在店铺详情页下拉 点击更多点评 才会进入真正的详情页。
在这个页面,使用的是css的文字映射反爬。
分析一下页面 可以看到部分评论的数据是缺失的,跟每个节点的class属性可能有关系
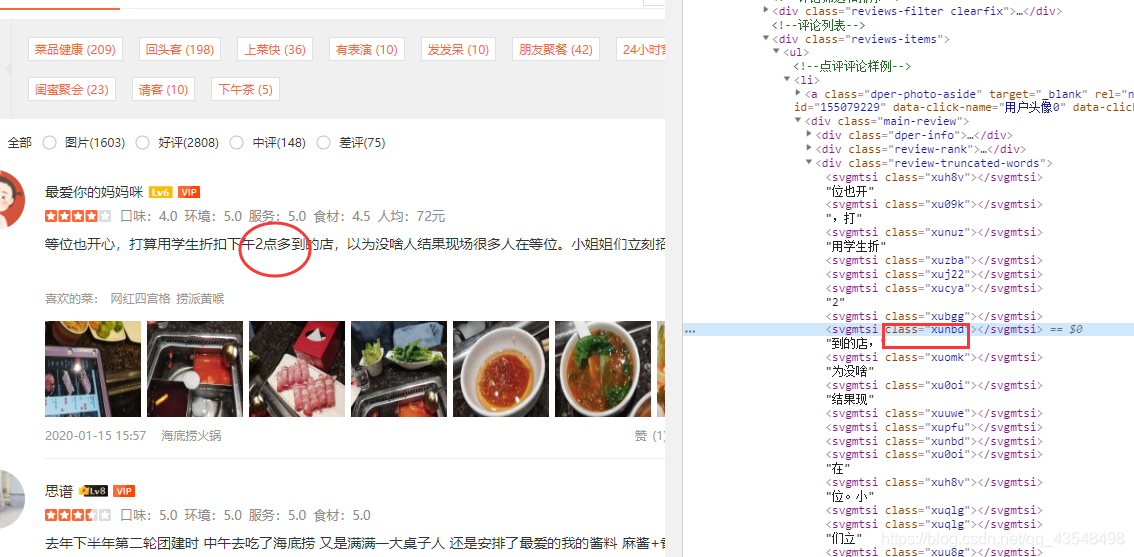
可以打开这个文件,找到节点class属性 映射的像素值。这个url可以用正则找到
svg_text_url = re.findall('<link rel="stylesheet" type="text/css" href="(.*?svg.*?)">', html)[0] #获得节点名对应坐标 css文件地址

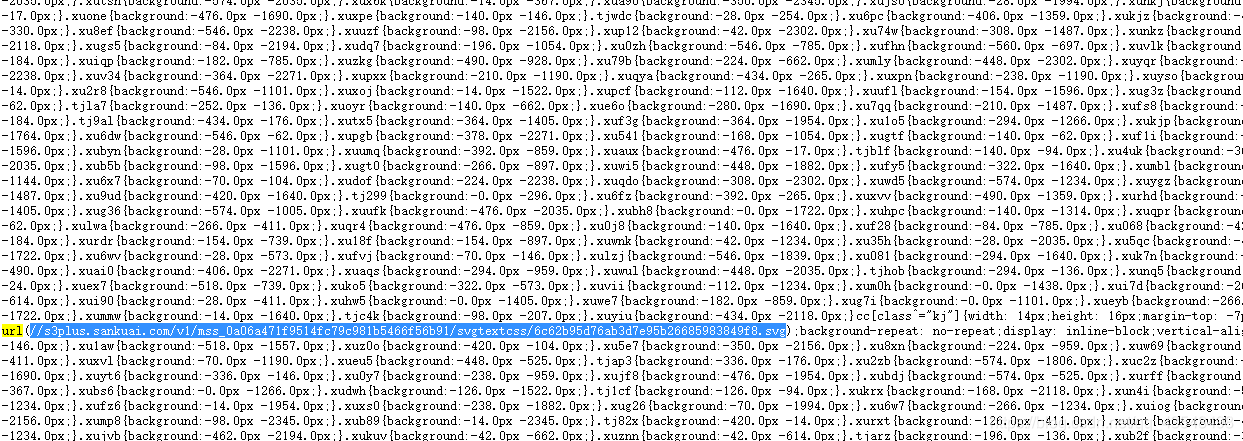
可以看到 css文件中 都是每个节点的class属性 对应的地址。接下来我们要找到地址所对应的文字
**
在css文件中,有一些 包含svg的url 将它打开
这个就是文字表,可以根据css坐标提取出相应的文字。
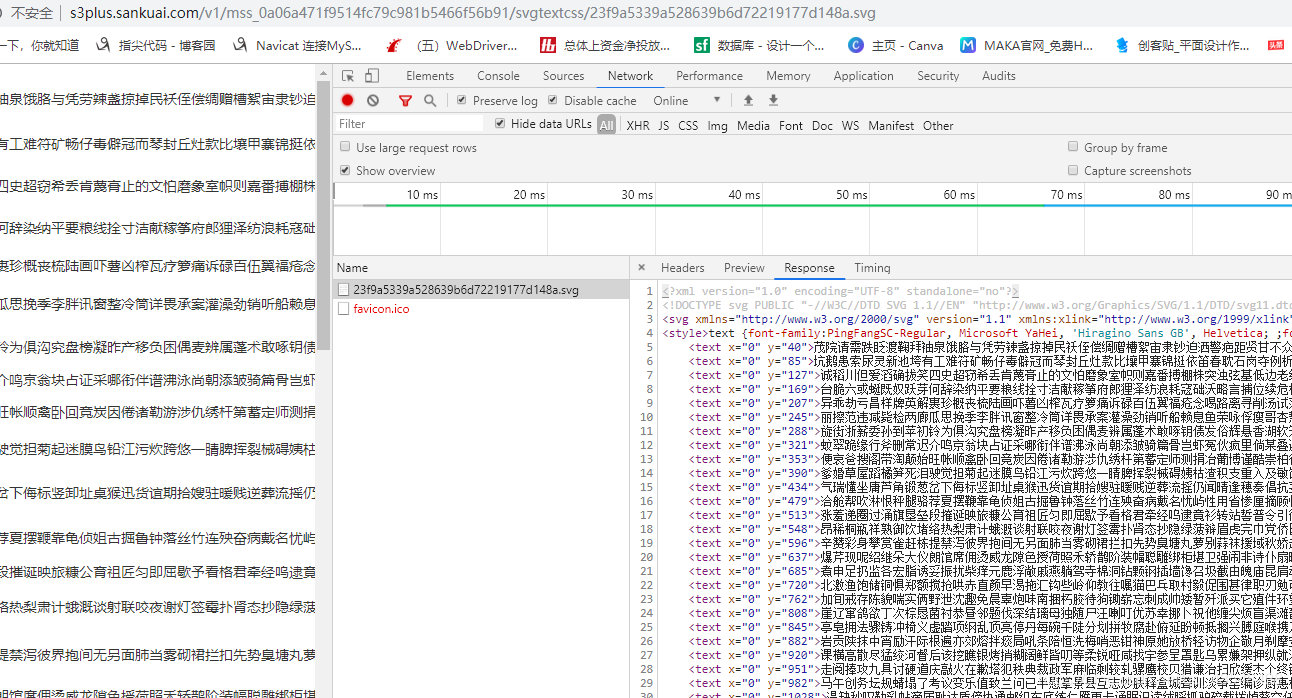
注意:有三个不同的文字坐标文件。其中只有两个坐标文件有用,点评网会在不同时间使用这两个坐标文件。如果进行长时间采集,需要对这两个坐标文件进行判断,来选择不同的坐标文件进行使用。
接下来我们的思路已经确定了
1.请求详情页数据,使用正则表达式找到css文件地址。
2.在css文件中 使用正则提取出所有节点名称以及对应的坐标。并找到文字坐标文件svg的地址
3.根据坐标 提取出.svg文件中对应的文字。形成节点名称对应文字的字典。
4.将请求详情页中返回的html,根据节点class属性替换为对应的文字。
5.正常解析html即可
在.svg文件根据坐标提取文字时,不同的时间段,点评网会使用不同的.svg文件进行匹配。
当.svg文件内容如下时 匹配规则如下:
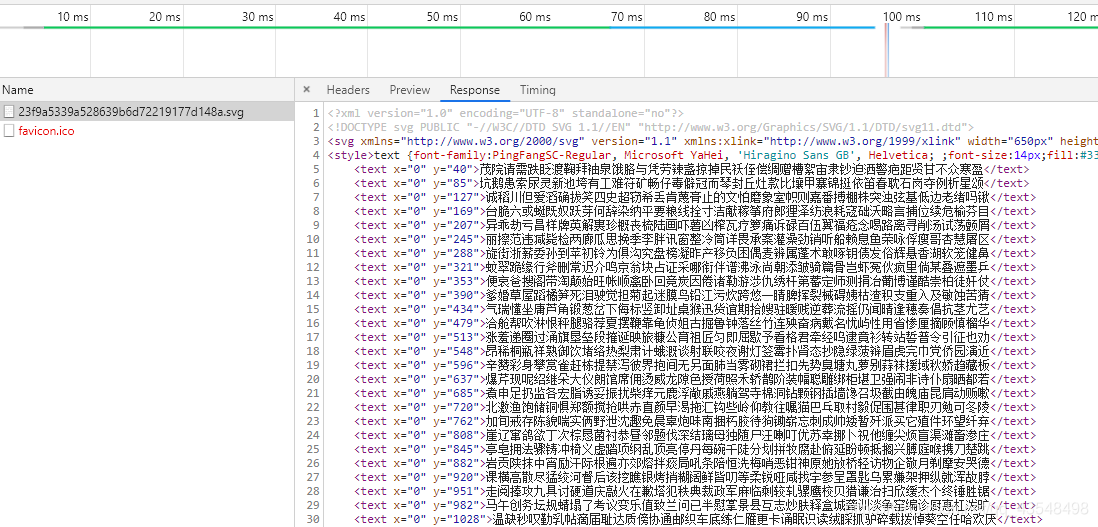
例:
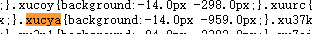
在html中 “午”字 对应的节点class属性为 “xucya”
“xucya” 对应的坐标为 “-14 -959”
其中 -959确定文字所在行 -14确定文字横向偏移量
可以看到svg返回数据中,每行的y值为一个个区间,根据959数字的大小确定区间,即可确定所在行。
确定行之后,横向便宜量为 数字/14 以14为例 14/14=1 则横向偏移量为1,确定的文字为当前行的第二个字。
当.svg文件内容如下时 匹配规则如下:

将每个节点前的 #数字 替换为上方的值 如下图所示
替换完成后 匹配规则和上面svg文件的匹配规则相同。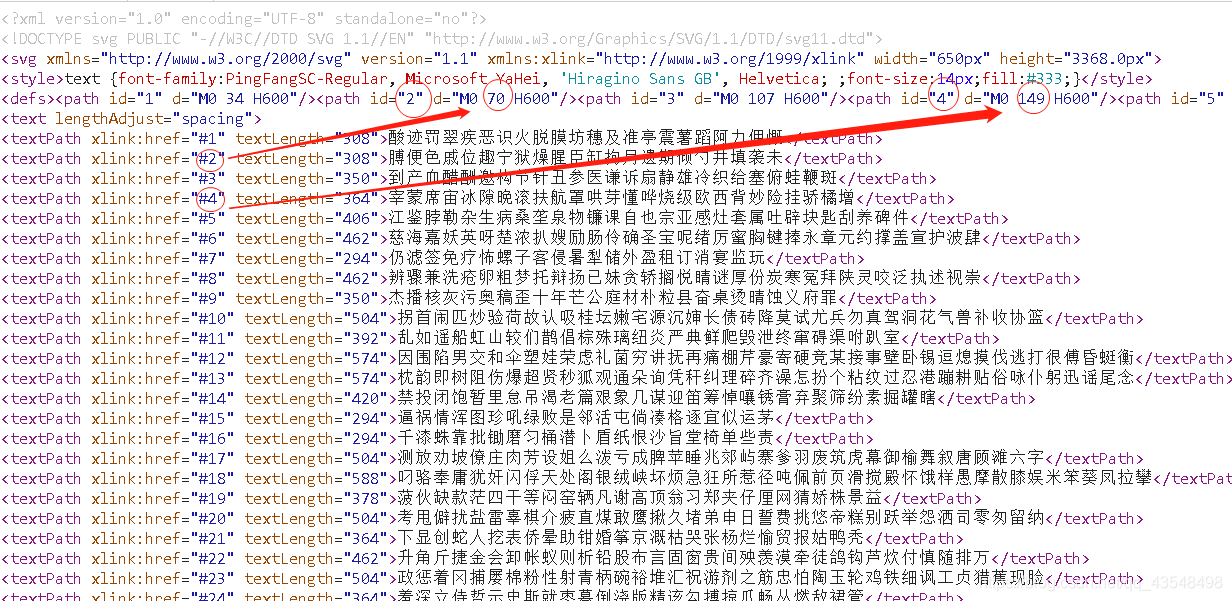
注:不可能每次启动采集都手动修改匹配方式,我们需要对svg文件做一个判断,完成自动化的匹配。可以根据svg内容信息来判断,如行数。每次解析svg文件,若行数小于20,则跳出继续解析下一个svg文件。如下图
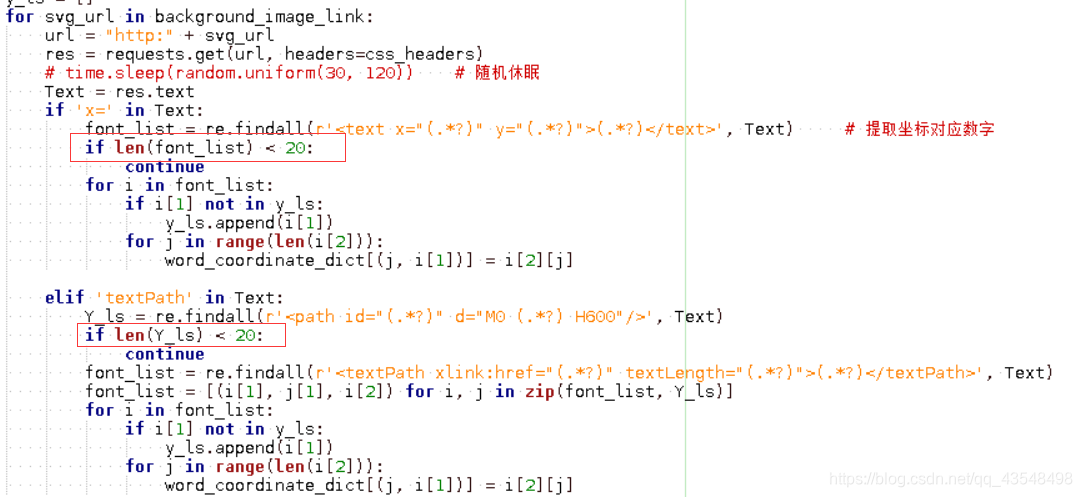
