会议:ISCSLP 2016
论文:End-to-end keywords spotting based on connectionist temporal classification for Mandarin
作者:Ye Bai ; Jiangyan Yi ; Hao Ni ; Zhengqi Wen ; Bin Liu ; Ya Li ; Jianhua Tao
Abstract
传统的基于DNN-HMM的混合式ASR系统用于关键字查找,其模型HMM状态无法灵活地针对特定语言进行优化。在本文中,我们构建了基于ASR的端到端声学模型,用于普通话中的关键词发现。该模型由LSTM-RNN构建,并使用CTC(connectionist temporal classification,用来解决输入序列和输出序列难以一一对应的问题)的客观度量进行训练。网络的输入是特征序列,输出的是普通话音节的首字母和结尾的概率。与基于混合的ASR系统相比,端到端系统在ATWV上相对实现了6.32%的显着改进。我们系统的最佳结果是在RASC863数据集上,ATWV 0.8310。所提出的基于CTC的方法适用于特定语言的KWS。
Introduction
关键字发现(KWS)用于检测给定的无约束语音[1]中的一组预先定义的口语术语。它已被广泛用于语音拨号,呼叫中心,语音监控,语音控制,语音检索等。在这些应用程序中,在KWS中应用了两种主要类型的方法。一种是有监督的方法,例如,基于大词汇量连续语音识别(LVCSR)的方法[2],另一种是无监督的方法,例如模板匹配[3]。一些方法,例如填充模型[4]和DNN [5],更改关键字列表后需要重新培训。在KWS的非特定任务中,基于LVCSR的方法被广泛使用,因为它不需要任何有关语音的先验知识即可搜索关键字。根据用户需求灵活更改关键字。在本文中,我们重点介绍基于LVCSR的KWS。
在基于LVCSR的方法中,首先将语音转换为文本数据结构的形式,然后构造倒排索引以搜索用户的关键字。由于LVCSR的1个最佳字级输出并不完全准确,因此会影响KWS的性能。提出了可以为关键词搜索提供更多候选结果的结构,例如位置特定的后验格(PSLP)[6]。原始文本结构包含多余的单词,并且关键字可能会出现在其中。
首先构建了LVCSR系统,该系统包括声学模型和语言模型。给定输入声学特征,声学模型将生成后验概率,包括隐马尔可夫模型(HMM)和高斯混合模型(GMM)[7]或深度神经网络(DNN)[8]。HMM用于描述声学特征序列与状态序列之间的关系以对电话建模,而GMM或DNN用于建模声学特征与HMM状态之间的关系。由大规模语料库训练语言模型还通过构建加权有限状态变换器(WFST)[9] ,[10] ,用于解码。
但是,构建这种LVCSR系统很复杂。声学模型的构建分为几个阶段。状态级别模型的构建在语音上没有实际意义。很难将特定语言的语音知识带入声学模型。因此,提高针对特定语言(例如普通话)的关键字搜索性能的方法并不方便。
最近,为LVCSR提出了基于端到端的声学模型,例如连接主义的时间分类(CTC)[11]和基于注意力的模型[12]。CTC是使用递归神经网络模型进行序列标记任务的直接方法。它可以通过单个递归神经网络(RNN)简化LVCSR的架构[13]。在不对HMM状态建模的情况下,CTC可以在给定输入声音特征(例如电话,音节或字符)的情况下为语音元素生成后验概率。
在本文中,我们构建了基于CTC的普通话关键词发现系统。我们研究了两种特征,梅尔频率倒谱系数(MFCC)和梅尔尺度滤波器组(FBANK)来训练RNN。该模型是针对普通话音节的首字母和结尾而构建的。进行实验以与基于传统DNN-HMM的声学模型进行比较。实验结果表明了该方法的优点。
CTC Based ASR
1、基于CTC的声学模型
在典型的ASR系统中,声学模型的结构可以表示为两个级别:HMM级别由一组群集状态组成,状态的输出分布级别由GMM或DNN表示。基于CTC的声学模型将两个级别的结构统一为一个基于RNN的框架。
语音识别中的主要问题是将声学特征序列转换为字符序列。但是这两个序列之间的关系不能通过RNN直接建模。由于字符序列的长度通常比声学特征序列的长度短,因此当RNN创建的标签与输入序列一一对应时。建议使用CTC解决此问题。主要思想是在标签集中添加一个空白符号,并使用RNN进行标签。最后,删除多余的空白符号和重复的符号[11]。该模型描述略~
2、基于CTC的ASR解码
结合声学成本和语言模型成本的解码方法基于加权有限状态传感器(WFST)[13]。 令牌WFST将CTC序列映射到电话序列。 词典WFST将电话序列映射到单词序列。 语法WFST是加权有限状态接受器,可将语言得分保存在弧线上。 最终的搜索图是由三个WFST组成的。了提供更多候选关键词搜索结果,将解码结果另存为格。在格子中搜索关键字。
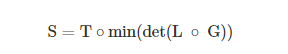
Keywords Spotting Based on CTC
系统图如图2所示。关键字发现系统的前端是ASR系统。然后将ASR的候选结果转换为索引以搜索关键字。
搜索索引是用定时因子转换器算法构建的[14]。定时因子换能器是一种加权有限状态换能器,它接受晶格中任何路径的所有子串。定时因子传感器的弧度为三个元组,可节省分数,开始时间和结束时间。给定语音的索引是通过考虑所有定时因子转换器的并集而构造的。
在构造之前对晶格进行预处理。通过遍历拓扑排序可以记录格中每个状态的时间步长。然后获得每个电弧的周期。弧根据输入标签和重叠时段进行聚类。首先,根据结束时间步长对弧进行排序。然后找到最大的不重叠(开始时间,结束时间)对作为簇头。最后,将群集ID分配给其余弧。因子转换器的输入是输入标签,而输出标签是群集ID。
搜索分为两个步骤。首先,将查询字符串编译为线性有限状态接受器。然后用索引组成接受器。可以通过投影WFST获得关键字出现的时间信息。

