1、进程
进程和程序
进程:正在执行的程序(代码+用到的资源)
程序:没有执行的代码,是一个静态的文件
进程的状态:
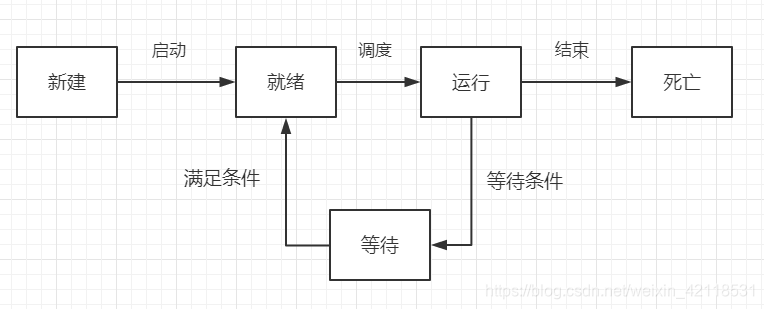
使用进程实现多任务
multiprocessing模块就是跨平台的多进程模块,提供了一个Process类来代表一个进程对象,这个对象可以理解为是一个独立的进程,可以执行另外的事情。
import threading # 线程模块库
import time
import multiprocessing # 进程模块库
def demo():
while True:
print("--1--")
time.sleep(1)
def demo1():
while True:
print("--2--")
time.sleep(1)
def main():
# t1 = threading.Thread(target=demo)
# t2 = threading.Thread(target=demo1)
#
# t1.start() # 线程启动
# t2.start() # 线程
p1 = multiprocessing.Process(target=demo)
p2 = multiprocessing.Process(target=demo1)
p1.start() # 进程启动
p2.start() # 进程启动
if __name__ == '__main__':
main()
图中显示的是一个主进程和两个字进程在任务管理器中的显示

在Ubuntu虚拟机中运行下面的代码,显示父进程和子进程的id
os.fork函数创建进程的过程是这样的。程序每次执行时,操作系统都会创建一个新进程来运行程序指令。进程还可调用os.fork,要求操作系统新建一个进程。父进程是调用os.fork函数的进程。父进程所创建的进程叫子进程。每个进程都有一个不重复的进程ID号。或称pid,它对进程进行标识。子进程与父进程完全相同,子进程从父进程继承了多个值的拷贝,如全局变量和环境变量。两个进程的唯一区别是fork的返回值。子进程接收返回值0,而父进程接收子进程的pid作为返回值。一个现有进程可以调用fork函数创建一个新进程。由fork创建的新进程被称为子进程(child process)。fork函数被调用一次但返回两次。两次返回的唯一区别是子进程中返回0值而父进程中返回子进程ID。 对于程序,只要判断fork的返回值,就知道自己是处于父进程还是子进程中。
参考:os.fork介绍
import os
import time
pid = os.fork() # 创建了子进程,复制了父进程
print("ch")
if pid == 0: # pid为0,说明是子进程
print("son_fork:{}, father_fork:{}".format(os.getpid(), os.getppid())) # os.getpid() :子进程id os.getppid():父进程id
else:
print('father_fork:{}'.format(os.getpid()))
time.sleep(2)
图中说明了:父进程创建了子进程,且子进程直接使用父进程的代码再执行一次。

线程和进程的区别:
线程执行多任务是采用多个不同的线程来完成任务,而进程是复制之前的代码进行执行多任务的,所以线程占用资源相较于进程比较小,进程容易造成资源浪费。
线程和进程之间的对比
先有进程,才有线程
进程:能够完成多任务,一台电脑上可以同时运行多个QQ
线程:能够完成多任务,一个QQ中的多个聊天窗口
根本区别:进程是操作系统资源分配的基本单位,而线程是任务调度和执行的基本单位
进程的CPU占用资源比较大,线程可以看作是轻量级的进程;线程之间的切换,占用资源比较小;同一类线程是共享代码和数据空间的。
2、进程间通信-Queue
Queue-队列:先进先出
栈:先进后出
常用方法介绍:
from multiprocessing import Queue
# 创建队列 参数代表存入队列中的数据数量
q = Queue(3)
# 存数据
q.put(1)
q.put('sda')
q.put([11, 22])
# q.put({"name": "a"}) # 最多存入参数值的数量的数据,超出就会堵塞
# 直接抛出异常 超出数目值
# q.put_nowait({"name": "a"})
# 取数据
print(q.get()) # 队列先进先出
print(q.get())
print(q.get())
# 超出数目值会堵塞
print(q.get())
# 超出数目值会主动抛出异常
print(q.get_nowait())
# 判断队列是否为满的
print(q.full())
# 判断队列是否为空的
print(q.empty())
# 判断队列大小
print(q.qsize())
队列间简单通信
模拟下载数据,与数据处理
import multiprocessing
def download(q):
"""下载数据"""
l = [11, 22, 33]
for item in l:
q.put(item) # 不断将数据存储进队列中
print("下载完成,并且保存到队列中...")