相关代码:
def get_node_dict(css_url, cookie):
"""
获取坐标值 对应 文字 字典
:param background_image_link:
:return:
"""
res = requests.get(css_url, headers=css_headers)
node_data_ls = re.findall(r'\.([a-zA-Z0-9]{5,6}).*?round:(.*?)px (.*?)px;', res.text) # 提取节点名与对应坐标
background_image_link = re.findall("background-image: url\((.*?)\)", res.text) # 提取 坐标对应数字 css文件地址
word_coordinate_dict, y_ls = get_word_coordinate_dict(background_image_link) #
node_data_dict = {}
for i in node_data_ls:
"""构造成{节点名: 数字, .........}"""
x = -int(i[1][:-2]) // 14
for index in range(len(y_ls)):
if -int(i[2][:-2]) <= int(y_ls[index]):
y = y_ls[index]
break
try:
node_data_dict[i[0]] = word_coordinate_dict[(int(x), str(y))]
except Exception as e:
pass
return node_data_dict
def get_word_coordinate_dict(background_image_link):
"""
获取坐标值 对应 文字 字典
:param background_image_link:
:return:
"""
word_coordinate_dict = {}
y_ls = []
for svg_url in background_image_link:
url = "http:" + svg_url
res = requests.get(url, headers=css_headers)
# time.sleep(random.uniform(30, 120)) # 随机休眠
Text = res.text
if 'x=' in Text:
font_list = re.findall(r'<text x="(.*?)" y="(.*?)">(.*?)</text>', Text) # 提取坐标对应数字
if len(font_list) < 20:
continue
for i in font_list:
if i[1] not in y_ls:
y_ls.append(i[1])
for j in range(len(i[2])):
word_coordinate_dict[(j, i[1])] = i[2][j]
elif 'textPath' in Text:
