文章目录
Sahu, S. K., et al. (2019). Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network. Proceedings ofthe 57th Annual Meeting ofthe Association for Computational Linguistics: 4309–4316.
abstract
句间关系抽取处理文档中大量复杂的语义关系,需要依赖于局部、非局部、句法和语义。现有的方法不能充分利用这种依赖关系。提出了一种基于文档级图的标记边缘图卷积神经网络的句子间关系抽取模型。图是使用各种句间和句内的依赖关系来捕获局部和非局部依赖关系信息来构造的。为了预测实体对之间的关系,我们使用了双仿射两分的多实例学习方法。实验结果表明,我们的模型在两个生物化学数据集上的性能与最先进的神经模型相当。我们的分析表明,图中的所有类型都可以有效地提取句子间的关系。
- 以前
- 不能充分利用依赖关系
- a novel model for inter-sentence RE using GCNN to capture local and non-local dependencies(本文)
- 句间关系抽取
- 基于文档级图的标记边缘GCNN
- a novel inter-sentence relation extraction model that builds a labelled edge graph convolutional neural network model on a document-level graph
- 认为依赖树无法提取句子间关系
- 构造一个文档级图
- 节点-单词
- 边-局部或非局部依赖关系
- 由什么建立
- 局部依赖的连接词(来自语法解析和序列信息)
- 非局部依赖(来自指代消解+其他语义依赖
- 用GCNN进行编码
- 用MIL进行标签分类
- 如何推断关系
- 得分函数:MIL-based bi-affine pairwise scoring function (Verga et al., 2018)
- 用在实体节点表示上
- 得分函数:MIL-based bi-affine pairwise scoring function (Verga et al., 2018)
1.introduction
命名实体之间的语义关系通常跨越多个句子。为了提取句子间关系,大多数方法使用远程监控来自动生成文档级语料库(Peng et al., 2017;Song et al., 2018)。最近,Verga等(2018)引入了多实例学习(multi-instance learning, MIL) (Riedel等,2010;(Surdeanu et al., 2012)处理文档中多次提到的目标实体。
句子间关系不仅依赖于局部关系,而且依赖于非局部关系。依赖树经常被用来提取语义关系的局部依赖关系(Culotta和Sorensen, 2004;Liu et al., 2015) in intra-sentence relation extraction (RE)。但是,这种依赖关系不适用于句间RE,因为不同的句子有不同的依赖树。图1说明了催产素和低血压之间的关系。为了捕捉它们之间的关系,有必要将催产素和Oxt这两个相互关联的实体联系起来。RNNs和CNNs,常用于句内RE (Zeng et al., 2014;dos Santos等人,2015;周等,2016b;Lin等人(2016)对较长的序列没有效果(Sahu和Anand, 2018),因此未能捕获这种非局部依赖。
