文章目录
前言
深度学习领域的“hello,world”可能就是这个超级出名的MNIST手写数字数据集的训练(想多了,要是有C++的helloworld简单就好了)。
在我这个项目中,除了最基本的对MNIST数据集进行训练,我还加入了以下功能:
可以运用热点图查看MNIST数据集中的图像
可以通过转换识别自己手写数字的照片
mnist_model.py
import keras
from keras.datasets import mnist
import matplotlib.pyplot as plt
import PIL
from PIL import Image
(train_images,train_labels),(test_images,test_labels) = mnist.load_data()
train_images.shape
len(train_labels)
train_labels
test_images.shape
len(test_labels)
test_labels
#导入MNIST数据集
'''plt.imshow(train_images[819], cmap=plt.get_cmap('gray'))
print(train_images[819])
print(train_labels[819])'''
#运用热点图查看MNIST数据集
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512,activation='relu',input_shape=(28*28,)))
network.add(layers.Dense(10,activation='softmax'))
#构建网络(含有两个dense层)
network.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
#编译网络
train_images = train_images.reshape((60000,28*28))
train_images = train_images.astype('float32')/255
test_images = test_images.reshape((10000,28*28))
test_images = test_images.astype('float32')/255
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
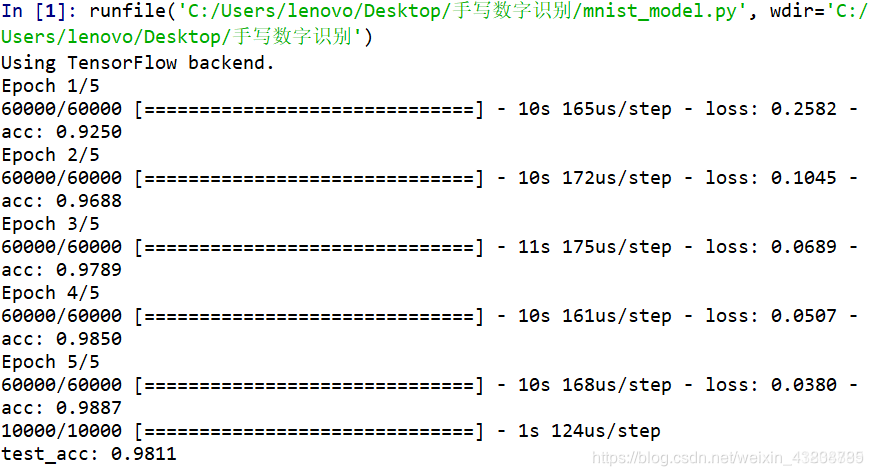
network.fit(train_images,train_labels,epochs=5,batch_size=128)
#训练循环
test_loss , test_acc = network.evaluate(test_images,test_labels)
print('test_acc:',test_acc)
#输出精度
此时,模型的训练就结束了,精度大概能稳定在98%左右
封装模型:
network.save('filename')
为了检验这个模型是否靠谱
我在ipad上的goodnote4中使用Apple pencil写下了10个数字,并将这10个数字单独保存

 再创建第二个.py文件调用模型
再创建第二个.py文件调用模型
predict.py
import numpy as np
from keras.models import load_model
import matplotlib.pyplot as plt
from PIL import Image
model = load_model('m_lenet.h5')
def pre_pic(picName):
# 先打开传入的原始图片
img = Image.open(picName)
# 使用消除锯齿的方法resize图片
reIm = img.resize((28,28),Image.ANTIALIAS)
# 变成灰度图,转换成矩阵
im_arr = np.array(reIm.convert("L"))
return im_arr
im1 = pre_pic('9.jpg')
print('输入数字:')
plt.imshow(im1,cmap=plt.get_cmap('gray'))
plt.show
im1 = im1.reshape((1,28*28))
im1 = im1.astype('float32')/255
predict = model.predict_classes(im1)
print ('识别为:')
print (predict)


可以看到,识别我自己手写的数字,精度并没有测试集的精度高,只有50%的成功率,而且几张图片都被识别成了数字6,说明可能我的写法和MNIST数据集取样人群的写法有较大差异,同时也有可能是模型过拟合。但总的来说,至少看起来还有点人模狗样。
