《深入浅出统计学》笔记
还是一样先概括书中的重点,对于一些抽象的内容,自己画了示意图帮助理解
再使用python实现其中的统计量
第二章 集中趋势的量度
平均数可以知道数据中心的所在
| 平均数 | 计算方法 | 何时使用 |
|---|---|---|
| 均值 | 或者 | 在数据非常对称,仅显示出一个趋势时使用 |
| 中位数 | 将数字升序排列,奇数个为中间的数字值,偶数个为位于中间的两个数字的平均值 | 数据由于异常而发生偏斜时使用 |
| 众数 | 选出具有最大频数的一个或几个数值,如果数据分组,则为每组找一个众数 | 当数据可以分为两个或更多组时使用 |
制造一个有偏数据
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
data = np.array(([500]*100+[2500]*80+[20000]*50))
sns.distplot(data,kde=False)
plt.bar(data.mean(),20)
#计算均值
data.mean()
5434.782608695652
#计算中位数
np.median(data)
2500.0
#计算众数
pd.Series(data).mode()#numpy中没有直接计算众数的方法,需要转为Series才可以
0 500
dtype: int64
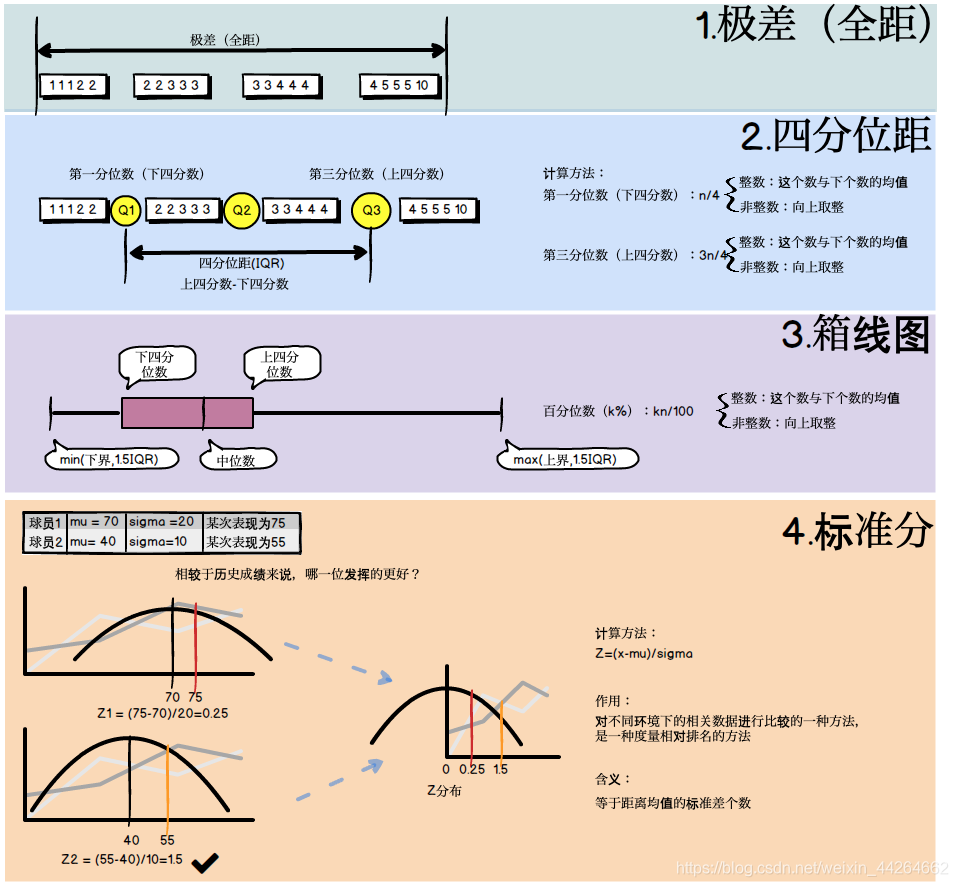
第三章 分散性与变异性的量度
| 统计量 | 计算方式 | 何时使用 |
|---|---|---|
| 全距 | 最大值-最小值 | 最简单 |
| 四分位距 | 上四分位数-下四分位数 | 看中间50%的数字范围,剔除异常值 |
| 百分位数 | 升序排列,kn/100为整还是不为整 | 可以知道位于数据范围的前百分之几 |
| 标准差 | 平均情况下的数值与均值的距离 | |
| 方差 | 或者 | |
| 标准分 | 度量相对排名的方法 有时可以将异常值定义为偏离均值三个标准差的数值 |
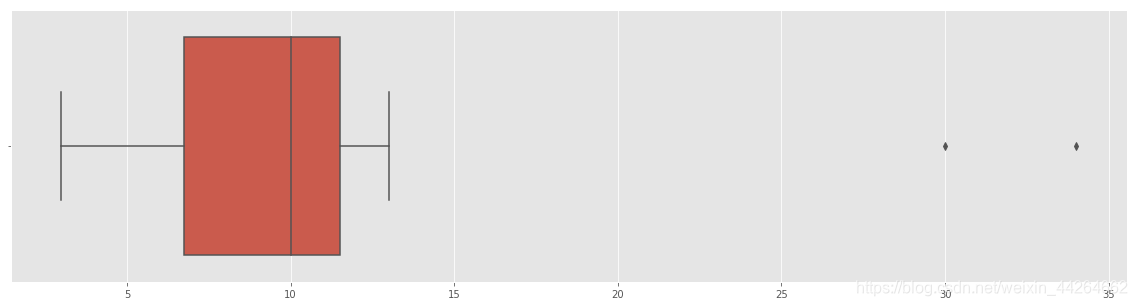
data = pd.DataFrame({'得分':[3,6,7,10,11,13,30,34],'频数':[2,1,2,3,1,1,1,1]})
original_data = []
for i in range(data.shape[0]):
original_data = original_data + [data.得分[i]]*data.频数[i]
original_data = pd.Series(original_data)
original_data
0 3
1 3
2 6
3 7
4 7
5 10
6 10
7 10
8 11
9 13
10 30
11 34
dtype: int64
#计算全距
original_data.max() - original_data.min()
31
#计算四分位距
#pandas中自带的计算四分位距的方法
a= original_data.quantile(q=[0.75,0.25],interpolation='nearest')
a.values[0]-a.values[1]
4
pandas中自带的计算四分位距的方法和书中提到的方法不同
下面介绍pandas中计算四分位距的方法
位置确定:
1+(n-1)*q
数值确定:
根据参数interpolation的不同略有不同
如果interpolation=‘linear’
则进行线性补充
下面是自己画的小图,对搜到的这三种计算四分位数的方法进行的总结

#计算标准差
original_data.std(ddof=0)
9.44281031614353
np.std(original_data)
9.44281031614353
需要注意的是,
在pandas中计算标准差时,默认的ddof=1,也就是计算标准差时,分母为n-1
而numpy中默认的ddof=0
方差也是同理
#箱线图
import seaborn as sns
import matplotlib.pyplot as plt
plt.style.use('ggplot')
plt.figure(figsize=(20,5))
sns.boxplot(original_data,orient='h',)