异步流及使用 CUDA C/C++ 对加速应用程序开展可视化分析
CUDA 工具包附带 NVIDIA Visual Profiler(或 nvvp),这是一款用于支持开发 CUDA 加速应用程序的强大 GUI 应用程序。nvvp 会生成加速应用程序的图解时间轴,其中包含有关 CUDA API 调用、核函数执行、内存活动和 CUDA 流使用情况的详细信息。
此外,nvvp 还提供一套分析工具,开发人员可通过运行这些工具接收有关如何有效优化其加速应用程序的明智建议。CUDA 开发人员必须认真学习 nvvp。
在本实验中,您将按照 nvvp 时间轴的指引以优化加速应用程序。此外,您还将学习一些中级 CUDA 编程技术来协助完成相关工作:非托管内存分配和迁移;钉固或页锁定主机内存;以及非默认并发 CUDA 流。
本实验学习课程结束时,我们将为您提供一份评估测试,让您加速和优化一款简单的 n-body 模拟器,这可让您借此展示在本课程学习期间所掌握的技能。若测试者能够在保持正确性的同时加速模拟器,我们将为其颁发证书以资证明。
Prerequisites
如要充分利用本实验,您应已能胜任如下任务:
- 编写、编译及运行既可调用 CPU 函数也可启动 GPU 核函数的 C/C++ 程序。
- 使用执行配置控制并行线程层次结构。
- 重构串行循环以在 GPU 上并行执行其迭代。
- 分配和释放 CUDA 统一内存。
- 理解统一内存在分页错误和数据迁移方面的行为。
- 使用异步内存预取减少分页错误和数据迁移。
Objectives
当您在本实验完成学习后,您将能够:
- 使用 NVIDIA Visual Profiler (nvvp) 对 GPU 加速 CUDA 应用程序的时间轴进行可视化分析。
- 借助 nvvp 识别并利用 GPU 加速 CUDA 应用程序中存在的优化机会。
- 利用 CUDA 流在加速应用程序中并发执行核函数。
-(可选高阶内容)使用手动内存分配(包括分配钉固内存),以便在并发 CUDA 流中异步传输数据。
Setting Up the NVIDIA Visual Profiler
点击 此 nvvp 链接 以在另一个选项卡中打开 nvvp 会话。使用密码 cuda 建立连接,之后即可访问 nvvp。在下一节中,您将开始使用它分析 CUDA 代码。
注意:若学习者使用基于 Windows 的触屏笔记本电脑,则可能会在使用 nvvp 的过程中遇到一些问题。如遇到问题,您可通过使用 [Firefox 网络浏览器] 加以解决。
如果系统要求您使用工作空间,请只接受选定的默认工作空间。此后不久,nvvp 便会自动打开。
无论在实验内何时出现 nvvp 连接超时,您只需点击连接按钮即可重新连接。
Comparing Code Refactors Iteratively with nvvp
以下多个练习将帮助您熟悉与 nvvp 时间轴的交互。您将借助业已学习的技术来分析一系列经过迭代改进的程序。每次分析时,时间轴中的信息都会为您提供支持下一次迭代的相关信息。这将有助您进一步了解各种 CUDA 编程技术会对应用程序性能带来何种影响。

完成本系列练习后,您将利用 nvvp 时间轴来协助学习新的 CUDA 编程技术,其中包括使用并发 CUDA 流以及非托管 CUDA 内存分配和复制技术。
Exercise: Examine Timeline of Compiled CUDA Code
01-vector-add.cu(<--------点击这些源文件链接以在浏览器中编辑)包含一个可运行的加速向量加法应用程序。请使用下方的代码执行单元(可以通过 CTRL 点击执行该代码执行单元和本实验中的任何代码执行单元)进行编译和运行。您应能看到一则打印消息,表明已编译成功。
#include <stdio.h>
void initWith(float num, float *a, int N)
{
for(int i = 0; i < N; ++i)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
!nvcc -arch sm_70 -o vector-add-no-prefetch 01-vector-add/01-vector-add.cu -run成功编译应用程序后,请使用 nvvp 打开已编译的可执行文件并最大化其时间轴窗口,然后执行以下操作:
- 创建将显示
addVectorsInto核函数执行时间的时间轴标尺。 - 确定应用程序时间轴中的何处发生 CPU 分页错误。确定程序中引起这些 CPU 分页错误的位置。
- 在时间轴中找到数据迁移 (DtoH)(设备到主机)事件。这些事件的发生时间几乎与核函数执行后发生 CPU 分页错误的时间相同。这些事件为何会在此时发生,而非在核函数执行前发生 CPU 分页错误期间?
- GPU 分页错误、HtoD 数据迁移事件与
addVectorsInto核函数执行之间在时间轴上有何关系?查看源代码后,您能否明确解释以上事件为何会以这种方式发生?

Exercise: Add Asynchronous Prefetching
01-vector-add-prefetch-solution.cu 可重构上述向量加法应用程序,以便在启动核函数之前将其 addVectorsInto 核函数所需的 3 个向量异步预取到处于活动状态的 GPU 设备(通过使用 cudaMemPrefetchAsync)。打开源代码并确定在应用程序中的何处作出这些更改。
查看更改后,请使用下方的代码执行单元编译和运行重构后的应用程序。您应能看到打印出的成功消息。
Exercise: Compare the Timelines of Prefetching vs. Non-Prefetching
01-vector-add-prefetch-solution.cu 可重构上述向量加法应用程序,以便在启动核函数之前将其 addVectorsInto 核函数所需的 3 个向量异步预取到处于活动状态的 GPU 设备(通过使用 cudaMemPrefetchAsync)。打开源代码并确定在应用程序中的何处作出这些更改。
查看更改后,请使用下方的代码执行单元编译和运行重构后的应用程序。您应能看到打印出的成功消息。
#include <stdio.h>
void initWith(float num, float *a, int N)
{
for(int i = 0; i < N; ++i)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
initWith(3, a, N);
initWith(4, b, N);
initWith(0, c, N);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
!nvcc -arch sm_70 -o vector-add-prefetch 01-vector-add/solutions/01-vector-add-prefetch-solution.cu -run使用 nvvp打开经编译的可执行文件,并在执行预取之前使先前的会话和向量加法应用程序保持开启状态。最大化时间轴窗口,然后执行以下操作:
- 创建将显示
addVectorsInto核函数执行时间的时间轴标尺。在添加异步预取之前,如何将执行时间与addVectorsInto核函数的执行时间进行比较? - 在时间轴的运行时 API 部分中找到
cudaMemPrefetchAsync。 - 请在重构前参考应用程序的时间轴,您将可在时间轴的统一内存部分中看到:由于对统一内存的需求增加,核函数执行期间已发生多组 GPU 分页错误。在执行预取之后,这些分页错误是否依然存在?
- 即使 GPU 分页错误消失,我们仍需将数据从主机迁移到设备。使用时间轴的数据迁移 (HtoD) 部分比较这两个应用程序之间的这些迁移。比较它们的数量、执行所需的时间及其相对
addVectorsInto核函数执行的发生时间。 - 查看这 2 个应用程序的整体运行时,该如何对它们进行比较?

Exercise: Profile Refactor with Launch Init in Kernel
在向量加法应用程序的上一次迭代中,向量数据正在 CPU 上进行初始化,因此在 addVectorsInto 核函数可以对该数据执行操作之前需要将其迁移到 GPU。
在应用程序 01-init-kernel-solution.cu 的下一次迭代中,我们已将应用程序重构为在 GPU 上并行初始化数据。
由于初始化目前在 GPU 上进行,因此预取操作已在初始化之前完成,而非在执行向量加法操作之前。查看源代码以确定作出这些更改的位置。
查看更改后,请使用下方的代码执行单元编译和运行重构后的应用程序。您应能看到打印出的成功消息。
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
!nvcc -arch=sm_70 -o init-kernel 02-init-kernel/solutions/01-init-kernel-solution.cu -run在 nvvp 的另一个会话中打开经编译的可执行文件,然后执行以下操作:
- 创建时间轴标尺以衡量应用程序的整体运行时、
addVectorsInto核函数的运行时以及初始化核函数的运行时。将应用程序和addVectorsInto的运行时与应用程序的先前版本进行比较,看看有何变化? - 查看时间轴的计算部分。在
addVectorsInto和初始化核函数这两个核函数中,哪一个在 GPU 上占用了大部分时间? - 您的应用程序包含以下哪几项?
- CPU 分页错误
- GPU 分页错误
- 数据迁移 (HtoD)
- 数据迁移 (DtoH)

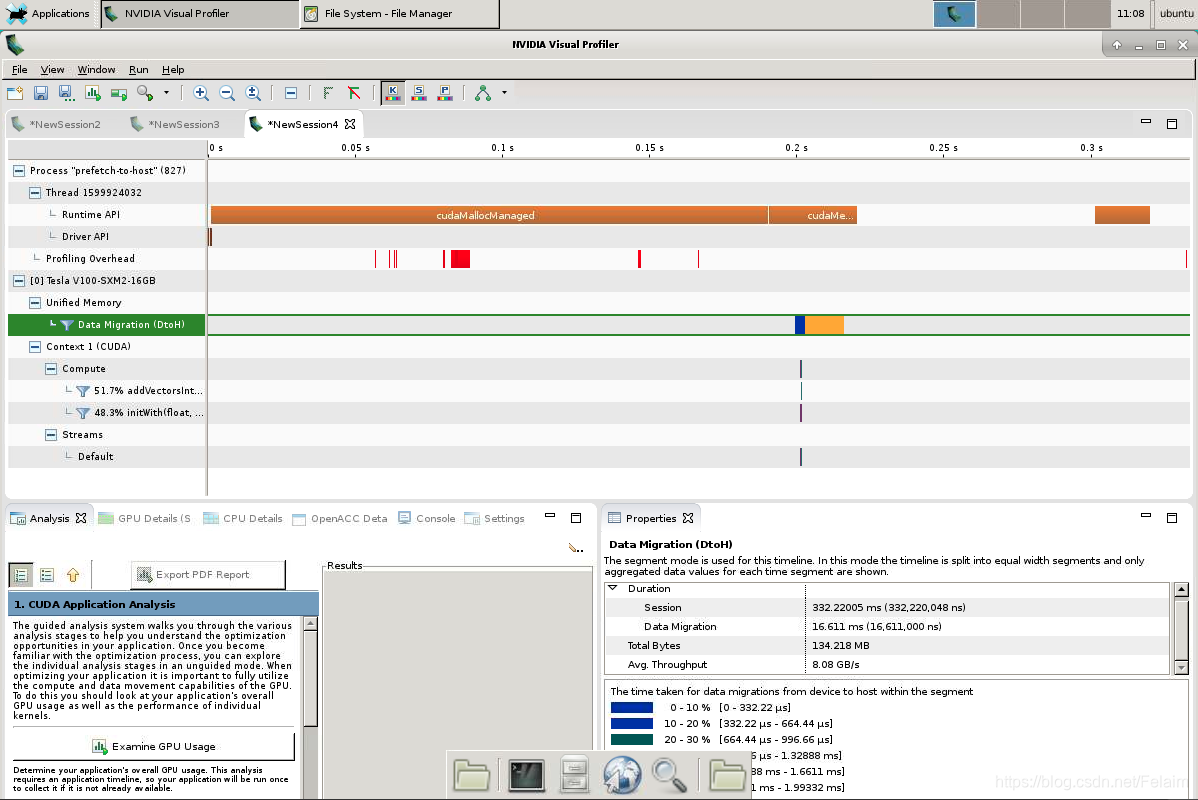
Exercise: Profile Refactor with Asynchronous Prefetch Back to the Host
目前,向量加法应用程序可以在主机上验证向量加法核函数的结果。在应用程序 01-prefetch-check-solution.cu 的下一次重构中,我们会将数据异步预取回主机以进行验证。
查看更改后,请使用下方的代码执行单元编译和运行重构后的应用程序。您应能看到打印出的成功消息。
!nvcc -arch=sm_70 -o prefetch-to-host 04-prefetch-check/solutions/01-prefetch-check-solution.cu -run#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
const int N = 2<<24;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 256;
numberOfBlocks = 32 * numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
initWith<<<numberOfBlocks, threadsPerBlock>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
checkElementsAre(7, c, N);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
在 nvvp 中打开新编译的可执行文件,最大化时间轴并执行以下操作:
- 关于添加预取回 CPU 之前和之后的数据迁移 (DtoH) 事件,请使用时间轴的统一内存部分比较其异同点。
- 如何比较 CPU 分页错误的数量?