我们提出一个新的句子间关系抽取模型,构建一个有标签边的(GCNN)模型(Marcheggiani季托夫、2017)在文档级图。图节点对应单词,边代表本地和外地他们之间的依赖关系。documentlevel图是由连接词与当地依赖从语法解析和顺序信息,以及非本地依赖从指代消解和其他语义依赖(Peng et al ., 2017)建立的。我们推断出实体之间的关系用MIL-based bi-affine成对得分函数(Verga et al ., 2018)在实体节点表示。
-
依赖树(Sunil Kumar Sahu,2019)
- 一个句子一个依赖树
- 无法捕捉非局部依赖
- 不适用于句子间关系抽取
-
句子间关系提取
- 依赖于局部和非局部依赖关系
- 使用远程监控来自动生成文档级语料库(Peng et al., 2017;Song et al., 2018)。
- MIL:Verga等(2018)引入了多实例学习(multi-instance learning, MIL) (Riedel等,2010;(Surdeanu et al., 2012)处理文档中多次提到的目标实体。—关系分类

-
贡献
- 提出了一种利用GCNN捕获局部和非局部依赖关系的句子间转换模型。
- 其次,将该模型应用于两个生物化学语料库,并验证了其有效性。
- 最后,我们从PubMed摘要中开发了一个具有化学反应物-生成物关系的新型远程监控数据集。
2.model
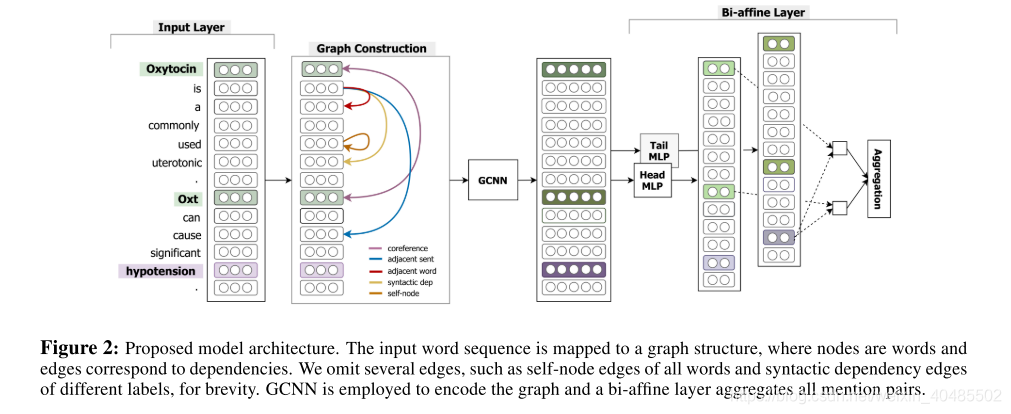
- 我们将句间文档级的RE任务制定为一个分类问题
设[w1, w2,···,wn]为t文档中的单词,e1和e2为t中感兴趣的实体对。关系提取模型以一个三元组(e1、e2、t)作为输入,并返回这一对的关系(包括无关系类别)作为输出。我们假设t中的目标实体之间的关系可以基于它们的所有提及进行推断。因此,我们在t上应用多实例学习来组合所有的mention -level对,并预测目标对的最终关系范畴。
- 关系抽取模型
- 输入:(e1,e2,t)
- 方法:多实例学习来组合所有的mention -level pairwise
- 预测:目标对的最终关系范畴
- 这里的mention:是实体的文字表述,可以有多种。
- t:一个文档
- 模型结构
- 输入:该模型将整个科学文章摘要和两个目标实体和他们所有的mention作为输入。
- 构造图:它构造一个图结构,
- 节点:其中单词作为节点,
- 边:标记了与局部和非局部依赖项相对应的边。
- GCNN编码:接下来,它使用一个堆叠的GCNN层对图结构进行编码,
- MIL分类:并通过应用MIL (多实例学习)(Verga et al., 2018)对所有提及对表示进行分类,从而对目标实体之间的关系进行分类。
2.1输入层
在输入层,我们将每个单词i及其与第一和第二目标实体的相对位置分别映射到实值向量wi、d1 i、d2 i。由于实体可以有多个引用,我们从最近的目标实体引用计算单词的相对位置。对于每个单词i,我们将单词和位置表示连接到输入表示中,
- 每个单词i及其与第一和第二目标实体的相对位置分别映射到实值向量wi、d1i、d2i
- 输入:
2.2构造图
- 多种边
- 句子的句法依赖边
- 共引用边
- 相邻句边
- 相邻词边
- 自节点边
- 为了学习到自身的信息
- 节点表示
- 由其邻居节点和边缘类型来学习节点表示
为了构建整个摘要的文档级图,我们使用以下类别的句间和句内依赖边,如图2中不同颜色所示。
- 句子的句法依赖边缘:句子的句法结构为内部关联提供了有益的线索(Miwa和Bansal, 2016)。因此,我们在每个句子的词之间使用标记的句法依赖边缘,将每个句法依赖标签视为不同的边缘类型。
- 共引用边缘:由于共引用是局部和非局部依赖关系的重要指标(Ma et al., 2016),我们使用共引用类型边缘将文档中的共引用短语连接起来。
