在前一篇文章《Win7 下使用spark 对文件进行处理》中,我们搭建了一个win7的开发测试环境,生成了一个jar执行包,并能够成功的在本机以多线程方式调试及运行,但将这个包分发到linux spark集群上,以standalone方式运行时,却报如下异常:
18/05/22 17:13:22 ERROR Executor: Exception in task 0.0 in stage 0.0 (TID 0)
java.lang.ClassCastException: cannot assign instance of scala.collection.immutable.List$SerializationProxy to field org.apache.spark.rdd.RDD.org$apache$spark$rdd$RDD$$dependencies_ of type scala.collection.Seq in instance of org.apache.spark.rdd.MapPartitionsRDD
at java.io.ObjectStreamClass$FieldReflector.setObjFieldValues(ObjectStreamClass.java:2233)
at java.io.ObjectStreamClass.setObjFieldValues(ObjectStreamClass.java:1405)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2288)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2206)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2064)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1568)
at java.io.ObjectInputStream.defaultReadFields(ObjectInputStream.java:2282)
at java.io.ObjectInputStream.readSerialData(ObjectInputStream.java:2206)
at java.io.ObjectInputStream.readOrdinaryObject(ObjectInputStream.java:2064)
at java.io.ObjectInputStream.readObject0(ObjectInputStream.java:1568)
at java.io.ObjectInputStream.readObject(ObjectInputStream.java:428)
at scala.collection.immutable.List$SerializationProxy.readObject(List.scala:479)
以下记录解决此问题的思路与过程。
部署环境及变量设置:
3台ubuntu虚拟机,已经配置好ssh免密登录《Linux系统中SSH安装及配置免密码登录》
master: 192.168.2.1 slave1: 192.168.2.2 slave2: 192.168.2.3
使用的是spark 2.2.1版本,spark在ubuntu上的standalone部署将另写文章记录
/home/mytestzk/spark-2.2.1-bin-hadoop2.7
因为程序使用了redis作为存储,故安装了redis 最新的版本4.0.9
/home/mytestzk/redis-4.0.9
添加环境变量到/etc/profile
export SPARK_HOME=/home/mytestzk/spark-2.2.1-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin
因spark可以不依赖hdfs,故虽然也安装了hadoop,但此处可以先忽略,所以不需要启动hdfs,如果文件是保存在hdfs中,则需要先启动hdfs
修改redis的配置文件redis.conf如下参数:
bind 192.168.2.1 protected-mode no
修改spark的配置文件以使spark运行在standalone集群模式:
- spark-defaults.conf
spark.master spark://192.168.2.1:7077
- spark-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_151 export SPARK_MASTER_HOST=master export SPARK_MASTER_PORT=7077 export SPARK_WORKER_MEMORY=2g
- slaves
slave1 slave2
Spark 以standalone集群方式运行及问题产生
首先启动redis
src/redis-server --protected-mode no
启动spark,执行spark-2.2.1-bin-hadoop2.7目录下命令,启动spark集群
src/start-all.sh
提交作业,将已经打好的jar包及测试文件上传到相应的目录后,然后提交spark程序如下,因为是一个完整的sprint boot包,在pom文件中已经指定了启动类,所以在运行spark-submit时不需要给出class参数
spark-submit --master spark://master:7077 --executor-memory 2g --total-executor-cores 2 /home/mytestzk/projects/myproject-1.0-SNAPSHOT.jar /mnt/WindowShare/holdings1.txt
运行异常如下所示:

问题解决:
经过上网搜索,有很多类似问题,有的意见是将spark-core_2.11的scope修改为provided,但验证后不起作用,后来发现在SPARK有一个类似jira: https://issues.apache.org/jira/browse/SPARK-19938,其中有一段comment:
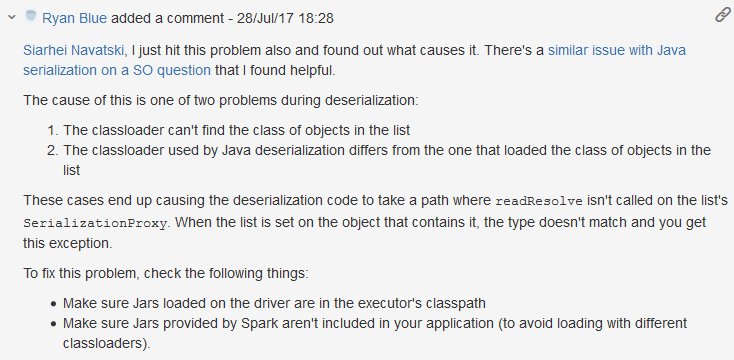
因为程序在standalone集群下以交互模式是可以运行成功的,
注: 以交互方式在standalonoe集群上测试,首先是启动spark集群及redis server,然后在启动spark-shell时,需要指定master参数,完整命令如下: spark-shell --master spark://master:7077 --executor-memory 2g --total-executor-cores 2 --jars jedis-2.9.0.jar
