p[i]==p[j])
{
++i;
++j;
next[i]=j;
}
else
{
j=next[j];//回溯
}
}
}
The hardest to understand is the phrase,
j=next[j];//回溯
Why is this so? But wait, for example:
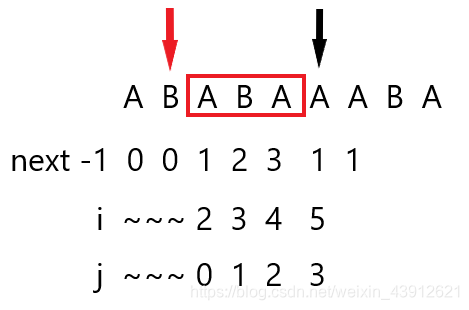
! When i = 5, j = 3, i.e. the position of the black arrow, p [i] = p [ j], i , and j indexes from 0 to P.SIZE (), then j = next [j], i.e., j = 1, i.e. the position of the red arrow unequal continues back to j = 0, so saving time back. The original dates back prefix is known, our next stored in the array is equal to the longest prefix and suffix for each index.
C ++ implementation:
#include<iostream>
using namespace std;
void getNext(string p, int *next)
{
next[0]=-1;
int i=0,j=-1;
while (i<p.size())
{
if(j==-1||p[i]==p[j])
{
++i;
++j;
next[i]=j;
}
else
{
j=next[j];
}
}
for(int i=0;i<=p.size();i++)
{
cout<<next[i]<<" ";
}
}
int kmp(string x,string y,int *next)
{
int i=0,j=0;
while(true)
{
if(x[i]==y[j]||j==-1)
{
i++;j++;
}
else
{
j=next[j];
}
if(i==x.size()||j==y.size()) break;
}
if(j==y.size())
{
return i-j;
}
else return -1;
}
int main()
{
string x;string y;
int *next=new int[1000005];
cin>>x>>y;
getNext(y,next);
int ans=kmp(x,y,next);
cout<<ans;
return 0;
}