- 相邻句边缘:我们将一个句子的句法根与上一个和下一个句子的根用相邻的句式边缘连接起来(Peng et al., 2017),用于相邻句子之间的非局部依赖关系。
- 相邻词边:为了保持句子中单词之间的顺序信息,我们将每个单词与其前一个单词和下一个单词与相邻词类型边缘连接起来。
- 自节点边缘:GCNN只根据它的邻居节点及其边缘类型来学习节点表示。因此,为了将节点信息本身包含到表示中,我们在图的所有节点上形成了selfnode类型的边。
2.3 GCNN层
我们在构建的文档图上使用GCNN (Kipf和Welling, 2017;Defferrard等人,2016)获得每个word的表示。GCNN是CNN用于图形编码的高级版本,它学习了图形节点的语义表示,同时保留了其结构信息。为了学习边缘类型特定的表示,我们使用一个标记的边缘GCNN,它为每个边缘类型保留单独的参数(Vashishth等,2018)。GCNN迭代更新每个输入单词i的表示形式如下:
- 用处:获得x的表示
- 公式
- 由第k个GCNN -block得到的表示。(共K个)
- l:边的类型
- 我们将K个GCNN块堆叠起来,以累积来自遥远邻近节点的信息,并使用边界选通控制来自邻近节点的信息。–最后一个是最终的)
- 减少参数
- 前n个类型保留单独的边的方向参数
- 其余使用相同参数。
- 避免过拟合
与Marcheggiani和Titov(2017)类似,我们为每个边的方向保留单独的参数。但是,我们通过仅为前n个类型保留单独的参数,并为所有剩余的边缘类型使用相同的参数来调整模型参数的数量,这些边缘类型称为“罕见”类型边缘。这可以避免由于不同边缘类型的过参数化而导致的可能的过拟合。
2.4MIL-based Relation Classification
- 由于每个目标实体在一个文档中可以有多个提及,
- MIL:因此我们采用基于多实例学习(multi-instance learning, MIL)的分类方案,
- 得分函数:使用双仿射两两评分来聚合所有目标提及对的预测(Verga et al., 2018)。
- 做法:
- FFNN:首先利用两层前馈神经网络(FFNN)将每个词i投影到两个独立的潜在空间中,对应于目标对的第一个(head)或第二个(tail)参数。
- 2个2层
- 公式
- 双仿射得分:然后,通过双仿射层生成二维水平的两两mention配对置信得分,并将其聚合得到实体水平的两两配对置信得分。
- FFNN:首先利用两层前馈神经网络(FFNN)将每个词i投影到两个独立的潜在空间中,对应于目标对的第一个(head)或第二个(tail)参数。
3.实验设置
我们首先简要地描述数据集,在数据集中,对所提出的模型及其预处理进行评估。然后介绍用于比较的基线模型。最后,我们展示了训练设置。
3.1 数据集
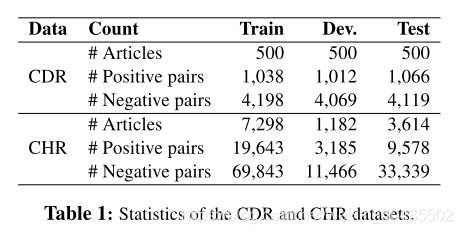
- 化学-疾病关系数据集(CDR):
- CDR数据集是为BioCreative V challenge开发的文档级、句间关系提取数据集(Wei et al., 2015)。
- CHR数据集
- 来自PubMed摘要和题目名
- 数据集由来自PubMed的12094篇摘要及其标题组成。化学品的注释是使用语义分面搜索引擎Thalia的后端执行的。化合物是从注释实体中选择的,并与图形数据库Biochem4j保持一致,Biochem4j是一个免费可用的数据库,集成了UniProt、KEGG和NCBI分类法等多种资源。如果在Biochem4j中识别出两个相关的化学实体,则它们将被视为数据集中的阳性实例,否则将被视为阴性实例。