Y_ls = re.findall(r'<path id="(.*?)" d="M0 (.*?) H600"/>', Text)
if len(Y_ls) < 20:
continue
font_list = re.findall(r'<textPath xlink:href="(.*?)" textLength="(.*?)">(.*?)</textPath>', Text)
font_list = [(i[1], j[1], i[2]) for i, j in zip(font_list, Y_ls)]
for i in font_list:
if i[1] not in y_ls:
y_ls.append(i[1])
for j in range(len(i[2])):
word_coordinate_dict[(j, i[1])] = i[2][j]
return word_coordinate_dict, y_ls
def replace_html(html, css_url, cookie):
"""
提取全部节点,根据节点名 替换数据 返回真实html数据
:param html:
:param css_url:
:param cookie:
:return:
"""
node_data_dict = get_node_dict(css_url, cookie)
node_names = set()
for i in re.findall('<svgmtsi class="([a-zA-Z0-9]{5,6})"></svgmtsi>', html): # 提取所有节点名
node_names.add(i)
for node_name in node_names:
try:
html = re.sub('<svgmtsi class="%s"></svgmtsi>' % node_name, node_data_dict[node_name], html) # 替换html节点为数字
except KeyError as e:
# print(e)
pass
return html
def parse_html(html, shop_id):
"""
解析html 第一次采集 提取好评差评数量
后续采集 提取口味,环境,服务,食材,星级,评论
:param html:
:param i:
:return:
"""
sel = etree.HTML(html)
save_data = []
for node_num in range(1, 16):
comment_content_3 = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[3]/text()'.format(node_num)) # 评论数据存在于 两个节点 div3号节点数据
comment_content_4 = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[4]/text()'.format(node_num)) # div4号节点数据