- 如何比较 DtoH 迁移所需的总时间?
- 请查看时间轴的流部分以继续学习下一节。请注意,所有核函数均在默认流中执行,并且核函数是在默认流中顺次执行。我们将在下一节伊始介绍流的内容。
Concurrent CUDA Streams
以下幻灯片将直观呈现即将发布的材料的概要信息。点击浏览一遍这些幻灯片,然后再继续深入了解以下章节中的主题。
%%HTML
<div align="center"><iframe src="https://view.officeapps.live.com/op/view.aspx?src=https://developer.download.nvidia.com/training/courses/C-AC-01-V1/AC_STREAMS_NVVP-zh/NVVP-Streams-1-zh.pptx" frameborder="0" width="900" height="550" allowfullscreen="true" mozallowfullscreen="true" webkitallowfullscreen="true"></iframe></div>流是指一系列指定且CUDA具有默认流,默认情况下,CUDA核函数会在默认流中运行,在任何流(包括默认流)中,其所含指令(此处为核函数启动)必须在下一个流开始之前完成,我们还可以创建非默认流,以便核函数执行,任一流中的核函数均须按顺序执行,不过不同的非默认流中的核函数则可同时交互。默认流比较特殊,它会阻止其他流中的所有核函数
在 CUDA 编程中,流是按顺序执行的一系列命令。在 CUDA 应用程序中,核函数执行和一些内存传输均在 CUDA 流中进行。直至此时,您仍未正式使用 CUDA 流;但正如上次练习中 nvvp 时间轴所示,您的 CUDA 代码已在名为默认流的流中执行其核函数。
除默认流以外,CUDA 程序员还可创建并使用非默认 CUDA 流,此举可支持执行多个操作,例如在不同的流中并发执行多个核函数。多流的使用可以为您的加速应用程序带来另外一个层次的并行,并能提供更多应用程序优化机会。
Rules Governing the Behavior of CUDA Streams
为有效利用 CUDA 流,您应了解有关 CUDA 流行为的以下几项规则:
- 给定流中的操作会按序执行。
- 就不同非默认流中的操作而言,无法保证其会按彼此之间的任何特定顺序执行。
- 默认流会受到阻碍,并在其他所有流完成之后方可运行,但其亦会阻碍其他流的运行直至其自身已运行完毕。
Creating, Utilizing, and Destroying Non-Default CUDA Streams
以下代码片段演示了如何创建、利用和销毁非默认 CUDA 流。请注意:如要在非默认 CUDA 流中启动 CUDA 核函数,必须将流作为执行配置的第 4 个可选参数进行传递。目前为止,您只使用了执行配置的前 2 个参数:
cudaStream_t stream; // CUDA streams are of type `cudaStream_t`.
cudaStreamCreate(&stream); // Note that a pointer must be passed to `cudaCreateStream`.
someKernel<<<number_of_blocks, threads_per_block, 0, stream>>>(); // `stream` is passed as 4th EC argument.