- 总的来说,语料库包含超过100,000个注释的化学物质和30,000个反应。
- 如果两个化学实体在Biochem4j中有关系,我们认为它们是数据集中的积极实例,否则就是消极实例
3.2 数据预处理
表1显示了CDR和CHR数据集的统计数据。对于这两个数据集,带注释的实体可以有多个关联知识库(KB) ID。如果提及之间至少有一个公共知识库ID,那么我们认为所有这些提及都属于同一个实体。这种方法可以减少负向配对。我们忽略了没有基于已知KB ID的实体,并删除了同一实体之间的关系(自关系)。对于CDR数据集,我们进行了hypernym滤波,类似于Gu等人(2017)和Verga等人(2018)。在CHR数据集中,两个方向都是为每个候选化学对生成的,因为在交互作用中,化学物质既可以是反应物(第一个参数),也可以是产物(第二个参数)。
我们使用GENIA Splitter4和GENIA tagger (Tsuruoka et al., 2005)处理数据集,分别用于句子拆分和单词标记。使用带有谓词-参数结构的Enju语法分析器(Miyao和Tsujii, 2008)获得了句法依赖关系。使用Stanford CoreNLP软件构建指代类型边缘(Manning et al., 2014)。
- 处理数据集
- mention归属哪个实体
- 看对应的是否有相同的KB的id
- 忽略无KB ID的实体,并删除自关系
- 句子拆分:GENIA Splitter
- 句子标记:GENIA tagger (Tsuruoka et al., 2005)
- 句法依赖:使用带有谓词-参数结构的Enju语法分析器(Miyao和Tsujii, 2008)获得了句法依赖关系。
- 指代消解:使用Stanford CoreNLP软件构建Coreference类型边缘(Manning et al., 2014)。
- mention归属哪个实体
3.3 基线模型
- CDR
- 得分函数:bi-affine pairwise scoring to detect relations.
- model
- SVM (Xu et al., 2016b),
- ensemble of feature-based and neural-based models (Zhou et al., 2016a),
- CNN and Maximum Entropy (Gu et al., 2017),
- Piece-wise CNN (Li et al., 2018)
- Transformer (Verga et al., 2018)
- CNN-RE, a re-implementation from Kim (2014) and Zhou et al. (2016a)
- RNN-RE, a reimplementation from Sahu and Anand (2018).
3.4 训练
我们使用在PubMed上培训的100维嵌入式单词(Pennington et al., 2014;TH等人,2015)。与Verga等人(2018)不同的是,我们使用预先训练好的词嵌入来代替子词嵌入来与我们的词图对齐。由于CDR数据集的大小,我们合并了训练和开发集来训练模型,类似于Xu et al. (2016a)和Gu et al.(2017)。我们用不同参数初始化种子的5次运行的平均值来报告性能,包括精度§、回忆®和f1分数。我们使用训练集中边缘类型的频率来选择2.3节中的top-N边。关于培训和超参数设置的细节,请参阅补充资料。
- 100-d embedding(在PubMed上训练的)(Pennington et al., 2014;TH等人,2015)
- 用预训练的词嵌入来代替子词嵌入来与我们的词图对齐。
