固态、机械双硬盘+UEFI、APT+Win10、Ubuntu18.04LTS双系统+GTX 1080Ti+Cuda9.0+cudnn7.1.4+Tensorflow1.12
1、系统框架
1.1 在win10系统上安装unbuntu
SSD 250G + 机械硬盘1t。我将SSD分出一部分作为C盘装win10系统,剩余100G不分区以备全部装linux; 机械硬盘整个作为一个区,用于win10系统下安装个人软件和存储文档。两个硬盘都借助diskGenius采用4K对齐格式化,并且两个硬盘的分区表都采用APT格式。(以上凭借小白PE软件完成)
Win10装好后,去ubuntu官网https://www.ubuntu.com/download下载Ubuntu18.04LTS桌面版的安装ISO,制作成USB启动盘。
重启机器,然后进入bios设置界面。在BOOT选项中,选UEFI USB这一项,进入U盘中的安装程序,不要安装第三方软件,并在分区页面选择“其他选项”,将SSD上面剩余的100G分成以下几个分区:
保留BIOS启动区域 主分区 空间起始区域 1G
swap 逻辑分区 空间起始区域 8G(我的内存是32G, 官方说只要不设置自动休眠,8G就够)
/usr 逻辑分区 空间起始区域 32G(因为很多软件的默认位置都是这里)
/ 逻辑分区 空间起始区域 16G(/usr和/home之外的所有东西都挂载在个目录)
/home 逻辑分区 空间起始区域 剩余空间
最后设置把ubuntu的grub装在保留bios启动区域,设置用户名和密码,开始安装…
重启电脑,进入bios设置界面,把启动选项改成UEFI hard disk这一项,并且设置成ubuntu grub,这样就可以直接用ubuntu自带的引导程序选择是进入ubuntu还是win10。
1.2 安装unbuntu单系统
如果是单系统,分区方案改为
sda(255G固态硬盘)
EFI partition 主分区 空间起始区域 1G
swap 逻辑分区 空间起始区域 8G(我的内存是32G, 官方说只要不设置自动休眠,8G就够)
/usr 逻辑分区 空间起始区域 64G(因为很多软件的默认位置都是这里)
/ 逻辑分区 空间起始区域 32G(/usr和/home之外的所有东西都挂载在个目录)
/home 逻辑分区 空间起始区域 freespace
sdb(1T机械硬盘)
/home/data 逻辑分区 空间起始区域 freespace
保留BIOS启动区域类型需要换成EFI partition。机械硬盘可以选择挂载在/home/data分区,但是这样用起来不太方便,因为目录结构会这样:
/home
____/data
____/用户名
而且/data这个文件夹属于root。如果你想让你自己随时可以方便取用这个硬盘,可以在安装完以后登录系统,进入用户目录
cd ~
ls /dev/sd* #查看你的机械硬盘的名称,以sdb为例
sudo umount /dev/sdb1 #假设机械硬盘上只有一个分区,是安装系统的时候已经分区好的
sudo mount /dev/sdb1 Documents #将这个分区挂载在Documents目录下
sudo vim /etc/fstab #设置sdb1启动自动挂载,将原来挂载/home/data目录改成/home/用户名/Documents
sudo chown -R 用户名:用户名 Documents #将文件夹所有者和群组从root改成你自己
最后把原来的/home/data这个文件夹删除就好了。你可以用df命令查看硬盘情况,也可以用fdisk -l查看使用情况。
如果你此时要再装一块新硬盘,与以上方法类似,但硬盘插好后要首先执行以下步骤
sudo fdisk -l #查看计算机内所有硬盘,查看你的机械硬盘的名称,以sdb为例
sudo mkfs.ext4 /dev/sdb #格式化,将生成sdb1分区
ls -l /dev/disk/by-uuid/ #记录sdb1的UUID
1.3 在ubuntu系统上安装win10
比如我们现在想把1T的机械硬盘拿出一部分来作为windows系统
sudo fdisk -l #查看计算机内所有硬盘,查看你的机械硬盘的名称,以sdb为例
sudo umount /dev/sdb1 # 假设目前只有一个分区,先卸载
sudo fdisk /dev/sdb # 开始对这块硬盘进行操作
d ——————》 1 # 删除/dev/sdb1这个分区
n ——————》 1 # 新建分区1,起始扇区默认2048, 设置分区大小为300G,用于linux系统的个人文件存储
n ——————》 2 # 新建分区2,起始扇区默认,用剩余所有空间,用于windows系统
w # 保存退出
sudo mkfs.ext4 /dev/sdb1 #格式化sdb1分区
ls -l /dev/disk/by-uuid/ #记录sdb1的UUID