if len(''.join(comment_content_3)) > len(''.join(comment_content_4).replace(' ', '').replace(r'\n', '')):
comment_content = comment_content_3
else:
comment_content = comment_content_4
taste_score = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[2]/span[2]/span[1]/text()'.format(node_num)) # 口味评分
environment_score = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[2]/span[2]/span[2]/text()'.format(node_num)) # 环境评分
service_score = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[2]/span[2]/span[3]/text()'.format(node_num)) # 服务评分
food_score = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[2]/span[2]/span[4]/text()'.format(node_num)) # 食物评分
food_score = ''.join(food_score).strip().replace('食材:', '')
per_capita = ''
if "人均" in food_score: #
per_capita = food_score.replace('人均:', '').replace('元', '')
food_score = ''
star_level = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[3]/div[3]/ul/li[{}]/div/div[2]/span[1]/@class'.format(node_num))
item = {
'taste_score': ''.join(taste_score).strip().replace('口味:', ''),
'environment_score': ''.join(environment_score).strip().replace('环境:', ''),
'service_score': ''.join(service_score).strip().replace('服务:', ''),
'food_score': food_score,
'per_capita': per_capita,
'shop_id': shop_id,
'star_level': ''.join(star_level).strip().replace('sml-rank-stars sml-str', '').replace(' star', ''),
