Yao, Y., et al. (2019). DocRED A Large-Scale Document-Level Relation Extraction Dataset. Proceedings of the 57th Annual Meeting ofthe Association for Computational Linguistics.
基线+docRED数据集
abstract
文档中的多个实体通常表现出复杂的句子间关系,并且不能通过现有的关系提取(RE)方法很好地处理,这些方法通常集中于提取单个实体对的句子内关系。为了加速文档级RE的研究,我们引入了DocRED,这是一个由维基百科和维基数据构建的新数据集,具有三个特征:(1)DocRED注释命名实体和关系,是文档级RE的最大人类注释数据集从纯文本; (2)DocRED要求阅读文档中的多个句子,通过综合文档的所有信息来提取实体并推断它们之间的关系; (3)与人工注释数据一起,我们还提供大规模远程监督数据,使DocRED可用于监督和弱监督情景。为了验证文档级RE的挑战,我们实施了最新的RE最新方法,并对DocRED上的这些方法进行了全面评估。实证结果表明DocRED对现有RE方法具有挑战性,这表明文档级RE仍然是一个开放的问题,需要进一步努力。基于对实验的详细分析,我们讨论了未来研究的多个有希望的方向。
- DocRED
- 用于:大规模文档集句间关系提取
- 来源:wikipedia和wikidata
- 特征:
- 标记实体和关系,文档集最大的人类标注纯文本数据集
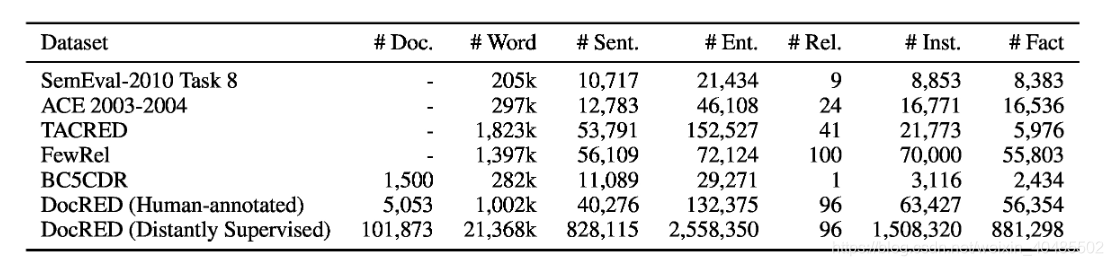
- DocRED包含132,375个实体和56,554个关联事实,这些事实在5,053维基百科文档中注释,使其成为最大的人工注释文档级RE数据集。
- 要求从多个句子中提取实体并推断关系
- 由于DocRED中至少40.7%的关系事实只能从多个句子中提取,DocRED要求阅读文档中的多个句子以识别实体并通过合成文档的所有信息来推断它们之间的关系。这将DocRED与那些句子级RE数据集区分开来。
- 提供大规模远程监督数据,使之可用于监督和弱监督情景
- 标记实体和关系,文档集最大的人类标注纯文本数据集
- 仍是一个开放问题
1.Introduction
- 句子级关系提取
- (Socher et al., 2012;
- Zeng et al., 2014, 2015; .
- dos Santos et al., 2015;
- Xiao and Liu, 2016;
- Cai et al., 2016;
- Lin et al., 2016;
- Wu et al., 2017;
- Qin et al., 2018;
- Han et al., 2018a).