Experiments
1、实验装置
实验是使用开源工具包Kaldi [17]和EESEN [13]实现的。LSTM-RNN构建了用于训练基于CTC的声学模型的拟议网络。该网络由四个单向LSTM层组成,每个层有320个单元。尝试了两种输入来测试效果。一种是从具有Delta和Double Delta的40维对数mel频率滤波器组特征向量生成的120维输入。另一个是39维,它是由13维的mel频率倒谱系数(具有增量和双增量)生成的。输出的是242维向量,表示61个普通话音节的首字母和结尾,175个消歧符号,5个辅助符号和一个空白符号的概率。使用时间反向传播(BPTT)对网络进行了训练[18]。初始学习率为0.00002。这些模型在RASC863:863上标注了4个区域重音语音语料库[19]。语料库包含250个小时的普通话演讲。语音以16kHZ采样。
我们使用从RASC863提取的数据来测试我们提出的KWS系统的有效性。测试集包含20个小时的语音数据,尚未包含在训练数据中。包含4253个关键字的关键字列表是从标签文本中随机生成的。词汇外(OOV)关键字的数量为16。由于OOV关键字太少而无法提供令人信服的结果,因此我们主要关注词汇内(IV)KWS。
语言模型是由开源工具包SRILM [20]训练的trigram 。包含30792个单词的文本数据是自收集的。最终WFST搜索图的大小为118MB。
衡量KWS有效性的指标是术语加权值(TWV)[21]。它是检测性能的总体优势,包括未检测到的术语加权概率和错误警报的术语加权概率的加权和。
2、ASR实验
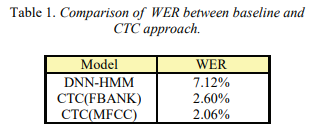
我们将基于CTC的声学模型与ANN中的DNN-HMM模型的效果进行了比较。DNN的输入功能是FBANK。DNN有6个隐藏层,每层有1024个单位。该模型使用sMBR标准进行判别式训练[22]。结果示于表1。与传统的基于DNN-HMM的ASR系统相比,基于CTC的模型的WER降低了5.06%。MFCC的输入具有最高的精度。
2、KWS实验
首先,我们研究了两个会影响KWS的ATWV的超参数的影响:解码波束的宽度和声学成本的权重。这两个超参数是独立的。
我们首先研究光束对ATWV的影响。结果如图3所示。实验将声级设置为0.7。

波束宽度影响晶格中候选句子的数量。较高的波束为KWS提供更多的候选单词。另一方面,由于格中权重的不准确性,导致错误警报的增加。由于太大的光束会导致晶格尺寸增加,并且不会改善ATWV,因此我们将光束的5个值从8测试到34。结果显示,ATWV从8增大到14,从26减小到34。从14变为26的效果并不明显。最高的ATWV在光束20处。因此,在其余实验中,我们将光束设定为20。

我们还研究了声学成本权重对ATWV的有效性。ATWV在5个声标上进行检查。结果如图4所示。ATWV从声级0.7增大到1.1,然后减小。在其余的实验中,我们将声级设置为1.1。声学标度是在声学模型和语言模型之间取得平衡的参数。我们认为声学成本的权重比语言模型更重要。因为在KWS任务中,目标是找到合适的单词,而不是识别整个句子。对于单个关键字,声学成本更为重要。但是,句子中关键字的上下文出现信息对于减少误报很重要。因此,声标不能设置得太大。
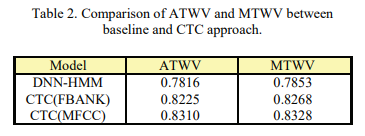
表2中显示了KWS的工作量。基于MFCC的CTC模型具有最高的ATWV和MTWV。具有FBANK功能的基于电话的CTC声学模型获得2.60%的字错误率(WER)。而带有MFCC输入的基于电话的CTC模型的WER为2.06%。具有MFCC输入的CTC模型的ATWV为0.8310。与DNN-HMM相比,ATWV相对提高了6.32%。
传统的ASR系统分为几个部分,每个部分都有自己的培训目标。端到端模型统一了整个系统,并直接使用RNN对普通话音节的首字母和结尾进行建模。它避免了多层次系统中目标的不一致。这对于改善KWS的ASR和ATWV中的WER是有效的。这也引起了我们的好奇,即在CTC模型中MFCC的结果优于FBANK。
Conclusion and Future Work
基于语音识别系统构建关键词识别系统,该语音识别系统的声学模型通过使用CTC的递归神经网络进行训练。分别为解码格和关键字构造了加权有限状态传感器。在这两个WFST上执行关键字发现。实验进行了评估该技术的有效性。研究了声束宽度和声级。当使用来自RASC863的250小时的音频数据训练模型时,ATWV和MTWV分别为0.8310和0.8328。与传统的DNN-HMM相比,ATWV相对提高了6.32%。这是因为CTC直接模拟普通话音节的首字母和结尾。
我们计划尝试对其他级别的语音元素(例如字符或音节)进行建模,以检查在汉语中发现关键词的适当元素。考虑使用MFCC功能比FBANK功能更有效的原因。我们还将考虑可以直接针对KWS任务训练模型。