'comment_content': ''.join(comment_content).strip(),
}
save_data.append(item)
return save_data
def parse_action(cookie, main_url, proxy, Thread_name, progress):
"""
详情页采集主函数
:param cookie:
:param url:
:return:
"""
# cookie = "__mta=51347094.1571707475917.1571707475917.1571707475917.1; _lxsdk_cuid=16ddc82c62cc8-0c2da24cdecceb-7373e61-15f900-16ddc82c62dc8; _lxsdk=16ddc82c62cc8-0c2da24cdecceb-7373e61-15f900-16ddc82c62dc8; _hc.v=63c163cf-d75d-89b9-0dc1-74a9b2026548.1571362621; ua=sph; ctu=cdff7056daa2405159990763801b14e0b74443eb8302ce0928ea5e3d95696905; s_ViewType=10; aburl=1; _dp.ac.v=da84abba-5c47-4040-ac30-40e09e04162f; uamo=15292060685; cy=1; cye=shanghai; dper=ae518422253841cb8382badd9f84a3d471e237b43479f8d74f098a5ea02eabda1d22f0912bc506af3ff0f9dfc1cabd260be8824e9a0abeff2b67e50524f5875806e64becebd3923d9b402b395373f85a7f4228bc2e2dfc6533237b19446496e3; ll=7fd06e815b796be3df069dec7836c3df; _lx_utm=utm_source%3DBaidu%26utm_medium%3Dorganic; _lxsdk_s=16e353fda1a-7ba-0ce-cef%7C%7C124"
# url = "http://www.dianping.com/shop/128001304/review_all"
headers["Cookie"] = cookie
headers['Host'] = 'www.dianping.com'
# ip_list = requests.get(
# url="http://route.xiongmaodaili.com/xiongmao-web/api/glip?secret=8c1fe70d7ceb3a4e77284561df11f0d5&orderNo=GL20191111103706QQa4ktHu&count=1&isTxt=1&proxyType=1").text.split("\r\n")