sudo vim /etc/fstab #设置sdb1启动自动挂载到/home/用户名/Documents
sudo chown -R 用户名:用户名 ~/Documents #将文件夹所有者和群组从root改成你自己
重启机器,然后进入bios设置界面。在BOOT选项中,选UEFI USB这一项,进入U盘中的win10 PE程序。使用虚拟win10桌面的分区工具将1T硬盘尚未格式化的空间分成两部分,都格式化为NTFS,一个作为C盘安装win10系统,另一个作为程序和文件盘。然后启动PE程序将win10安装到C盘。安装好以后你会发现win10系统有三个盘,一个是C盘系统盘,一个是D盘即程序和文件盘,还有一个E盘是启动盘(其实是借用了linux系统的EFI partition,即固态硬盘的主分区/dev/sda1)。
既然如此,就可以利用ubuntu的grub选择启动哪个系统了,不过需要更新一下grub的选项
sudo update-grub # 更新grub选项
sudo reboot #启动的时候注意看一下grub选项里面windows系统是第几个
sudo gedit /etc/default/grub # 设置grub默认启动顺序
GRUB_DEFAULT=××× #修改对应行,默认取值0,即启动grub选项里面的第一个,改成windows的那一个
sudo update-grub
sudo reboot
2、在Ubuntu18.04LTS上面配置开发环境
在图像界面选择安装过程中设置的用户名,输入密码,登录,然后开始配置开发环境
设置root权限:
sudo passwd
输入安装时设置的用户密码(不是root哦)
设置root密码
确认密码
然后退出root,换成普通用户(你安装时设置的用户)
安装vim:
sudo apt-get install vim
sudo vim /etc/vim/vimrc
在文件的最后添加
set nu
set tabstop=4
set shiftwidth=4
set expandtab
set nobackup
set cursorline
set ruler
set autoindent
set fileencodings=utf-8,gb2312,gb18030,gbk,ucs-bom,cp936,latin1
set termencoding=utf-8
set listchars=tab:>-,trail:-
set list
如果你想在vim里面使用系统剪贴板,再安装
sudo apt-get install vim-gtk
你就可以用"+p来从系统剪贴板粘贴进vim, 用"+y来将vim复制到系统剪贴板了。
配置源:
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
sudo vim /etc/apt/sources.list
把里面的都删除,再把清华源复制进去https://mirror.tuna.tsinghua.edu.cn/help/ubuntu/
sudo apt-get update
编译环境:
sudo apt-get install build-essential
安装输入法:
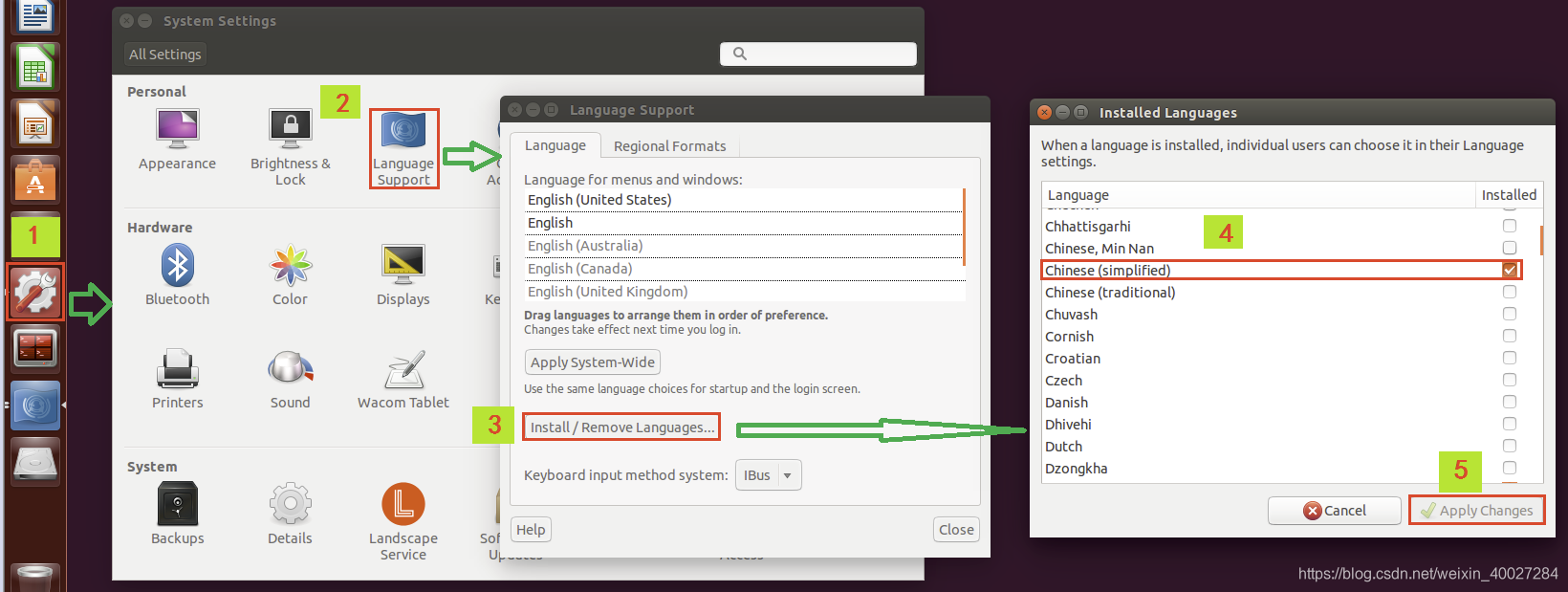
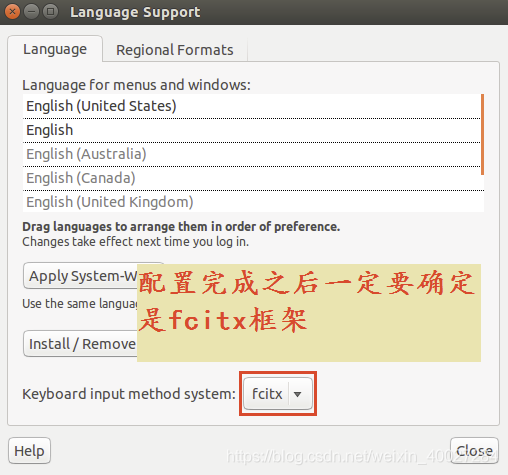
配置好输入法框架之后,重启ubuntu系统。重启之后如果配置成功,在任务栏的右上角会出现fcitx的设置选项
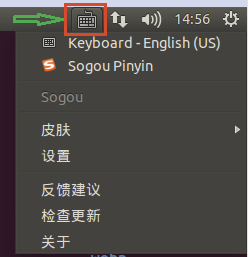
https://pinyin.sogou.com/linux/?r=pinyin
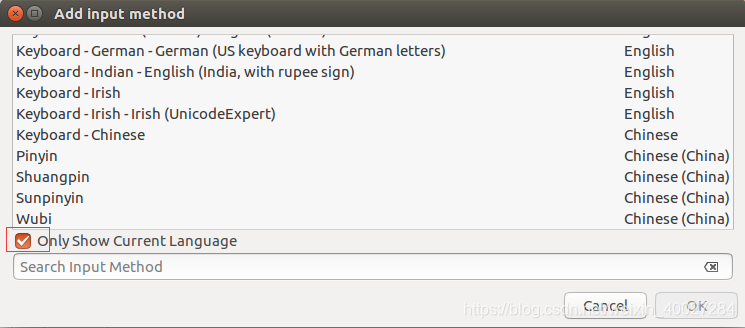
下载完成之后使用 dpkg -i *.deb 安装搜狗输入法。点击右上角的小键盘,选择配置选项。

点击“+”号添加输入法
安装git:
sudo apt-get install git
git config --global user.name "Your Name"
git config --global user.email "[email protected]"
git config --global core.editor vim
ssh-keygen -C 'you email ' -t rsa #公钥的参数全部默认,不用设置phrasekey
然后登录你的远程github账号,选择settings–ssh and gpg keys—new ssh keys
title任意填一个名称
内容将 ~/.ssh/id_rsa.pub里面的内容全部复制进去。
确定后你就可以将你的本地仓库push到远程仓库了
安装unrar:
apt-get install unrar