- 有必要从句子级提升到文档级
- 因为许多关系只能从多个句子中提取推理得到
- 需要文档级数据集
- 文档级数据集少
- 非人工标注,噪声大:Quirk and Poon (2017) and Peng et al. (2017)—有个远程监督生成的数据集,没有人类标注,噪声大。
- 特定领域:BC5CDR(Li et al。,2016)是一个人类注释的文档级RE数据集,由1500个PubMed文档组成,这些文档在生物医学的特定领域仅考虑“化学诱导的疾病”关系,使其不适合开发一般 - 文档级RE的目的方法。
- 特定方法:Levy等人。 (2017)通过使用阅读理解方法回答问题从文档中提取关系事实,其中问题从实体关联对转换。由于这个工作中提出的数据集是针对特定方法量身定制的,因此它也不适用于文档级RE的其他潜在方法
- 存在各种问题,所以提出了DocRED
- 实验结果表明,现有方法的性能在DocRED上显着下降,表明任务文档级RE比句级RE更具挑战性,并且仍然是一个开放性问题。
- 文档级数据集少
2.数据收集
(1)为维基百科文档生成远程监督注释。
(2)在文档和指代消解中注释所有命名实体。
(3)将命名实体提及链接到维基数据项。
(4)标签关系及相应的证据。
第二阶段和第四阶段还要:
(1)使用命名实体识别(NER)模型生成命名实体,或者使用远程监督和RE建立关系建议楷模。 (2)手动纠正和补充建议。
(3)审查并进一步修改第二遍的注释结果,以获得更好的准确性和一致性。
3.数据分析
- 推理类型
- (1)大多数关系实例(61.1%)需要进行推理识别,只能通过简单的模式识别提取38.9%的关系实例,这表明推理是文档级RE必不可少的。
- (2)在与推理相关的情况下,多数(26.6%)需要逻辑推理,其中两个实体之间的关系由桥实体间接建立。逻辑推理要求RE系统能够建模多个实体之间的交互。
- (3)显着数量的关系实例(17.6%)需要共参照推理,其中必须首先执行共参考解析以识别富文本中的目标实体。
- (4)相似比例的关系实例(16.6%)必须基于常识推理来识别,其中读者需要将文档中的关系事实与常识结合起来以完成关系识别。
- 总之,DocRED需要丰富的推理技巧来综合文档的所有信息。
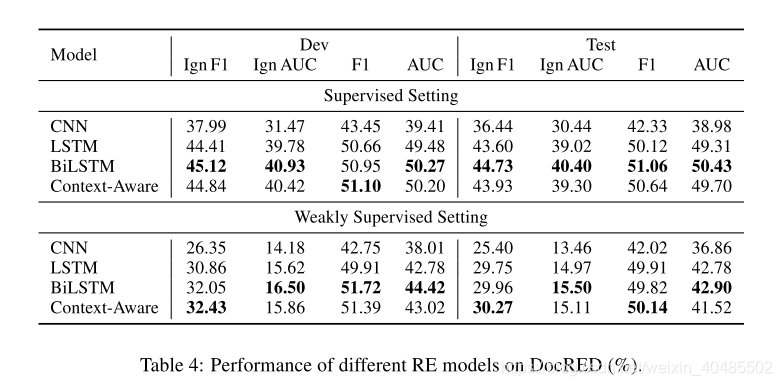
4.基线设置
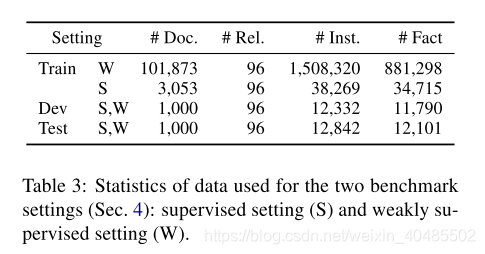
- 实验时设置
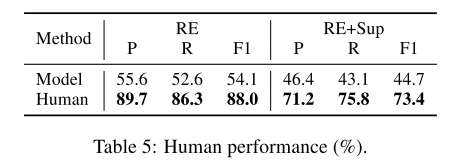
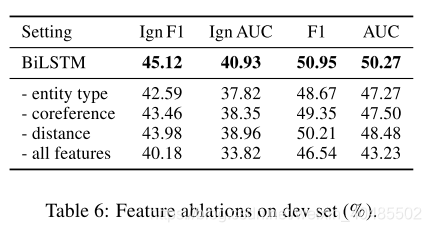
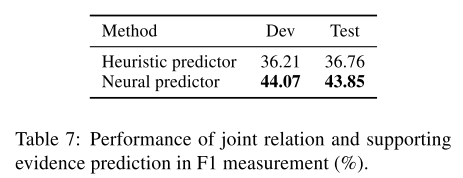
5.实验
- 基线
- CNN (Zeng et al., 2014) based model,
- an LSTM (Hochreiter and Schmidhuber, 1997) based model,
- a bidirectional LSTM (BiLSTM) (Cai et al., 2016) based model and
- the Context-Aware model (Sorokin and Gurevych, 2017) originally designed for leveraging contextual relations to improve intra-sentence RE.
- 过程
- 输入:concate(glove embedding, coference embedding,type embedding)
- 编码器(CNN/LSTM…)编码得到h(隐层表示)
- 一个提及的编码为:
- 实体的编码:
- 分类器:
- 输入:实体和位置编码的
- 输出: