这篇文章的主要工作
1) 首先,我们提出MV-GAN作为一种新的深度学习框架来产生珍珠的多视图图像。特别是,这里我们将每个珍珠的多视图图像按上、左、右、主视图和稀有视图的顺序叠加到图像通道维度中,形成多视图输入数据。
2) 其次,MV-GAN框架结合了DCGAN的网络结构和CGAN的标签训练方式。因此,鉴别器有四个卷积层,发生器有四个反卷积层。同时,珍珠标签被用来限制每一层的训练和生成图像的自由度。然后,利用珍珠的多视图图像对MV-GAN进行训练,利用训练后的MV-GAN生成多视图图像,扩展训练集。
3) 第三,利用扩展后的数据集对MS-CNN进行再训练。实验证明,MS-CNN确实可以进一步改进,特别是在原始训练集相对较小的情况下。此外,MV-GAN还可以帮助MS-CNN抵抗环境带来的干扰,如亮度干扰。这些结果表明,我们的MV-GAN框架在提高珍珠分类精度和稳健性方面具有潜在的应用前景。
4) 第四,MV-GAN可以用来生成各种物体的多视图图像。因此,它有可能应用于许多其他三维(3-D)物体分类[20]-[23]
METHOD
这篇文章使用与DCGAN[18]相同的网络结构,并使用与CGAN[19]相同的策略来限制训练和生成过程。
在不假设数据分布的情况下,GAN直接从给定的数据集中抽取样本,然后逼近其分布。然而,这可能导致产生的数据的相当大的潜在空间,使得GAN不太可靠。此外,作为一种无监督的学习方法,GAN只能生成与给定分布相似的数据,而不能生成具有特定标签的数据。因此,传统的GAN不能满足我们对珍珠图像进行标签扩展以完成分类任务的要求。