安装qq和微信:
git clone https://github.com/wszqkzqk/deepin-wine-ubuntu.git
在http://mirrors.aliyun.com/deepin/pool/non-free/d/中下载想要的容器,点击deb安装即可
QQ:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.com.qq.im/
TIM:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.com.qq.office/
QQ轻聊版:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.com.qq.im.light/
微信:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.com.wechat/
Foxmail:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.com.foxmail/
百度网盘:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.com.baidu.pan/
360压缩:http://mirrors.aliyun.com/deepin/pool/non-free/d/deepin.cn.360.yasuo/
解决windows和linux系统之前切换时间混乱的问题
sudo timedatectl set-local-rtc 1
安装护眼redshift:
sudo apt-get install redshift
sudo apt install gtk-redshift #这个是安装一个图标,不安的话可以在terminal里直接输入redshift来启动
vim ~/.config/redshift.conf
配置文件中添加
[redshift]
brightness-day=0.9
brightness-night=0.9
gamma=0.8
[manual]
lat=32
lon=120
在启动前,要保证你的location services(类似于GPS定位)已经开启:Settings > Privacy > Location Services
然后可以在terminal 输入redshift来启动,或者去找你下在的图标,点击运行,启动完找到托盘里的图标,把autostart选上
解决gedit中文乱码问题:
运行dconf-editor
展开/org/gnome/gedit/preferences/encodings
candidate encoding下面加入 [‘GB18030’,‘GBK’,‘GB2312’,‘UTF-8’];
gedit显示空格和制表符
sudo apt-get install gedit-plugins
打开Gedit,点击“edit”->“preferences”->“plugins”。
找到“Draw Spaces”选项,选中
点击“edit”->“preferences”->“editor”
找到tab stop, 设置为4,并选中use spaces to replace tab,enable auto indentation
安装spark
首先到oracle官网下载jdk8的Linux包
http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
我下载的是jdk-8u221-linux-x64.tar.gz
cd ~/Downloads
tar -zxvf jdk-8u221-linux-x64.tar.gz #得到jdk1.8.0_221
cd /usr/lib
sudo mkdir jdk
sudo mv ~/Downloads/jdk1.8.0_221 jdk
vim ~/.bashrc
#set java environment
export JAVA_HOME=/usr/lib/jdk/jdk1.8.0_221
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
source ~/.bashrc
sudo ln -s /usr/lib/jdk/jdk1.8.0_221/bin/javac /usr/bin/javac
sudo ln -s /usr/lib/jdk/jdk1.8.0_221/bin/java /usr/bin/java
输入java -version验证是否安装成功
然后安装scala
https://www.scala-lang.org/download/
选择binaries for linux, 我下载的版本为scala-2.13.0.tgz