cudaStreamDestroy(stream); // Note that a value, not a pointer, is passed to `cudaDestroyStream`.执行配置的第 3 个可选参数虽已超出本实验的学习范围,但仍值得一提。此参数允许程序员提供共享内存(目前不会涉及的高阶主题)的字节数,以便在此核函数启动时按块进行动态分配。按块分配给共享内存的默认字节数为 0,在本实验的余下练习中,您会将 0 作为此值进行传递以揭示极为重要的第 4 个参数:
Exercise: Predict Default Stream Behavior
01-print-numbers 应用程序带有一个非常简单的 printNumber 核函数,可用于接受及打印整数。仅在单个线程块内使用单线程执行该核函数,但使用“for 循环”可执行 5 次,并且每次启动时都会传递“for 循环”的迭代次数。
使用下方的代码执行线程块编译和运行 01-print-numbers应用程序。您应能看到打印的数字 0 至 4。
#include <stdio.h>
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
printNumber<<<1, 1>>>(i);
}
cudaDeviceSynchronize();
}
!nvcc -arch=sm_70 -o print-numbers 05-stream-intro/01-print-numbers.cu -run
既已了解核函数在默认情况下会在默认流中执行,那么据您预计,print-numbers 程序的 5 次启动将会顺次执行还是会并行执行?您应能提及默认流的两个功能来支持您的回答。在 nvvp 的新会话中打开可执行文件并最大化时间轴,然后在核函数启动时进行放大以确认答案。

Exercise: Implement Concurrent CUDA Streams
由于核函数的所有 5 次启动均在同一个流中发生,因此看到 5 个核函数顺次执行也就不足为奇。此外,也可以这么说,由于默认流受到阻碍,所以核函数的每次启动都会在完成之后才启动下一次,而事实也是如此。
重构 01-print-numbers 应用程序,以便核函数的每次启动都在自身非默认流中进行。若已不再需要所创建的流,请务必予以销毁。请使用下方的代码执行单元编译和运行经重构的代码。您应仍能看到打印的数字 0 至 4,不过这些数字不一定会按升序排列。
#include <stdio.h>
__global__ void printNumber(int number)
{
printf("%d\n", number);
}
int main()
{
for (int i = 0; i < 5; ++i)
{
cudaStream_t stream;
cudaStreamCreate(&stream);
printNumber<<<1, 1, 0, stream>>>(i);
cudaStreamDestroy(stream);
}
cudaDeviceSynchronize();
}
!nvcc -arch=sm_70 -o print-numbers-in-streams 05-stream-intro/01-print-numbers.cu -run
您既已为核函数的 5 次启动使用 5 个不同的非默认流,您预计它们会顺次执行还是会并行执行?除目前对流的了解之外,您还需考虑 printNumber 核函数的简单程度,也就是说,即使您预测并行运行,核函数的完成速度是否仍会允许完全重叠?
做出假设后,请使用重构程序的可执行文件打开新的 nvvp 会话并最大化时间轴,然后放大核函数执行以查看其实际行为。

Exercise: Use Streams for Concurrent Data Initialization Kernels
您一直使用的向量加法应用程序 01-prefetch-check-solution.cu目前启动 3 次初始化核函数,即:为 vectorAdd 核函数需要初始化的 3 个向量分别启动一次。重构该应用程序,以便在其各自的非默认流中启动全部 3 个初始化核函数。在使用下方的代码执行单元编译及运行时,您应仍能看到打印的成功消息。
#include <stdio.h>
__global__
void initWith(float num, float *a, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
a[i] = num;
}
}
__global__
void addVectorsInto(float *result, float *a, float *b, int N)
{
int index = threadIdx.x + blockIdx.x * blockDim.x;
int stride = blockDim.x * gridDim.x;
for(int i = index; i < N; i += stride)
{
result[i] = a[i] + b[i];
}
}
void checkElementsAre(float target, float *vector, int N)
{
for(int i = 0; i < N; i++)
{
if(vector[i] != target)
{
printf("FAIL: vector[%d] - %0.0f does not equal %0.0f\n", i, vector[i], target);
exit(1);
}
}
printf("Success! All values calculated correctly.\n");
}
int main()
{
int deviceId;
int numberOfSMs;
cudaGetDevice(&deviceId);
cudaDeviceGetAttribute(&numberOfSMs, cudaDevAttrMultiProcessorCount, deviceId);
printf("Device ID: %d\tNumber of SMs: %d\n", deviceId, numberOfSMs);
const int N = 2<<12;
size_t size = N * sizeof(float);
float *a;
float *b;
float *c;