在MV-GAN体系结构中使用了来自[18]的以下指导原则:首先,将所有隐藏层设置为卷积层,并且消除人工设置的池化层[18],以便网络能够学习其自己的上采样(对于生成器)和下采样(对于鉴别器)操作符;其次,完全连接的层去除以加快收敛速度[18];第三,使用一些技巧,即ReLU激活[52]用于生成器的每个隐藏层,LeakyReLU用于鉴别器的每个隐藏层,批处理规范化[53]用于生成器和鉴别器。
如CGAN[19]中所讨论的,如果生成器和鉴别器都受某些额外信息y的约束,则GAN可以扩展到条件模型。这里,y可以是任何类型的辅助信息,例如类标签或来自其他模式的数据。我们可以简单地将条件输入和先验噪声作为输入引入到多层感知器的单个隐藏层中,这在CGAN中通过了混合国家标准技术研究所(MNIST)数据集的验证【19】。或者,也可以使用更复杂的生成机制的高阶交互。
对于所提出的MV-GAN方法,在CGAN[19]的启发下,将类别标签y作为条件信息添加到输入中。对于生成器,条件信息y和输入噪声pz(z)形成一个联合的隐藏层表示,这可以看作是对势维数的一些限制,即对MVGAN的随机生成施加限制。
同样,对于鉴别器,类别标签也与输入图像相结合。这样的条件信息被添加到神经网络的每个隐藏层以增强约束,如图2所示。生成器输入层的类别标签是一个热编码的。按顺序,在每个隐藏图层输出要素地图后,将添加相同的类别标签作为其中的一部分。此外,与一个one-hot类似,表示正确类别的特征映射层被设置为一,而所有其他的被设置为零,如图3所示。鉴频器采用相同的编码方法,由于类别标签的限制,鉴频器的任务是在一定的类别下区分假图像和真图像。
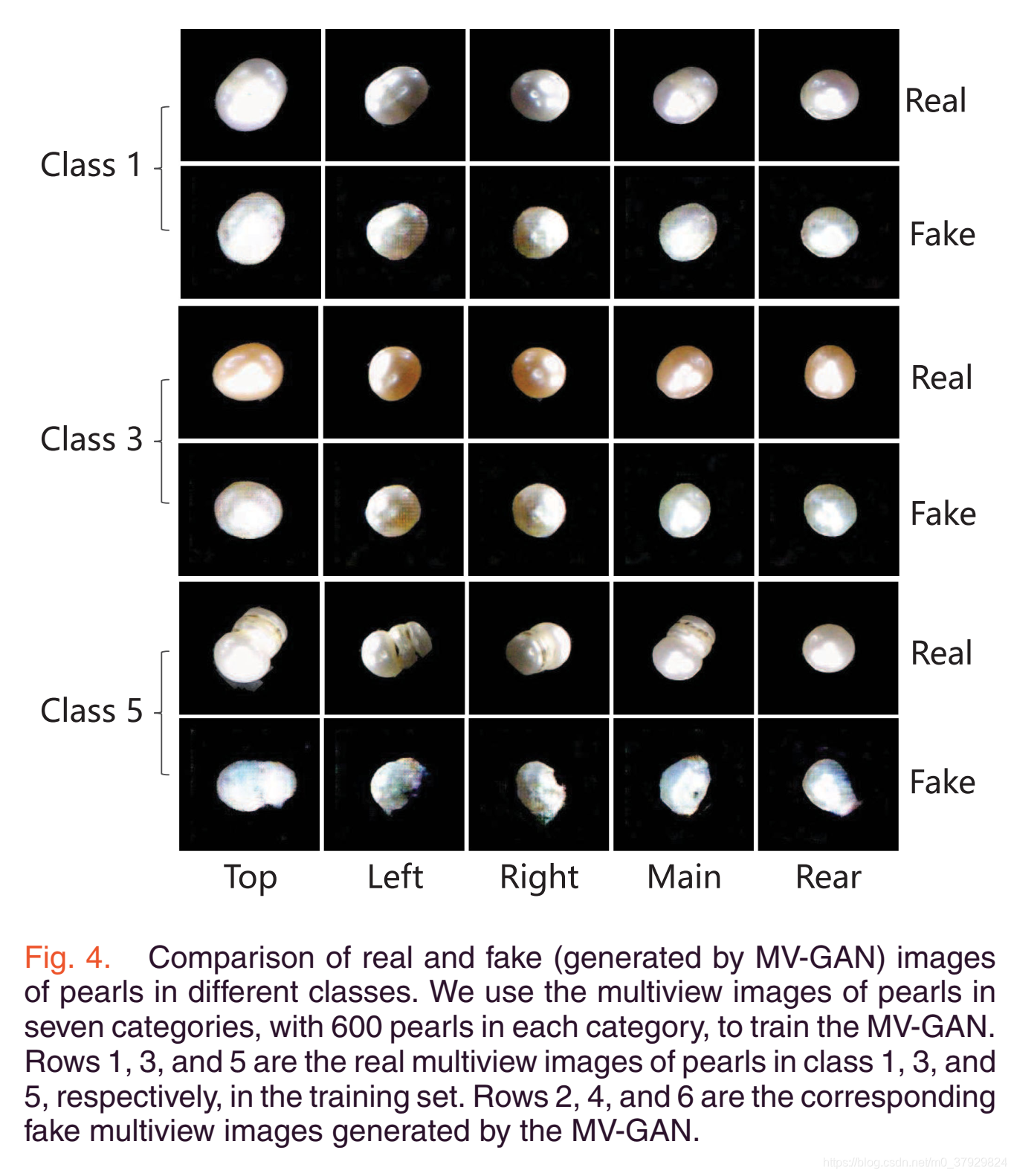

Experiments
将生成的图片与真实图片混合,形成最终数据集进行训练,总计进行三个实验。
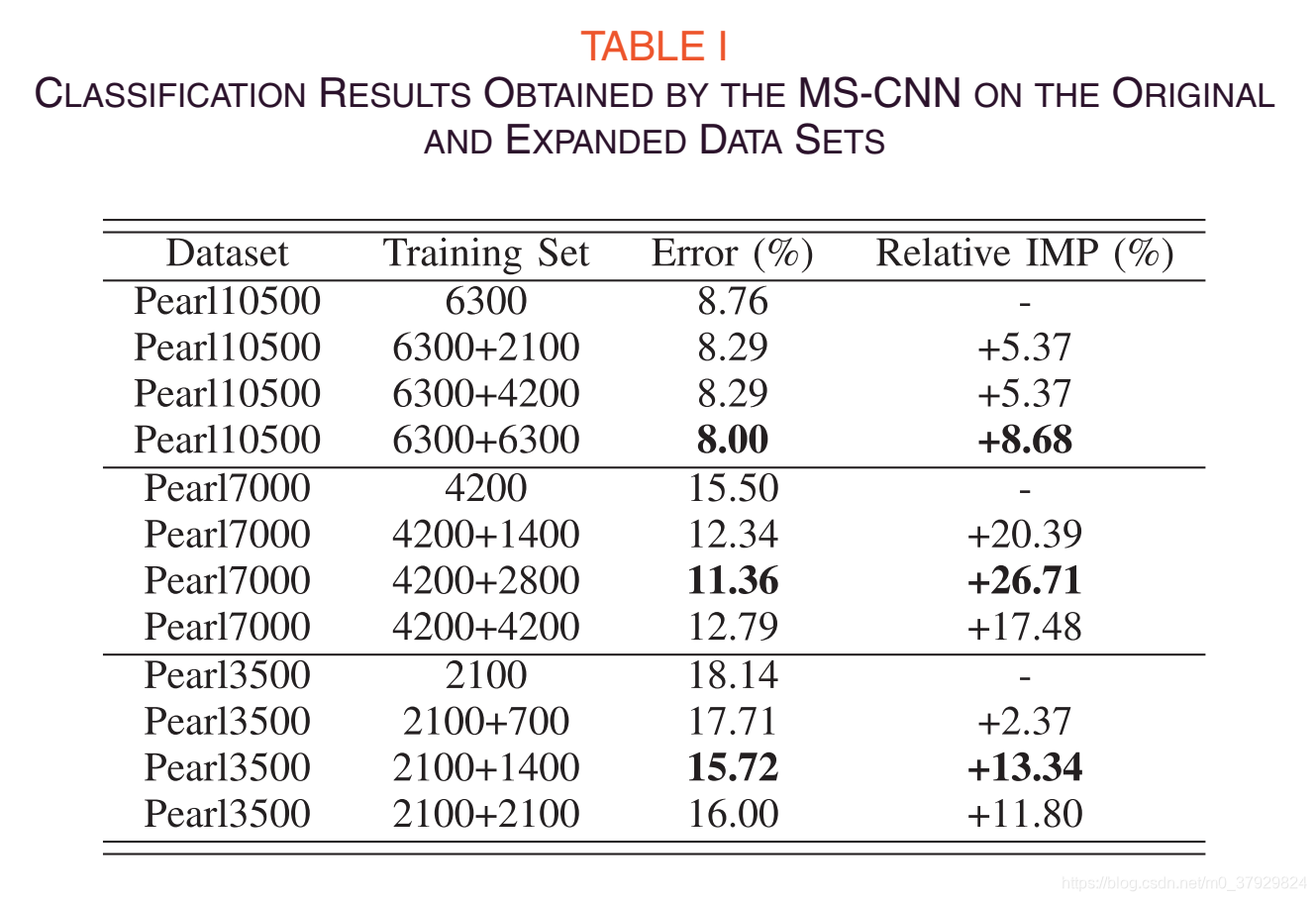
首先,为了研究数据量对MV-GAN模型的影响,我们使用了三个集合,每个类别分别包含1500、1000和500颗珍珠。因此,该方法在三个不同大小的珍珠图像数据集上实现,分别包含10500、7000和3500个珍珠,即Pearl10500、Pearl7000和Pearl3500。其次,分别使用五个单视图,在更多的CNN结构上进一步研究了MV-GAN的产生数据。第三,研究了不同光照条件下珍珠图像的场景,探讨了环境对珍珠图像的影响MV-GAN的性能。
这样的结果可以解释如下。当数据集足够大时,MS-CNN本身可以达到相当高的分类精度。因此,即使对MV-GAN进行了良好的训练,使得生成的多视图珍珠图像具有高质量,进一步改进的可能性也相对较低。另一方面,当数据集太小时,MV-GAN可能没有经过良好的训练,从而产生较差的多视点珍珠图像,这在一定程度上会损害分类模型。一些可怜的多视角珍珠图像