cd ~/Downloads
tar -zxvf scala-2.13.0.tgz #得到scala-2.13.0
cd /usr/lib
sudo mkdir scala
sudo mv ~/Downloads/scala-2.13.0 scala
vim ~/.bashrc
#set scala environment
export SCALA_HOME=/usr/lib/scala/scala-2.13.0
export PATH=${SCALA_HOME}/bin:$PATH
source ~/.bashrc
输入scala验证是否成功
进入spark官网
http://spark.apache.org/downloads.html
我下载的是spark-2.4.3-bin-hadoop2.7.tgz
cd ~/Downloads
tar -zxvf spark-2.4.3-bin-hadoop2.7.tgz #得到spark-2.4.3-bin-hadoop2.7
cd /usr/lib
sudo mkdir spark
sudo mv ~/Downloads/spark-2.4.3-bin-hadoop2.7 spark
vim ~/.bashrc
#set spark environment
export SPARK_HOME=/usr/lib/spark/spark-2.4.3-bin-hadoop2.7
export PATH=$SPARK_HOME/bin:$PATH
export PYTHONPATH=$SPARK_HOME/python/:$PYTHONPATH
source ~/.bashrc
pip install py4j==0.10.7 #spark2.4.3要求的
输入spark-shell可以出来scala界面的spark
python import pyspark可以出来python界面的spark
安装eclipse
到http://www.eclipse.org/downloads/packages/下载Eclipse IDE for C/C++ Developers
cd ~/Downloads
tar -zxvf *.tar.gz -C /home/用户名 #将其解压缩到用户目录下,生成eclipse文件夹
cd /home/用户名/eclipse/
./eclipse
启动Eclipse, Window -> Preferences -> General -> Editors -> Text Editors -> Show whitespace characters
insert space for tabs, displayed tab width=4
File—New—Project—C++Project----Empty----新建的工程右击-----new folder–src----src右击—new source file, 生成cpp文件(记得自己加cpp后缀)
点击help-eclipse marketplace,搜索cmake editor,安装cmake editor和cmake4eclipse
启动Eclipse, 点击Help->Install New Software… 在弹出的对话框中,点Add 按钮。 Name中填:Pydev, Location中填http://pydev.org/updates
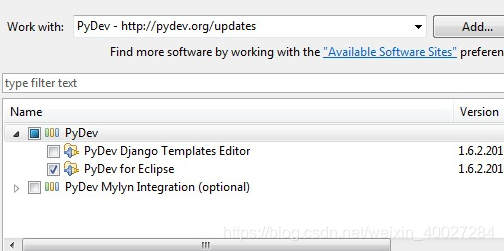
不要勾选第一项
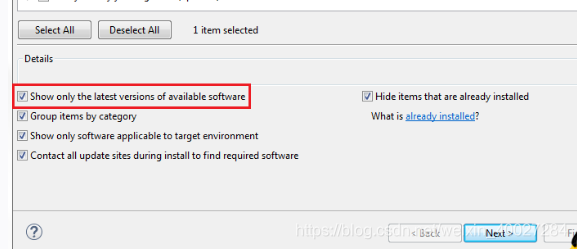
在Window菜单中选Preference,选择PyDev下面的Intercepters,选择Python Intercepter。然后点击右侧的New…,在弹出框中选择python安装路径,即python.exe所在文件路径。
点击File,选择New Project,选择PyDev下面的PyDev Project
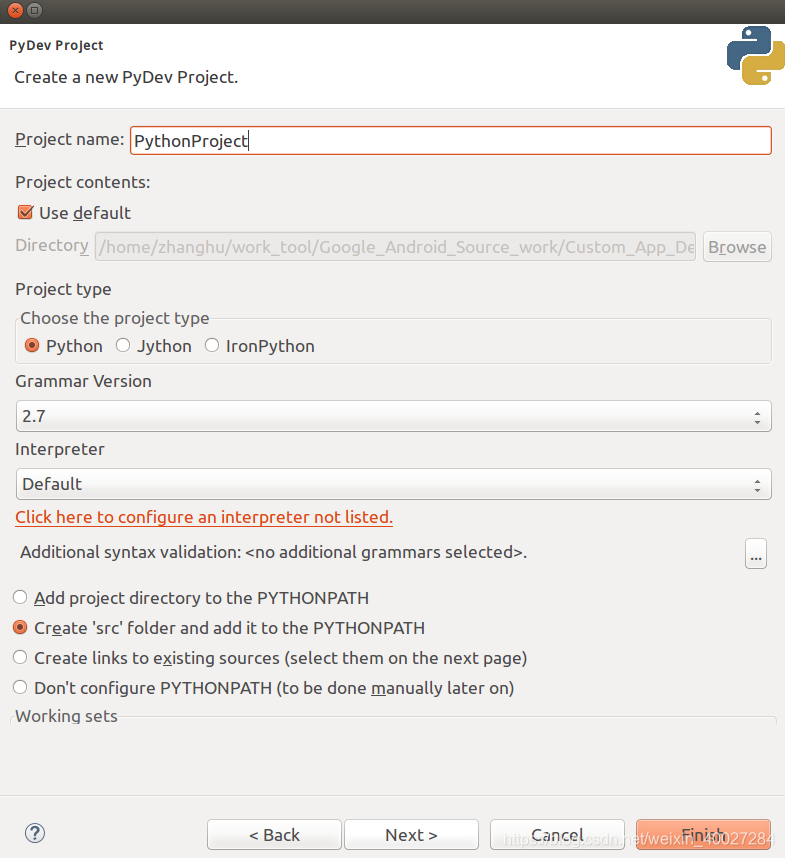
右键src,选择New->PyDev Package,建立一个包,默认生成init.py。在包下新建×××.py
安装gtest
从https://github.com/google/googletest.git上clone最新的gtest代码
cd googletest/googletest
vim CmakeLists.txt
找到如下代码,将C++11标准添加进去
if (CMAKE_VERSION VERSION_LESS 3.0)
project(gtest CXX C)
else()
cmake_policy(SET CMP0048 NEW)
set(CMAKE_CXX_STANDARD 11) #添加
set(CMAKE_CXX_STANDARD_REQUIRED ON) #添加