def analysis(q):
"""分析数据"""
analysis_data = list()
while True:
data = q.get() # 一直从队列中提取数据
analysis_data.append(data) # 添加到分析数据的列表中并输出
if q.empty(): # 为空队列时,跳出死循环
break
print(analysis_data)
def main():
# 创建一个队列
q = multiprocessing.Queue() # 在不清楚存储多少数据量的时候,Queue方法中的参数可以不写,就没有数量的限制
t1 = multiprocessing.Process(target=download, args=(q, )) # 传参就不用申明全局变量
t2 = multiprocessing.Process(target=analysis, args=(q, ))
t1.start()
t2.start()
if __name__ == '__main__':
main()
多进程共享全局变量的问题
共享全局变量不适用于多进程编程
多进程间的全局变量是不共享的,多线程是共享的
import multiprocessing
a = 1
def demo1():
global a
a += 1
def demo2():
print(a) # 1 输出为1,说明进程间的全局变量是不共享的,线程是共享的
if __name__ == '__main__':
t1 = multiprocessing.Process(target=demo1)
t2 = multiprocessing.Process(target=demo2)
t1.start()
t2.start()
下面介绍的是:
Queue() 方法只是普通的队列,而multiprocessing.Queue()则是跨进程通信的队列
from queue import Queue
def demo1(q):
q.put('a')
def demo2(q):
data = q.get()
print(data) # a 传参成功
if __name__ == '__main__':
q = Queue() # 这里的Queue() 方法只是普通的队列,而multiprocessing.Queue()则是跨进程通信的队列
t1 = multiprocessing.Process(target=demo1, args=(q, ))
t2 = multiprocessing.Process(target=demo2, args=(q, ))
t1.run() # 注意这里使用的方法,不是start方法,同时这个代码也不是多进程执行的代码,只是普通队列的操作
t2.run() # 没办法完成进程间通信
注意上面代码使用的方法,不是start方法,同时这个代码也不是多进程执行的代码,只是普通队列的操作
3、进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态生成多个进程;
但是如果是上百甚至上千个目标,手动的去创建的进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求,但是如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务。
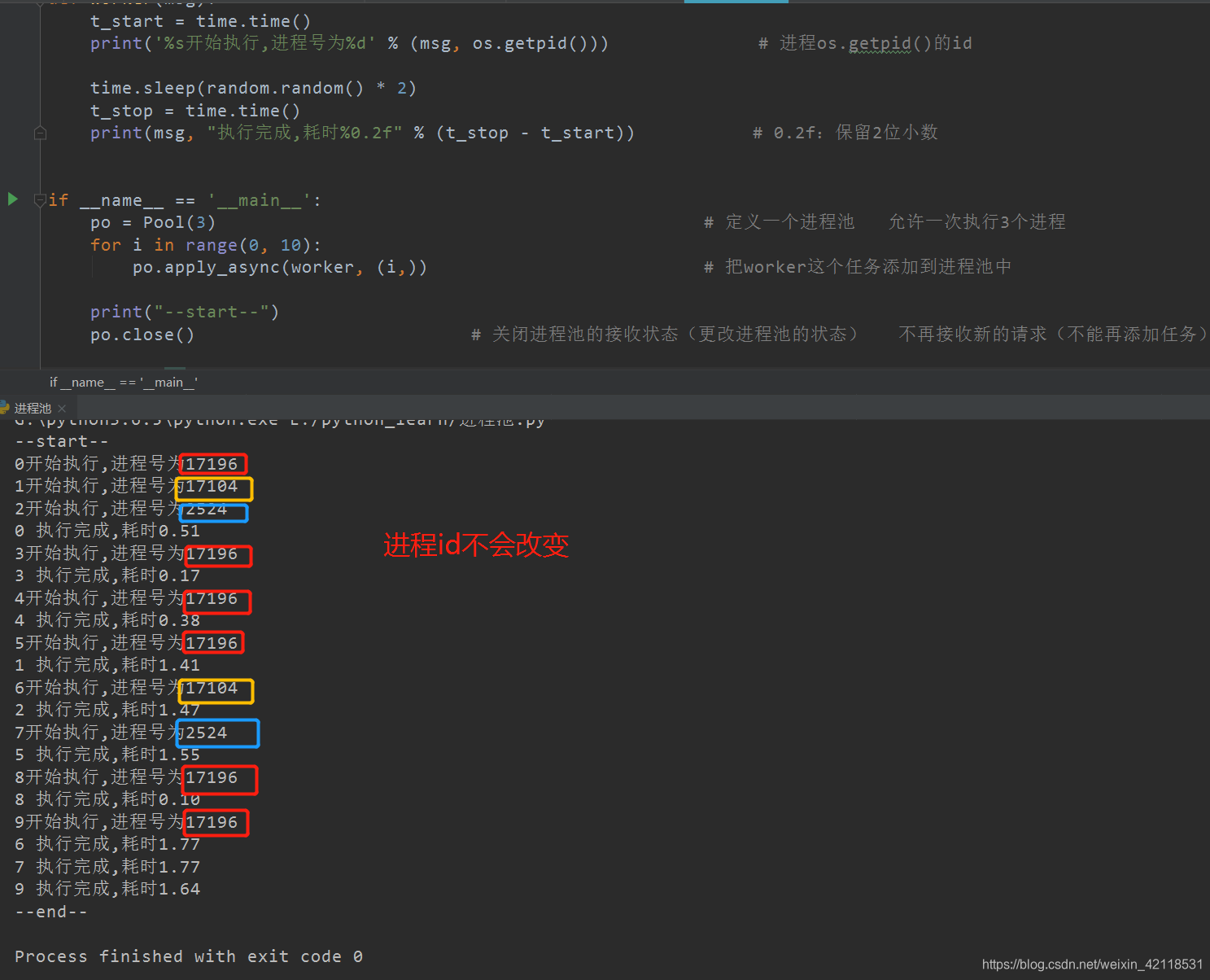