由MV-GAN使用Pearl3500数据集产生的如图5所示,在其他两个数据集上出现的较少。可以看到,这些图像看起来非常粗糙,与真实的珍珠图像有很大的不同。
当数据集稍有不足时,MS-CNN本身可能无法产生满意的分类结果。MV-GAN生成的多视图珍珠图像在这种情况下可以起到正则化的作用,即它倾向于对与原始训练集中的真实图像相同但在某些特征上有所不同的图像进行采样,这样可以防止过采样,从而提高MS-CNN的性能。

1) 首先,不同的视图可以提供不同的信息量,从而导致不同的分类性能,即我们发现,无论是否使用MV-GAN,CNN模型在使用左视图和右视图的珍珠图像时表现得更好。
2) 其次,与多视图图像相比,单视图图像在区分不同种类珍珠方面提供的信息要少得多,即我们发现,无论是否使用MV-GAN,AlexNet在使用多视图珍珠图像时的性能都比使用单视图珍珠图像时好得多。这一结果与文献[8]一致,表明了MS-CNN的优越性。
3) 第三,根据网络结构和视角,采用MVGAN生成的单视图图像来扩展训练集,可以提高分类精度,也可以不提高分类精度。因此,利用MV-GAN产生多视角珍珠图像对提高MS-CNN的性能至关重要。
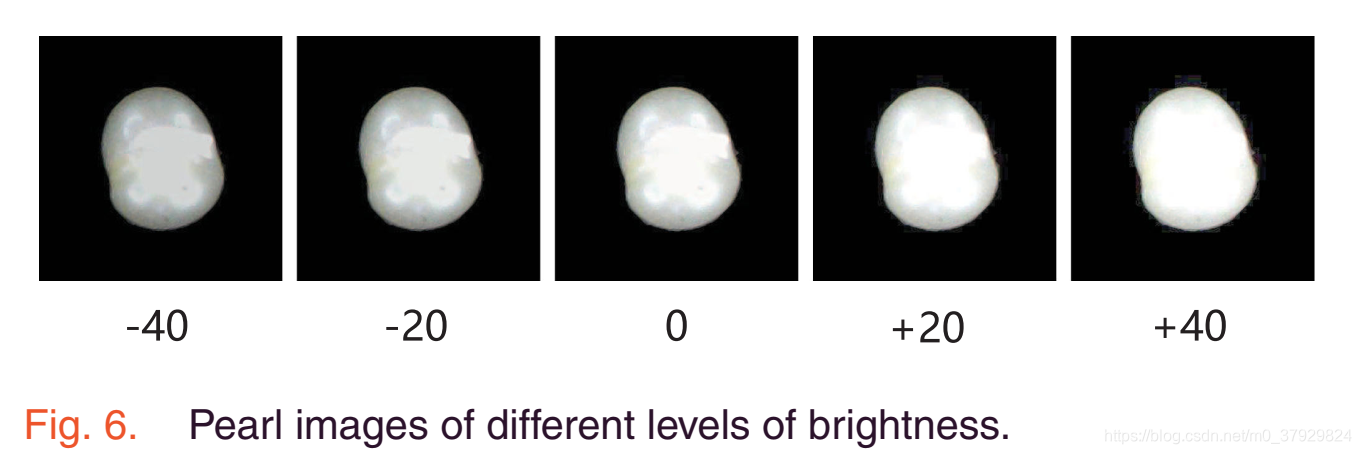