project(gtest VERSION ${GOOGLETEST_VERSION} LANGUAGES CXX C)
endif()
生成静态链接库
mkdir build
cmake …
make
生成libgtest.a libgtest_main.a两个静态库
写测试cpp的时候,加入#include <gtest/gtest.h>, 编译的时候把googletest/googletest/include下面的gtest文件夹所在路径作为该cpp搜索头文件时的路径,链接的时候把上述两个.a文件所在的路径作为library搜索路径并指明库名gtest(比如g++ -lgtest)
如果要生成动态链接库,在上述cmakelists.txt文件中找到如下代码
option(BUILD_SHARED_LIBS “Build shared libraries (DLLs).” OFF) #把off改成ON
然后按照上述静态库的方法,mkdir build2 cmake… make
生成libgtest.so libgtest_main.so两个动态库,编译的时候把googletest/googletest/include下面的gtest文件夹所在路径作为该cpp搜索头文件时的路径,链接的时候把上述两个.so文件所在的路径作为library搜索路径并指明库名gtest(比如g++ -lgtest)。如果你想把动态库文件放在某个默认路径下面,链接时候不用指定搜索路径了,可以把上述库文件拷贝在/lib或/usr/lib下面,然后任意路径下执行ldconfig, ldconfig通常在系统启动时运行,默认搜寻/lilb和/usr/lib,以及配置文件/etc/ld.so.conf内所列的目录下的库文件,因此当用户安装了一个新的动态链接库时又不想重新启动系统就直接用新的库,就需要手工运行这个命令。搜索出来的可共享的动态链接库格式为:lib***.so.**,进而创建出动态装入程序(ld.so)所需的连接和缓存文件,缓存文件默认为/etc/ld.so.cache,该文件保存已排好序的动态链接库名字列表。如果你想装在自己的某个路径下,比如/usr/local/lib/目录下,就要修改/etc/ld.so.conf文件,往该文件追加library所在的路径,然后也需要重新调用下ldconfig命令。
比如在安装MySQL的时候,其库文件/usr/local/mysql/lib,就需要追加到/etc/ld.so.conf文件中。命令如下:
echo “/usr/local/mysql/lib” >> /etc/ld.so.conf
ldconfig -v | grep mysql
还有一个办法,就是往~/.bashrc里面往LD_LIBRARY_PATH添加你的动态库的路径
安装CLION, 公司的人都用这个。。。。。
http://www.jetbrains.com/clion/download/#section=linux
tar -xzvf CLion-2018.3.3.tar.gz #把解压缩后的文件夹放在用户主目录下~/
cd ~/clion-2018.3.3/bin
./clion.sh #一直默认往下走
点击激活窗口的“Evaluate for free”免费试用,然后再创建一个空项目,这样就可以进入到工作页面
点击链接 https://pan.baidu.com/s/16ALpz_BCXjsRkpS_PtD23A 下载补丁文件 jetbrains-agent.jar 并将它放置到安装目录的\bin目录下
点击最上面的菜单栏中的 “Help” -> “Edit Custom VM Options …”,如果提示是否要创建文件,请点"Yes",会自动在你的
~/目录下面建立.Clion2018.3/config文件夹,并在文件夹里面建立clion64.vmoptions文件
在打开的vmoptions编辑窗口末行添加:-javaagent:/home/你的用户名/clion-2018.3.3/bin/jetbrains-agent.jar
删除~/clion-2018.3.3/bin目录下的clion.vmoptions和clion64.vmoptions
重启之后,点击菜单栏中的 “Help” -> “Register …”,选择最后一种License server激活方式,地址填入:http://jetbrains-license-server (应该会自动填上),或者点击按钮:”Discover Server”来自动填充地址,完成激活
当你激活完毕后,右下角会有个Registration小长条提示框,大致的内容为:You copy is Licensed to XXX意思就会告诉你:兄弟,你已经激活成功了
查看有效期的步骤为点击:Help->About这里可以看到你的pycharm的版本号、许可来源、有效期、以及一些环境
服务器激活是没有期限的,即为永久有效
安装pycharm, 专业pythoner也用这个,所以。。。。安装方法与clion一样,毕竟一家公司
https://www.jetbrains.com/pycharm/download/#section=linux
最新方法http://idea.lanyus.com/
3、安装tensowflow
3.1 准备工作
安装依赖包
sudo apt-get install libprotobuf-dev libleveldb-dev libsnappy-dev libopencv-dev libhdf5-serial-dev protobuf-compiler
sudo apt-get install --no-install-recommends libboost-all-dev
sudo apt-get install libopenblas-dev liblapack-dev libatlas-base-dev
sudo apt-get install libgflags-dev libgoogle-glog-dev liblmdb-dev
sudo apt-get install cmake libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
sudo apt-get install ffmpeg libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
sudo apt-get install python-pil python-lxml python-tk
如果安装出现什么问题,都是依赖没建立导致的,将错误复制,进行百度一个个解决,安装完成后都需要:
sudo apt-get update
sudo apt-get upgrade
以下同
下载anaconda 3
bash Anaconda3-4.3.0-Linux-x86_64.sh #这个版本的默认Python为3.6,太高版本怕不能装tensorflow。 安装在/home/你的用户名/
添加源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
conda config --set show_channel_urls yes
pip install --upgrade pip
conda upgrade libgcc
#删除源的话用
conda config --remove channels XXXXX
#显示源的话用
conda config --show
安装xgboost
https://s3-us-west-2.amazonaws.com/xgboost-wheels/list.html
下载xgboost-0.81-py2.py3-none-manylinux1_x86_64.whl
pip install xgboost-0.81-py2.py3-none-manylinux1_x86_64.whl
3.2 安装显卡驱动
首先卸载以前的nvidia驱动版本
sudo apt-get purge nvidia*
然后用系统自带的安装驱动方法来装,这样就不用关图形界面了(我的电脑默认驱动版本为390)
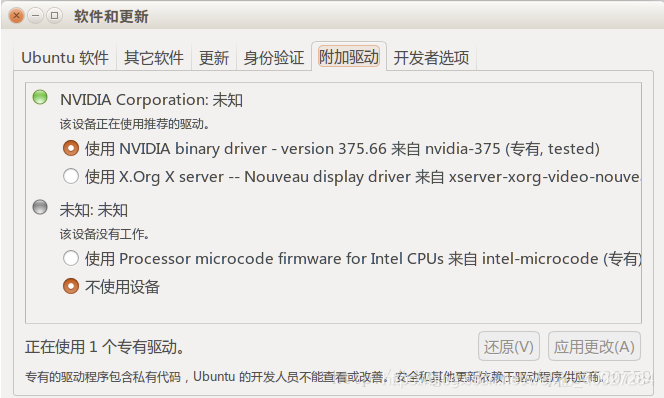
点击应用更改,重启电脑,命令行输入
nvidia-smi
如果出现如下图片说明成功
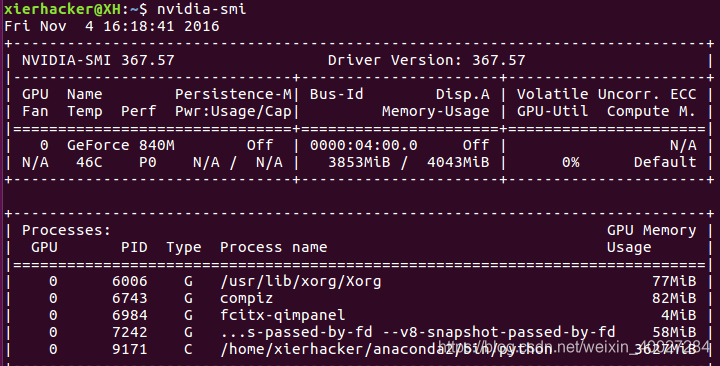
如果是Ubuntu16.04的系统,系统默认的nvidia是384.13,这个版本低于cuda 9.0 384.81,因此你需要自己手动来安装nivida了。不过也不麻烦O(∩_∩)O哈哈~
http://www.nvidia.com/Download/index.aspx?lang=en-us 这个网站可以看你需要的驱动版本
sudo add-apt-repository ppa:graphics-drivers/ppa #添加源
sudo apt-get update
reboot
CTRL+ATL+F1 #进入终端1并用你的用户名和密码登录
sudo service lightdm stop
sudo apt-get install nvidia-390
sudo apt-get update
sudo service lightdm start
reboot
重新用图形界面登录后,terminal输入nvidia-smi验证
3.3 安装cuda
https://developer.nvidia.com/cuda-downloads
cuda的版本一定不能比显卡驱动的版本高,刚才装的显卡版本是390,因此我选择了cuda 9.0 384.81
但是安装CUDA9.0最高支持的版本只到GCC6.0,那么接下来的工作是给GCC降级
sudo apt install gcc-5
sudo apt install g++-5
进入到/usr/bin目录下, 运行一下ls -l gcc*,可以看到gcc是指向gcc-7的
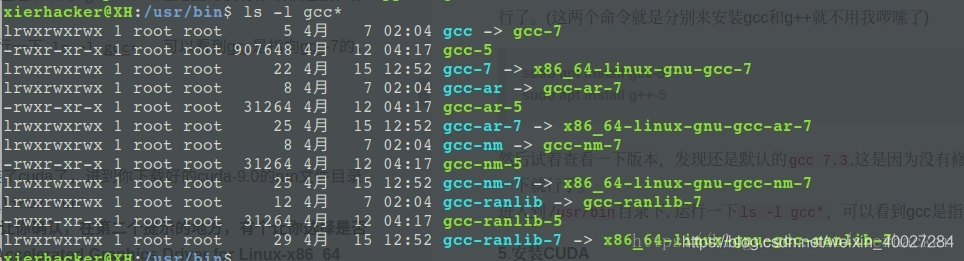
sudo mv gcc gcc.bak #备份
sudo ln -s gcc-5 gcc #重新链接gcc
sudo mv g++ g++.bak #备份
sudo ln -s g++-5 g++ #重新链接g++
降到5.5之后,可以直接来安装了cuda了,进到你下载好的cuda-9.0的run文件目录,运行
sudo sh cuda_9.0.176_384.81_linux.run
执行后会有一些提示让你确认,在第3个提示的地方,有个让你选择是否安装驱动时(Install NVIDIA Accelerated Graphics Driver for Linux-x86_64 384.81?),选择否:因为前面我们已经安装了新的驱动,所以这里不要选择安装。
sudo sh cuda_9.0.176.1_linux.run
sudo sh cuda_9.0.176.2_linux.run
sudo sh cuda_9.0.176.3_linux.run
sudo sh cuda_9.0.176.4_linux.run
编辑.bashrc配置文件
sudo vim ~/.bashrc
文件最后添加
export PATH=/usr/local/cuda-9.0/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda-9.0/lib64:$LD_LIBRARY_PATH #这样在IDE里面就可以链接库了
好了,重启一下
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
sudo make
./deviceQuery
出现了下面的你的GPU的一些信息的话,就是真的安装成功了。
3.4 安装cudnn
https://developer.nvidia.com/rdp/cudnn-download
自己注册一下,之后下载其中的cuDNN v7.1.4 Library for Linux
版本再高的话安装tensorflow会有一些问题,比如pip install tensowflow-gpu无法自动查找合适的tensorflow的版本
下载的时候发现是一个压缩包,下完之后解压
解压出来是一个cuda文件夹,进去有两个文件夹,如下
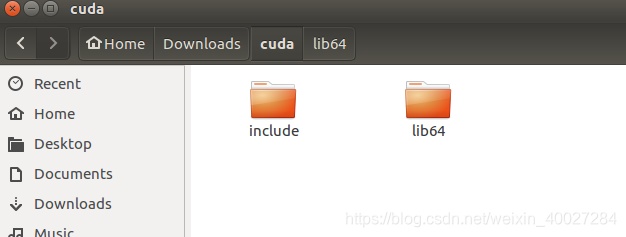
进入include目录,在命令行进行如下操作:
sudo cp cudnn.h /usr/local/cuda/include/
进入lib64目录,在命令行进行如下操作:
sudo cp lib* /usr/local/cuda/lib64/ #复制动态链接库
cd /usr/local/cuda/lib64/
sudo rm -rf libcudnn.so libcudnn.so.7 #删除原有动态文件
sudo ln -s libcudnn.so.7.1.4 libcudnn.so.7 #生成软衔接
sudo ln -s libcudnn.so.7 libcudnn.so #生成软链接
如果你想删除,可以
sudo rm /usr/local/cuda/include/cudnn.h
sudo rm /usr/local/cuda/lib64/libcudnn*
3.5 安装opencv和caffe
Anaconda可以管理不同的python环境,我们很多框架的python代码都是用2.7开发的,tensorflow自带的models框架也是用python2开发的,因此可以创建一个环境
conda create -n tensorflow python=2.7 #删除环境用conda env remove -n tensorflow
source activate tensorflow
pip install --upgrade pip
pip install jupyter #这个时候安装可以保证jupyter用的kernel是python2.7的,所以必须一开始就装
cd ~/
git clone https://github.com/BVLC/caffe.git #下载caffe的源代码
cd caffe/python #利用它对python的prequirements来配置我们的python2.7的环境
for req in $(cat requirements.txt); do pip install $req; done #运行这行命令之前删去txt里面的python-dateutil那一行