- dev+train来训练
- 评估:
- 五次不同种子的初始化平均来报告性能
- P,R,F1
- top-N边:用边的类型的频率来选择。
3.5结果
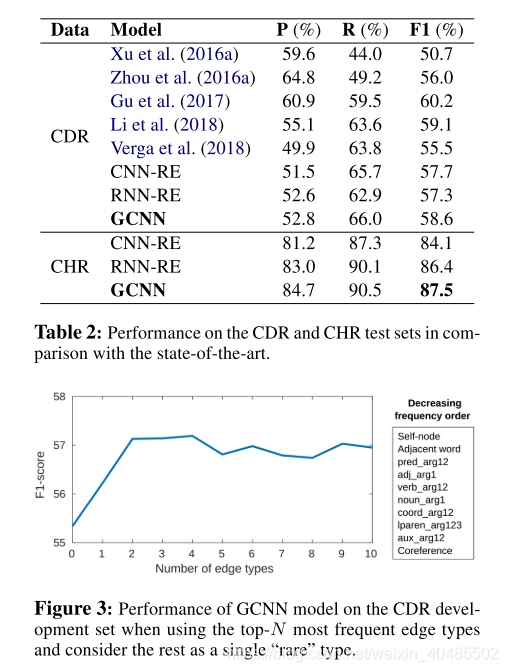
表2显示了我们的CDR和CHR数据集模型的结果。我们报告了最先进的模型的性能,没有任何额外的增强,如与NER的联合训练,模型集成和启发式规则,以避免任何影响的增强,在比较。我们观察到,在两个数据集中,GCNN都优于基线模型(cnn - re /RNN-RE)。然而,在CDR数据集中,GCNN的性能比性能最好的系统(Gu et al., 2017)低1.6个百分点。事实上,Gu等人(2017)将两种独立的神经和基于特征的模型分别用于句内和句间配对,而我们对两对句子都使用单一的模型。此外,GCNN的表现与Li等人(2018)的第二种最先进的神经模型相当,与我们的统一方法不同,该模型需要两个步骤来进行提及聚合。
图3展示了我们的模型在CDR开发集上使用不同数量的最频繁的边缘类型N时的性能。在对N进行调优时,我们发现前四个边缘类型的性能最佳,但随着边缘类型的增加,性能略有下降。我们在其他实验中选择了前4个edge类型。
- top-4最好
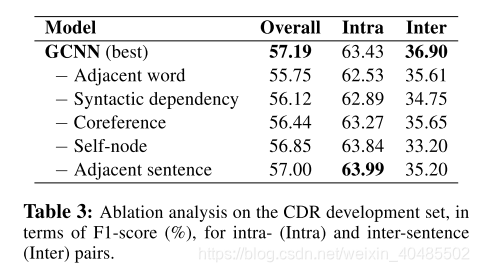
我们对CDR数据集进行消融分析,方法是将开发集分为句内对和句间对(分别约占70%和30%的对)。表3显示了一次删除边缘类别时的性能。总的来说,所有的依赖类型对句间RE和整体性能都有积极的影响,尽管自节点和相邻的句子边缘对句内关系的性能有轻微的损害。此外,共引用不影响句子内对。
4.相关工作
4.1 句子间关系抽取
近期提出的任务
- 句间关系抽取
* Peng et al.(2017)和Song et al.(2018)将基于图的LSTM网络用于n元RE在多个句子中用于蛋白质-药物-疾病关联。他们将关系候选词限制在最多两句话中。
* Verga等人(2018)考虑了文档级RE的多实例学习。
* GCNN(Sahu, S. K., et al. (2019)):
* 我们的工作与Verga等人(2018)不同,我们使用GCNN模型替换Transformer,使用非局部依赖(如实体指代消解)进行全抽象编码。
4.2 GCNN
- GCNN最早由Kipf和Welling(2017)提出,并应用于引文网络和知识图数据集。
- 后来它被用于语义角色标记(Marcheggiani和Titov, 2017)、
- 多文档摘要(Yasunaga等人,2017)和
- 时间关系提取(Vashishth等人,2018)。
- Zhang等人(2018)在插入语RE的依赖树中使用了一个GCNN。
- 与之前的工作不同,我们在文档级图中引入了一个GCNN,在句间RE中包含了句内和句间的依赖关系。
5. 结论
提出了一种新的基于图元的句子间转换方法,该方法使用文档级图的标记边缘GCNN模型。图以单词为节点,它们之间的多个句内和句间依赖关系作为边。采用GCNN模型对图结构进行编码,并引入MIL对多维度对进行聚类。结果表明,该方法在两个生物化学数据集上的性能可与最先进的神经模型相媲美。
我们调整了标记边缘的数量,以保持标记边缘GCNN中的参数数量。分析表明,所有的边缘类型对句子间RE都是有效的。虽然该模型适用于生物化学语料库中的句子间RE,但我们的方法也适用于其他关系提取任务。作为未来的工作,我们计划合并联合命名实体识别培训和子词嵌入,以进一步提高提出的模型的性能。
相关博客
论文笔记 Inter-sentence Relation Extraction with Document-level Graph Convolutional Neural Network