from multiprocessing import Pool
import os, time, random
def worker(msg):
t_start = time.time()
print('%s开始执行,进程号为%d' % (msg, os.getpid())) # 进程os.getpid()的id
time.sleep(random.random() * 2)
t_stop = time.time()
print(msg, "执行完成,耗时%0.2f" % (t_stop - t_start)) # 0.2f:保留2位小数
if __name__ == '__main__':
po = Pool(3) # 定义一个进程池 允许一次执行3个进程
for i in range(0, 10):
po.apply_async(worker, (i,)) # 把worker这个任务添加到进程池中
print("--start--")
po.close() # 关闭进程池的接收状态(更改进程池的状态) 不再接收新的请求(不能再添加任务)
po.join() # 等待子进程执行完成
print("--end--")
4、进程池间的进程通信
进程池中的进程出现异常的时候,代码不会主动抛出异常的,所以需要自己写try方法实现主动抛出异常。
import multiprocessing
def demo1(q):
# 进程池中的进程出现异常的时候,代码不会主动抛出的,所以最好自己写出try方法
1/0 # 这句是异常代码,但是进程池里并不会主动抛出异常,需要添加try方法才能抛出异常
try:
print(1)
q.put('a')
except Exception as e:
print(e)
def demo2(q):
try:
1/0 # 这里可以主动抛出异常:division by zero
print(2)
data = q.get()
print(data)
except Exception as e:
print(e)
if __name__ == '__main__':
# q = Queue() # 不能完成进程间通信
# q = multiprocessing.Queue() # 用这个multiprocessing.Queue()方法不能实现进程池间的通信 # 能实现进程间通信
q = multiprocessing.Manager().Queue() # Manager().Queue()方法能够实现进程池间通信功能
po = multiprocessing.Pool(2)
po.apply_async(demo1, args=(q, ))
po.apply_async(demo2, args=(q, ))
po.close()
po.join()
q = Queue() # 不能完成进程间通信,只能实现普通队列的操作
q = multiprocessing.Queue() # 用这个multiprocessing.Queue()方法不能实现进程池间的通信 # 能实现进程间通信
q = multiprocessing.Manager().Queue() # Manager().Queue()方法能够实现进程池间通信功能
5、多任务文件夹复制案例实现
1 获取用户要copy的文件夹的名字
2 创建一个新的文件夹
3 获取文件夹的所有的待copy的文件名字
4 创建进程池
5 向进程池中添加拷贝任务
import multiprocessing