pip install pillow
pip install lxml
conda install libgcc
安装labelimg:
git clone https://github.com/tzutalin/labelImg
cd labelImg
conda install pyqt=4
python labelImg.py
在home/你的用户名/下面建立了一个OpenCV的目录(地方其实是任意的)
mkdir ~/OpenCV
cd ~/OpenCV
用https://opencv.org/releases.html下载3.4.2版本的(4.0后面在caffe安装的时候有问题),解压。你就会看见你的工作目录(OpenCV)下面有了opencv-3.4.2文件夹。进入到这个文件夹,这时候建立一个build的文件夹,用来接收cmake之后的文件。
cd opencv-3.4.2
mkdir build
cd build
cmake -D CMAKE_BUILD_TYPE=RELEASE -D BUILD_TIFF=ON -D CMAKE_INSTALL_PREFIX=/usr/local ..
cmake-gui #如果没有安装,需要用sudo apt-get install cmake-qt-gui来安装
确保
Build_opencv_python2=ON
BUILD_ZLIB=ON
BUILD_JPEG=ON
BUILD_TIFF=ON
BUILD_PNG=ON
WITH_PNG=ON
WITH_JPEG=ON
WITH_TIFF=ON
PYTHON2_EXCUTABLE=/home/用户名/anaconda3/envs/tensorflow/bin/python2.7
PYTHON2_INCLUDE_DIR=/home/用户名/anaconda3/envs/tensorflow/include/python2.7
PYTHON2_LIBRARY=/usr/lib/x86_64-linux-gnu/libpython2.7.so
PYTHON2_NUMPY_INCLUDE_DIRS=/home/用户名/anaconda3/envs/tensorflow/lib/python2.7/site-packages/numpy/core/include
如果有修改的话,就按configure ---->generate
cmake能自动解析到合理的路径,你自己弄的话很可能不对
成功的话出现
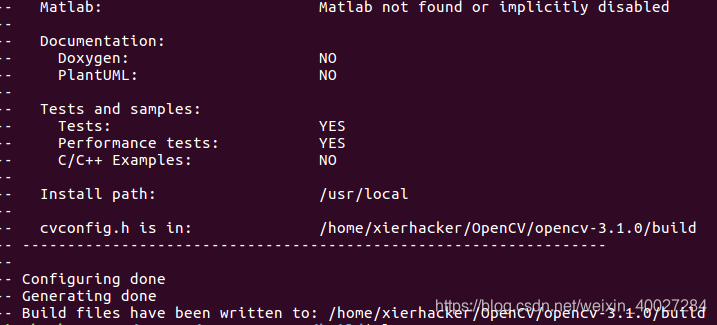
然后终端再输入
make -j12
sudo make install #由于程序会被装在/usr/local下面,因此必须加sudo
最后把build/lib 里面的cv2.so拷贝到/home/用户名/anaconda3/envs/tensorflow/lib/python2.7/site-packages/下面
python打开,import cv2不错就说明好了
下面开始装caffe
cd ~/caffe
mkdir build
cd build
cmake .. #会自动用anaconda的python2.7环境来编译pycaffe
make -j12
make install #caffe默认安装路径为build/install,因此不用sudo
make runtest -j12 #进行测试
最后,为了能让anaconda找到caffe
gedit ~/.bashrc
添加
export PYTHONPATH="/home/你的用户名/caffe/python:$PYTHONPATH"
source ~/.bashrc
python
import caffe
不报错就证明pycaffe安装好了
3.6 安装tensorflow
然后就可以进行tensorflow的安装了。当然如果你不想在python2.7里面装,那么source deactivate tensorflow,tensorflow将在当前的python 3.6环境下安装
如果以前装过就卸载掉
pip uninstall tensorflow-gpu
卸载之后,直接用下面的命令来安装tensorflow,会自动为你选择合适的版本。(-i为使用指定的源,加快速度)
pip install --upgrade tensorflow-gpu -i https://pypi.tuna.tsinghua.edu.cn/simple/
然后就安装好啦,运行下面的代码检验一下
import tensorflow as tf
hello = tf.constant(‘Hello, TensorFlow!’)
sess = tf.Session()
print(sess.run(hello))
sess.close()