我们在不同的光照条件下合成珍珠图像如下:对于像素值不为零的区域,我们均匀地将像素值改变为不同的亮度级别。例如,图6示出了5个不同亮度级别的珍珠图像。中间那张是原图。左二者亮度较低,像素值分别减少20和40,右二者亮度较高,像素值分别增加20和40。我们使用这些不同亮度级别的珍珠图像作为新的测试集
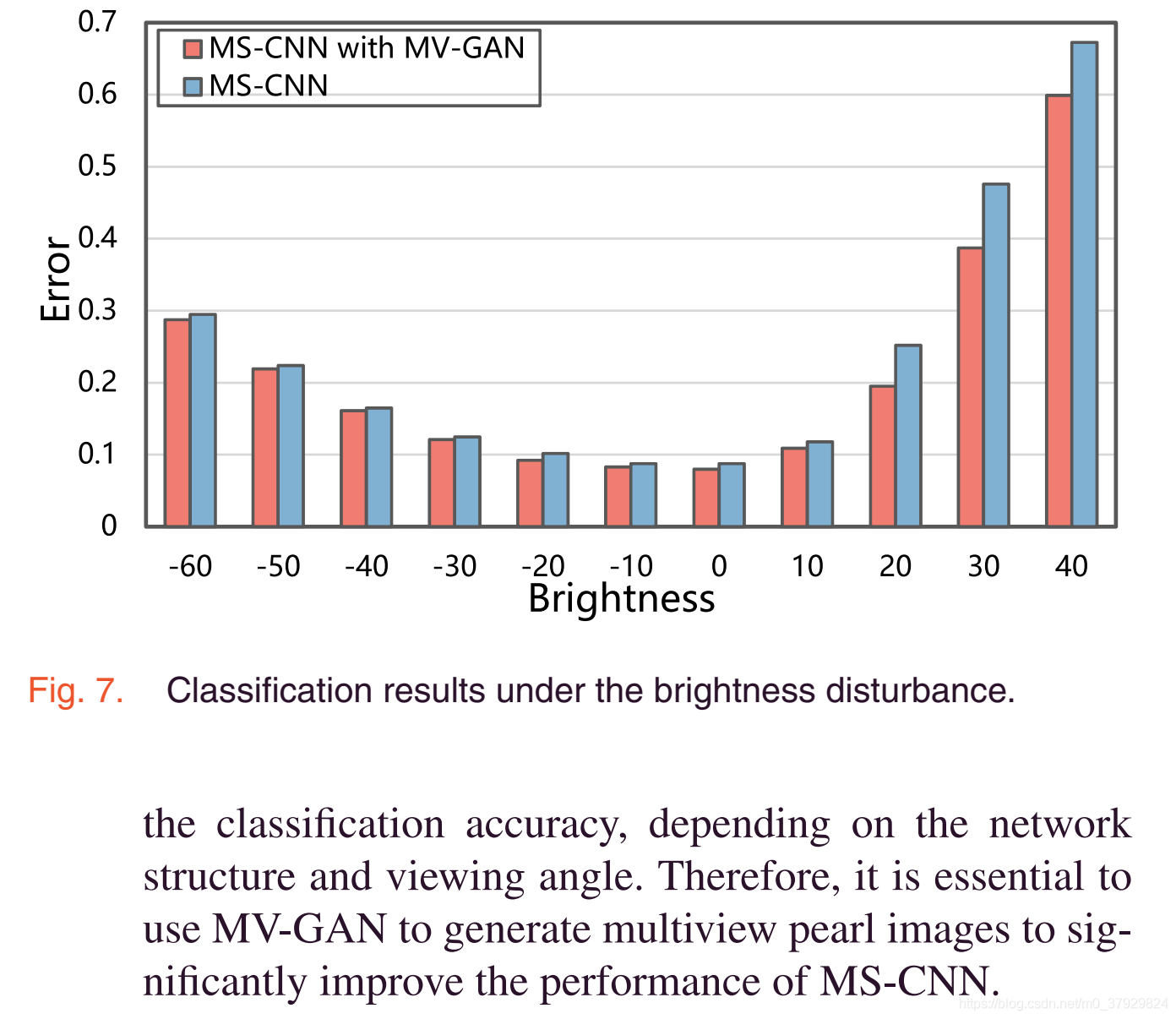
Conclusion
这篇文章以珍珠分类为基础,针对样本数不足问题,将多个角度的珍珠图像结合在一起进行图像生成,再将生成后的图像送入特殊的卷积神经网络训练,得出极好的性能。所作的实验包括:不同模型下在生成数据和不生成数据中性能的差异、(感觉少一组实验,即与传统数据生成方法的对比实验)、单一图像生成和批次生成的对比实验、不同光照下利用本数据生成方式性能对比实验、不同数据量情况下性能提升程度的对比实验。
参考文献
[1]Q. Xuan, Z. Chen, Y. Liu, H. Huang, G. Bao and D. Zhang, “Multiview Generative Adversarial Network and Its Application in Pearl Classification,” in IEEE Transactions on Industrial Electronics, vol. 66, no. 10, pp. 8244-8252, Oct. 2019.doi: 10.1109/TIE.2018.2885684