import time
import os
def copy_file(q, file_name, new_folder_name, old_folder_name):
"""完成拷贝任务"""
print("拷贝的文件名称为:%s" % file_name)
# old_file = open(old_folder_name + "/" + file_name, "rb")
# content = old_file.read()
# old_file.close()
# 打开文件
with open(old_folder_name + "/" + file_name, "rb") as f: # 使用with open实现上面的功能
content = f.read()
# 保存到新的文件夹中
new_file = open(new_folder_name + "/" + file_name, "wb")
new_file.write(content)
new_file.close()
q.put(file_name) # 每次读取一个文件就放入队列中
def main():
# 获取用户要copy的文件夹的名字
old_folder_name = input("请输入要复制的文件夹的名字:")
# 创建一个新的文件夹
new_folder_name = old_folder_name + "副件"
# 判断是否存在
if not os.path.exists(new_folder_name): # 判断文件夹是否已经存在
os.mkdir(new_folder_name) # 创建新的文件夹
# 获取文件夹的所有的待copy的文件名字
file_names = os.listdir(old_folder_name)
# print(file_names) # 返回的是list类型文件
# 创建出进程池 最多5个子进程同时进行
po = multiprocessing.Pool(5)
# 创建一个队列
q = multiprocessing.Manager().Queue()
# 向进程池中添加拷贝任务
for file_name in file_names:
po.apply_async(copy_file, args=(q, file_name, new_folder_name, old_folder_name)) # 注意传参
po.close() # 进程池任务添加功能关闭
# po.join() # 等待子进程完成
# 文件总数
file_count = len(file_names)
# 已经复制过的文件数目
copy_file_num = 0
while True:
file_name = q.get()
copy_file_num += 1
print("\r拷贝文件的进度%2.f%%" % (copy_file_num * 100/file_count), end=' ') # 注意* 100是百分制,2.f%%代表保留2位小数,%%是为了输出一个%
# \r 这个符号是将光标的位置回退到本行的行首,改变进度条显示方式
# 退出循环条件
# if q.empty(): # 这个条件不严谨,当某一时刻进程池中同时完成当前的5个子进程,剩余的子进程任务还没进入执行就会被退出循环
if copy_file_num >= file_count: # 当复制文件数目>= 文件总数
break
if __name__ == '__main__':
main()