# ip_pool = [{"http": "http://{}".format(ip)} for ip in ip_list if ip != ""]
# main_url = "http://www.dianping.com/shop/100034705"
shop_id = main_url.replace("http://www.dianping.com/shop/", "") # 提取shop_id
if progress == None:
progress = 1
for page_num in range(int(progress)+1, 1000):
url = "http://www.dianping.com/shop/{}/review_all/p{}?queryType=isAll&queryVal=true".format(shop_id, page_num) # 生成url
time.sleep(random.uniform(85, 120)) # 每次随机休眠50-100秒
i = 0
while i < 2:
try:
rep = requests.get(url, headers=headers, timeout=25, proxies=proxy)
break
except requests.exceptions.ConnectionError as e:
i += 1
time.sleep(300)
print('{}: 请求失败 休眠300秒 url:{}'.format(Thread_name, url))
continue
Text = rep.text
sel = etree.HTML(Text)
go_on_flag = sel.xpath('//*[@id="review-list"]/div[2]/div[3]/div[2]/div[3]/text()')
if go_on_flag == ["暂无点评"]: # 解析出暂无电影 则退出采集
print("{}: {}店铺 采集完毕".format(Thread_name, shop_id, ))
Mysql.modify_statue(main_url, page_num, 1)
break
css_url = "http:" + re.findall('<link rel="stylesheet" type="text/css" href="(.*?svg.*?)">', Text)[0] # 提取cssurl地址
html = replace_html(Text, css_url, cookie) # 原始html 替换节点后 生成带有原文的html
save_data = parse_html(html, shop_id) # 解析
Mysql.save_comment(url, save_data, Thread_name) # 存储
Mysql.modify_statue(main_url, page_num)
项目github:https://github.com/sph116/dazhong_spider_font_svg