如果启动spark shell时没有指定master地址,也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,和spark集群没有关系。
故可以排除代码的问题,那问题就很可能在使用spart-submit提交程序时,环境不一致导致的,因为我使用的打包插件是spring-boot-maven-plugin,jar包里是使用的classloader是springframework loader,根据上面jira里comment的描述(avoid loading with different classloaders),很有可能问题就出在这里
<build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <executions> <execution> <goals> <goal>repackage</goal> </goals> <configuration> <!--<classifier>spring-boot</classifier>--> <mainClass>mytest.Import</mainClass> </configuration> </execution> </executions> </plugin> </plugins> </build>
修改方案1:修改pom文件,不使用sprint boot插件:
<build> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <version>2.15.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.6.0</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-surefire-plugin</artifactId> <version>2.19</version> <configuration> <skip>true</skip> </configuration> </plugin> </plugins> </build>
这次打包出来的jar包只包含代码的class文件,不包含第3放的类库,因为这个spark程序需要使用的jedis-2.9.0.jar也没有包含到输出的jar包中,这个包只有10k不到,为了正确执行这个包,必须先把依赖的第3方库也上传到spark环境相应的目录中,在调用spark-submit时,需要通过参数--jars指定依赖包的路径,命令执行如下
spark-submit --class mytest.Import --jars /home/mytestzk/projects/jedis-2.9.0.jar --master spark://master:7077 --executor-memory 2g --total-executor-cores 2 /home/mytestzk/projects/myproject-1.0-SNAPSHOT.jar /mnt/WindowShare/holdings1.txt
执行成功,问题解决!
修改方案2:
进一步,对于上面方案,如果依赖的第3放包比较少,也还可以,命令参数不会太长,但如果要依赖很多包,那么在spark-submit的jars参数中就需要列出来所有的包,中间用逗号分隔,这样导致命令就比较长,很麻烦,那是否可以把所有需要依赖的第3放包放到一个专门的目录中呢,查看spark文档,答案是可以的,
修改spark的spark-default.conf,添加下面参数指定第3方库的目录,将依赖包jedis-2.9.0.jar拷贝到这个目录
spark.executor.extraClassPath=/home/mytestzk/projects/* spark.driver.extraClassPath=/home/mytestzk/projects/*
执行spark-submit命令如下
spark-submit --class mytest.Import --master spark://master:7077 --executor-memory 2g --total-executor-cores 2 /home/mytestzk/projects/myproject-1.0-SNAPSHOT.jar /mnt/WindowShare/holdings1.txt
执行成功,问题解决!
修改方案3:
上面2种方案,需要单独部署第3方依赖库到spark执行环境,部署升级都很麻烦,如果能将程序所有依赖的包都打在一起,这样部署升级都很方便,那好吧,再进一步,修改pom文件
<build> <sourceDirectory>src/main/scala</sourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.5</arg> </args> </configuration> </plugin> <plugin> <artifactId>maven-assembly-plugin</artifactId> <version>3.0.0</version> <configuration> <archive> <manifest> <mainClass>mytest.Import</mainClass> </manifest> </archive> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build>
使用maven-assembly-plugin插件,依赖的jar包会被解开并打入包中,而最开始使用的sprint-boot-maven-plugin插件,依赖的jar包是不会被解开的,使用这种方法,也不需要修改spark-defaults.conf文件了,重新打包并执行:
spark-submit --class mytest.Import --master spark://master:7077 --executor-memory 2g --total-executor-cores 2 /home/mytestzk/projects/myproject-1.0-SNAPSHOT-jar-with-dependencies.jar /mnt/WindowShare/holdings1.txt
执行成功,问题解决!
思考这次遇到的问题,其实是从一开始,就希望能够使用spint boot方式将所有依赖的库打包成一个fat jar,但又不希望依赖库被解包,如果开始是使用的maven assembly插件,就不会出现这个问题,也不会在这个问题上折腾了许久时间,但不折腾无收获,希望对遇到类似问题的朋友有帮助。