cudaMallocManaged(&a, size);
cudaMallocManaged(&b, size);
cudaMallocManaged(&c, size);
cudaMemPrefetchAsync(a, size, deviceId);
cudaMemPrefetchAsync(b, size, deviceId);
cudaMemPrefetchAsync(c, size, deviceId);
size_t threadsPerBlock;
size_t numberOfBlocks;
threadsPerBlock = 32;
numberOfBlocks = numberOfSMs;
cudaError_t addVectorsErr;
cudaError_t asyncErr;
cudaStream_t stream_a,stream_b,stream_c;
cudaStreamCreate(&stream_a);
cudaStreamCreate(&stream_b);
cudaStreamCreate(&stream_c);
initWith<<<numberOfBlocks, threadsPerBlock, 0 , stream_a>>>(3, a, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0 , stream_b>>>(4, b, N);
initWith<<<numberOfBlocks, threadsPerBlock, 0 , stream_a>>>(0, c, N);
addVectorsInto<<<numberOfBlocks, threadsPerBlock>>>(c, a, b, N);
addVectorsErr = cudaGetLastError();
if(addVectorsErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(addVectorsErr));
asyncErr = cudaDeviceSynchronize();
if(asyncErr != cudaSuccess) printf("Error: %s\n", cudaGetErrorString(asyncErr));
cudaMemPrefetchAsync(c, size, cudaCpuDeviceId);
checkElementsAre(7, c, N);
cudaStreamDestroy(stream_a);
cudaStreamDestroy(stream_b);
cudaStreamDestroy(stream_c);
cudaFree(a);
cudaFree(b);
cudaFree(c);
}
!nvcc -arch=sm_70 -o init-in-streams 04-prefetch-check/solutions/01-prefetch-check-solution.cu -run在 nvvp 中打开经编译的二进制文件并最大化时间轴,然后确认初始化核函数的 3 次启动均在其各自的非默认流中运行,并且具有一定程度的并发重叠。
网速真的太渣了。。。NVIDIA官网真的对国内网络不是很友好,/(ㄒoㄒ)/~~

Summary
此时,您在实验中能够执行以下操作:
- 使用 NVIDIA Visual Profiler (nvvp) 对 GPU 加速 CUDA 应用程序的时间轴进行可视化分析。
- 借助 nvvp 识别并利用 GPU 加速 CUDA 应用程序中存在的优化机会。
- 利用 CUDA 流在加速应用程序中并发执行核函数。
现在,您已经掌握大量基本工具和技术,可用来加速 CPU 应用程序,并能进一步对这些加速应用程序进行优化。在最后的练习中,您将有机会运用所学的全部知识加速 n-body 模拟器,以预测通过引力相互作用的一组物体的个体运动。
Final Exercise: Accelerate and Optimize an N-Body Simulator
n-body 模拟器可以预测通过引力相互作用的一组物体的个体运动。[01-nbody.cu] 包含一个简单而有效的 n-body 模拟器,适合用于在三维空间移动的物体。我们可通过向该应用程序传递一个命令行参数以影响系统中的物体数量。
该应用程序现有的 CPU 版能够处理 4096 个物体,在计算系统中物体间的交互次数时,每秒约达 3000 万次。您的任务是:
- 利用 GPU 加速程序,并保持模拟的正确性
- 以迭代方式优化模拟器,以使其每秒计算的交互次数超过 300 亿,同时还能处理 4096 个物体
(2<<11) - 以迭代方式优化模拟器,以使其每秒计算的交互次数超过 3250 亿,同时还能处理约 65000 个物体
(2<<15)
完成此任务后,请返回先前用于打开此笔记本的浏览器页面,然后单击“Assess”(评估)按钮。如果您已成功保持应用程序模拟的准确性,并已按照上述要求为其实现加速,则将获得_基础课程之使用 CUDA C/C++ 加速应用程序_的资质证书。
Considerations to Guide Your Work
在开始任务之前,请注意以下事项:
- 在第一次重构中,请格外注意应用程序的逻辑部分(尤其是
bodyForce函数)能够并且应该基本保持不变:要侧重于尽可能轻松地加速应用程序。 - 由于
randomizeBodies函数采用rand函数,而rand函数在 GPU 设备上不可用,因此您无法对其加速。randomizeBodies是主机函数。请勿使用该函数。 - 代码库包含
main函数内的“for 循环”,用于将bodyForce函数计算的物体间力集成到系统中物体的所在位置。该集成需在bodyForce函数运行后进行,并且需在下一次调用bodyForce函数之前完成。在选择并行化的方式和位置时,请牢记这一点。 - 使用分析驱动和迭代的方法。
- 无需为代码添加错误处理,但其可能有助您确保代码的顺利运行。
快去开心地执行任务吧!
!nvcc -arch=sm_70 -o nbody 09-nbody/01-nbody.cu!./nbody 11 # This argument is passed as `N` in the formula `2<<N`, to determine the number of bodies in the system!nvprof ./nbody这个出于对课程的尊重,就不把课程测试放到博客中了!
